







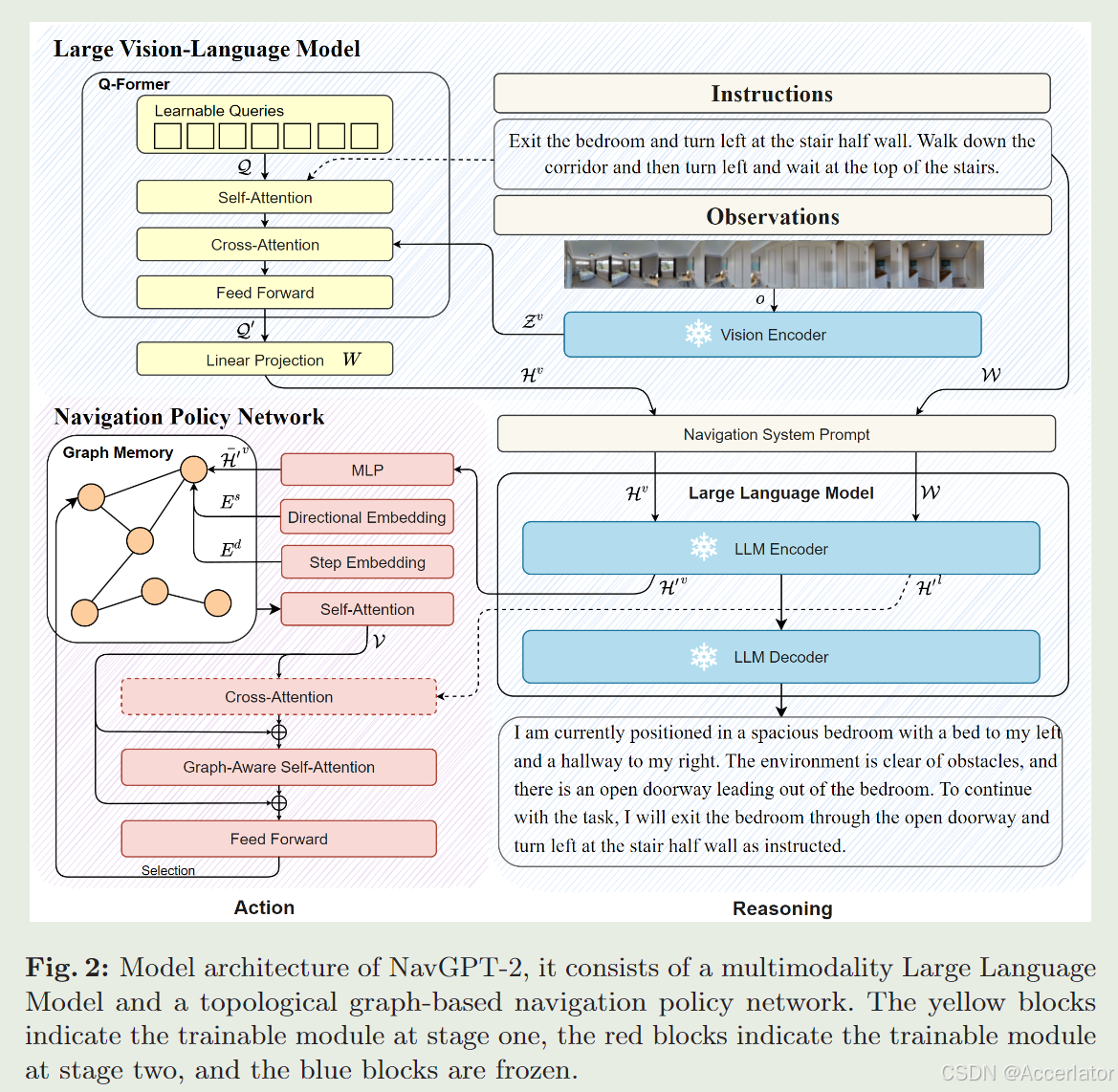
主要贡献
1.将之前专门在视觉语言导航上面训练的专家模型和大语言模型结合起来,利用了大语言模型的推理能力(专家模型是图里面红色的那个部分,是之前的 DUET ,在视觉语言导航里是一个很有名的模型)。2.利用了预训练过的视觉语言模型(VLM)(图中的黄色部分),这里面用的是 InstructBlip,将它与后面的大语言模型通过微调进行模态对齐。
针对大语言模型的不同模态对齐策略
这部分是在 Related Works 中提到的,相当于你现在想让大语言模型能够接受视觉信息作为输入,在大语言模型中划分出一定的 token 来表征视觉输入。目前有两种做法,第一种是训练视觉采样器,例如 InstructBlip,Qwen-VL,MiniGPT 等模型。第二种是直接采用一个全连接层将视觉编码器的输出映射到 LLM 的 token 上,LLAVA,MiniGPT-V2 都采用了这种方法。

这篇文章就做了这样的一件事,将候选点的视觉输入映射成了 image_tokens,来输入给大模型。
训练策略
这个模型的训练分两个部分,第一个阶段:训练视觉编码器即黄色部分和大语言模型对齐,第二个阶段:训练红色部分,即导航策略网络。
第一个阶段
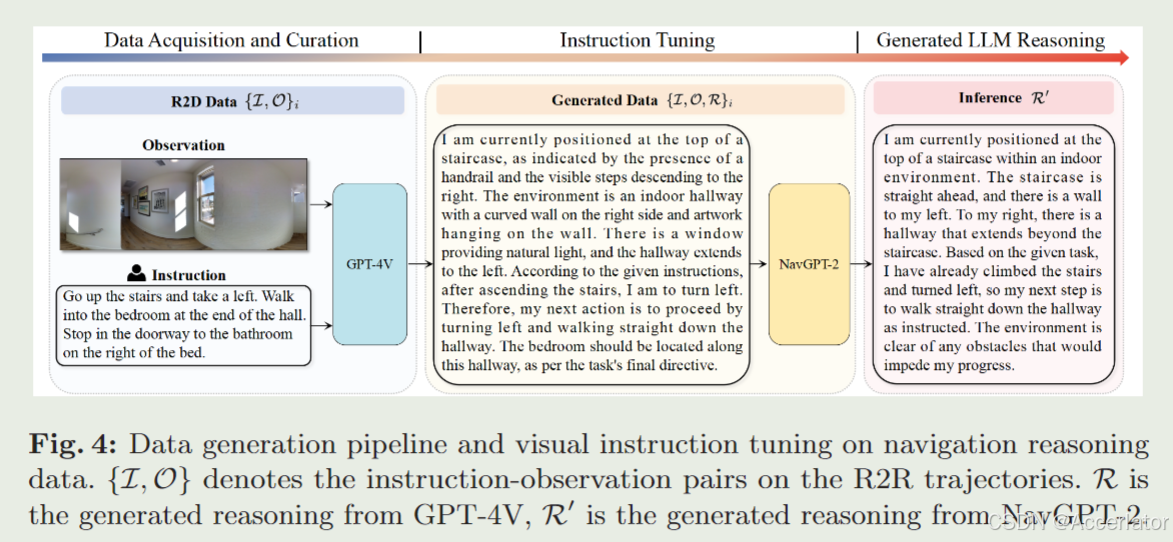
首先作者丢弃了一条轨迹中的历史信息,比如说一条导航轨迹是 A-B-C-D-E,这里作者只把 C拿出来,A,B,D,E 都不要了,然后丢给GPT-4v,要求它生成和导航有关的推理,然后拿着这个推理过程去训练 VLM 和 LLM,也就是图中的黄色和蓝色部分,要注意,此时蓝色大语言模型是冻结住的,不会参与训练。
第二个阶段
第二个阶段冻结住黄色和蓝色部分,仅仅在完整导航数据集上微调红色部分,也就是导航策略部分。

















 167
167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









