






-
Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation
-
使用使单语言句子嵌入多语言
句子嵌入是将一个句子转换为向量表示的过程,使得这个向量能够捕捉句子的语义信息。
Abstract
我们提出了一种简单而有效的方法,将现有的句子嵌入模型扩展到新的语言。这允许从以前的单语言模型中创建多语言版本。
训练是基于这样的想法:一个翻译的句子应该被映射到向量空间中与原句相同的位置。我们使用原始(单语)模型来生成源语言的句子嵌入,然后在翻译的句子上训练一个新系统来模仿原始模型。
与其他训练多语言句子嵌入的方法相比,这种方法有几个优点: 它很容易用相对较少的样本将现有的模型扩展到新的语言,更容易确保向量空间的理想属性,而且训练的硬件要求也较低。我们证明了我们的方法对不同语言家族的50多种语言的有效性。将句子嵌入模型扩展到400多种语言的代码是公开可用的。
1.Introduction
将句子或短文段落映射到一个密集的向量空间,使类似的句子接近,在NLP中有着广泛的应用。然而,大多数现有的句子嵌入模型是单语种的,通常只适用于英语,因为适用于其他语言的训练数据非常少。对于多语言和跨语言的情况,只有少数句子嵌入模型存在。
在这份出版物中,我们提出了一种新方法(基于知识蒸馏的多语言sentence embedding的训练方式),使我们能够将现有的句子嵌入模型扩展到新的语言。
我们需要一个源语言s的teacher模型M和一组平行(翻译)句子((s1;t1);::;(sn;tn)),ti是si的翻译。注意,ti可以是不同的语言。我们训练一个新的student模型M,
训练准则:
使用均方误差函数MSE。我们称这种方法为多语言知识蒸馏(multilingual knowledge distillation ),因为学生^M在多语言设置中提炼了教师M的知识。
我们证明,这种训练方式适用于各种语言组合以及多语言设置。我们观察到,与LASER相比,低资源语言的准确性提高了40个百分点。
给出平行数据(如英语和德语),训练学生模型,使产生的英语和德语句子向量与教师的英语句子向量接近。
student模型^M学习了一个具有两个重要属性的多语言句子嵌入空间:
1)向量空间在不同语言之间是一致的,即不同语言中的相同句子是接近的,
2)teacher模型M的原始源语言的向量空间属性被采用并转移到其他语言。
与其他多语言句子嵌入的训练方法相比,所提出的方法具有各种优势。
LASER(Artetxe和Schwenk,2019b)使用翻译任务训练一个编码器-解码器LSTM模型。编码器的输出被用作句子嵌入。虽然LASER在识别不同语言的准确翻译方面效果很好,但它在评估非精确翻译的句子的相似性方面效果较差。
Multilingual Universal Sentence Encoder(mUSE多语言通用句子编码器)在SNLI和来自流行的在线论坛和QA网站的超过10亿个问题-答案对的多任务设置中进行训练。为了对齐跨语言向量空间,mUSE使用了一个翻译排名任务(translation ranking task)。给定一个翻译对(si; ti)和各种备选(不正确)的翻译,确定正确的翻译。
弊端:1)多任务学习是困难的,因为它可能受到灾难性遗忘的影响,而且平衡多个任务也不是简单的。2)运行translation ranking task是复杂的,导致巨大的计算开销。选择随机的替代翻译通常会导致平庸的结果。
相反,需要硬否定词-hard negatives(Guo等人,2018),即与正确翻译有高度相似性的替代错误翻译。为了获得这些硬否定句,首先用随机否定句样本训练mUSE,然后,这个初步的句子编码器被用来识别硬否定句的例子。然后,他们重新训练了网络。
在这篇文章中,我们采用了Sentence-BERT(SBERT)——目前在各类句子嵌入任务中取得了最佳效果。SBERT是基于transformer模型像BERT并且在输出应用均值池(?)
采用XLM-R,一个在100种语言上预训练的网络,作为student模型。
注意,描述的这个方法,没有局限于只使用translation模型,也会使用其他网络架构进行工作。
2.Training
需要一个teacher模型M,可以将一种或多种源语言s映射到一个稠密的向量空间。然后,我们需要平行(经过翻译)的句子((s1,t1),……,(sn,tn))si是源语言中的一个句子,ti是目标语言中的一个句子。
训练学生模型的方式:
对于给定的batch,最小化均方方差损失函数
^M可以有teacher模型M的构架和权重,或者可以是一个不同网络架构
这个训练的流程如图1所示:

用^M<—M表示:已从teacher模型M学习到相应的句子embeding知识的student模型 ^ M 在我们的实验中,主要使用英语SBERT模型作为teacher模型M,使用XLM-R作为学生模型^M。英语BERT模型的词汇量为30k,只要由英语令牌组成。使用英语SBERT模型作为^M的初始化不是最优的,因为其他基于拉丁语系的语言中的大多数单词将被分解为短的字符序列,而非拉丁语系字母的单词将被映射到UNK标记。相比之下,XLM-R使用SentencePiece2,它避免了特定语言的预处理。此外,它还使用了来自100种不同语言的25万个条目的词汇表。这使得XLM-R更适合用于多语言学生模型的初始化。
3.Training Data
在本节中,我们评估了训练数据对于使句子嵌入模型成为多语言的重要性。OPUS网站3(Tiedemann,2012)提供了数百种语言对的平行数据。在我们的实验中,我们使用了以下数据集:
-
GlobalVoices:A parallel corpus of news stories from the website Global Voices.
-
TED2020:We crawled the translated subtitles for about 4,000 TED talks, available in over 100 languages. This dataset is available in our repository.
-
NewsCommentary: Political and economic commentary crawled from the web site Project Syndicate, provided by WMT.
-
WikiMatrix: Mined parallel sentences from Wikipedia in different languages (Schwenk et al., 2019). We only used pairs with scores above 1.05, as pairs below this threshold were often of bad quality.
-
Tatoeba: Tatoeba4 is a large database of example sentences and translations to support language learning.
-
Europarl: Parallel sentences extracted from the European Parliament website (Koehn, 2005).
-
JW300: Mined, parallel sentences from the magazines Awake! and Watchtower (Agi´c and Vuli´c, 2019).
-
OpenSubtitles2018: Translated movie subtitles from opensubtitles.org (Lison and Tiedemann, 2016).
-
UNPC: Manually translated United Nations documents from 1994 - 2014 (Ziemski et al.,2016).
获得平行的句子数据对于资源匮乏的语言对。因此,我们尝试使用双语字典。
-
MUSE: MUSE5 provides 110 large-scale ground-truth bilingual dictionaries created by an internal translation tool (Conneau et al., 2017b).
-
Wikititles: We use the Wikipedia database dumps to extract the article titles from crosslanguage links between Wikipedia articles. For example, the page ”United States” links to the German page ”Vereinigte Staaten”. This gives a dictionary covering a wide range of topics.
英德(EN-DE)和英阿(EN-AR)的数据集大小如表5所示。在训练中,我们通过从每个数据集中抽取大致相同数量的样本来平衡数据集的大小。来自较小数据集的数据被重复使用。
我们训练XLM-R作为student模型,并使用在英语NLI和STS数据6上微调的SBERT作为我们的teacher模型。
训练参数:
-
epochs:最大20
-
batch size:64
-
warm-up steps:10,000
-
learning rate:2e-5
-
MSE loss
在(Reimers and Gurevych, 2017, 2018)中,我们表明随机种子对训练好的模型的性能有很大的影响,特别是对于小数据集。在下面的实验中,我们有相当大的数据集,多达几百万的平行句子,我们观察到随机种子之间的差异相当小(0.3分)。
4 Experiments
在本节中,我们对三个任务进行了实验: 多语言和跨语言的语义文本相似性(STS)、bitext retrieval(咬文检索)和跨语言相似性搜索。STS为一对句子分配分数,而咬文检索则从两个大的单语语料库中找出平行(翻译)的句子。
注意,评估不同策略在不同语言间对齐向量空间的能力是不容易的。跨语言任务的性能取决于将不同语言的句子映射到一个向量空间(通常是英语的向量空间)的能力,以及这个源向量空间的属性。性能上的差异可能是由于语言之间更好或更差的对齐,或者由于(源)向量空间的不同属性。
我们评估了以下系统:
-
SBERT-nli-stsb:BERT-base模型的输出与均值集合相结合,形成一个固定大小的句子表示(Reimers和Gurevych,2019)。它在英语AllNLI(SNLI(Bowman等人,2015)和Multi-NLI(Williams等人,2018))数据集和STS基准(Ceret al.,2017)的英语训练集上使用连体网络结构进行微调。
-
mBERT / XLM-R mean: 预先训练的多语言BERT(mBERT)和XLM-R模型的平均输出汇集。这些模型在多语言数据上进行了预训练,并有一个多语言词汇表。然而,没有使用平行数据。
-
mBERT- / XLM-R-nli-stsb: 我们微调了 XLM-R和mBERT在(英文)AllNLI和 STS基准的(英文)训练集进行微调。
-
LASER:LASER(Artetxe和Schwenk,2019b)在一个堆叠的LSTM编码器的输出上使用最大集合。该编码器是在93种语言的平行语料库上进行编码-解码器设置(机器翻译设置)训练的。
-
mUSE: 多语言通用句子编码器(Chidambaram等人,2019年)使用了双编码器转换结构,并在挖掘的问答对、SNLI数据、翻译的SNLI数据以及16种语言的平行语料库上进行训练。
-
LaBSE: 语言无关的BERT句子嵌入(LaBSE)(Feng等人,2020)与mUSE类似,采用基于BERT的双编码器转化器架构,对109种语言的60亿个翻译对进行训练。
-
mBERT- / DistilmBERT- / XLM-R <- SBERT-nli-stsb: 我们学习mBERT DistilmBERT和XLM-R来模仿英语SBERT-nli-stsb模型的输出。
-
XLM-R SBERT-paraphrases: 我们训练XLM-R来模仿SBERT-paraphrases,这是一个在超过5000万个英语释义对上训练的RoBERTa模型。
对于我们的多语言知识提炼实验,我们用50种语言的平行(经过翻译的)数据训练了一个单一模型。
4.1 Multilingual Semantic Textual Similarity()
语义文本相似性STS的任务是为一对句子分配一个表示其语义相似性的分数。例如,0分表示没有关系,5分表示语义上相等。
数据集:multilingual STS 2017 数据集包含EN-EN、AR-AR、ES-ES、EN-AR、EN-ES和EN-TR的注释对。本文通过将EN-EN数据集中的每对句子翻译成德语来扩展这个数据集。此外,我们使用谷歌翻译来创建数据集EN-FR、EN-IT和EN-NL。并由人工审查翻译结果。
sentence embedding 用余弦相似度衡量,使用斯皮尔曼相关系数ρ(Spearman`s rank correlation)来评估模型输出score和给定的标签score之间的差异。(在作者提供的sentence-transformer的代码中,其实还用Pearson相关系数进行评估)
实验结果:通过实验表格可以看出,经过知识蒸馏的的student模型效果取得明显的提升:
表1展示单语言,表2展示跨语言

实验分析:
-
不进行微调的mBERT 和 XLM-R模型,性能都很差。经过在English NLI&STS数据上微调训练后(mBERT/XLM-nli-stsb)性能明显提升。
-
在单语言设置中(表1)这些模型表现都很出色,但我们观察到在跨语言设置(表2)的性能明显下降。说明在跨语言向量空间没有很好地对齐
-
但用跨语言知识蒸馏处理后性能明显提升,大大超过了其他最先进的模型LASER、mUSE、LaBSE。
-
尽管SBERTnli-stsb是在STS基准训练集上训练的,但我们观察到SBERT-paraphrase的表现最好,它没有经过任何STS数据集的训练。相反,它是在一个主要来自维基百科的庞大而广泛的转述语料库上训练的,该语料库可以很好地适用于各种主题。
-
经过知识蒸馏,XLM-R比mBERT和DistilmBERT表现得更出色。mBERT和DistilmBERT使用不同的特定语言的标记工具,使这些模型更难以用于原始文本。相比之下,XLM-R使用一个Sentence Piece模型,可以直接应用于所有语言的原始文本数据。因此,在下面的实验中,我们只报告XLM-R的结果。
4.2 BUCC:Bitext Retrieval 双语言文本检索
Bitext Retrieval任务应该就是从两个不同语言的语料库中,找出语义一样的两个(即互为翻译)进行配对
Guo等人(2018)表明,计算所有句子嵌入的余弦相似度并使用带有阈值的近邻检索有一定问题。
使用来自LASER8的BUCCBitext Retrieval检索代码和Artetxe和Schwenk(2019a)的评分函数:
x;y是两个句子的嵌入,NNk(x)表示x在另一种语言中的k个最近的邻居。作为余量函数,我们使用 margin(a; b) = a/b。
数据集: the BUCC mining task
实验结果:
使用F1 score进行评估:
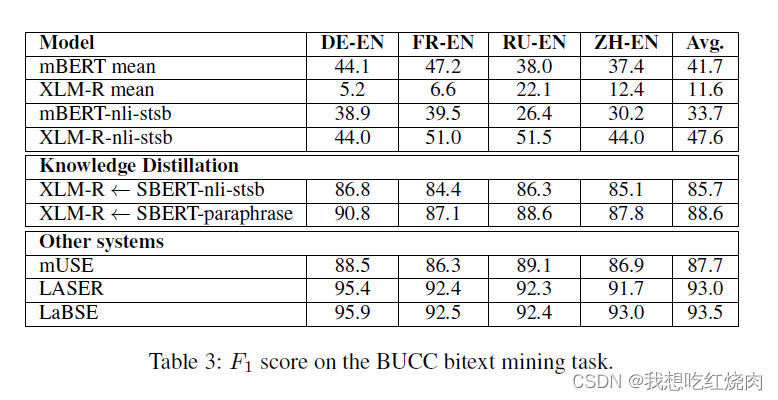
实验分析:
-
使用mean pooling的mBERT/XML-R模型,表现很差
-
使用English NLI and STS数据进行微调 XLM-R 模型,实验结果分数反而更差了。目前还不知道是什么原因
-
mBERT 和 XML-R 模型表现较差,还有由于他们仅在 English data 上进行train,向量空间没有很好的对齐。
-
经过知识蒸馏的 XML-R 模型效果提升非常明显。
-
比较有意思的是,LASER和LaBSE 模型的表现比该文的模型还要好一些(自圆其说:LASER和LaBSE模型可以很好地识别不同语言的准确翻译,但是它在评估不是精确翻译的句子的相似性方面表现较差)
4.3 相似搜索 Tatoeba:Similarity Search
本节评估 low resource languages,在这种场景获得向量空间对齐的embedding 非常具有挑战性。
任务:给定一个句子,从其他语言的所有句子中,找出最相似的一个句子。
数据集:Tatoeba作为 test set ,在JW300上训练。
评估方式:基于余弦相似度为所有句子找到另一种语言的句子中最相似的那句。计算两个方向的准确性(从英语到另一种语言再返回)。

实验还发现,即使是XLM-R模型之前未预训练的语言,经过蒸馏后,也取得了较高的准确率,作者得出结论:蒸馏策略也可很好的应用于语料资源较少的语言上。
5 Evaluation of Training Datasets
为了评估不同训练集的适用性,本文训练了 English-German 和 English-Arabic 的双语言 XML-R 模型。
多语言诅咒:在模型容量保持不变的情况下,向模型中添加更多语言可能会降低性能
英语和德语非常相似,字母表有很大的重叠,但英语和阿拉伯语是完全不同的语言,具有不同的字母表。
评估数据集:STS 2017 dataset
实验结果
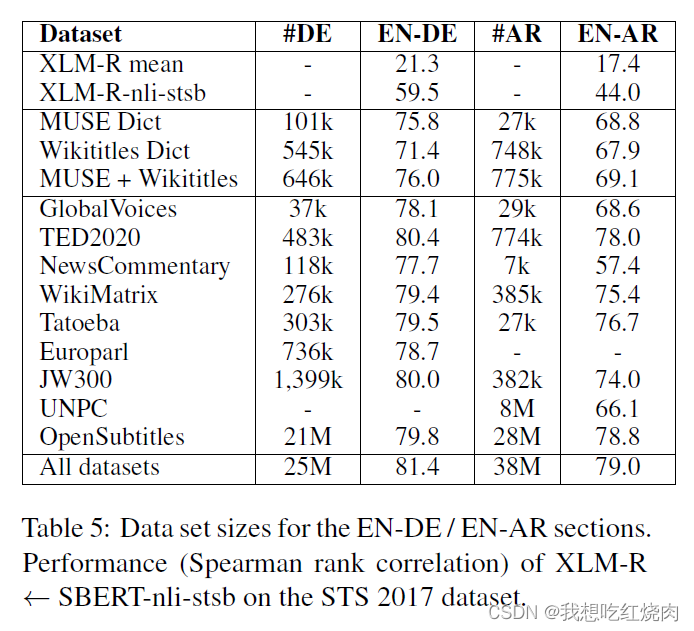

实验分析:
-
Table 6 只在 TED2020 前 k 个 sentences 上训练,k 分别为 1k~25k
-
语言模型的测试效果比10种语言模型的测试效果好一点。分析其原因可能是因为模型的容量是固定的,因此使得模型记忆更多语言会降低性能。
-
从表格可以看出,更多数据的数据集并不一定会带来更好的结果。
6 Target Language Training 目标语言训练
之前的模型都是基于英文预训练模型,这一节评估了将基于英语模型迁移到特定目标语言和在特定目标语言上合适的数据集直接训练哪种方案会取得更好的结果。
数据集:KorNLI 和 KorSTS,(这些数据集是将SNLI,Multi NLI,STS benchmark等英文数据集通过翻译转化为朝鲜语得到的)
实验结果:

实验结果证明,只有一小部分效果提升。因此,之前使用多语言的知识蒸馏方式其实就能取得较为不错的效果,并且通过这种方式能同时学习到两种语言的对齐向量空间。
7. Language Bias 语言偏见
语言偏见:A model prefers one language or language pair over others。
例如:如果一个模型仅仅因为两个句子的语言相同就在向量空间中更接近,那么它就有语言偏见。
在单语言模型上,出现模型偏见现象并不会产生什么影响,但是在多语言模型上,如果模型的语言偏见现象较为严重的话,会严重导致不同的语言在向量空间中无法对齐。
没有语言偏见的模型在多语言的数据集上的测试性能应与各单语言的数据集平均性能相近。
然而,如果一个模型有语言偏见,来自特定语言组合的句子对将比其他语言组合的排名高,从而降低了联合集的Spearman等级相关度。
第四节中只用了单语言句子库,因此这些基准不适合衡量语言偏见的潜在影响。
因此,本文做了一些相关的实验,将多语言STS数据集的句子对组合起来计算相似度得分。实验结果如下:

由结果可以看出,LASER 和 LaBSE 模型语言偏见现象较明显,在单语言测试集和多语言测试集上评估分数相差较大,mUSE和本文提出的知识蒸馏模型的语言偏见影响较小。
图2显示了不同的多语言句子嵌入方法的前两个原则成分图。
该图显示了LaBSE模型受语言偏见影响较大,在两种语言之间的急剧分离(图中两个颜色点分散聚成两个不同的堆。),表明语言极大地影响了所产生的嵌入向量。

8 Related Work
9 Conclusion
本文提出一种可以让单语言的句嵌入在多语言之间实现向量空间的对齐的方法:多语言知识蒸馏 multilingual knowledge distillation。本文方法成功地将 properties 从源语言向量空间(本文中是英语)迁移到各种目标语言。在相同的训练过程中,模型可以扩展到多种语言。
这种逐步(stepwise)训练方法的优点是,可以首先为资源丰富的语言创建具有所需 properties 的嵌入模型,例如用于聚类的嵌入模型。然后,在独立的步骤中,扩展它以支持更多的语言。与以前的方法相比,这种解耦极大地简化了训练过程。此外,它最大限度地减少了结果模型的潜在语言偏见。
词嵌入:
-
将单词表示为语义上有意义的密集实值向量
-
这解决了简单的one-hot编码的许多问题
-
最重要的是,词嵌入可提高几乎任何 NLP 问题的通用化和性能,尤其是在没有太多的培训数据时
文章提出知识蒸馏的方法,其实没有很具体的实现,主要是对方法的各方面性能进行评估















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









