







李沐深度学习笔记———NiN,GoogLeNet,ResNet
文章目录
前言
本文为jjw对李沐大神所讲NiN,GoogLeNet,ResNet网络的理解以及笔记。
一、NiN网络
1.前言
由于全连接层所需的参数个数太多,花销太大。所以有人提出使用1×1的卷积网络来替换全连接层,这样就引入了NiN网络。
2.网络架构图
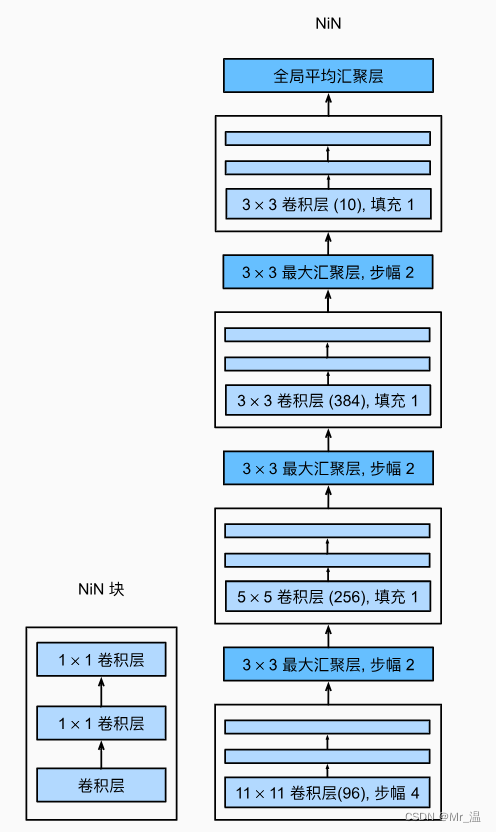
首先NiN网络是由4个NiN块组成的,每个块由一个卷积和两个1×1的卷积组成(将其通道数扩大),然后经过一个MaxPool层(将其宽高减半),最后接一个AdaptiveAvgPool2d层将每个通道求平均数,按通道的维度累加在一起。有多少类别就输出多少通道数。
3.代码实现
1.NiN块的实现
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1), nn.ReLU())
2.NiN 网络的实现
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2),
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3, stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3, stride=2),
nn.Dropout(0.5),
# 标签类别数是10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1, 1)),
# 这个层将原来的输出 转变为 1*通道数*1*1的形状
# 将四维的输出转成二维的输出,其形状为(批量大小,10)
nn.Flatten())
4.总结
NiN使用由一个卷积层和多个1×1卷积层组成的块。该块可以在卷积神经网络中使用,以允许更多的每像素非线性。
NiN去除了容易造成过拟合的全连接层,将它们替换为全局平均汇聚层(即在所有位置上进行求和)。该汇聚层通道数量为所需的输出数量(例如,Fashion-MNIST的输出为10)。
移除全连接层可减少过拟合,同时显著减少NiN的参数。
NiN的设计影响了许多后续卷积神经网络的设计。
二、GoogLeNet
1.前言
在2014年的ImageNet图像识别挑战赛中,一个名叫GoogLeNet的网络架构大放异彩。 GoogLeNet吸收了NiN中串联网络的思想,并在此基础上做了改进。 这篇论文的一个重点是解决了什么样大小的卷积核最合适的问题。
2.网络架构图
1.卷积块 Inception块
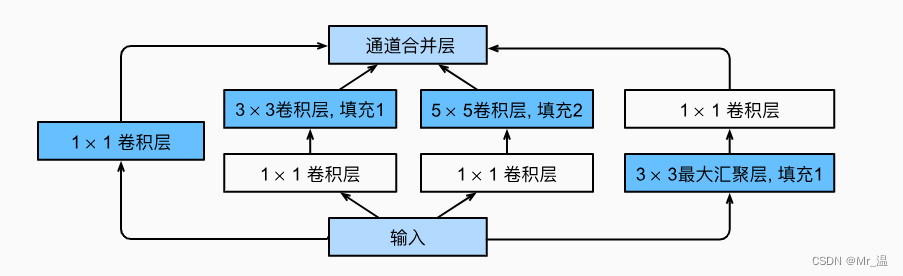
一个卷积块包含了四个分支。
- 直接使用1×1卷积将其通道数降低
- 先经过一个1×1的卷积将其通道数降低,然后经过3×3的卷积去学习特征
- 先经过一个1×1的卷积将其通道数降低,然后经过5×5的卷积去学习特征
- 先使用一个MaxPool层,再使用1×1的卷积
值得一提的是,这个Inception块并没有改变输入数据的高宽,最后我们将每条线路的输出在通道维度上连结,并构成Inception块的输出。
2.网络整体模型
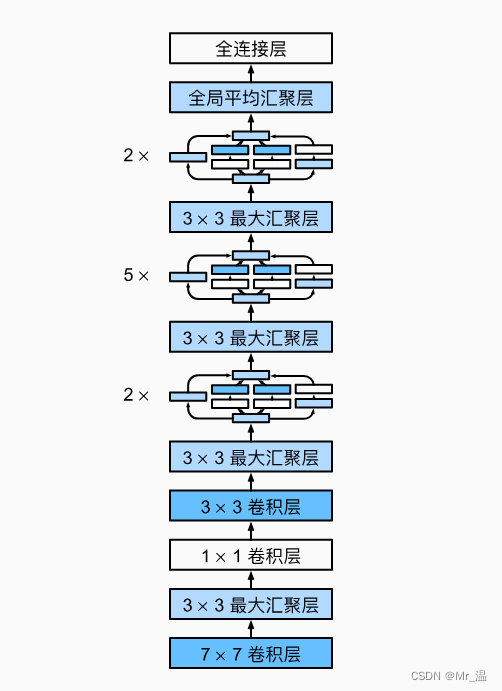
它用了7个Inception块,输出完跟一个MaxPool层减少高宽。
3.代码实现
1.Inception块
class Inception(nn.Module):
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1x1卷积层后接5x5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3x3最大汇聚层后接1x1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道维度上连结输出
return torch.cat((p1, p2, p3, p4), dim=1)
最后将其按通道的维度叠加起来,使用torch.cat
2.完整网络
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
其中b3,b4,b5,分别就是使用了Inception的三个块
4.总结
Inception块相当于一个有4条路径的子网络。它通过不同窗口形状的卷积层和最大汇聚层来并行抽取信息,并使用
卷积层减少每像素级别上的通道维数从而降低模型复杂度。
GoogLeNet将多个设计精细的Inception块与其他层(卷积层、全连接层)串联起来。其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得来的。
GoogLeNet和它的后继者们一度是ImageNet上最有效的模型之一:它以较低的计算复杂度提供了类似的测试精度。
但是这种方法可以会让模型学到一些杂质。
三、ResNet
1.前言
由于网络层越深,它越容易学到一些其他的东西(不利于精度)。
所以为了使每次加深网络不至于让其学歪,何恺明等人提出了残差网络(ResNet)。 残差网络的核心思想是:每个附加层都应该更容易地包含原始函数作为其元素之一。
2.网络架构图
1.残差快
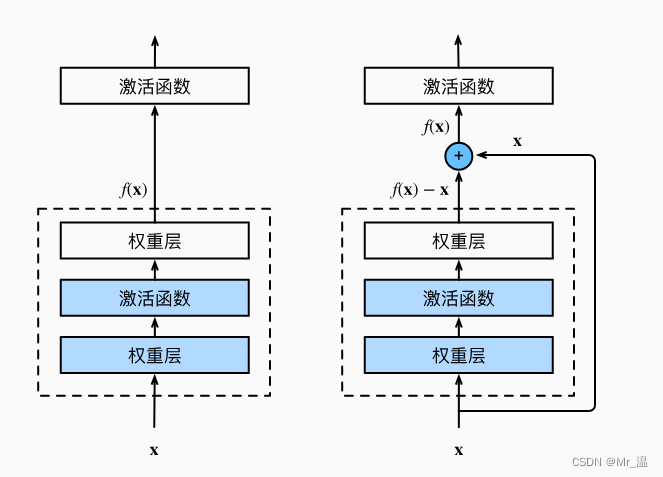
让输出的F(X) = F(X) +X
这样使梯度传播的更块,更大了。而且不至于让网络学歪。
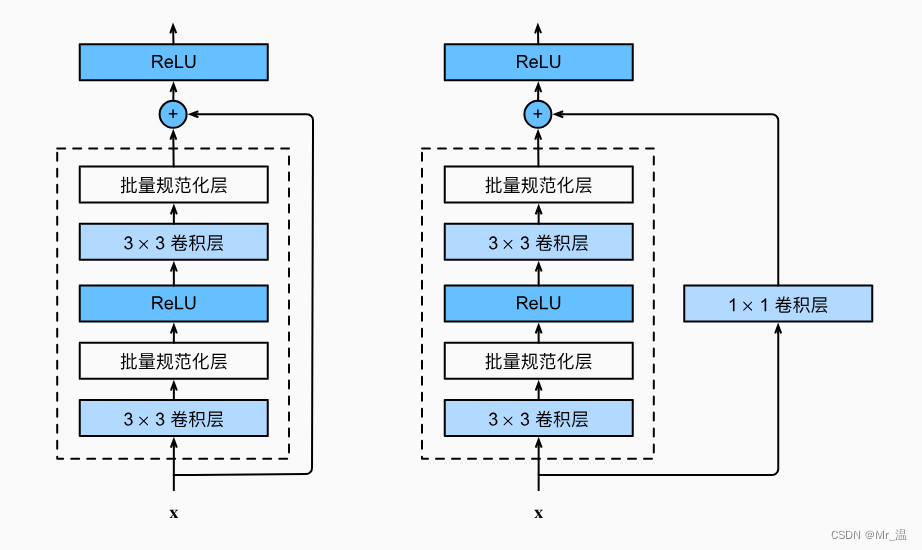
两种残差块,一种让其直接+x,另一种让输入经过1×1的卷积后再相加。
2.完整网络
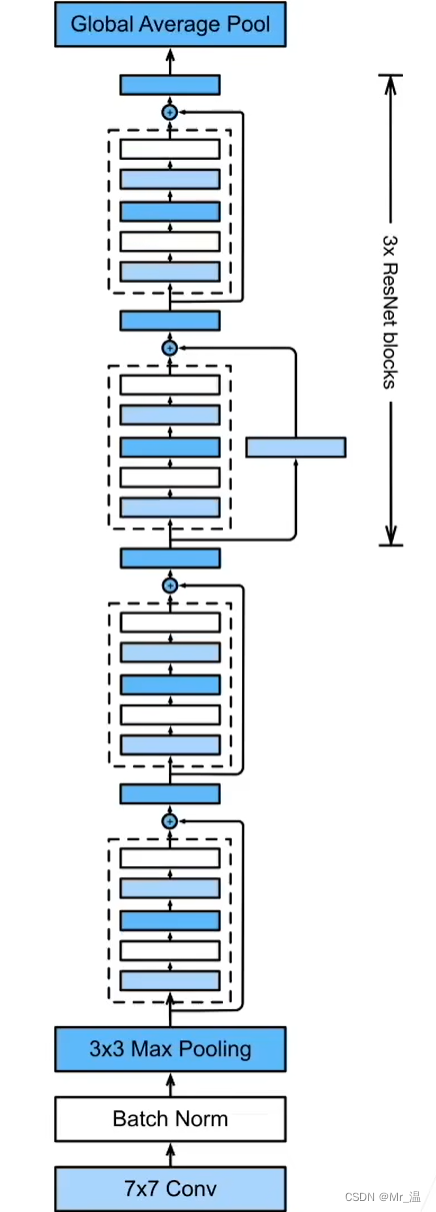
其类似于GoogLeNet,只不过是每个Inception块换为了残差块,并且每个残差块加入了批量归一化层。
3.代码实现
1.残差块
注意这里的1×1卷积是用于X的,所以conv3的第一个参数为input_channels
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,
use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
这里的first_block表示是不是为第一个使用残差块的 块。
然后除了第一个大块的其他块 每一个块的第一个残差块,都要使用对x使用1*1卷积并且让其strides=2,使高宽减半。
2.完整网络
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(), nn.Linear(512, 10))
注意对b2进行了特殊处理,这里b1已经让宽高减半了,我们不希望降的那么狠,所以将first_block置为True,使其不需要降高宽,不使用1×1卷积。
4.总结
残差映射可以更容易地学习同一函数,例如将权重层中的参数近似为零。
利用残差块(residual blocks)可以训练出一个有效的深层神经网络:输入可以通过层间的残余连接更快地向前传播。
残差网络(ResNet)对随后的深层神经网络设计产生了深远影响。
总结
以上就是今天要分享的内容,本人研0小白,有问题还望各位指正。
本文所有图片和代码都来自李沐-深度学习。















 727
727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









