






主要分几个大块:backone搭建, Default box生成,数据预处理,损失函数计算,后处理算法,正负样本的选取
我们结合论文的策略和代码实现辅助理解
Backbone:
主要是由部分的resnet50,和5个额外层构成
class Backbone(nn.Module):
def __init__(self, pretrain_path=None):
function: 建立SSD算法的Backbone ResNet_50部分,其中删除掉Conv4_x 后面的部分,
Conv4_1部分: Conv_3*3:stride=1,branch_conv:stride=1
并且Conv4_x 的输出是 第一个预测特征层
para: pretrain_path 预训练参数文件位置
return: 返回一个nn.Sequential()的类用于构建网络
def __init__(self, pretrain_path=None):
super(Backbone, self).__init__()
net = resnet50()
self.out_channels = [1024, 512, 512, 256, 256, 256]
if pretrain_path is not None:
net.load_state_dict(torch.load(pretrain_path))
self.feature_extractor = nn.Sequential(*list(net.children())[:7])
conv4_block1 = self.feature_extractor[-1][0]
# 修改conv4_block1的步距,从2->1
conv4_block1.conv1.stride = (1, 1)
conv4_block1.conv2.stride = (1, 1)
conv4_block1.downsample[0].stride = (1, 1)
def forward(self, x):
x = self.feature_extractor(x)
# print(x.shape)
return x通过 net.children()返回一个迭代器,通过遍历这个迭代器,就可以得到net网络所有的子模块,其中我们只需要Conv1 BN ReLU MaxPool Conv2_x,Conv3_x,Conv4_x(Sequential结构),转化为列表类型,将列表的元素传递给nn.Sequential
当然我们需要更改Conv4_1 的stride 将这个虚线残差结构的stride 更改,out_channels 不变
Conv4_x的结构如下 其中残差结构Conv4_1为self.feature_extractor[6][0]
6 : Sequential(
(0): Bottleneck()
(1): Bottleneck()
(2): Bottleneck()
(3): Bottleneck()
(4): Bottleneck()
(5): Bottleneck()
)6 : Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
.......conv4_block1 = self.feature_extractor[6][0]
conv4_block1.conv2.stride = (1,1)
conv4_block1.downsample[0].stride = (1,1)
class SSD300(nn.Module):
self._build_additional_features(self.feature_extractor.out_channels)
_build_additional_features : 函数创建5个额外层 返回 nn.ModuleList结构
由于5个额外层是连续的,一个的输出是下一层的输入,
额外层结构:Conv(1*1/s1) BN ReLU Conv(3*3/s2/p1) BN ReLU
代码里舍弃了VGG网络 用 ResNet网络代替
这五个额外层,显然输入和输出是有部分重叠的
input_size = [1024,512,512,256,256]
output_size= [512,512,256,256,256]
middle_channels = [256,256,128,128,128]
input_size --> middle_channels-->output_size
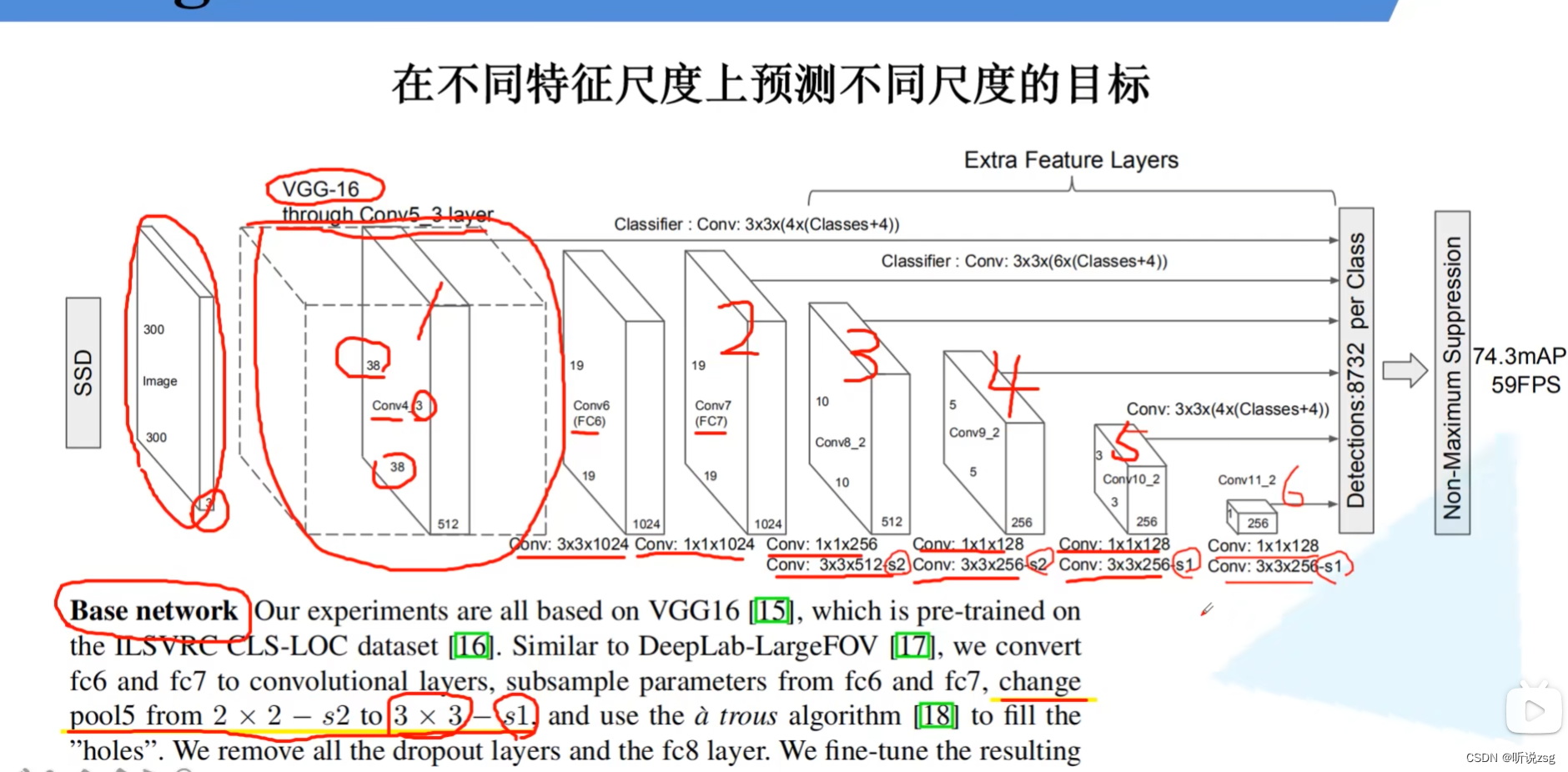
设置 input_size = [1024, 512, 512, 256, 256, 256]
input_ch = input_size[:-1], output_ch =input_size[1:]
注意 BN层之前 卷积层的偏置设置为False Conv --> BN -- > ReLU
padding, stride = (1, 2) if i < 3 else (0, 1)
layer = nn.Sequential(
nn.Conv2d(input_ch, middle_ch, kernel_size=1, bias=False),
nn.BatchNorm2d(middle_ch),
nn.ReLU(inplace=True),
nn.Conv2d(middle_ch, output_ch, kernel_size=3, padding=padding, stride=stride,
bias=False),
nn.BatchNorm2d(output_ch),
nn.ReLU(inplace=True),
)
additional_blocks.append(layer)
self.additional_blocks = nn.ModuleList(additional_blocks)
这里用nnModuleList( :List) 而不是nn.Sequential(*List) 主要是我们需要在每个特征层进行预测每经过一个特征层我们需要输出预测结果,而不是直接把输出传递到下一个特征层
我们每个特层的输出需要进行预测边界框的位置参数和置信度参数
每个边界框需要预测位置参数4个, 那对于每个ceil 输出的channel: 边界框个数*位置参数个数
每个边界框需要预测类别个数为21个,那对于每个ceil 输出的channel:类别个数*边界框个数
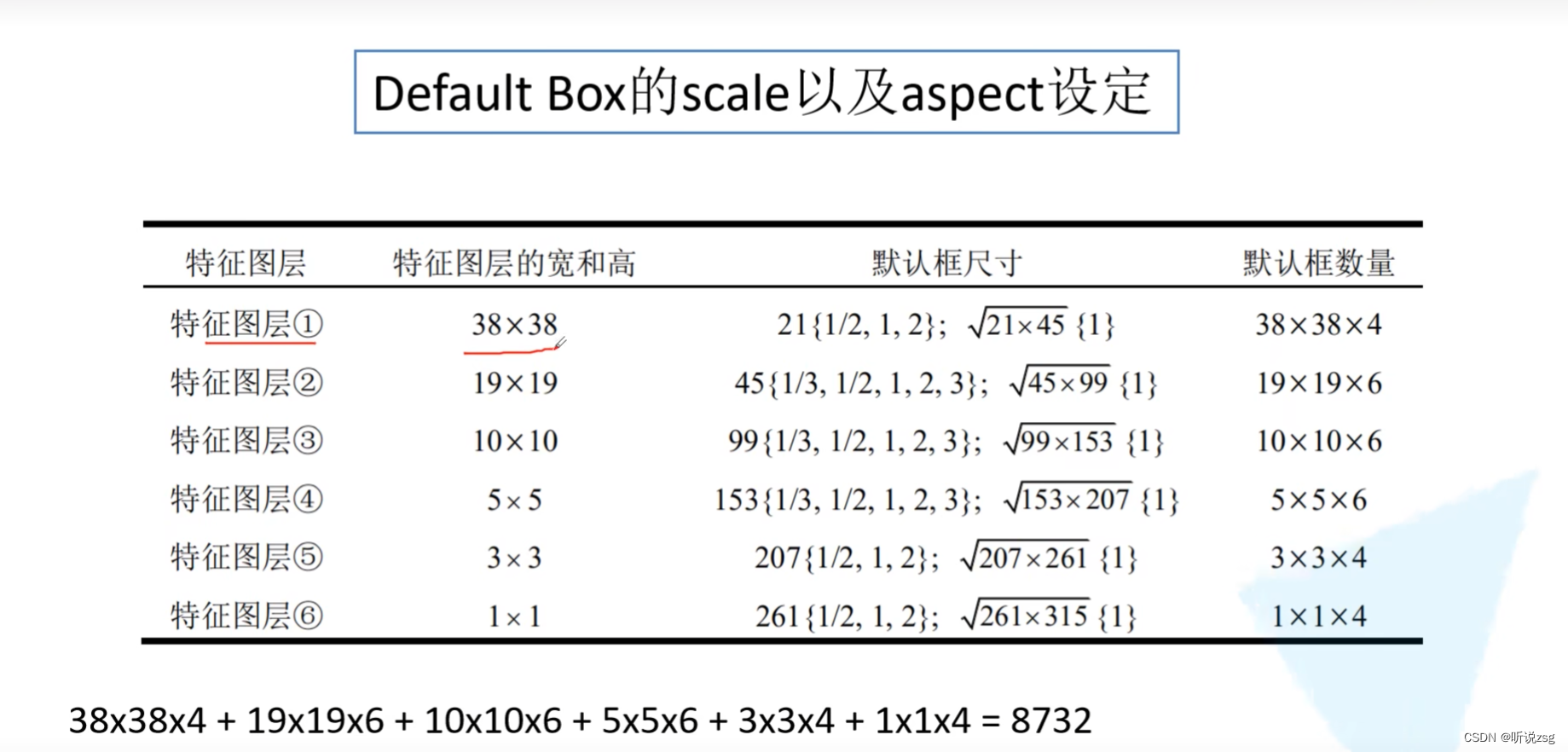
对于每个特征层的预测的default box数量不一定相同
self.num_defaults = [4,6,6,6,4,4]
预测器策略介绍
如何在这6个预测特征矩阵上,进行预测
对于 size = m*n channel = p 的特征层,我们直接使用卷积核大小为3*3 channel = p的卷积核来进行实现,来生成概率分数,以及边界框偏移量(回归参数)
显然,对于我们特征图上的每一个位置,我们会计算k个default box 我们对每个default box 计算 c个类别分数(包括背景),以及4个坐标偏移量,也就是需要(C+4)*k个卷积核 进行卷积处理,对于大小为m*n的特征层 就会生成 (C+4)*kmn个输出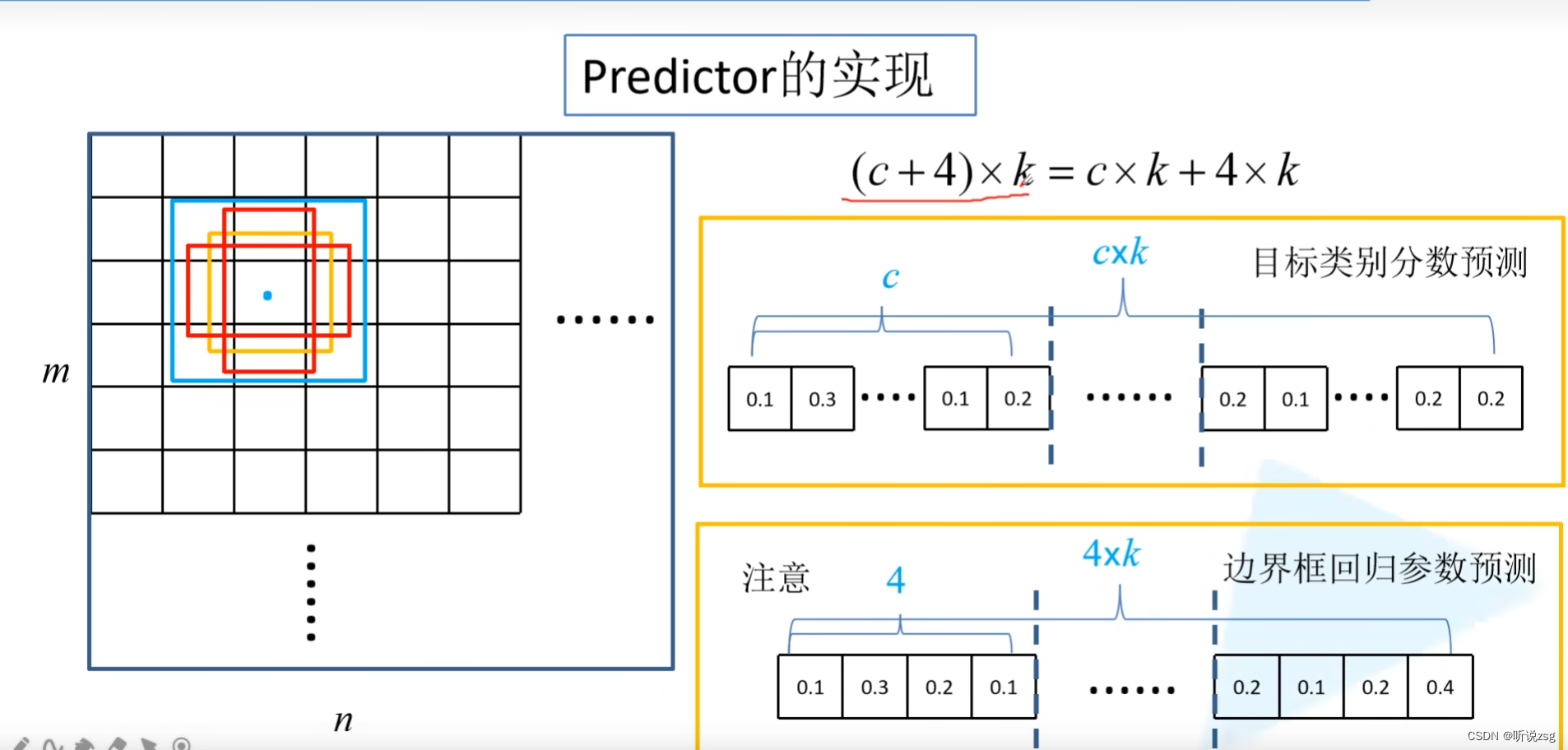
for nd, oc in zip(self.num_defaults, self.feature_extractor.out_channels):
# nd is number_default_boxes, oc is output_channel
location_extractors.append(nn.Conv2d(oc, nd * 4, kernel_size=3, padding=1))
confidence_extractors.append(nn.Conv2d(oc, nd * self.num_classes, kernel_size=3, padding=1))
self.loc = nn.ModuleList(location_extractors)
self.conf = nn.ModuleList(confidence_extractors)正向传播过程:
先得到每一个特征层的输出,之后将这些输出传入预测器中进行预测
detection_features 定义一个张量列表,初始化为空列表,这里就可以看到ModuleList()结构的用处
x = self.feature_extractor(image)
# Feature Map 38x38x1024, 19x19x512, 10x10x512, 5x5x256, 3x3x256, 1x1x256
# 返回一个空列表,其中的元素类型 tensor 这个列表存储预测特征层进行预测之前的输入
detection_features = torch.jit.annotate(List[Tensor], []) # [x]
detection_features.append(x)
for layer in self.additional_blocks:
x = layer(x)
detection_features.append(x)
# 传入预测器中 self.loc self.conf
locs, confs = self.bbox_view(detection_features, self.loc, self.conf)
拿到预测特征层的数据,我们分别传入预测位置参数的预测器和预测类别的预测器,
类别预测器和位置参数预测器都是用的kernel_size = 1,padding = 1 的卷积核进行卷积,不改变输入特征层的尺寸,只改变out_channels
self.num_defaults = [4,6,6,6,4,4]
输出的张量格式为:[batch, 4/21*num_default, feat_size, feat_size]
格式调整成:(batch, 4/21 -1) 其实第三维数据就是当前特征层需要预测出多少个default_box
default_box = feat_size*feat_size*num_defaults
当然最终把所有的层的default_box 加在一起是 8732 (将第三维数据进行拼接,之后再进行正负样本的选取)
返回值: locs: batch,4,8732 confs: batch,21,8732
# locs, confs = self.bbox_view(detection_features, self.loc, self.conf)
def bbox_view(self, features, loc_extractor, conf_extractor):
"""
function : 将输入的特征层进行预测操作
:param features: 预测特征层的数据 张量类型的列表,
:param loc_extractor: 进行预测位置参数的卷积操作 nn.ModuleList对象
:param conf_extractor: 进行预测置信度参数的卷积操作 nn.ModuleList对象
:return: 返回一个三维张量,[batch,4/21,...] 第三维是所有default box 的个数8732
"""
locs = []
confs = []
# l(f) : batch,框个数*4,high,width c(f) : batch,框个数*21,high,width
for f, l, c in zip(features, loc_extractor, conf_extractor):
# [batch, n*4, feat_size, feat_size] -> [batch, 4, -1]
locs.append(l(f).view(f.size(0), 4, -1))
# [batch, n*classes, feat_size, feat_size] -> [batch, classes, -1]
confs.append(c(f).view(f.size(0), self.num_classes, -1))
# contiguous() 确保张量是在连续内存中存储 ,连续存储的格式
# cat操作将 locs, conf 列表第三维数据进行拼接
locs, confs = torch.cat(locs, 2).contiguous(), torch.cat(confs, 2).contiguous()
return locs, confs如果是训练模式下就计算其损失,如果不是训练模式 就进行预处理得到最终的结果















 6137
6137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









