



| 标 题 | iTransformer: Inverted Transformers Are Effective for Time Series Forecasting |
|---|---|
| 作 者 | Yong Liu,∗Tengge Hu,∗Haoran Zhang,∗Haixu Wu, Shiyu Wang§, Lintao Ma§, Mingsheng Long |
| 机 构 | School of Software, BNRist, Tsinghua University, Beijing 100084, China; §Ant Group, Hangzhou, China |
| 论 文 | https://arxiv.org/pdf/2310.06625 |
摘要
近期线性预测模型的兴起,引发了对基于 Transformer 的预测模型的架构修改热潮的质疑。此类模型利用 Transformer 来建模时间序列的时间令牌中的全局依赖关系,其中每个令牌由同一时间戳的多个变量组成。然而,Transformer 在处理具有较大回顾窗口的时间序列时表现不佳,性能下降且计算量急剧增加。此外,每个时间令牌的嵌入融合了多个不同变量,这些变量可能代表潜在的延迟事件和不同的物理测量,导致难以学习变量中心的表示,进而生成无意义的注意力图。在这项工作中,我们反思了 Transformer 组件的核心职责,并在不修改基本组件的情况下重新设计了 Transformer 架构。我们提出了 iTransformer,它简单地将注意力机制和前馈网络应用于倒置的维度。==具体来说,个体序列的时间点被嵌入到变量令牌中,利用注意力机制捕捉多变量之间的关联;同时,前馈网络应用于每个变量令牌以学习非线性表示。==iTransformer 模型在具有挑战性的真实数据集上达到了最新的性能,使 Transformer 家族在多变量时间序列预测任务中表现出色,并能够更好地利用任意回顾窗口,成为时间序列预测的理想基础模型。
解释:什么是时间令牌?什么是回顾窗口?什么是线性模型?
线性预测模型(Linear Forecasting Models) 是指通过线性方法对时间序列进行建模和预测的一类模型。这些模型假设输出(目标变量)与输入(历史数据)之间呈线性关系。
线性模型的典型例子
- ARIMA(自回归积分滑动平均模型)
利用时间序列的历史数据,通过线性回归和移动平均计算未来值。
- 最小二乘法(Least Squares Method)
通过历史数据拟合出最优的线性关系。
- DLinear(简单线性解耦模型)
一种新型的时间序列模型,将复杂序列分解为多个简单的线性关系来预测。

image-20241120102633941
1 引言
Transformer(Vaswani 等,2017)在自然语言处理领域和计算机视觉领域取得了巨大的成功(Brown 等,2020),并逐渐成为一个遵循扩展法则的基础模型(Kaplan 等,2020)。受其在广泛领域中巨大成功的启发,Transformer 以其强大的描述配对依赖关系和提取序列多层次表示的能力,正在时间序列预测领域崭露头角(Wu 等,2021;Nie 等,2023)。
然而,研究人员最近开始质疑基于 Transformer 的预测模型的有效性。这些模型通常将同一时间戳的多个变量嵌入到不可区分的通道中,并在这些时间令牌上应用注意力机制来捕捉时间依赖关系。考虑到时间点之间的数值关系,但缺乏语义关系,研究人员发现简单的线性层(可以追溯到统计预测模型(Box & Jenkins,1968))在性能和效率上已经超越了复杂的 Transformer(Zeng 等,2023;Das 等,2023)。同时,最近的研究通过显式建模多变量之间的相关性,进一步强调了变量独立性和相互作用的重要性,以实现准确的预测(Zhang & Yan,2023;Ekambaram 等,2023)。然而,这一目标很难在不颠覆传统 Transformer 架构的情况下实现。
显式建模(Explicit Modeling) 是一个技术术语,指的是在模型中明确设计和处理某种特定特性或关系,而不是隐含地让模型自行发现和学习。
明确处理特定问题:
显式建模强调在模型结构或训练目标中,清楚地纳入某种关系或特性,而非依赖模型自动学习。
它通常通过设计特定的模块、公式或约束,直接体现出这一特性。

image-20241120110525919
考虑到关于基于 Transformer 的预测模型的争议,我们反思了为什么 Transformer 在时间序列预测中表现得比线性模型还差,而在其他许多领域却表现卓越。我们注意到,现有的基于 Transformer 的预测模型结构可能并不适合多变量时间序列预测。如图 2 所示,显然同一时间点的多个变量代表了完全不同的物理含义,由不一致的测量记录下来,而这些点被嵌入到一个令牌中,导致多变量相关性被抹去。由一个时间点形成的令牌可能难以揭示有益的信息,因为其接收域过于局部化,且由同时的时间点表示的事件不对齐。此外,尽管序列的变化可能受到序列顺序的极大影响,但现有的 Transformer 在时间维度上采用了不变的注意力机制(Zeng 等,2023),这使得 Transformer 难以捕捉到重要的时间序列表示和多变量相关性,限制了其在多样化时间序列数据上的能力和泛化性。

image-20241120112137066
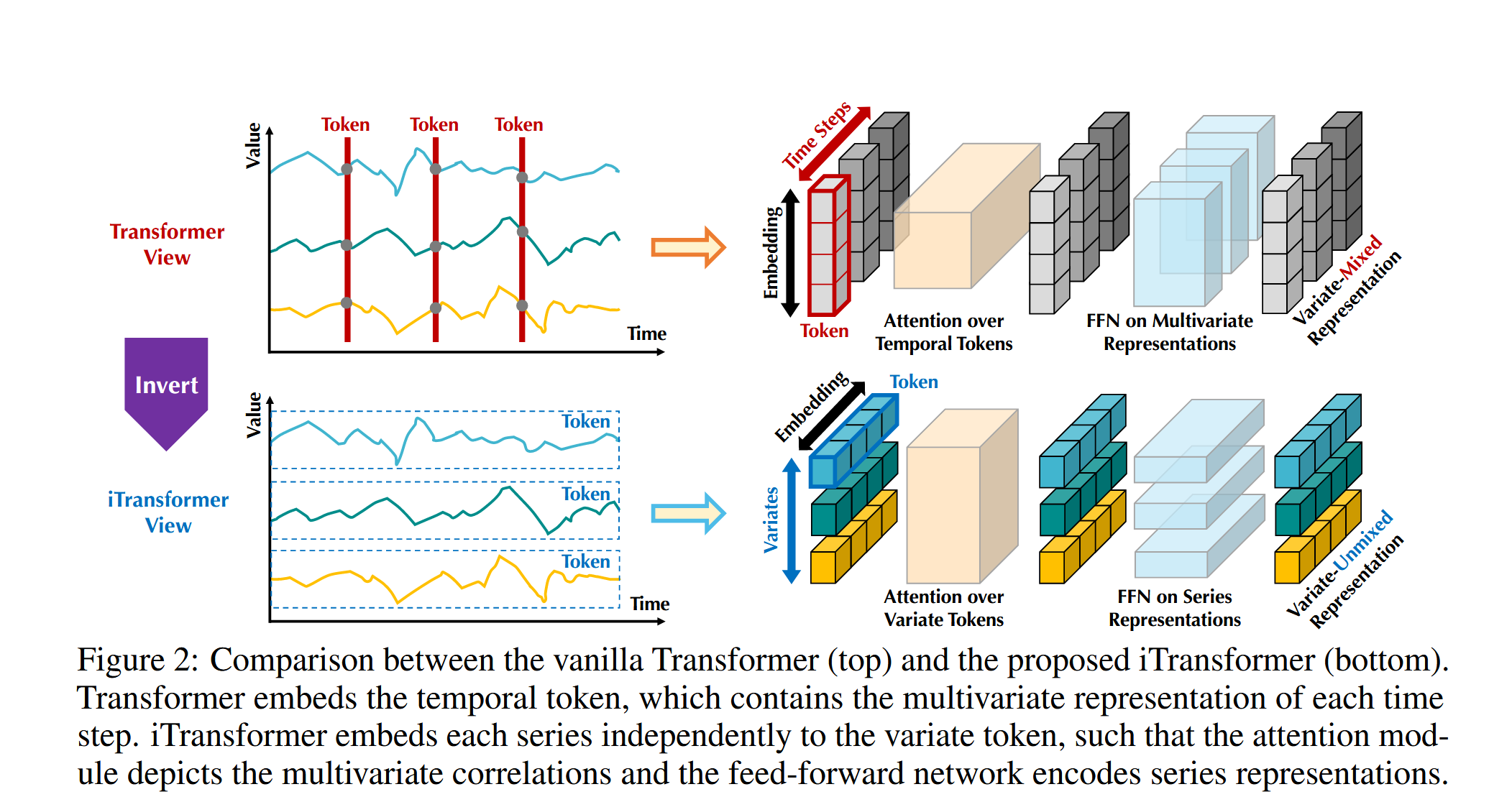
image-20241120113752010
图 2:Vanilla Transformer(上图)与建议的 iTransformer(下图)之间的比较。iTransformer 将每个序列独立嵌入到变量标记中,这样注意力模块就能描述多元相关性,而前馈网络则能编码序列表示。
针对将一个时间戳的多变量嵌入为一个(时间)令牌的潜在风险,我们采取了对时间序列的反向视角,将每个变量的整个时间序列独立嵌入为一个(变量)令牌。这是 Patching 方法的极端案例(Nie 等,2023),该方法通过扩大局部接收域,嵌入的令牌聚合了序列的全局表示,使得注意力机制可以更好地捕捉多变量关联。同时,前馈网络可以足够有效地学习从任意回顾序列编码的不同变量的可泛化表示,并解码为预测的未来序列。
编码(encoding) 是指将输入数据转化为可以被神经网络处理的格式。在时间序列问题中,输入数据(例如温度、湿度、风速等)被编码成向量或其他形式,以便于神经网络处理。解码(decoding) 是指网络根据所学到的信息,生成预测结果。在时间序列预测中,解码就是将通过前馈网络学习到的模式转化为对未来的预测。可泛化表示(generalizable representations) 指的是通过学习,模型不仅能理解当前的数据,还能对新的、不同的数据进行有效预测。例如,一个模型如果能有效地预测未来的气温,不仅能对训练数据进行预测,还能在其他气候区域、季节或其他类似的数据上保持良好的表现。
举例:假设你在训练一个天气预测模型,输入数据包括过去几天的温度、湿度和风速等变量(这些就是“不同变量”)。前馈网络会将这些历史数据(回顾序列)编码成一个向量,然后通过学习这些变量之间的关系,生成一个能够适应不同天气条件的“可泛化表示”。接着,模型将这个表示“解码”成未来几天的温度、湿度、风速等预测值。
总结:这段话的意思是,前馈网络通过有效的学习过程,能够从历史的时间序列数据中提取出有用的、能够适应不同情况的特征表示,并将这些表示转化为对未来序列的预测。
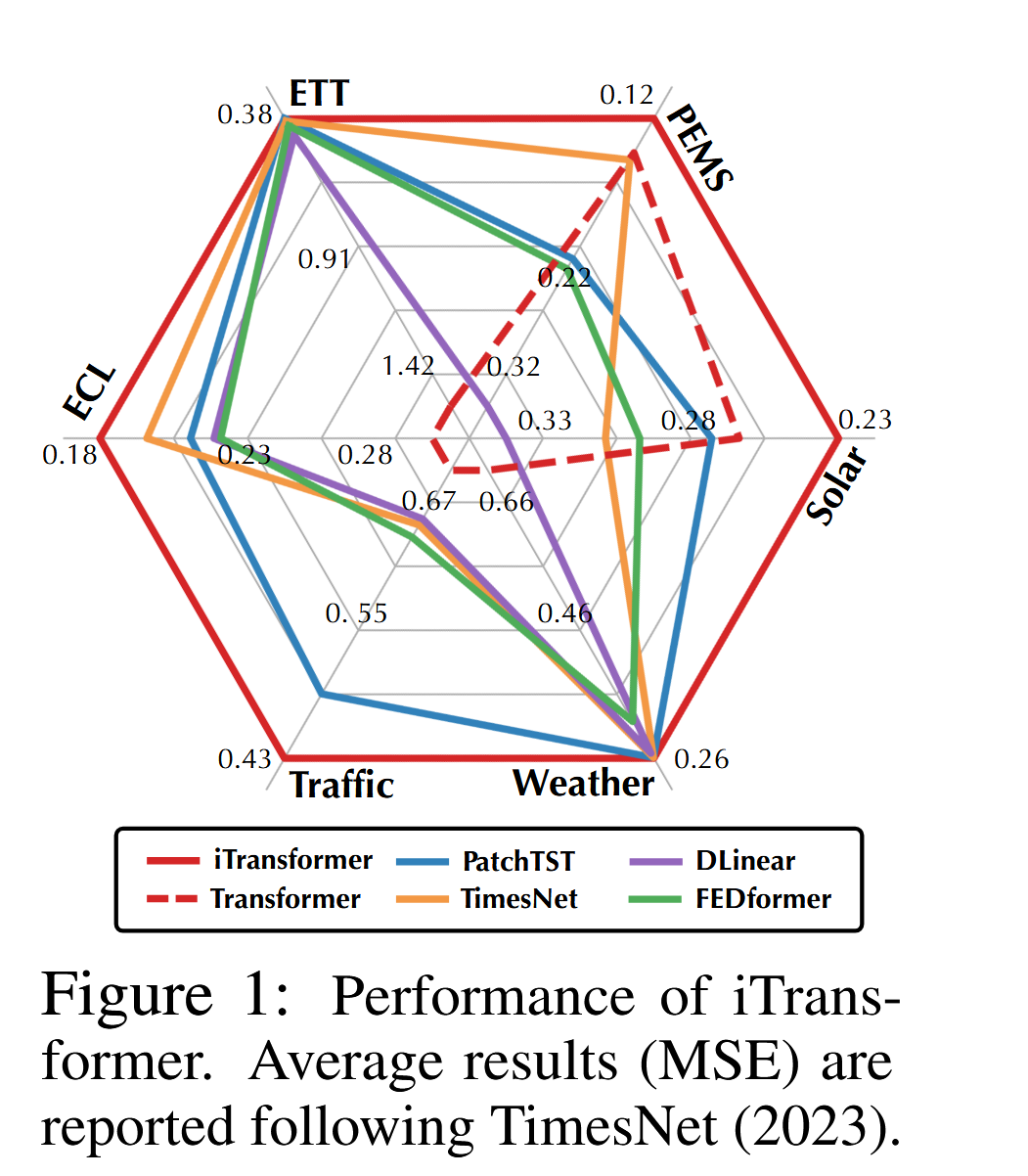
图 1:iTransformer 的性能。平均结果(MSE)按照 TimesNet (2023) 报告。
==基于以上动机,==我们认为 Transformer 在时间序列预测中并非无效,而是使用不当。在本文中,我们重新审视了 Transformer 的结构,并倡导将 iTransformer 作为时间序列预测的基础模型。技术上,我们将每个时间序列嵌入为变量令牌,采用注意力机制捕捉多变量相关性,并使用前馈网络学习序列的全局表示。通过实验证明,所提出的 iTransformer在图1所示的真实世界的预测基准上取得了最先进的性能,并且有效应对了基于 Transformer 的预测模型的痛点。我们的贡献主要体现在三个方面:
-
我们反思了 Transformer 的架构,并指出 Transformer 组件在多变量时间序列预测中的潜力尚未得到充分挖掘。
-
我们提出了 iTransformer,将独立的时间序列视为令牌,通过自注意力机制捕捉多变量相关性,并利用层归一化和前馈网络模块来学习更好的时间序列全局表示。
-
实验结果表明,iTransformer 在真实世界的基准上达到了全面的最新水平。我们广泛分析了倒置模块和架构选择,表明这是未来改进基于 Transformer 的预测模型的一个有前景的方向。
2 相关工作
随着自然语言处理和计算机视觉领域的逐步突破,精心设计的 Transformer 变体被提出来应对广泛的时间序列预测应用。超越同时代的 TCN(Bai 等,2018;Liu 等,2022a)和基于 RNN 的预测模型(Zhao 等,2017;Rangapuram 等,2018;Salinas 等,2020),Transformer 展现了强大的序列建模能力和令人期待的模型可扩展性,推动了为时间序列预测任务设计热情的修改趋势。
通过系统性地回顾基于 Transformer 的预测模型,我们总结出现有的修改可以根据是否修改组件和架构,分为四类。如图 3 所示,第一类(Wu 等,2021;Li 等,2021;Zhou 等,2022)是最常见的实践,主要关注组件的适应性,特别是用于时间依赖性建模的注意力模块和长序列的复杂性优化。然而,随着线性预测模型的快速兴起(Oreshkin 等,2019;Zeng 等,2023;Das 等,2023;Liu 等,2023),其令人印象深刻的性能和效率不断挑战这一方向。随后,第二类尝试充分利用 Transformer。它更多地关注时间序列的固有处理,如平稳化(Liu 等,2022b)、通道独立性和 Patching(Nie 等,2023),这些改进带来了持续的性能提升。此外,面对多个变量之间独立性和相互作用的重要性日益增加,第三类在组件和架构两个方面对 Transformer 进行了改造。代表性工作(Zhang & Yan,2023)通过改进的注意力机制和架构,明确捕捉跨时间和跨变量的依赖关系。
与之前的工作不同,iTransformer 没有修改 Transformer 的任何原生组件。相反,我们将组件应用于倒置的维度,并改变了架构。据我们所知,这是唯一一个属于第四类的模型。我们相信,Transformer 组件的能力已经经过广泛的验证,问题在于 Transformer 的架构在时间序列预测任务中的应用不当。
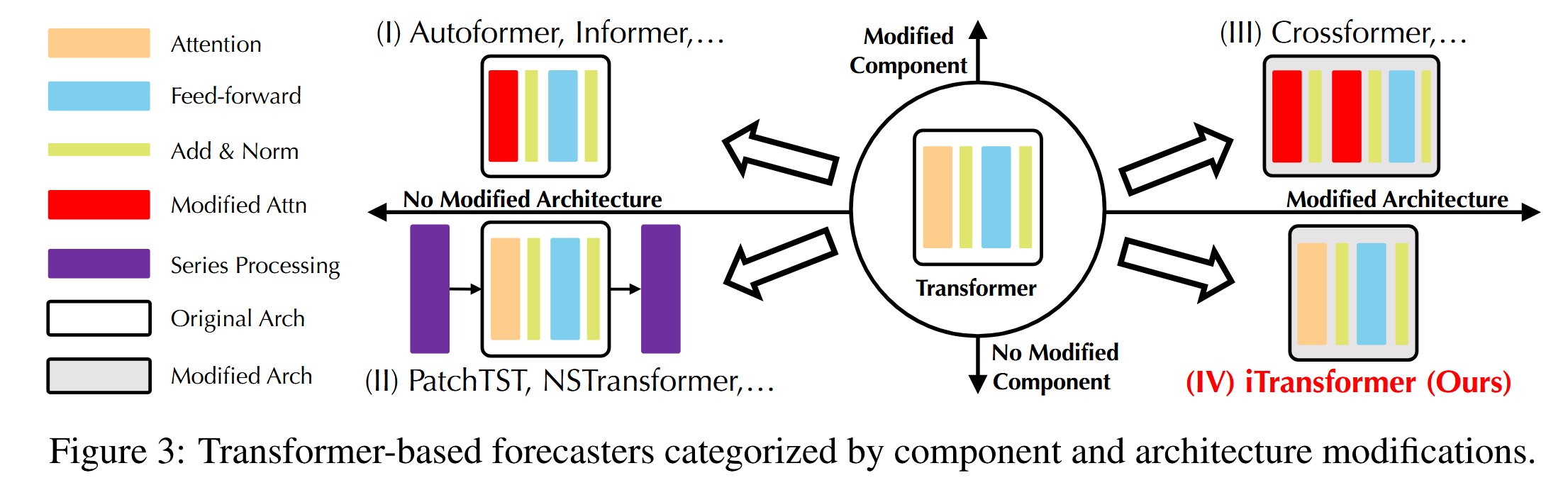
image-20241125212827244
3 iTransformer
在多变量时间序列预测中,给定历史观测值 ,其中包含 个时间步和 个变量,我们需要预测未来 个时间步的值 。为方便起见,==我们将 表示为第 ( t ) 个时间步同时记录的时间点, 表示每个变量 的整个时间序列。==值得注意的是,在实际场景中, 可能不会包含反映同一事件的时间点,因为数据集中变量之间会存在系统性时间滞后。此外, 的元素在物理测量和统计分布上可能彼此不同,而变量 通常具有一致性。

image-20241126105416965

image-20241126105457632
3.1 结构概览
如图 4 所示,所提出的 iTransformer 采用了 Transformer 的仅编码器(encoder-only)架构(Vaswani 等,2017),包括嵌入、投影和 Transformer 模块。
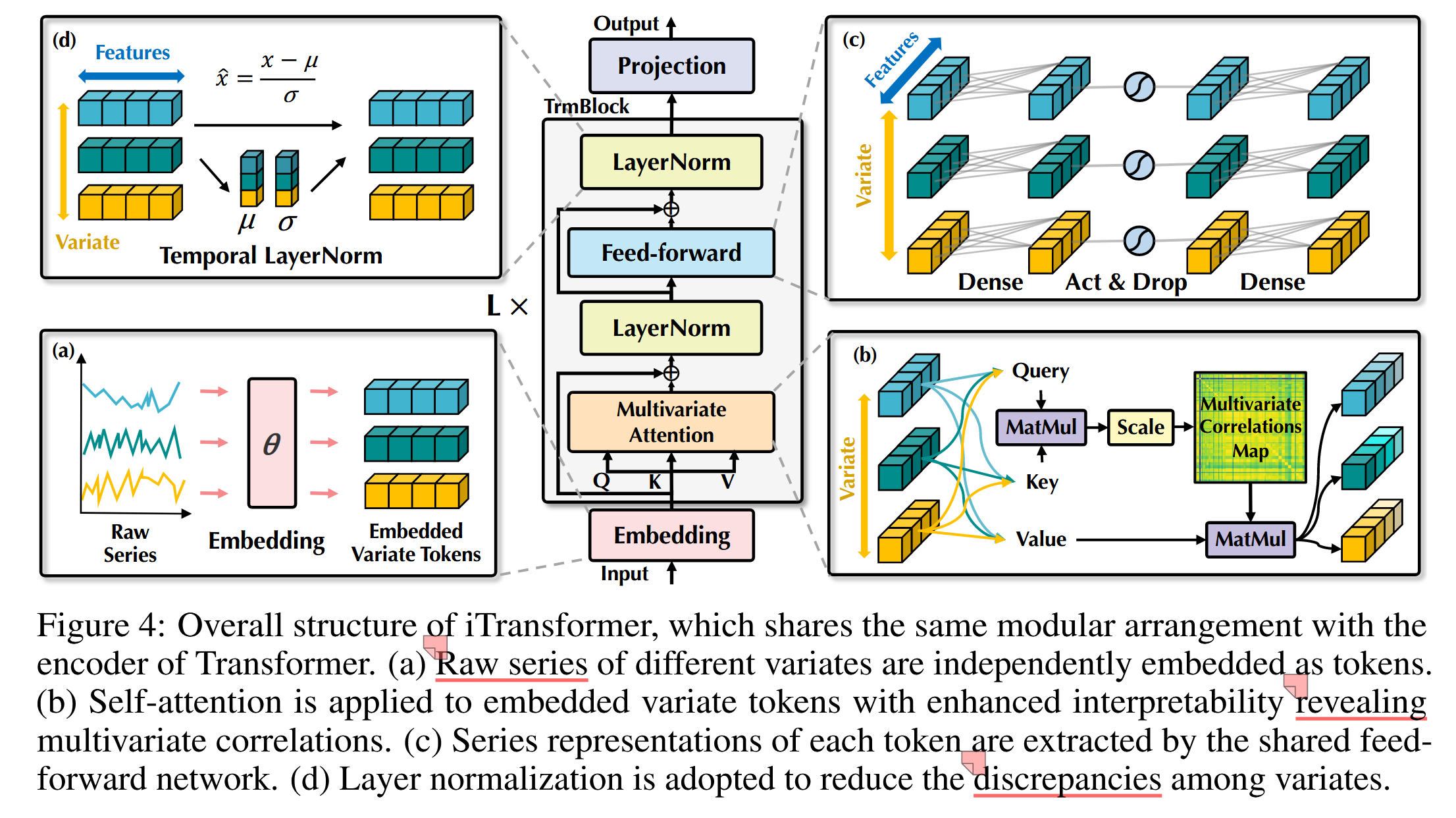
image-20241126105959140
图 4:iTransformer 的整体结构,iTransformer 的结构与 Transformer 编码器的模块化安排相同。(a) 不同变量的原始序列被独立嵌入为令牌(tokens)。(b) 在嵌入的变量令牌上应用自注意力机制(self-attention),通过增强的可解释性揭示多变量之间的相关性。 (c) 每个令牌的序列表示由共享的前馈网络(feedforward network)提取。 (d) 采用层归一化(layer normalization)以减少变量之间的差异性。
将整个序列嵌入为令牌
大多数基于 Transformer 的预测模型通常将同一时间点的多个变量视为(时间)令牌,并遵循生成式的预测任务公式。然而,我们发现这种方法在数值模式上的指导意义较小,不能有效地学习注意力图。越来越多的应用采用 Patching 方法(Dosovitskiy 等,2021;Nie 等,2023),这种方法通过扩展接收域来提升模型性能。同时,线性预测模型的成功也对采用复杂的 Transformer 编码器-解码器结构生成令牌的必要性提出了质疑。相反,我们提出的仅编码器 iTransformer 侧重于表示学习和多变量时间序列的自适应关联。每个由潜在复杂过程驱动的时间序列首先被令牌化以描述变量的特性,通过自注意力机制进行相互作用,并由前馈网络独立处理来生成序列表示。值得注意的是,生成预测序列的任务本质上交由线性层完成,这在之前的工作中已被证明是有效的(Das 等,2023),我们将在下一节中进行详细分析。
基于上述考虑,在 iTransformer 中,==基于回顾序列 预测每个特定变量的未来序列 的过程可以简单地表示为以下公式:==
其中 包含了 个维度为 的嵌入令牌,且上标 表示层索引。Embedding 函数将 映射至 ,Projection 函数将 映射至 ,它们均由多层感知机(MLP)实现。得到的变量令牌通过自注意力机制相互作用,并在每个 TrmBlock 中由共享的前馈网络独立处理。具体来说,由于序列的顺序隐含地存储在前馈网络的神经元排列中,原始 Transformer 中的位置嵌入在此不再需要。

image-20241126112918113
iTransformers
该架构本质上不对 Transformer 变体提出更多的特定要求,只要自注意力机制能够用于多变量关联即可。因此,一系列高效的注意力机制(Li 等,2021;Wu 等,2022;Dao 等,2022)可以作为插件来减少当变量数量增加时的复杂性。此外,由于注意力机制输入的灵活性,令牌数量可以从训练到推理阶段有所变化,模型允许在任意数量的变量上进行训练。我们在第 4.2 节的实验中对倒置的 Transformer(称为 iTransformers)进行了广泛评估,结果表明其在时间序列预测任务中具有明显优势。
3.2 倒置的 Transformer 组件
我们组织了一堆由层归一化、前馈网络和自注意力模块组成的 ( L ) 层堆栈,但它们在倒置维度上的任务被重新审视和仔细考虑。
层归一化
==层归一化(Ba 等,2016)最初被提出是为了提高深度网络的收敛性和训练稳定性==。在典型的基于 Transformer 的预测模型中,该模块对同一时间戳的多变量表示进行归一化,逐渐将变量彼此融合。然而,一旦收集的时间点不代表同一事件,该操作可能会引入非因果或延迟过程之间的噪声。在我们的倒置版本中,归一化应用于每个变量的系列表示,如公式 2 所示,这在处理==非平稳问题==上已被研究并证明是有效的(Kim 等,2021;Liu 等,2022b)。此外,由于所有变量令牌都被归一化为高斯分布,由不一致测量引起的差异可以减少。相比之下,在之前的架构中,不同时间步的令牌被归一化,导致时间序列过度平滑。
==总结==:非平稳问题 是时间序列分析中的一个关键概念,指时间序列的统计特性(如均值、方差、协方差)随时间变化,而不是保持恒定的状态。
传统Transformer中归一化的问题:
在之前的架构中,不同时间步的令牌被归一化,可能导致时间序列的特征被模糊化。导致时间序列过度平滑;强行将不同变量的信息混合,可能引入错误的相关性。(将同一时间戳的变量进行归一化,但是可能这些变量不是同一个时间获得。例如预测天气数据,变量包括温度、湿度和风速。湿度可能是 前一天的温度 导致的滞后反应,强行将这些变量归一化会融合它们的特征,从而引入非因果关联或噪声。)
iTransformer 的改进:
变量级归一化:每个变量的时间序列单独归一化,保留变量间的独立特性。
适应非平稳数据:变量嵌入统一为标准正态分布,减少了测量不一致带来的影响。

前馈网络
Transformer 采用前馈网络(FFN)作为编码令牌表示的基本构建块,并对每个令牌一致地应用。如前所述,在原始 Transformer 中,由同一时间戳的多个变量组成的令牌可能存在位置错位,且过于局部化,无法为预测提供足够的信息。在倒置版本中,==FFN 被用于每个变量令牌的系列表示。==根据通用逼近定理(Hornik,1991),FFN 可以提取复杂的表示来描述一个时间序列。通过倒置块的堆叠,它们专注于编码观测到的时间序列并通过密集的非线性连接解码这些表示以预测未来序列。最近完全基于 MLP 的工作(Tolstikhin 等,2021;Das 等,2023)表明了这种方法的有效性。
FFN 和 MLP 的关系
- 包含关系:前馈网络是一个更广义的概念,而 MLP 是其中的一种具体类型。
前馈网络可以有多种结构形式,比如可以包含卷积层或注意力机制。
MLP 主要关注通过全连接层和激活函数提取特征。
问题:
位置错位:不同变量(如温度和湿度)可能并非同时测量,导致时间戳内的信息不一致。强行将这些变量融合处理可能引入噪声。
过于局部化:FFN 聚焦于单个时间戳的变量嵌入,而忽略了整个时间序列的全局趋势和模式。
MLP(多层感知机):MLP 的神经元可以被看作滤波器,专注于时间序列中的特定模式,如去除噪声、捕捉趋势。
更有趣的是,独立时间序列上的相同线性操作,结合最近的线性预测模型(Zeng 等,2023)和通道独立性方法(Nie 等,2023),可以帮助我们理解序列表示。最近对线性预测模型的重新审视(Li 等,2023)强调,MLP 提取的时间特征应该在不同的时间序列之间共享。我们提出了一种合理的解释,即 MLP 的神经元被教导去描绘任何时间序列的内在属性,例如振幅、周期性,甚至频谱(即神经元作为滤波器),这使其成为比自注意力机制更有优势的预测表示学习器。我们在第 4.3 节的实验中验证了这种分工的好处,例如当提供更大的回顾序列时性能提升,以及在未见过的变量上良好的泛化能力。
在独立的时间序列上(即单变量的时间序列),线性操作可以有效提取趋势和基本模式。这些操作可以帮助理解时间序列的表示特性,例如趋势(向上或向下)或波动(稳定或不稳定)。
通道独立性是什么意思?——时间序列的每个变量(如温度、湿度)可以看作一个独立的通道。每个通道的时间序列独立处理,不受其他通道的干扰。
MLP 通过参数共享和通用神经元的设计,让每个时间序列的特征可以互相参考。

image-20241126183400037
自注意力机制
虽然注意力机制在之前的预测模型中通常用于促进时间依赖性建模,但倒置模型将每个变量的整个时间序列视为一个独立的过程。具体来说,在对每个时间序列全面提取表示 后,自注意力模块采用线性投影以获得查询(queries),键(keys)和值(values),即 ,其中 是投影维度。
以 表示某个变量令牌的查询和键,我们注意到每个 Softmax 前得分的具体项公式为:
由于每个令牌在其特征维度上被预先归一化,这些得分项可以在一定程度上揭示变量之间的相关性,并且整个得分矩阵 展示了变量令牌之间的多变量相关性。因此,高度相关的变量将在下一步与值 进行表示交互时获得更高的权重。基于这一直觉,所提出的机制被认为在多变量时间序列预测中更加自然且具有解释性。我们进一步在第 ==4.3 节和附录 E.1== 中提供了得分矩阵的可视化分析。
自注意力机制的作用:捕获输入中不同部分之间的关系和重要性。在多变量时间序列预测任务中,目标是理解不同变量的相互依赖关系以及时间维度上的交互。
多变量相关性分析 得分矩阵 表示变量之间的多变量相关性:如果的值高,说明第 个变量和第 个变量有很强的依赖关系。
自然且解释性强 在时间序列预测中,自注意力机制能够自动选择相关变量并赋予更高的权重,使得模型更加自然地捕捉多变量之间的复杂交互。


image-20241126213330151
4 实验
我们对所提出的 iTransformer 进行了全面的评估,涵盖了多种时间序列预测应用,验证了所提框架的普适性,并进一步深入研究了将 Transformer 组件应用于时间序列倒置维度的有效性。
数据集
实验中包含了 7 个真实世界的数据集,包括:
-
ECL、ETT(4 个子集)、Exchange、Traffic、Weather,均来自 Autoformer (Wu et al., 2021) 的研究。
-
Solar-Energy 数据集源于 LSTNet (Lai et al., 2018)。
-
PEMS(4 个子集),使用了 SCINet (Liu et al., 2022a) 评估的公开数据。
我们还在==附录F.4==中提供了关于Market(6个子集)的实验。该数据集记录了支付宝在线交易应用的分钟级服务器负载数据,包含数百个变量,在该数据集上,我们的模型一直优于其他基准模型。数据集的详细描述请参见==附录A.1==。
4.1 预测结果
在本节中,我们通过大量实验评估了我们提出的模型与先进的深度预测模型的预测性能。
基准模型
我们精心选择了10个公认的预测模型作为基准,包括:
-
基于Transformer的方法:Autoformer(Wu等,2021),FEDformer(Zhou等,2022),Stationary(Liu等,2022b),Crossformer(Zhang & Yan,2023),PatchTST(Nie等,2023);
-
基于线性的方法:DLinear(Zeng等,2023),TiDE(Das等,2023),RLinear(Li等,2023);
-
基于TCN的方法:SCINet(Liu等,2022a),TimesNet(Wu等,2023)。
基于TCN的方法指的是那些使用时序卷积网络(Temporal Convolutional Networks, TCN)来处理时间序列数据的预测方法。TCN是一种神经网络架构,特别适用于时间序列建模,其核心思想是通过卷积操作来捕捉时间序列数据中的时序依赖性。
与传统的递归神经网络(RNN)或长短期记忆网络(LSTM)相比,TCN使用卷积层来替代循环结构。其优势在于可以并行计算,处理长时间依赖关系时效果更好,且不易受到梯度消失或爆炸的影响。
主要结果
综合预测结果列在表1中,==最佳结果用红色标出,第二好的结果用下划线标出==。较低的MSE/MAE值表示预测结果更为准确。与其他预测模型相比,iTransformer在高维时间序列预测方面表现尤为出色。此外,作为之前的最先进方法,PatchTST在PEMS数据集中的许多案例中表现不佳,这可能源于数据集中的剧烈波动,PatchTST的补丁机制可能未能集中处理特定的局部波动。相比之下,我们提出的模型通过聚合整个序列的变化来生成序列表示,能够更好地应对这种情况。值得注意的是,作为一种明确捕捉多变量相关性的代表,Crossformer的表现仍然不如iTransformer,这表明来自不同多变量的时间不对齐补丁之间的相互作用会带来不必要的噪声,影响预测效果。因此,本地Transformer组件在时间建模和多变量相关性建模方面具有足够的能力,而我们提出的倒置架构能够有效应对实际时间序列预测场景。
表1:PEMS的预测长度为S ∈ {12, 24, 36, 48},其他数据集的预测长度为S ∈ {96, 192, 336, 720},固定回顾长度T = 96。结果为所有预测长度的平均值。Avg表示进一步按子集平均。完整结果列在==附录F.4==中。
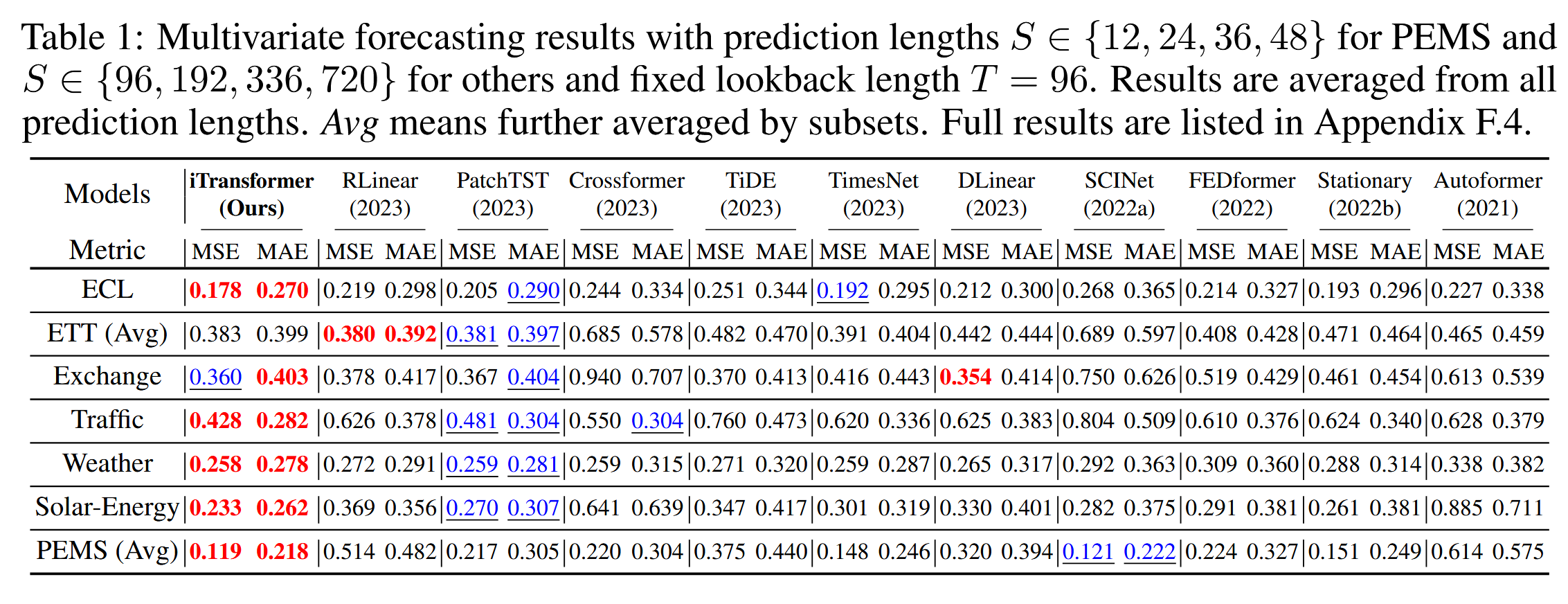
image-20241126214903348
4.2 iTransformer的普适性
在本节中,我们通过将我们的框架应用于Transformer及其变体来评估iTransformer,这些变体通常用于解决自注意力机制的二次复杂度问题,包括Reformer(Kitaev等,2020)、Informer(Li等,2021)、Flowformer(Wu等,2022)和FlashAttention(Dao等,2022)。实验展示了令人惊喜且充满希望的发现,表明简单的反转视角**==可以在效率、对未见变量的泛化能力以及对历史观察的更好利用方面==**提升基于Transformer的预测模型的性能。
性能提升
我们评估了Transformer及其对应的iTransformer,并在表2中列出了性能提升情况。值得注意的是,该框架能够持续提升多种Transformer的表现。总体来看,iTransformer在普通Transformer上平均提升38.9%,在Reformer上提升36.1%,在Informer上提升28.5%,在Flowformer上提升16.8%,在Flashformer上提升32.2%。这些结果揭示了之前在时间序列预测中对Transformer架构的不当使用。此外,由于在我们反转结构中,自注意力机制被应用在变量维度上,引入具有线性复杂度的高效注意力机制本质上解决了由于大量变量导致的计算问题,这在实际应用中非常普遍,但对通道独立(Channel Independence, Nie等,2023)方法来说可能消耗大量资源。因此,iTransformer的概念可以广泛应用于基于Transformer的预测模型,从而充分利用迅速发展的高效注意力机制。
总结:传统的Transformer由于通道独立的方法对于多变量可能消耗大量资源,ITransformer的倒置思想可在一定程度避免这种现象。
表2:我们的反转框架带来的性能提升。Flashformer指的是配备硬件加速的FlashAttention的Transformer(Dao等,2022)。我们报告了平均性能以及相对均方误差(MSE)的减少情况(提升幅度)。完整结果请参见==附录F.2==。
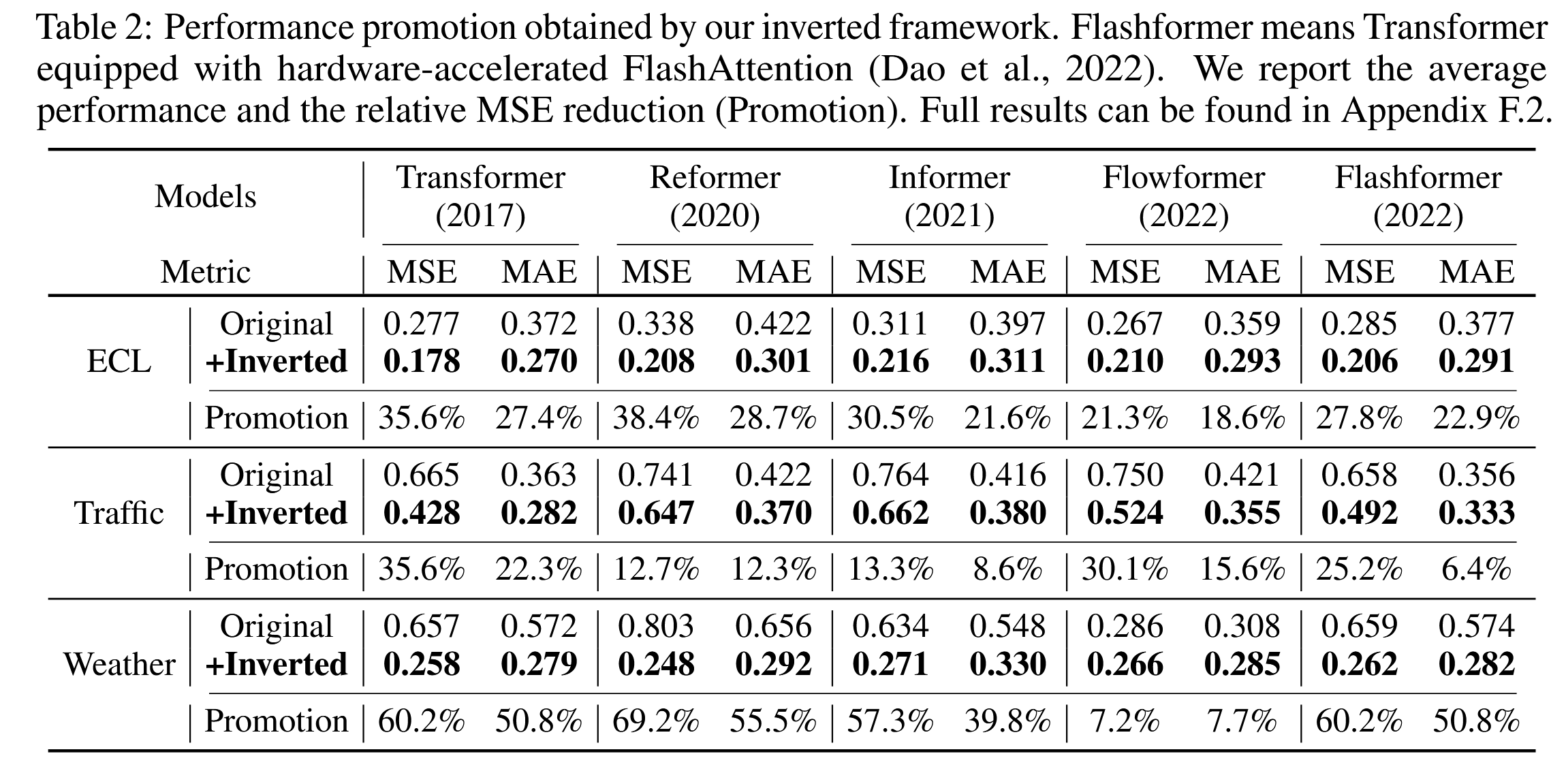
image-20241127103205637
==总结:作者把自己的iTransformer倒置思想应用带Transformer的变体中,成为iTransformers,效果比较好。==
“此外,由于在我们反转结构中,自注意力机制被应用在变量维度上,引入具有线性复杂度的高效注意力机制本质上解决了由于大量变量导致的计算问题。”
- 解释
iTransformer把“自注意力机制”从时间维度转移到了“变量维度”。
线性复杂度的注意力机制:传统的注意力机制复杂度是二次的,计算量大,而iTransformer通过优化,把复杂度降低到线性,解决了多变量计算资源消耗过大的问题。
变量泛化能力
通过反转传统Transformer,模型在未见变量上的泛化能力得到了显著提升。首先,受益于输入token数量的灵活性,变量通道数量不再受到限制,因此训练和推理阶段的通道数量可以变化。此外,iTransformer中的前馈网络(Feed-Forward Network, FFN)被相同地应用于独立的变量token上。如前所述,FFN中的神经元作为过滤器,能够学习任何时间序列的内在模式,并倾向于在不同变量之间共享和迁移。
为验证这一假设,我们将反转策略与另一种泛化策略——通道独立(Channel Independence)进行比较,该策略通过一个共享骨干网络来预测所有变量。我们将每个数据集的变量分为五份,仅使用一份中20%的变量进行训练,并在不进行微调的情况下直接预测所有变量。我们在图5中比较了性能,每个柱状图代表所有分组的平均结果,以避免分组随机性带来的影响。CI-Transformer在推理阶段需要逐个变量进行预测,耗时较长,而iTransformer直接预测所有变量,且通常表现出更小的误差增长,表明FFN能够学习可迁移的时间序列表示。这为基于iTransformer构建一个基础模型提供了潜在方向,使得不同数量变量的多元时间序列可以一起高效训练。详细查看附件F.3。
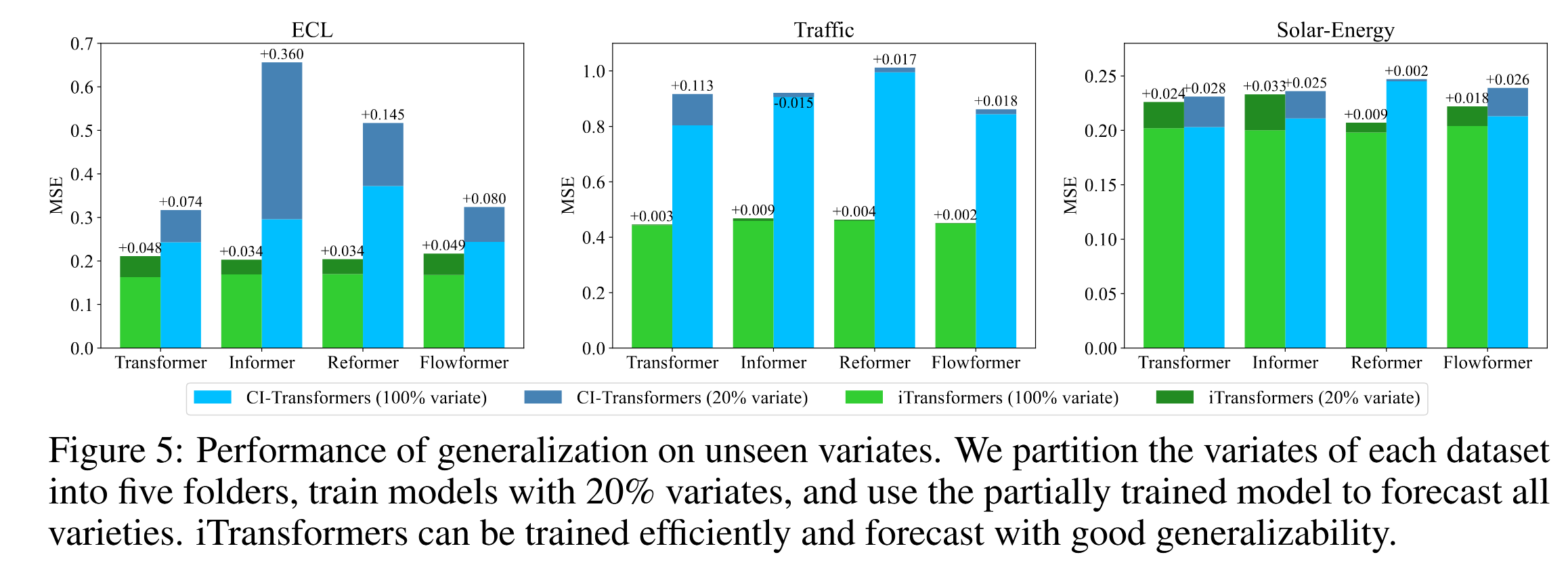
image-20241127105914605
图5:在未见变量上的泛化性能。我们将每个数据集的变量分为五个文件夹,使用20%的变量进行模型训练,并利用部分训练的模型预测所有变量。iTransformer能够高效地进行训练,并在预测时表现出良好的泛化能力。
增加回溯长度
以往研究表明,Transformer的预测性能并不一定随着回溯长度的增加而提升(Nie等,2023;Zeng等,2023),这可能是由于在输入长度增加时注意力分散。然而,线性预测模型通常能够随着回溯窗口的扩展而提升性能,这一现象在统计方法(Box & Jenkins, 1968)中有理论支持,即利用更多的历史信息。由于注意力机制和前馈网络的工作维度被反转,我们在图6中评估了在增加回溯长度情况下Transformer和iTransformer的性能。结果验证了在时间维度上利用MLP(多层感知机)的合理性,从而使Transformer能够从扩展的回溯窗口中受益,实现更精准的预测。
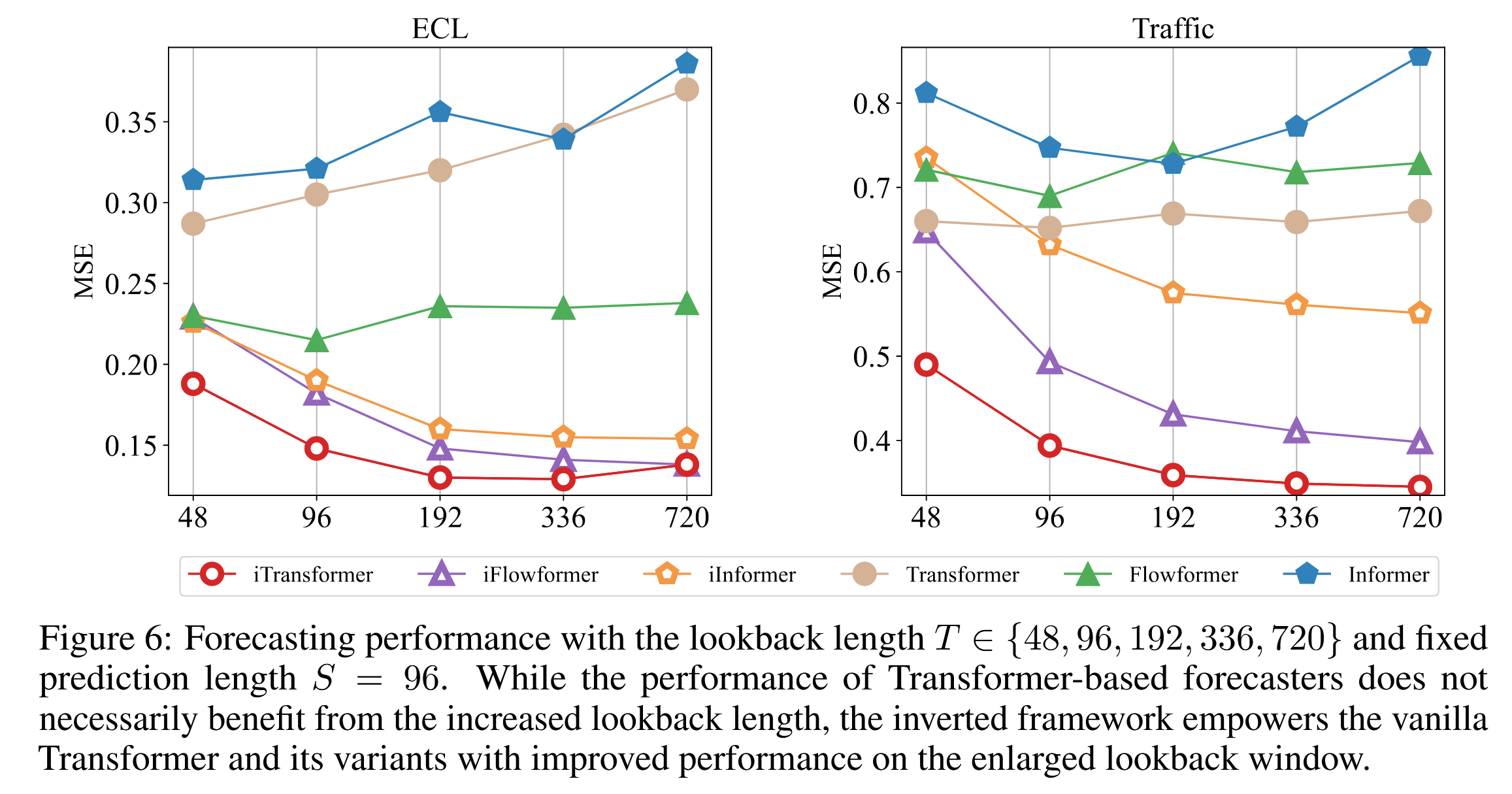
image-20241127111936818
图6:不同回溯长度 T∈{48,96,192,336,720}和固定预测长度 S= 96 下的预测性能。 尽管基于Transformer的预测模型性能并不一定会因回溯长度的增加而提升,但反转框架赋能了基础Transformer及其变体,使其在较大的回溯窗口下表现出更优的性能。
4.3 模型分析
消融研究
为了验证 Transformer 组件的合理性,我们进行了详细的消融实验,包括替换组件(Replace)和移除组件(w/o)的实验。结果列于表 3 中。
iTransformer 通过在变量(variate)维度上使用注意力机制(attention)以及在时间(temporal)维度上使用前馈网络(feed-forward)来实现最佳性能。值得注意的是,基础 Transformer(第三行)的性能在这些设计中表现最差,这揭示了传统架构可能存在的潜在风险,我们在==附录 E.3== 中对此进行了详细描述。
表 3:iTransformer 的消融实验。我们在相应维度上替换不同组件,以学习多变量相关性(变异维度)和系列表示(时间维度),此外还进行了组件移除实验。此处列出了所有预测长度的平均结果。
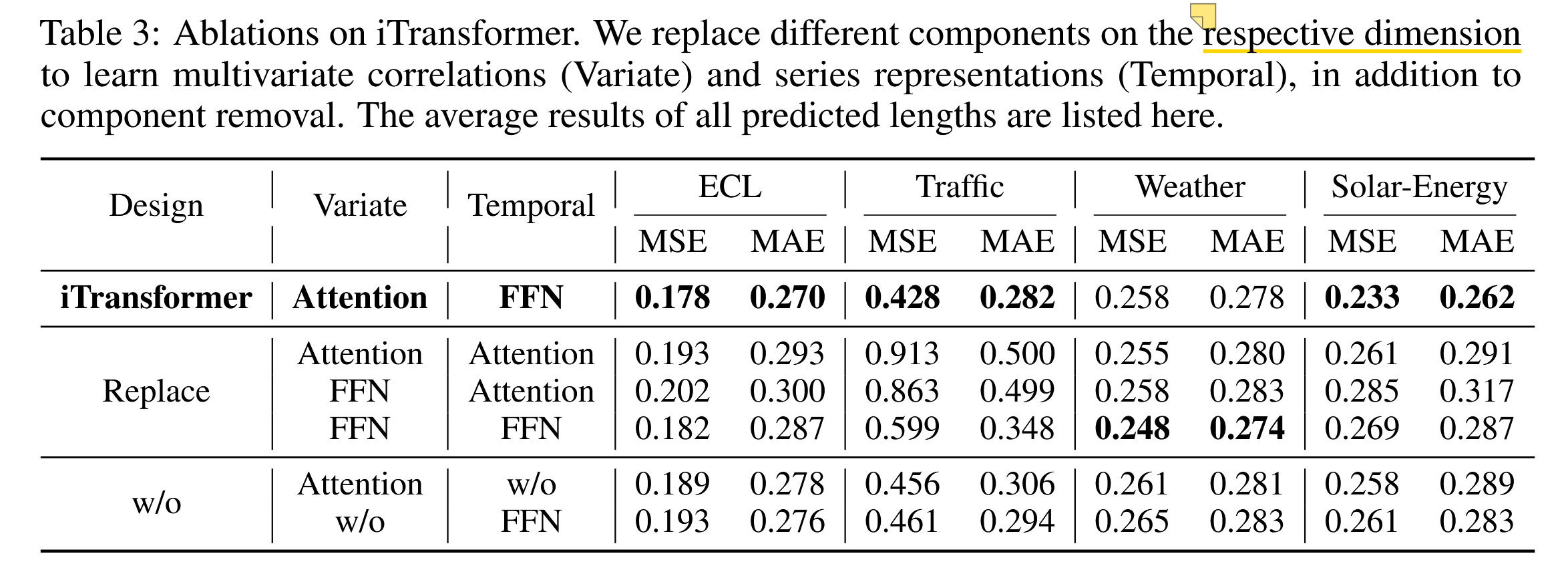
image-20241128094615610
序列表示分析
为了进一步验证前馈网络在提取序列表示方面的优势,我们基于中心核对齐(CKA)相似性(Kornblith 等,2019)进行了表示分析。较高的 CKA 表示更相似的表示特征。
对于 Transformer 变体和 iTransformer,我们计算了第一个块和最后一个块输出特征之间的 CKA。值得注意的是,先前的研究已经表明,时间序列预测作为一种低级生成任务,更倾向于更高的 CKA 相似性(Wu 等,2023;Dong 等,2023),以实现更优的性能。
如图 7 所示,展示了一条清晰的分隔线,这表明 iTransformer 通过维度翻转学习到了更合适的序列表示,从而实现了更准确的预测。结果也表明,翻转 Transformer 的设计值得作为预测模型架构的基础性改进。
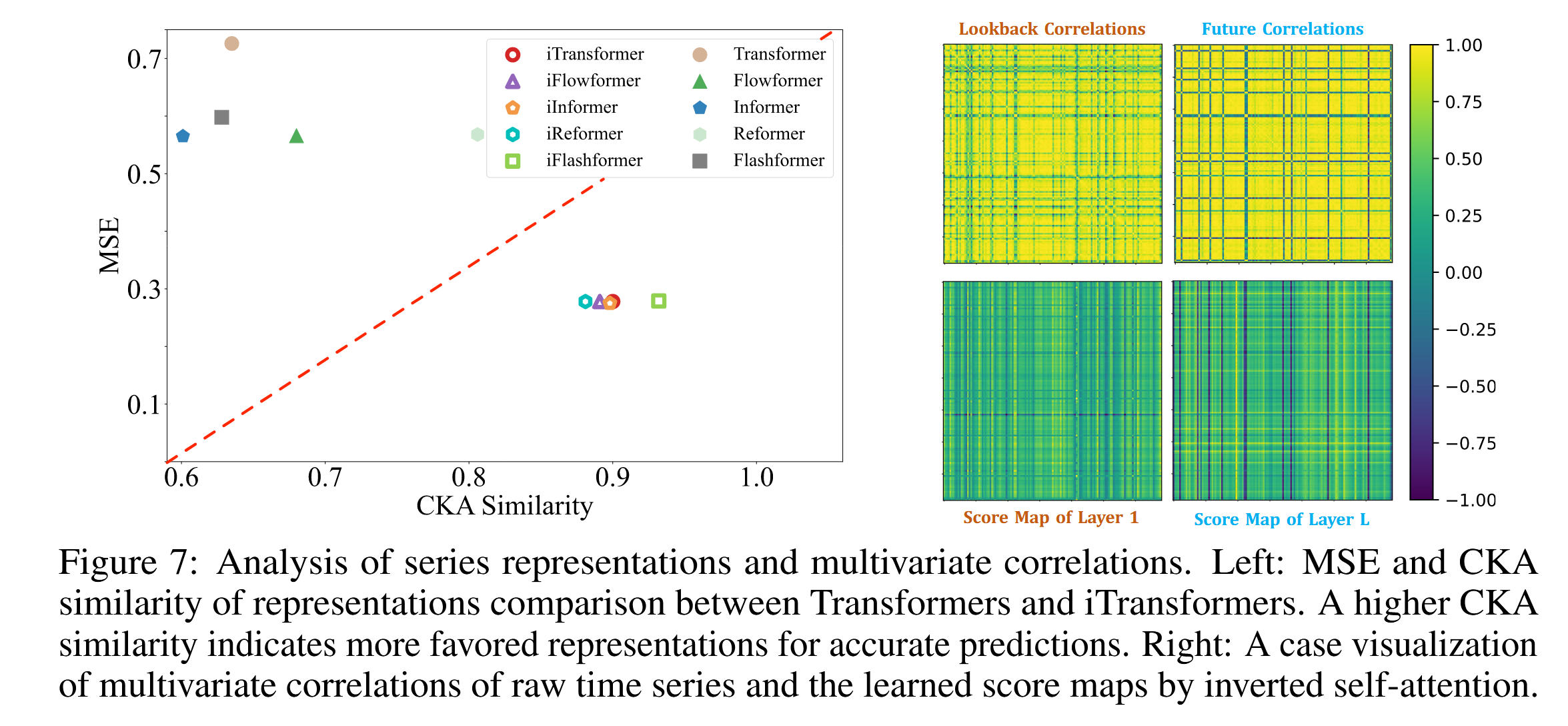
image-20241128094920948
图 7:系列表示和多变量相关性分析。 左图:Transformer 和 iTransformer 表示的 MSE 和 CKA 相似性对比。较高的 CKA 相似性表示更有利于准确预测的表示。 右图:原始时间序列的多变量相关性与通过反转自注意力机制学习的得分映射的案例可视化。
多变量相关性分析
通过将多变量相关性学习任务分配给注意力机制,所学习的映射具有更强的可解释性。我们在 Solar-Energy 数据集上展示了系列数据的可视化结果(如图 7 所示),该数据集在回溯窗口和未来窗口中具有明显的相关性特征。 可以观察到,在浅层注意力层中,学习到的映射与原始输入序列的相关性有许多相似之处。而随着模型逐层深入,学习到的映射逐渐接近未来序列的相关性。这验证了翻转操作赋予了注意力机制更高的可解释性,用于处理变量之间的相关性,且在前馈过程中,过去的编码和未来的解码实质上是通过序列表示完成的。

高效训练策略
由于自注意力机制的二次复杂度,在包含众多变量的训练中可能会带来巨大的计算开销,这在实际场景中十分常见。除了使用高效注意力机制外,我们还提出了一种针对高维多变量序列的新型训练策略,利用了先前已验证的变量生成能力。 具体而言,我们在每个训练批次中随机选择部分变量进行训练,而模型可以通过翻转操作处理灵活数量的变量通道,从而预测所有变量。 如图 8 所示,我们提出的策略在性能上仍然与全变量训练相当,但显著减少了内存占用。
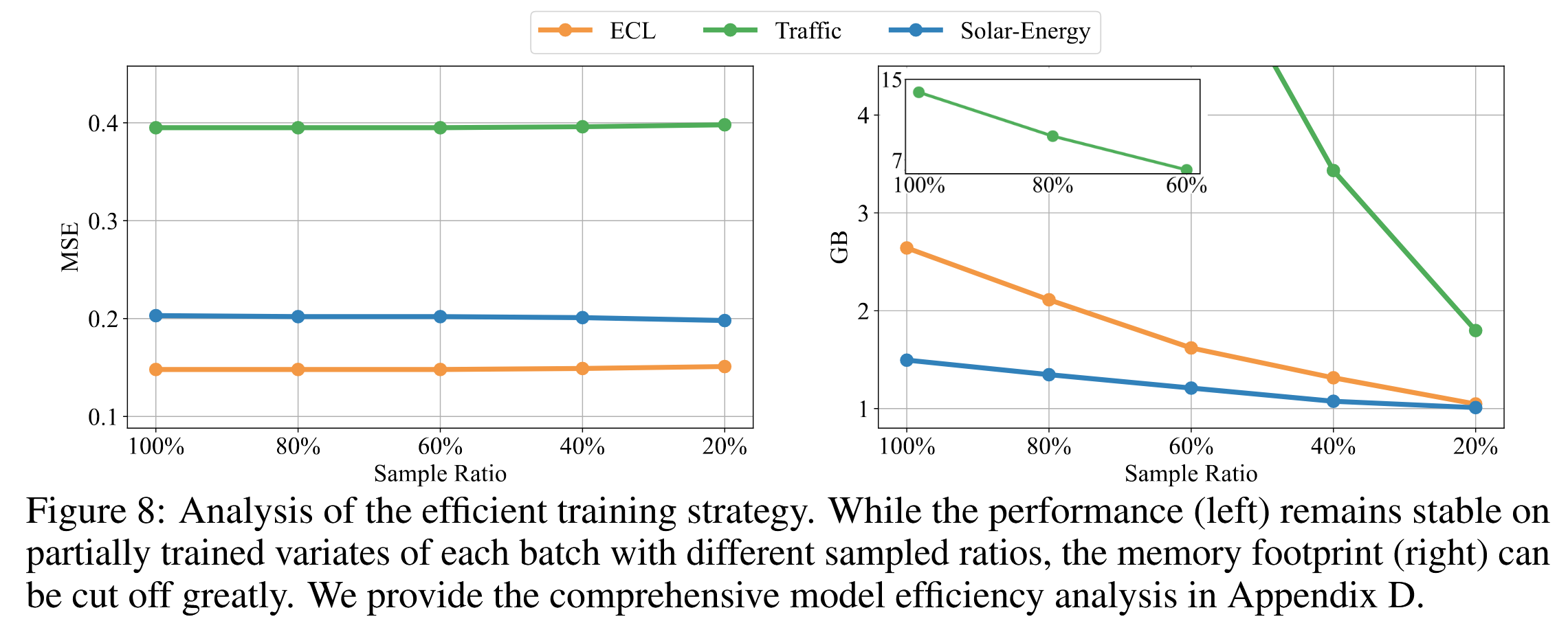
image-20241128121315513
图 8:高效训练策略分析。 尽管在每批中对部分变量进行训练时,不同采样比例下的性能(左图)保持稳定,但内存占用(右图)却显著减少。全面的模型效率分析详见附录 D。
采样比例是什么?指的是在模型训练过程中,从输入数据中选取一部分特征(或变量)进行训练,而不是使用全部特征。这种方法常用于减小模型的计算负担和内存占用,尤其在处理多变量时间序列或高维数据时。
5 结论与未来工作
考虑到多变量时间序列的特点,我们提出了 iTransformer,它在不修改任何原生模块的情况下,通过翻转 Transformer 的结构实现新颖设计。 iTransformer 将独立的序列视为变量 token,以通过注意力机制捕获多变量相关性,并利用层归一化和前馈网络学习序列表示。在实验中,iTransformer 实现了当前最先进的性能,并通过有力的分析展示了出色的框架通用性。 未来,我们将探索大规模预训练模型以及更多的时间序列分析任务。
A. 实施细节
A.1 数据集描述
我们在 7 个真实世界数据集上进行实验,以评估所提出的 iTransformer 的性能,包括:
-
ETT(Li 等, 2021):包含 2016 年 7 月至 2018 年 7 月间电力变压器的 7 个因素数据。数据集分为四个子集,其中 ETTh1 和 ETTh2 为每小时记录,ETTm1 和 ETTm2 为每 15 分钟记录。
-
Exchange(Wu 等, 2021):收集了 1990 年至 2016 年 8 个国家的每日汇率面板数据。
-
Weather(Wu 等, 2021):包含 2020 年从 Max Planck 生物地球化学研究所气象站每 10 分钟收集的 21 个气象因素。
-
ECL(Wu 等, 2021):记录了 321 个客户的每小时用电量数据。
-
Traffic(Wu 等, 2021):收集了 2015 年 1 月至 2016 年 12 月期间旧金山湾区高速公路 862 个传感器每小时的道路占用率。
-
Solar-Energy(Lai 等, 2018):记录了 2006 年 137 个光伏电站的太阳能发电量,每 10 分钟采样一次。
-
PEMS:包含通过 5 分钟窗口收集的加州公共交通网络数据,我们采用 SCINet(Liu 等, 2022a)使用的四个公共子集(PEMS03、PEMS04、PEMS07、PEMS08)。
==除了广泛用作预测基准的公共数据集,我们还收集了一组真实应用中的 Market 数据集,==记录了 2023 年 1 月 30 日至 2023 年 4 月 9 日支付宝在线交易的每分钟服务器负载数据,变量数量从 285 到 759 不等。该数据集包含 6 个子数据集,按不同交易领域划分。
==【学习实验描述部分怎么撰写】我们遵循 TimesNet(Wu 等, 2023)中的数据处理和训练-验证-测试集拆分协议,严格按照时间顺序划分数据集,确保没有数据泄漏问题。====预测设置中,ETT、Weather、ECL、Solar-Energy、PEMS 和 Traffic 数据集的回溯序列长度固定为 96,预测长度为 {96, 192, 336, 720}。PEMS 数据集的预测长度为 {12, 24, 36, 48},与该数据集上当前最优的 SCINet 一致。Market 数据集的回溯序列包含过去一天的 144 个时间点,预测长度为 {12, 24, 72, 144}。数据集的详细信息见表 4。==
表 4:数据集详细描述。 Dim 表示每个数据集的变量数量。Dataset Size 表示数据集中(训练集、验证集、测试集)分别包含的总时间点数。 Prediction Length 表示需要预测的未来时间点数,每个数据集都包含四种预测设置。 Frequency 表示时间点的采样间隔。
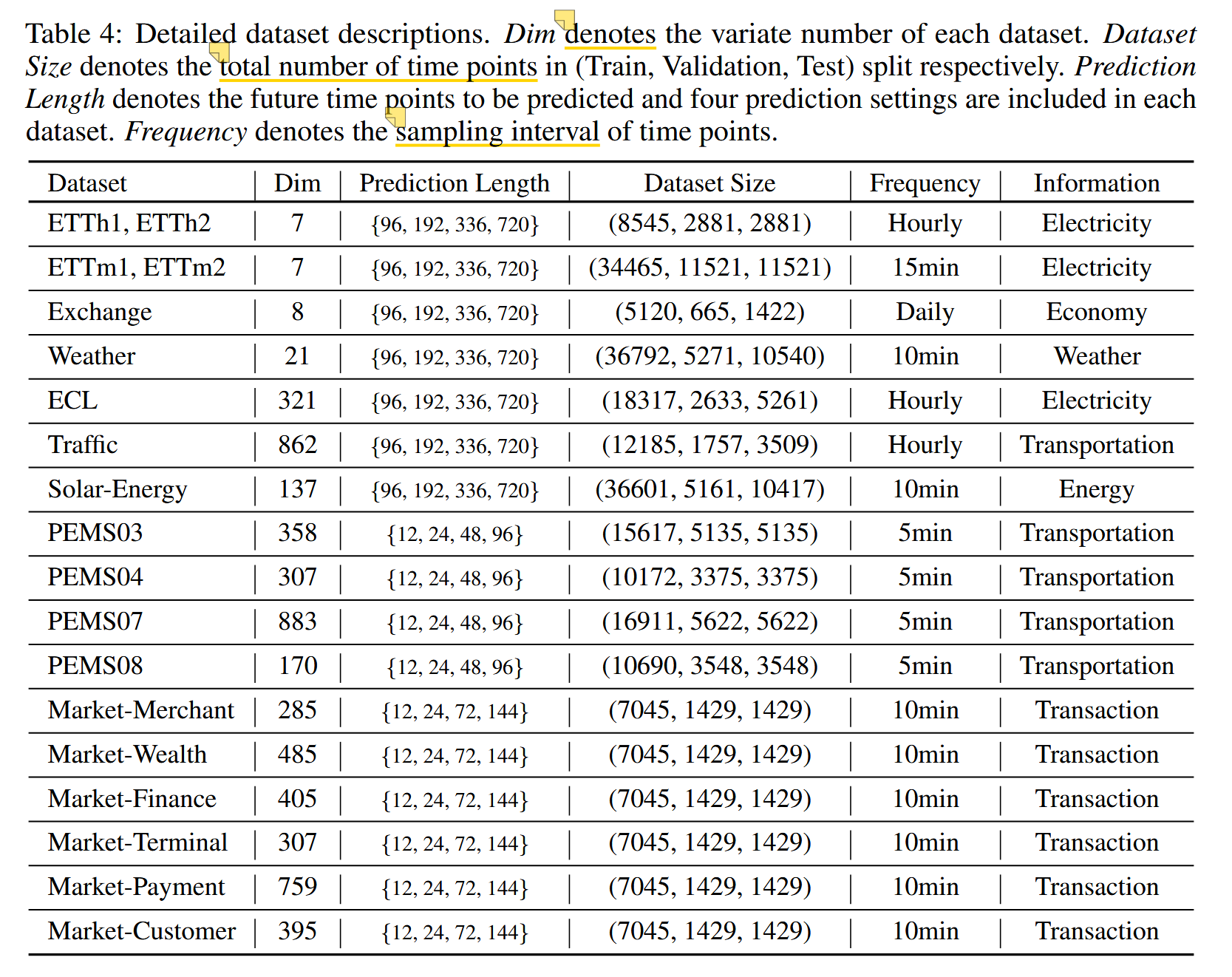
image-20241128171004814
A.2 实施细节

image-20241128171203974
所有实验均使用 PyTorch(Paszke 等, 2019)实现,并在单个 NVIDIA P100 16GB GPU 上运行。我们使用 ADAM(Kingma & Ba, 2015)优化器,初始学习率为 {10⁻³, 5 × 10⁻⁴, 10⁻⁴},损失函数为 L2 损失。批量大小统一设置为 32,训练轮数固定为 10。我们在模型中设置的反向 Transformer 块数量 L 取值范围为 {2, 3, 4},序列表示的维度 D 取值为 {256, 512}。==所有重现的基线模型均基于 TimesNet(Wu 等, 2023)基准库实现,严格依据各模型原论文或官方代码提供的配置==。我们在算法 1 中提供了 iTransformer 的伪代码。==此外,我们在表 5 中报告了使用不同随机种子进行五次运行后 iTransformer 性能的标准差,结果显示 iTransformer 的性能稳定。==
表 5:iTransformer 性能的鲁棒性。 结果基于五个随机种子获得。
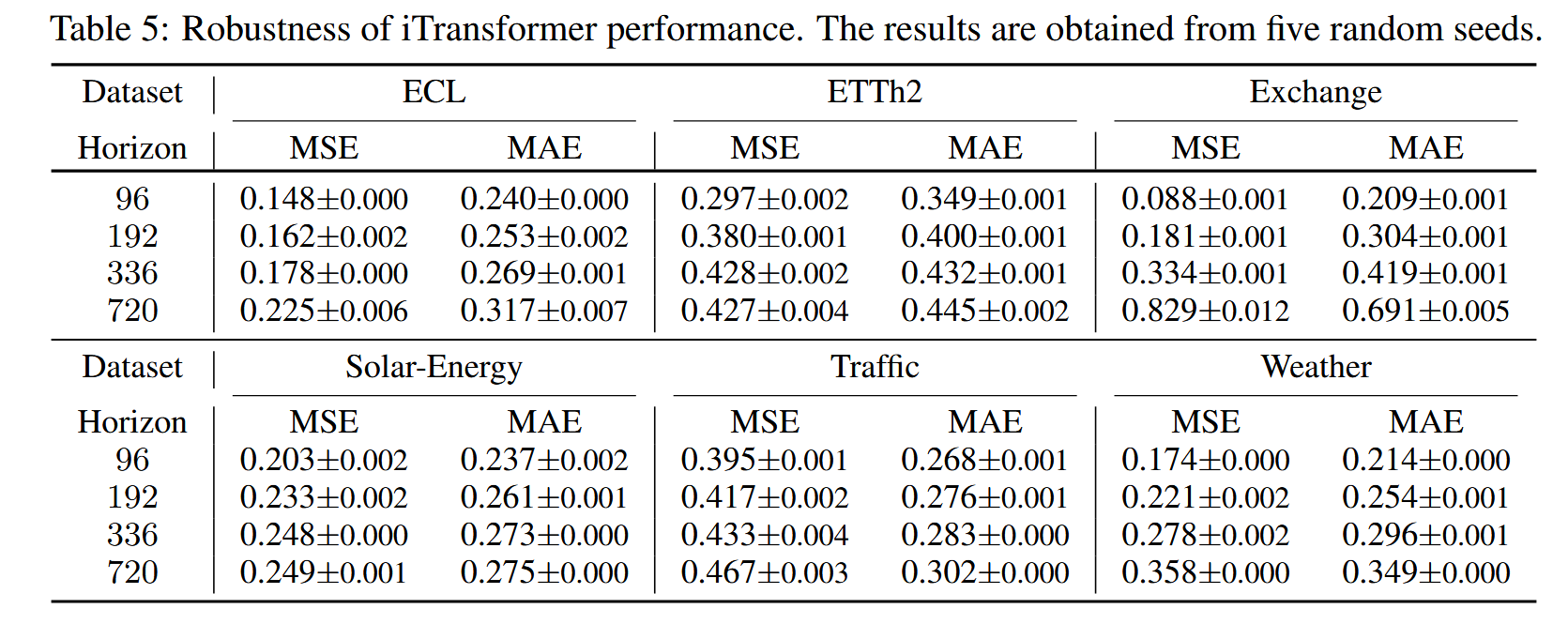
image-20241128173704451
实验中使用多种学习率的目的:在实验中设置多个学习率 {10⁻³, 5 × 10⁻⁴, 10⁻⁴} 是为了比较不同学习率对模型性能的影响。通过实验发现哪个学习率能够在当前数据集和模型配置下获得最佳性能。
B. 消融研究
为了详细阐述 Transformer 组件的合理性,我们进行了替换组件(Replace)和移除组件(w/o)的消融实验。由于篇幅限制,平均结果已在表 3 中列出,这里提供了更详细的结果和分析。
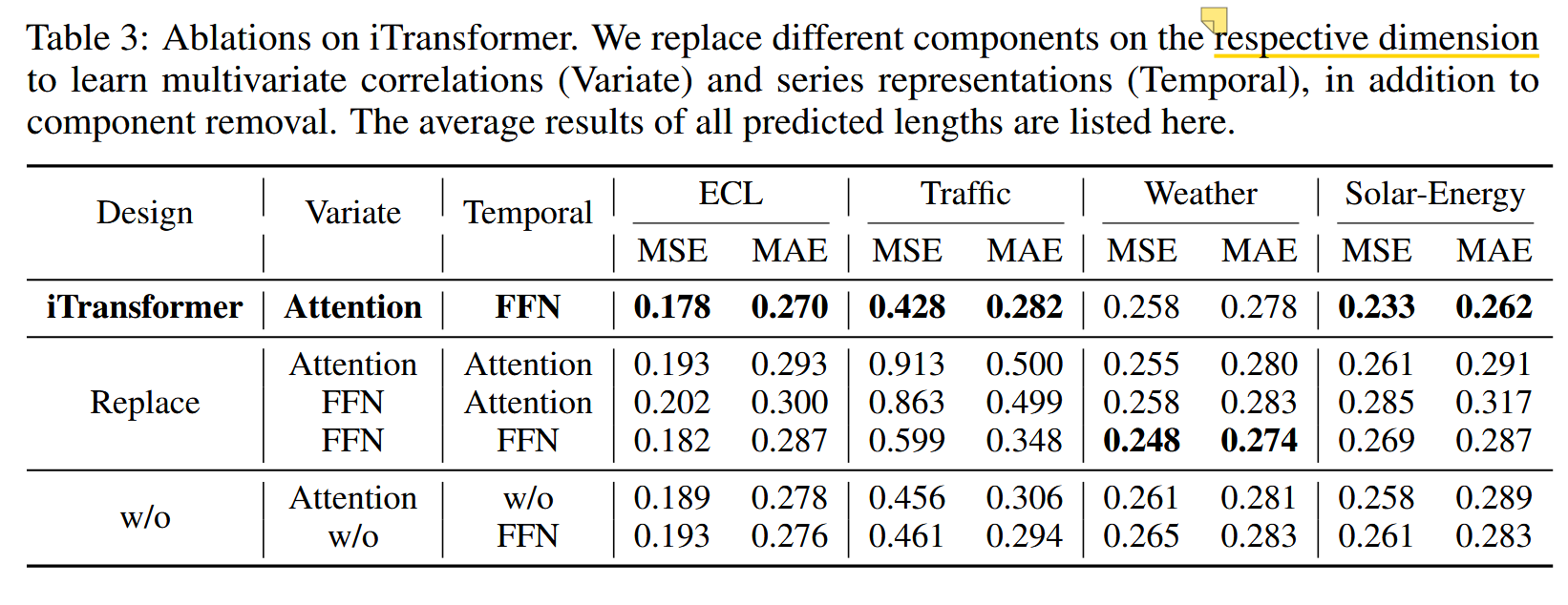
image-20241128174213540
如表 6 所示,在各种架构设计中,iTransformer 通常表现出卓越的性能,通过自注意力机制学习多变量间的关联,并通过前馈网络(FFN)编码时间序列表示。然而,原生 Transformer 的结构安排可能导致性能退化,这表明在时间序列模态下误用 Transformer 组件可能产生负面影响。基于第二种(双注意力机制)和第三种(原生 Transformer)设计的相对较差结果,==可能的原因之一是注意力模块在滞后时间序列的时间令牌上表现不佳,==这一点将在第 **==E.3 节==**中结合数据集进行更详细的阐述。
值得注意的是,将 FFN 应用于两个维度上,在变量数较少的数据集(如 21 个变量的 Weather 数据集)中也能表现出较好的性能。然而,随着在复杂多变量预测任务中变量数的增加,捕获多变量关联的重要性愈发凸显。原生 Transformer 难以考虑变量的异质性。在嵌入过程中,变量被投射到不可区分的通道中,忽视了不一致的物理测量,从而无法保持变量的独立性,更不用说捕捉和利用多变量关联。因此,通过引入用于变量关联的高级注意力模块,第一种(iTransformer)和第五种(变量注意力)设计在复杂多变量数据集上表现更为有效。
总之,时间依赖性和多变量关联性对于多变量时间序列预测至关重要。iTransformer 通过自注意力模块解耦变量令牌之间的关联,比前馈网络更具表现力和可解释性,从而在复杂多变量数据集上提升了性能,并增强了模型的容量。
表 6:iTransformer 的完整消融实验结果。我们在相应的维度上应用不同组件来学习多变量相关性(变元)和序列表示(时间),并对 Transformer 的特定组件进行了去除实验。
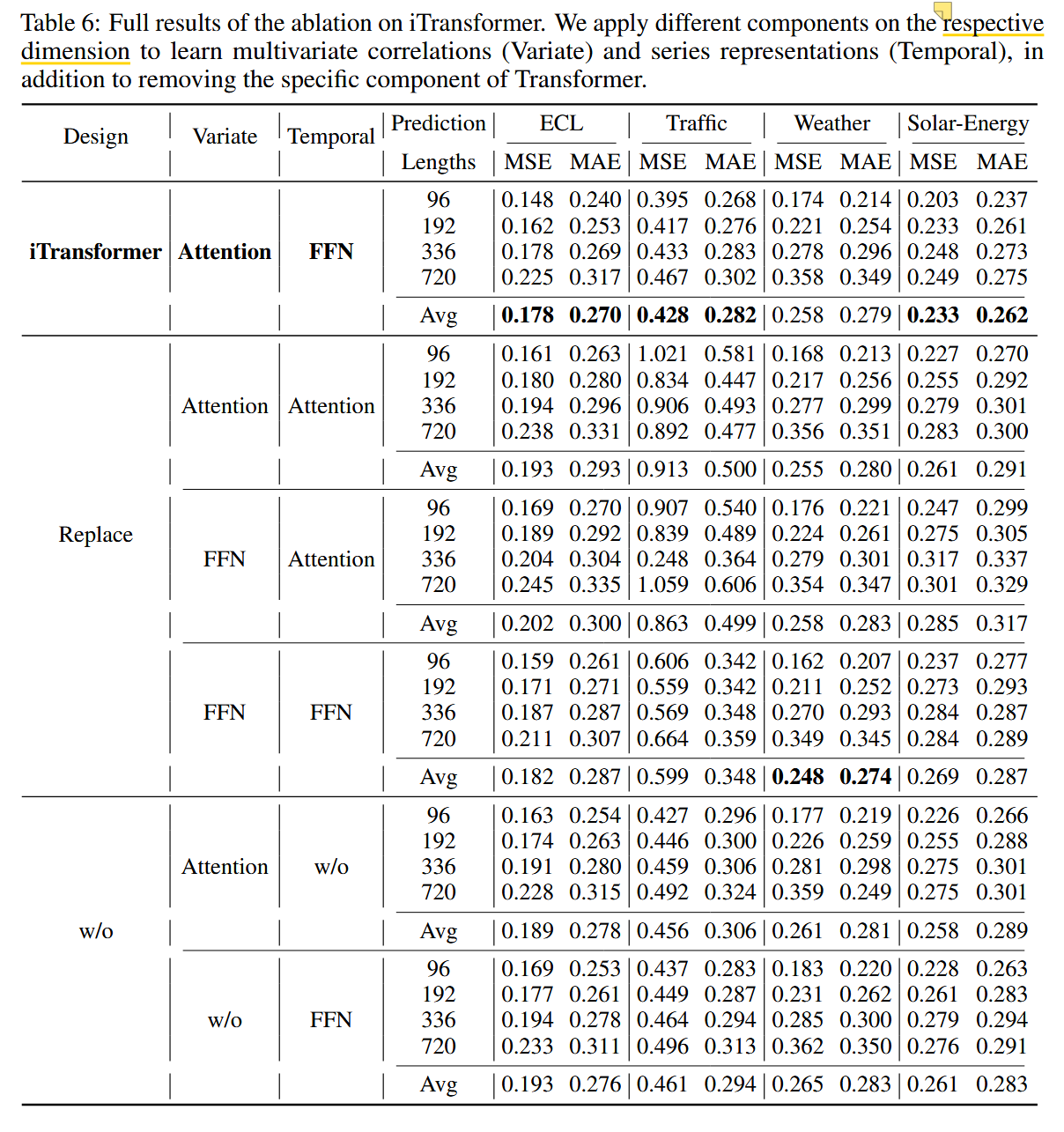
image-20241128174445914
C. 超参数敏感性
我们评估了 iTransformer 对以下超参数的敏感性:学习率 lr、Transformer 块的数量 L、以及变量令牌的隐藏维度 D。结果如图 9 所示。我们发现,学习率作为最常见的影响因素,在变量数量较多时(如 ECL、Traffic 数据集)应谨慎选择。块的数量和隐藏维度并非越大越好。
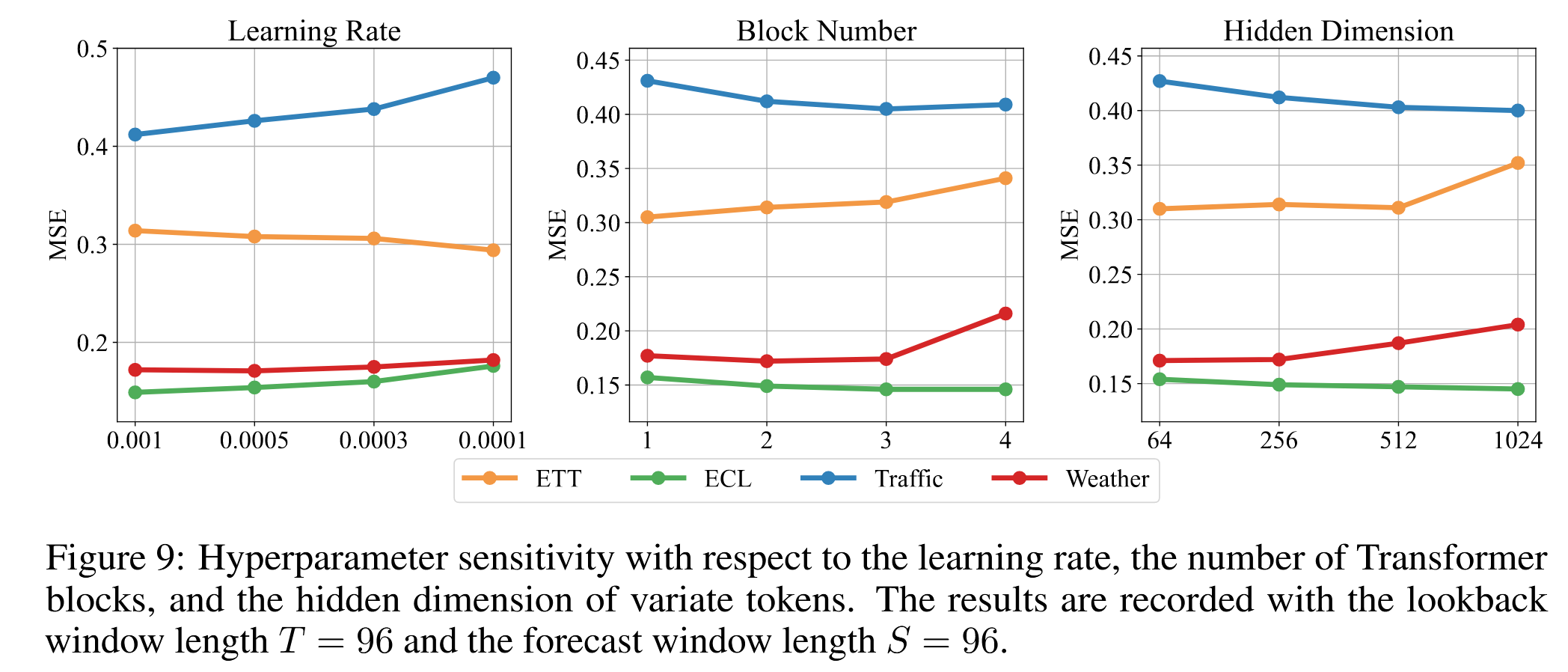
image-20241128204533813
图 9:学习率、Transformer 块数量、变量令牌隐藏维度的超参数敏感性分析,观测窗口长度 T=96,预测窗口长度 S=96。
D. 模型效率
我们全面比较了以下模型的预测性能、训练速度和内存占用情况:iTransformer、采用高效训练策略的 iTransformer、以及带有高效流式注意力模块(Wu et al., 2022)的 iTransformer;线性模型包括 DLinear(Zeng et al., 2023)和 TiDE(Das et al., 2023);Transformer 模型包括 Transformer(Vaswani et al., 2017)、PatchTST(Nie et al., 2023)和 Crossformer(Zhang & Yan, 2023)。这些结果是在使用官方模型配置和相同批量大小的条件下记录的。在图10中,我们比较了在两个具有代表性的数据集(Weather数据集中有21个变量,Traffic数据集中有862个变量)上进行96个时间步回溯时的效率表现。
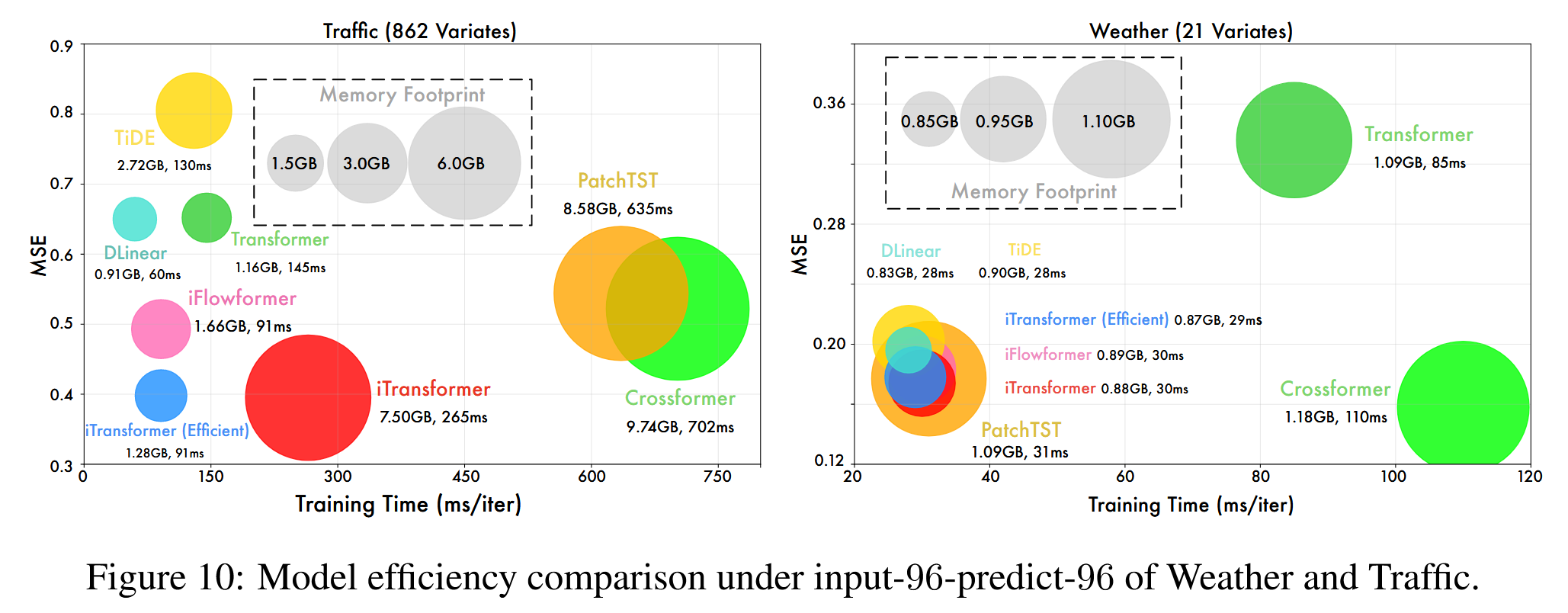
image-20241128205543762
简而言之,在变量数量相对较少的数据集(Weather)中,iTransformer的效率优于其他Transformer模型。而在变量数量较多的数据集(Traffic)中,iTransformer的内存占用与其他Transformer模型基本相同,但训练速度更快。基于注意力模块复杂度为O(N²)的情况下,其中N为令牌数量,Transformer在这种情况下的效率超过了iTransformer,因为时间序列令牌的N值为96,而变量令牌的N值为862。然而,由于iTransformer能够显式利用多变量之间的相关性,因此在处理大量变量时表现更佳。通过采用线性复杂度的注意力机制(Wu等,2022)或如图8中提到的高效训练策略(在20%的变量上训练,预测所有变量),iTransformer在速度和内存占用方面可以与线性模型相媲美。此外,这两种策略可以结合使用。
E展示案例
E.1多元相关性的可视化
通过在变量标记上使用注意力机制,得到的学习映射变得更具可解释性。为了直观地理解多元相关性,我们在图11中提供了来自太阳能数据集的三个随机选择的时间序列案例可视化。我们通过以下公式提供原始系列中每个变量的皮尔逊相关系数:
(越接近 1 或 -1,表示变量之间的线性相关性越强。)
其中遍历要相关的成对变量的所有时间点。所有案例在回顾窗口和预测窗口中都有明显的多元相关性,因为数据集在白天和晚上表现出明显的季节性变化。在每个案例的第二行,我们提供了第一层和最后一层的自注意力模块的学习到的预softmax映射。正如我们在浅层注意力层(左)中观察到的,我们发现学习到的映射与原始回顾系列的相关性相似。随着我们深入到层中(右),学习到的映射逐渐变得更类似于要预测的未来系列的相关性。这表明倒置操作允许在相关中进行可解释的注意力,并且在层堆叠期间通过系列表示进行过去的编码和未来的解码。

image-20241128205806185
图11:回顾系列和未来系列的多元相关性以及通过不同层的倒置自注意力学习到的得分图。案例均来自太阳能数据集。
总结:这段内容说明了通过注意力机制捕捉时间序列中变量间的相关性,模型不仅能准确预测,还能在每层中逐步转移注意力焦点,使模型在时间序列预测中具备更强的解释性。
我们在图12中展示了另一个有趣的观察结果,以表明iTransformer的注意力模块具有增强的可解释性。我们提供了来自市场数据集的随机选择的多元时间序列。在这个数据集中,每个变量代表一种服务接口的监测值,并且服务可以进一步分组为细化的应用类别。我们将这些变量划分为相应的应用(如顶部栏“App”中所列),使得相邻变量属于同一应用,并且我们通过顶部栏显示应用索引。 我们可视化变量的时间序列,并绘制学习到的多元相关性以及变量之间特定相关性的标记。一方面,我们在多元相关性图中观察到明显的分区,表明变量的分组。一方面,标记的相关值可以反映原始系列的相关性,其中来自同一应用的变量的相似性比来自不同组的对更接近。因此,高度相关的变量将被用于下一次交互,从而有利于多元预测。
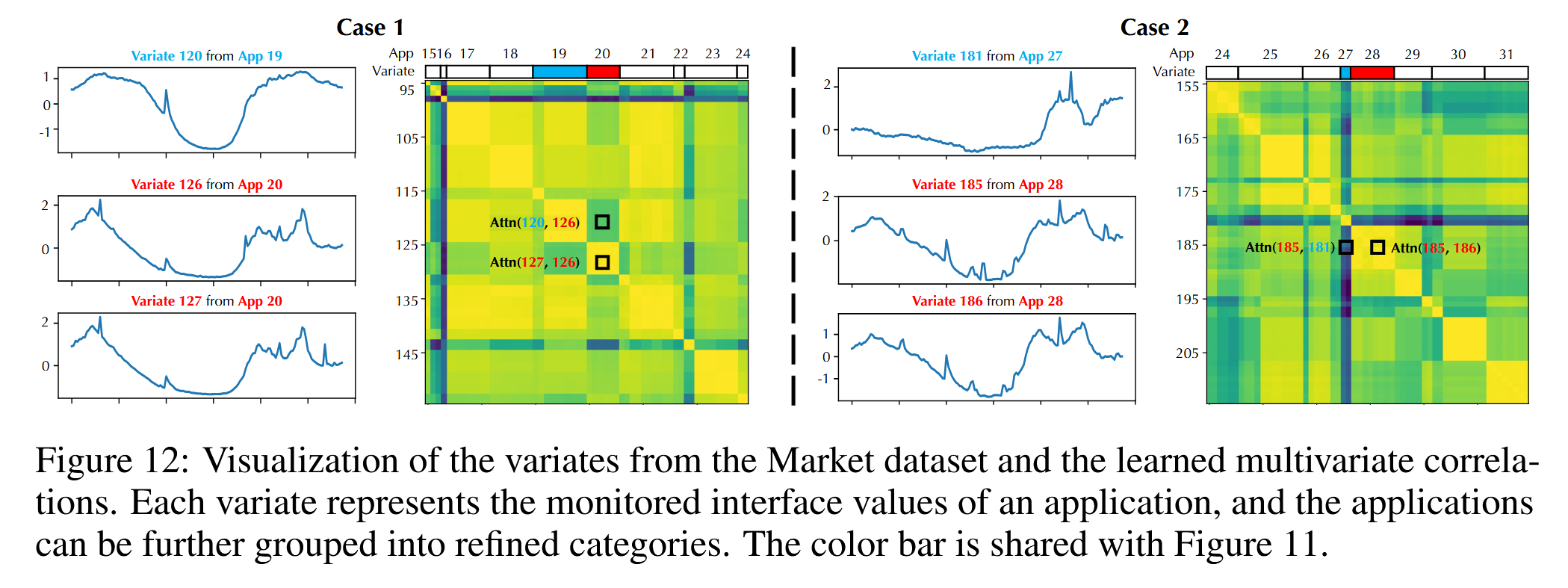
image-20241128205913694
图12:来自市场数据集的变量可视化和学习到的多元相关性。每个变量代表一个应用的监测接口值,并且应用可以进一步分组为细化类别。**==颜色条与图11共享。==**
E.2预测结果的可视化
为了在不同模型之间提供清晰的比较,我们在图13 - 16中列出了四个代表性数据集的补充预测展示,这些展示由以下模型给出:iTransformer、PatchTST(Nie等人,2023)、DLinear(Zeng等人,2023)、Crossformer(Zhang和Yan,2023)、Autoformer(Wu等人,2021)、Transformer(Vaswani等人,2017)。在各种模型中,iTransformer预测出最精确的未来系列变化并表现出优越的性能。
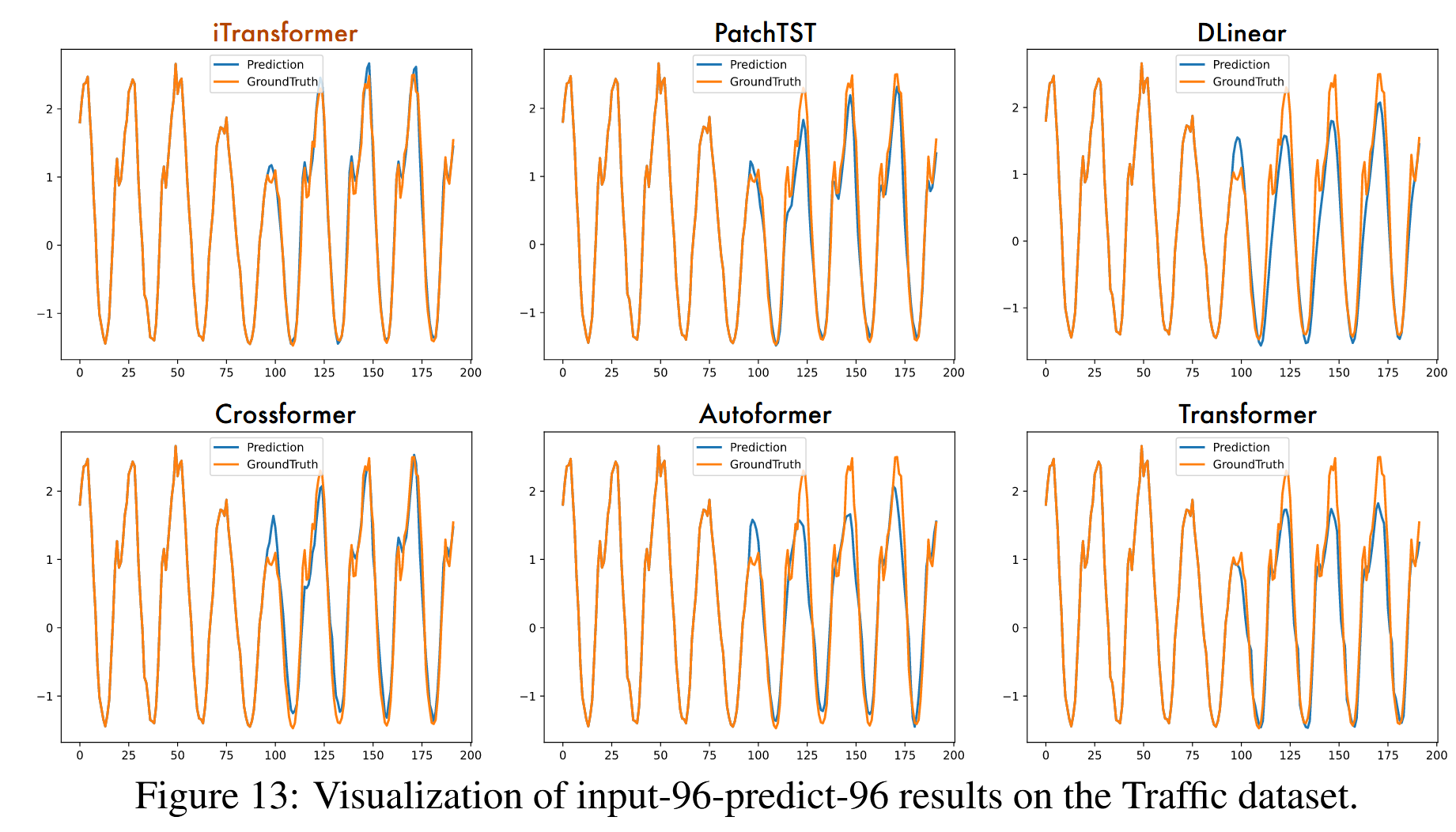
image-20241128210005240
图13:交通数据集上输入96预测96结果的可视化。
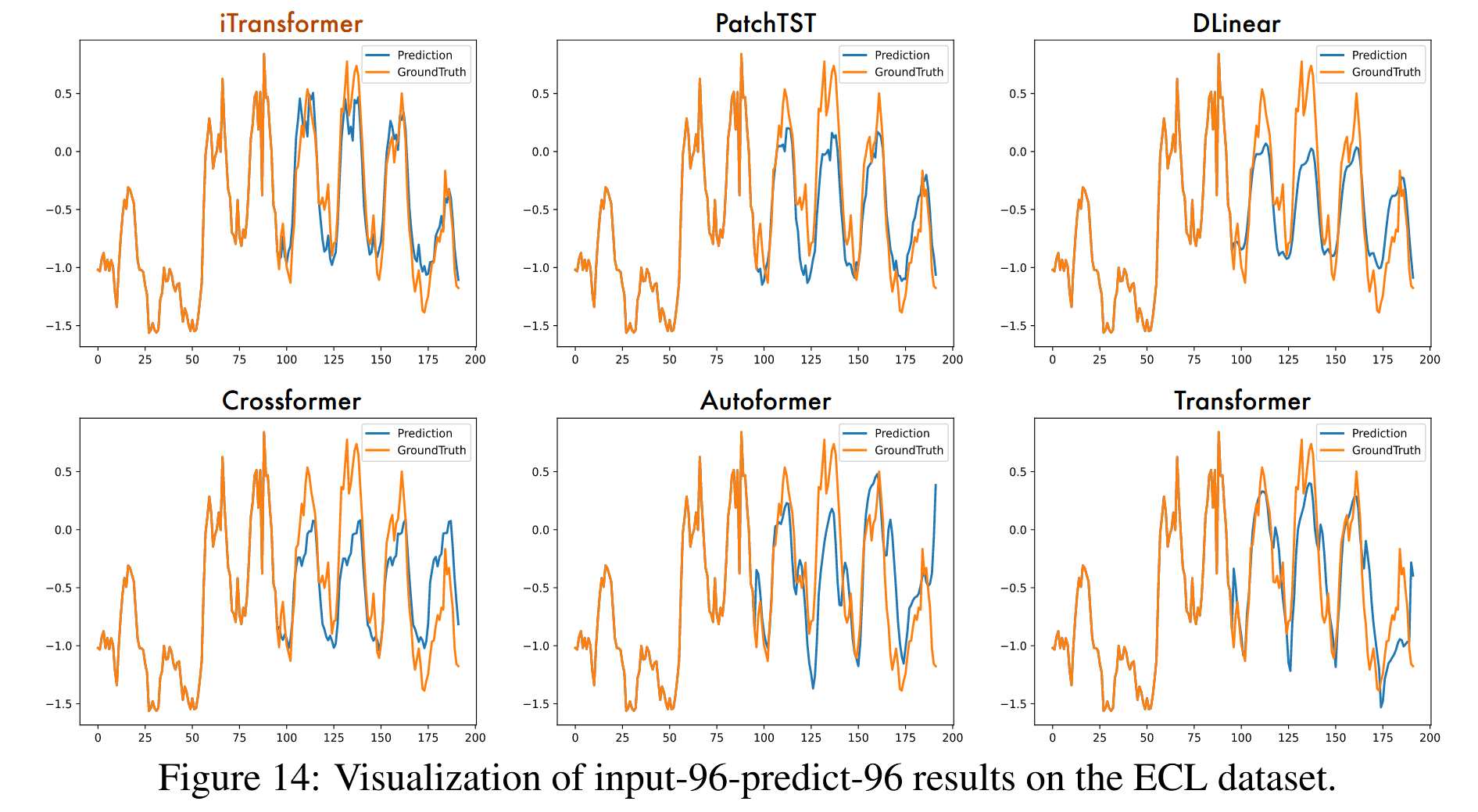
image-20241129182449263
图14:ECL数据集上输入-96-预测-96结果的可视化。
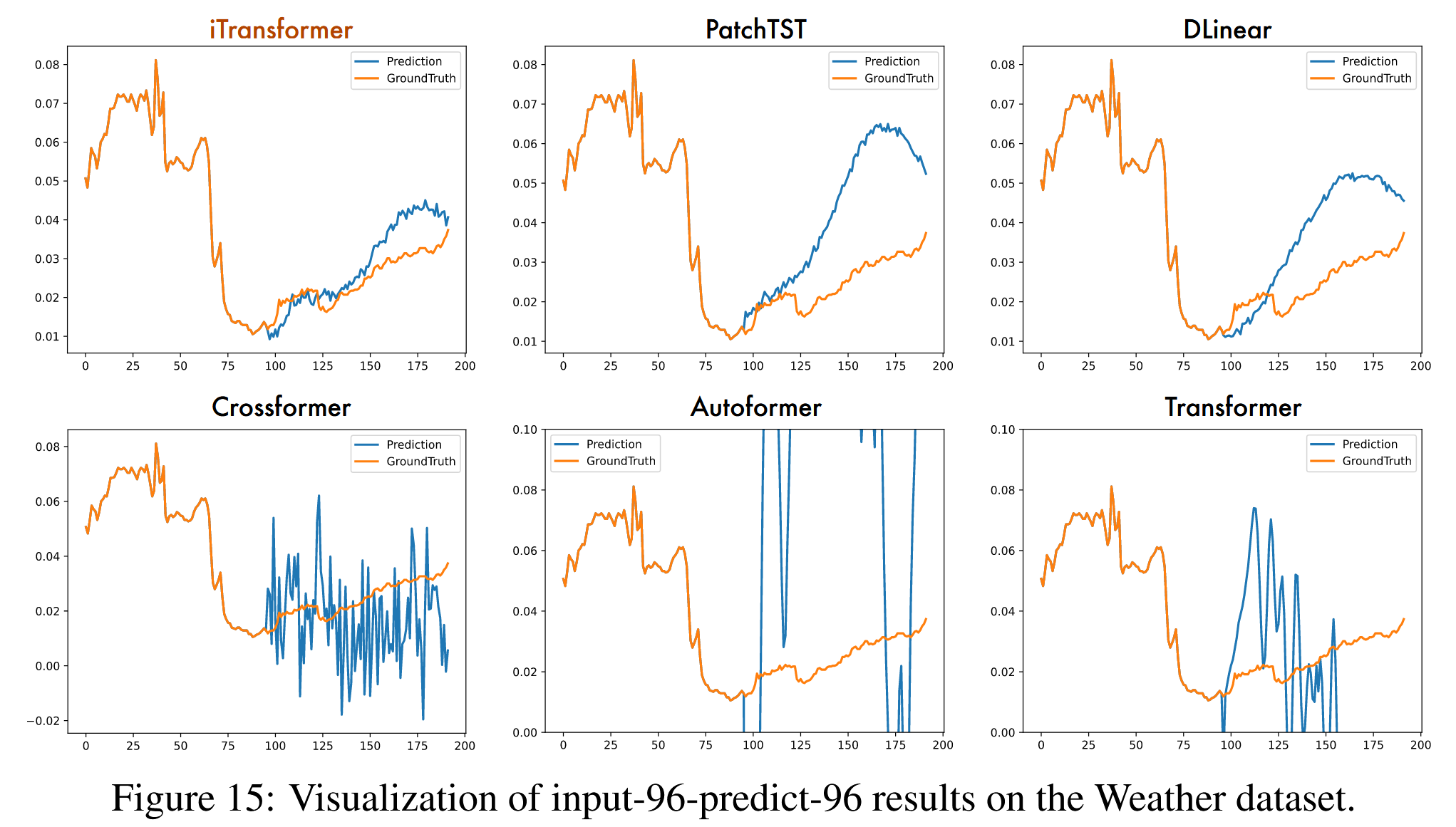
image-20241129182533032
图 15:天气数据集上输入-96-预测-96 结果的可视化。
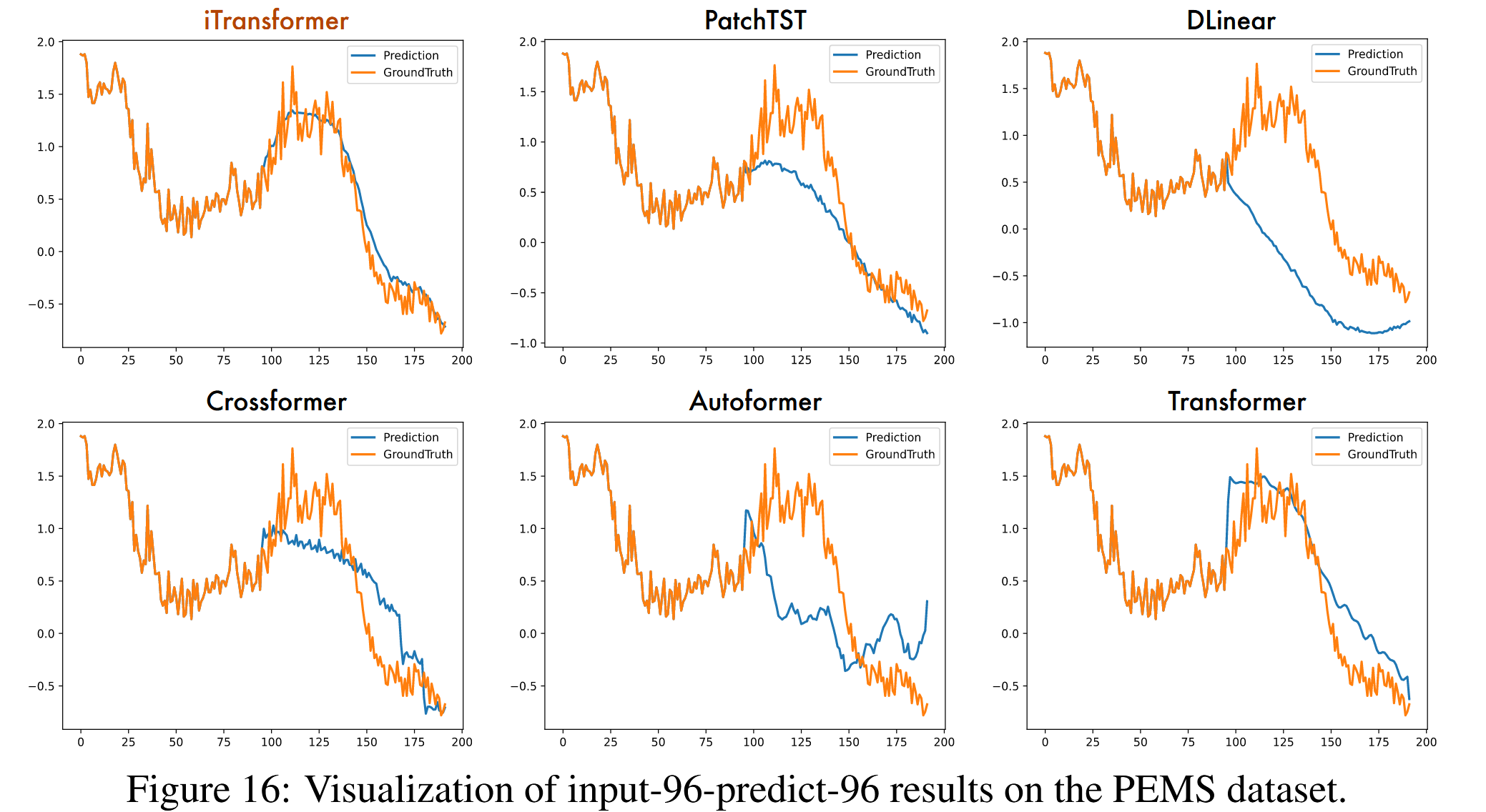
image-20241129182630449
图 16:PEMS 数据集上输入-96-预测-96 结果的可视化。
E.3嵌入时间戳的多元点的风险
如前所述,先前Transformer的嵌入方法融合了代表潜在延迟事件和不同物理测量的多个变量,这可能无法学习以变量为中心的表示并导致无意义的注意力图。我们提供交通数据集(Liu等人,2022a)的可视化案例,该数据集是从洛杉矶城市道路不同区域的传感器收集的。如图17所示,我们可以观察到数据集的多元时间序列之间存在很强的相关性,同时它们也表现出明显的相位偏移,这是由于每个系列描述的道路占用率存在系统时间滞后。由于传感器安装在高速公路的不同区域,一个事件(如交通堵塞)会以不同的延迟影响道路占用率。
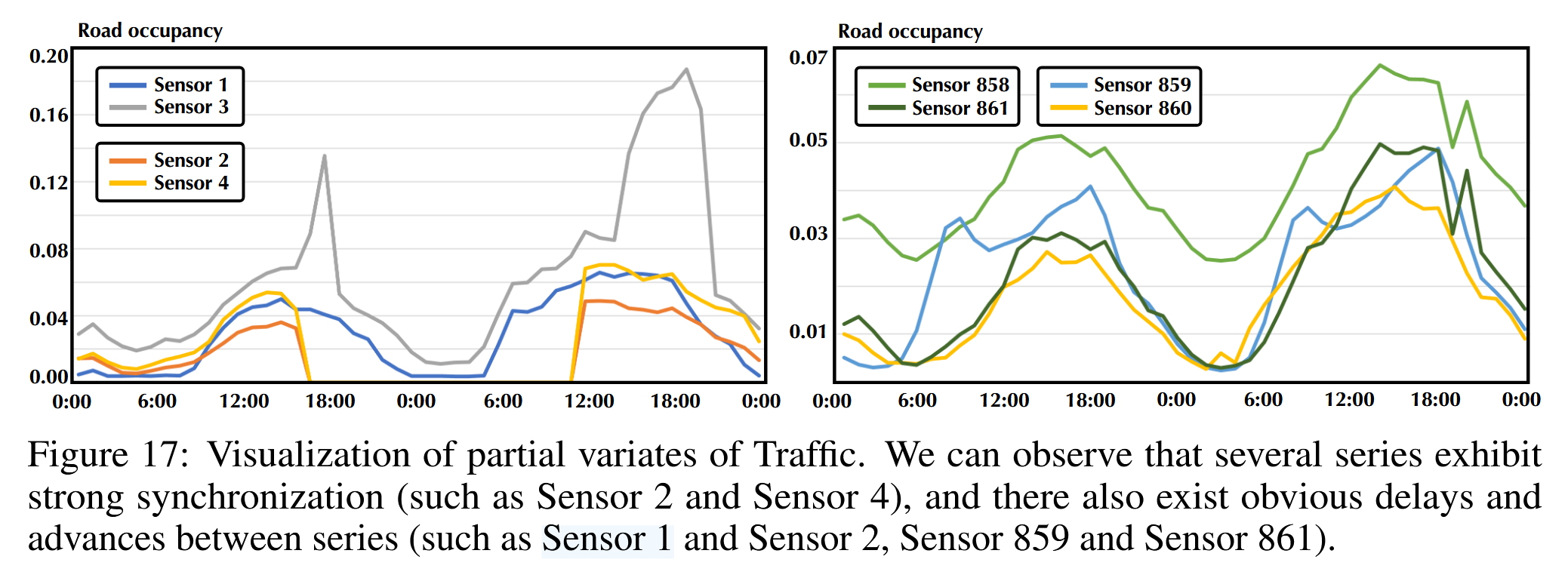
image-20241128210130372
图17:交通数据集部分变量的可视化。我们可以观察到几个系列表现出强烈的同步性(如Sensor 2和Sensor 4),并且系列之间也存在明显的延迟和提前(如Sensor 1和Sensor 2,Sensor 859和Sensor 861)。
此外,我们在表6中观察到交通数据集的第二和第三种设计(对时间标记应用注意力)的性能显著下降。在我们看来,通过注意力捕获时间依赖性不是一个大问题。但这是基于每个时间戳的时间点本质上反映相同事件以包含语义表示的事实。由于时间点之间存在固有的延迟,除非模型有一个扩大的各自领域来了解衰减或因果过程,否则由于无意义的注意图,性能会大大降低。
其他风险可能来自不同的变量测量,例如在天气数据集(Wu等人,2021)中组织不同的气象指标(温度和降雨量),以及在ILI(Wu等人,2023)中相同观测的数量和比例。鉴于这些潜在风险,iTransformer提出了一种新的范式,即将整个系列嵌入为变量标记,这在广泛的实际场景中可能更稳健,例如延迟事件、不一致的测量、不规则(不均匀间隔)的时间序列、监视器的系统延迟以及生成和记录不同时间序列的时间间隔。
表 6:iTransformer 的完整消融实验结果。我们在相应的维度上应用不同组件来学习多变量相关性(变元)和序列表示(时间),并对 Transformer 的特定组件进行了去除实验。
image-20241128174445914
F 完整结果
F.1 全面提升结果
我们在表7中比较了Transformer和iTransformer在所有数据集上的性能。结果显示出一致且显著的提升,表明在倒置维度上的注意力机制和前馈网络极大地增强了Transformer在多元时间序列预测中的能力。这为构建广泛时间序列数据的基础模型指明了方向。
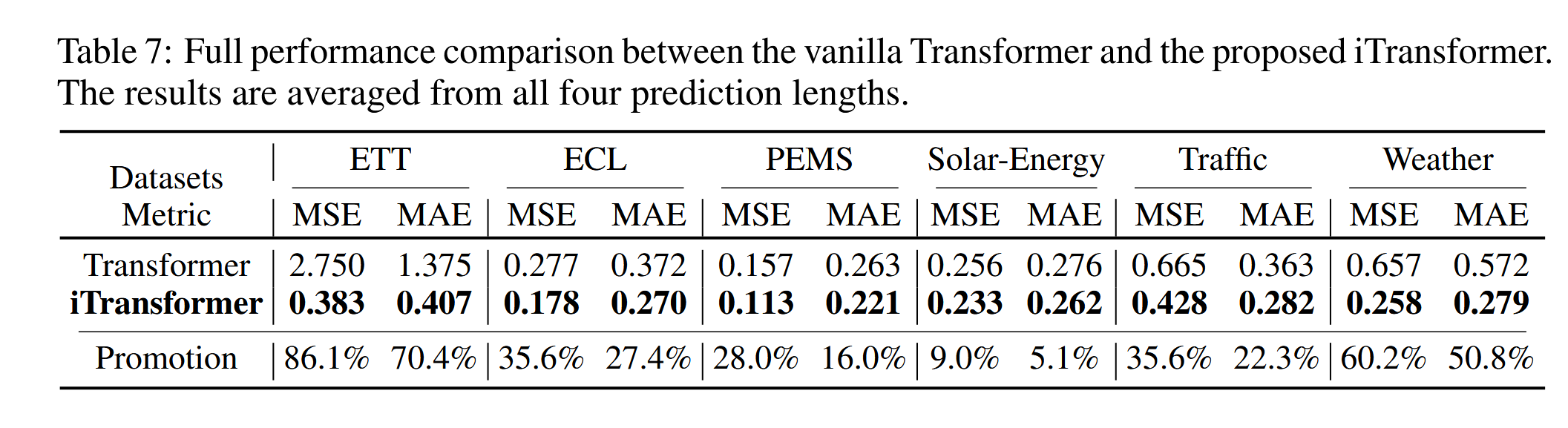
image-20241129205108824
F.2 框架通用性结果
我们将提出的倒置框架应用于Transformer及其变体:Transformer(Vaswani, 2022)、Reformer(Kitaev等, 2020)、Informer(Li等, 2021)、Flowformer(Wu等)、Flashformer(Dao等, 2022)。由于篇幅限制,表2中展示了平均结果,我们在表8中提供了补充的预测结果。结果表明,我们的iTransformers框架能够持续提升这些Transformer变体的性能,并充分利用高效注意力机制的发展。
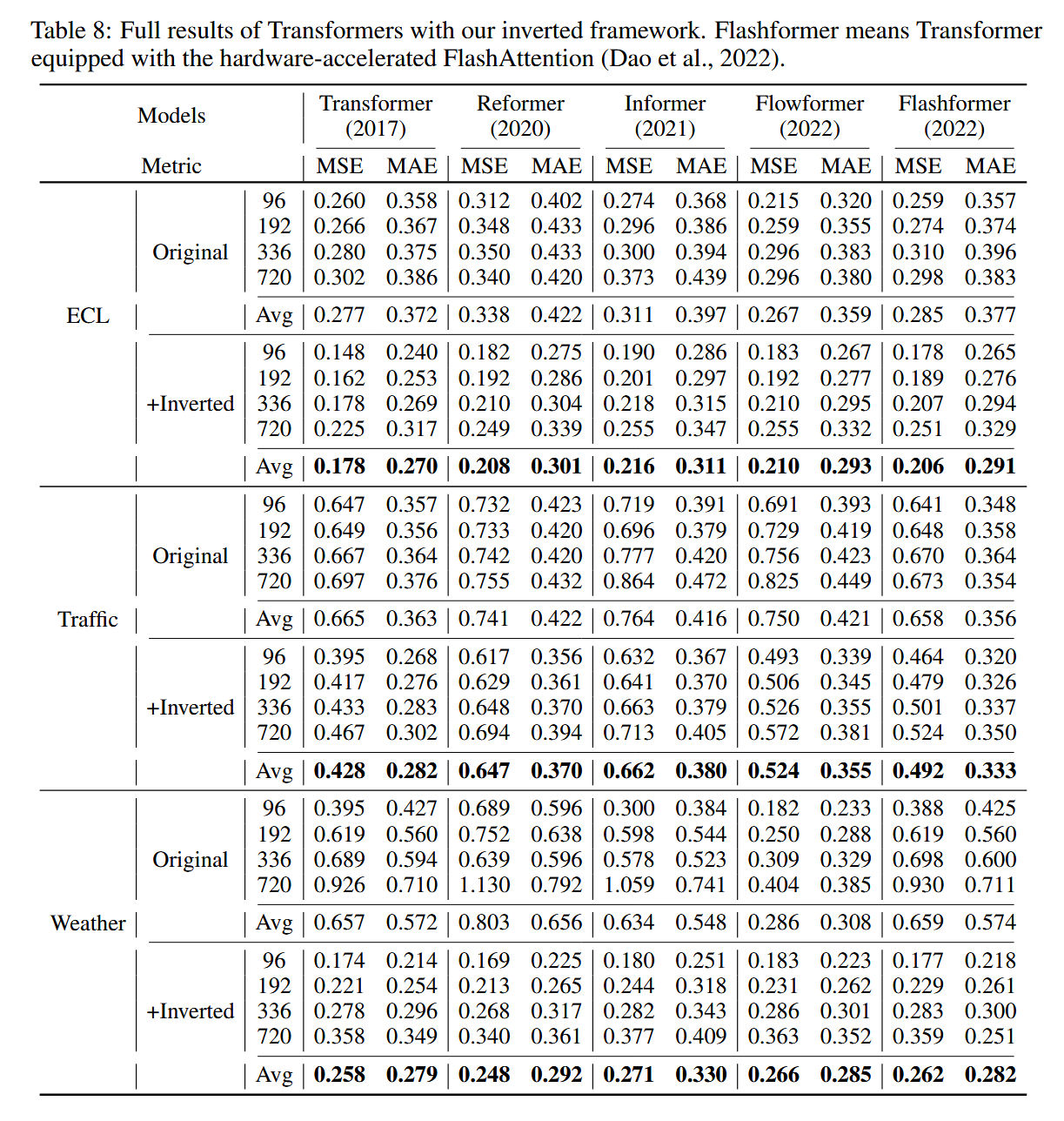
image-20241129205418762
F.3 变量泛化的完整结果
我们将每个数据集的变量分为五个文件夹,使用一个文件夹中的20%变量训练模型,并直接预测所有变量而无需微调。我们采用两种策略来实现Transformer对未见变量的泛化:
-
CI-Transformers(Nie等, 2023):通道独立方法将时间序列的每个变量视为独立通道,并使用共享的主干网络进行训练。在推理阶段,模型逐个预测变量,但此过程可能耗时。
-
iTransformers:由于注意力机制的灵活性,输入的token数量可以动态变化,因此变量数量不再受到训练和推理过程的限制,甚至可以让模型在任意变量上进行训练。表18中的结果显示,iTransformers可以在仅用20%变量训练的情况下,对所有变量完成预测,并具备学习可迁移表示的能力。
如图18所示,ITransformer可以用20%的变量进行自然训练,并具有学习可转移表征的能力,完成对所有变量的预测。
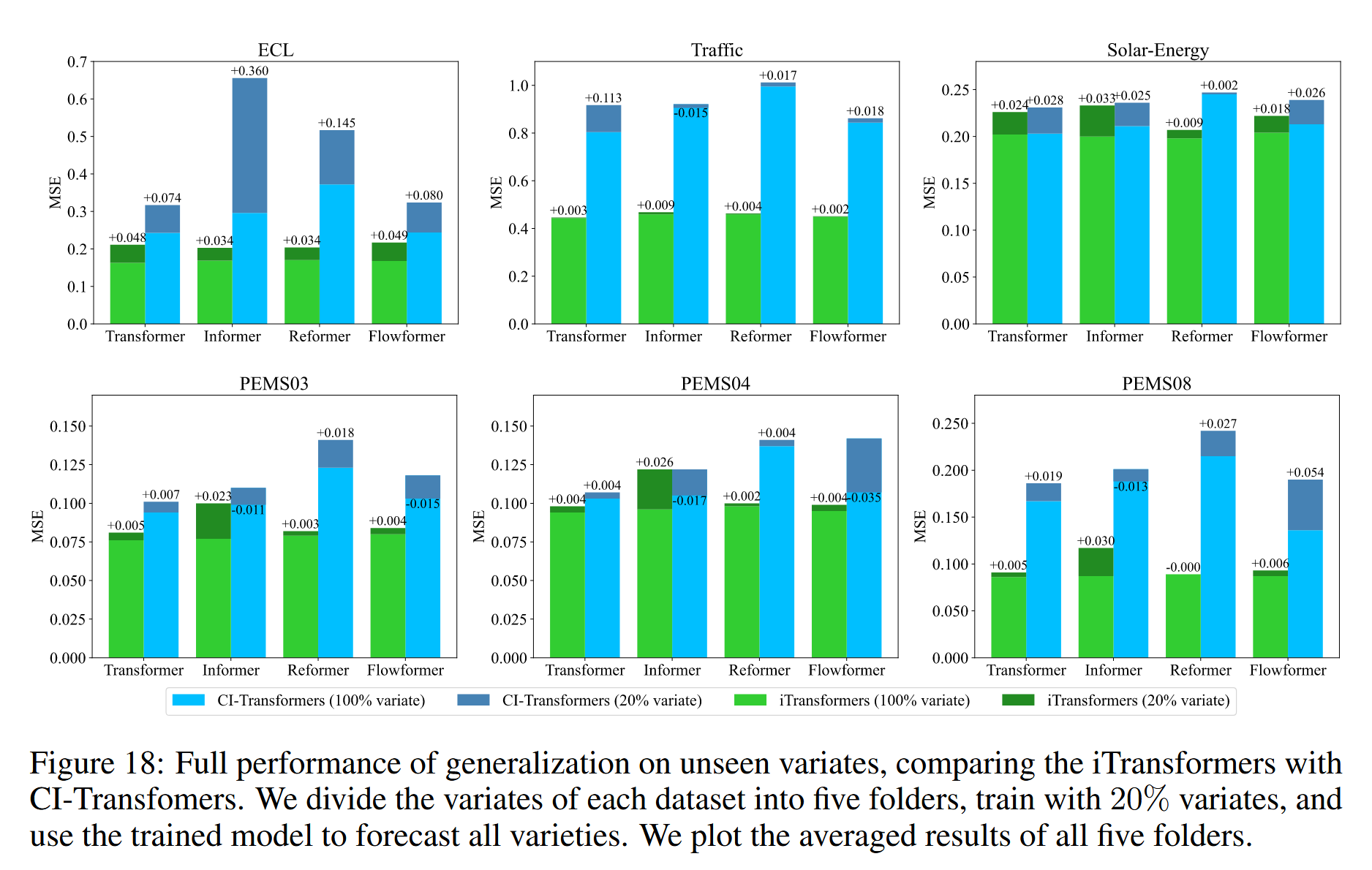
image-20241129210741670
F.4完整预测结果
由于正文空间限制,完整的多元预测结果在以下部分提供。我们在具有挑战性的预测任务上广泛评估了竞争模型。表9包含了来自PEMS(Liu等人,2022a)的四个公共子集的预测结果。表10包含了九个公认的预测基准的所有预测长度的详细结果。表11记录了支付宝服务器负载预测的市场结果。所提出的模型在实际预测应用中实现了全面的最先进水平。
表9:PEMS预测任务的完整结果。我们根据SCINet(2022a)的设置,在不同预测长度下比较了广泛的竞争模型。所有基线的输入长度设置为96。Avg表示所有四个预测长度的平均结果。
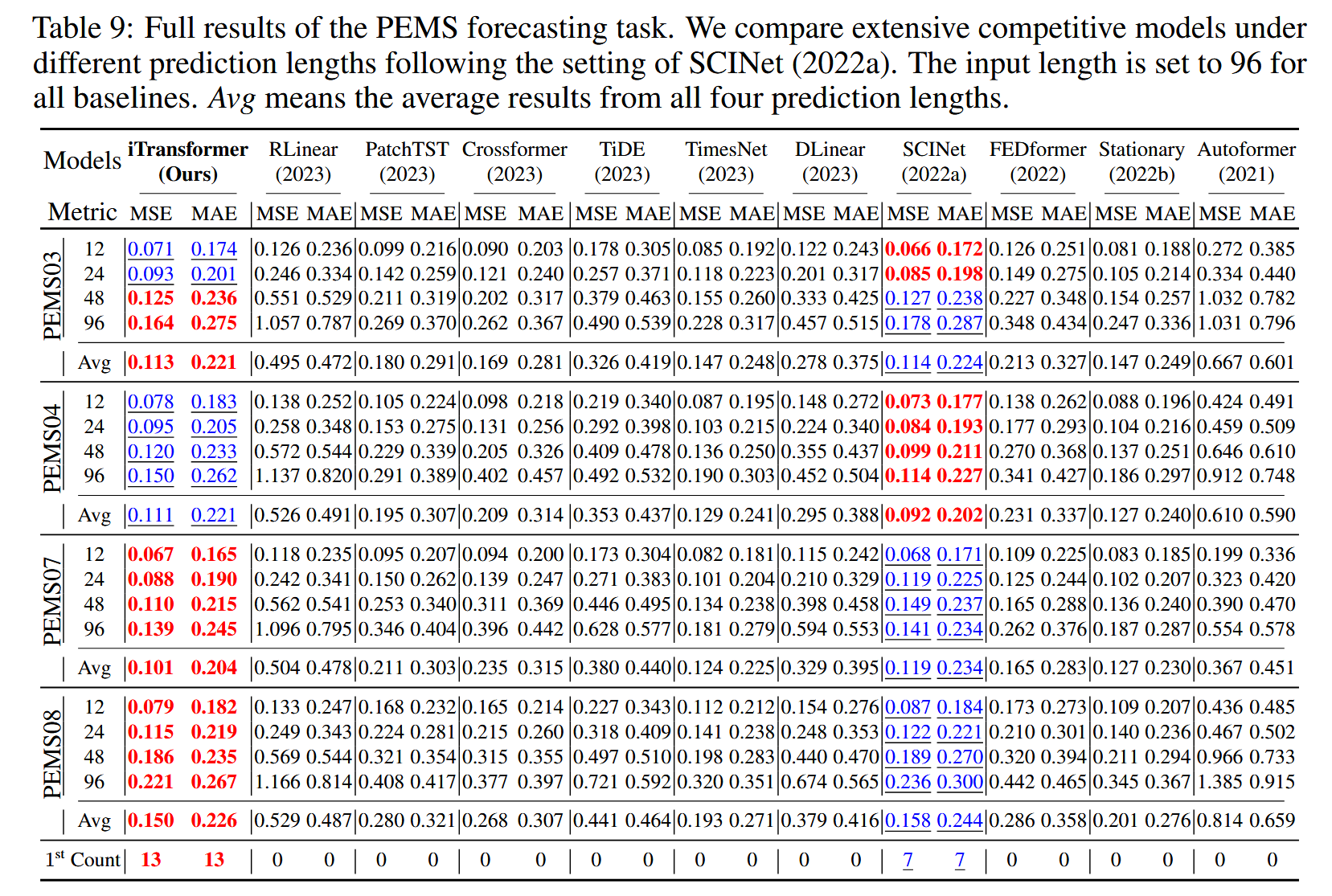
image-20241129211223751
表10:长期预测任务的完整结果。我们根据TimesNet(2023)的设置,在不同预测长度下比较了广泛的竞争模型。所有基线的输入序列长度设置为96。Avg表示所有四个预测长度的平均结果。
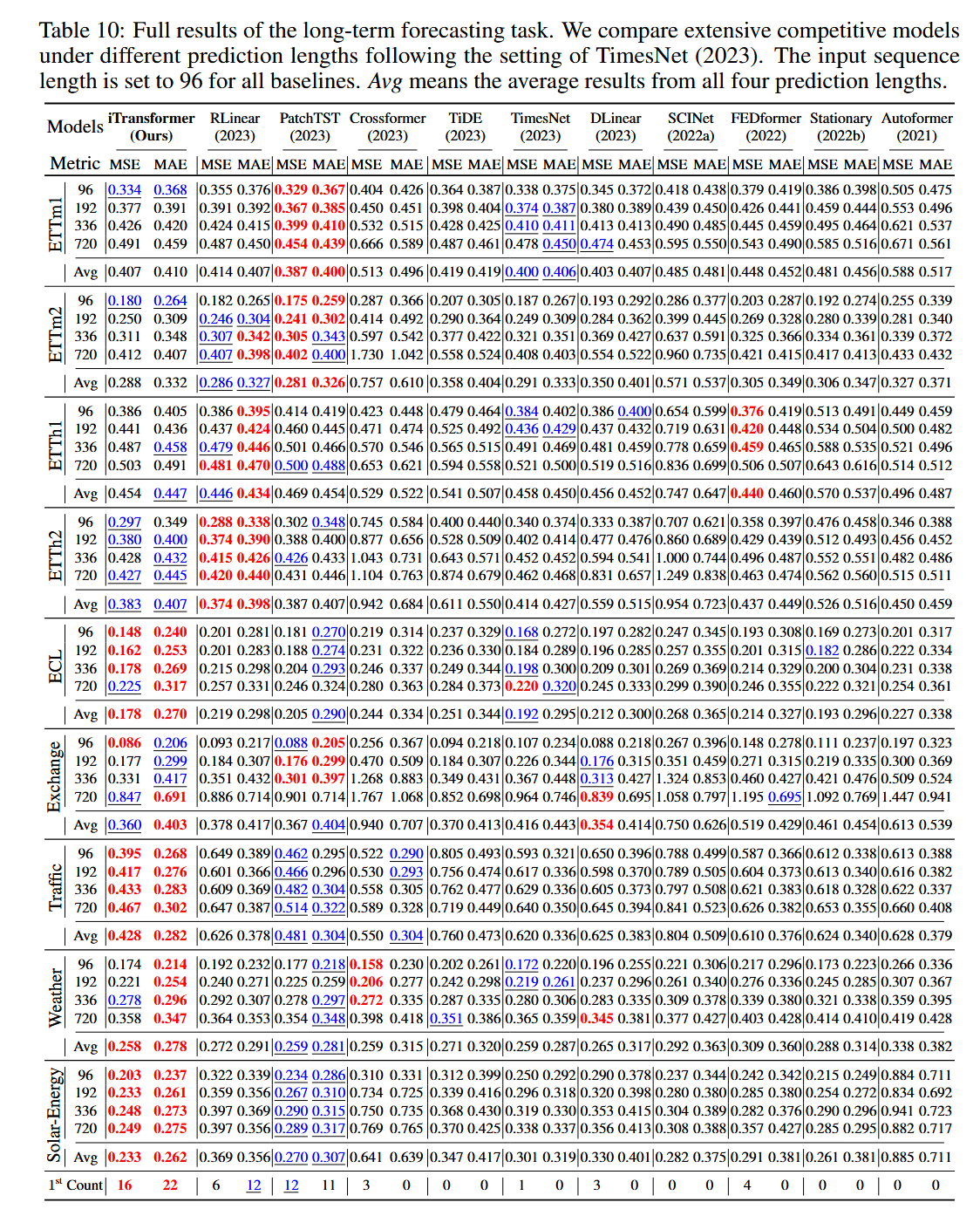
image-20241129211308621
表 11:市场数据集的全部结果。我们在真实交易预测任务中比较了大量有竞争力的模型。Avg 表示所有预测长度的平均结果。
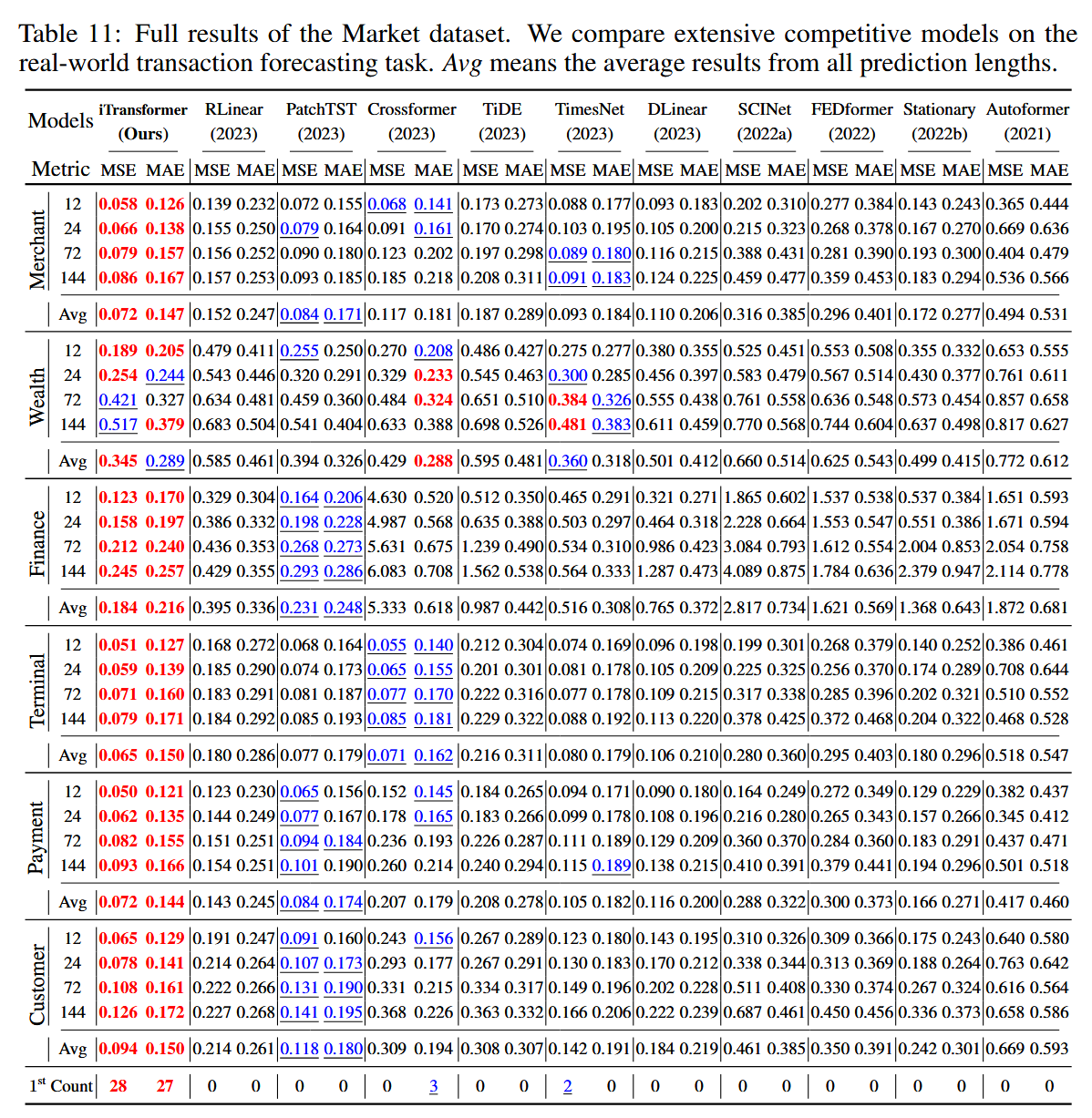
image-20241129211355243
G.讨论与进一步改进
G.1对无架构方法的讨论
通道独立性(CI)(Nie等人,2023)将时间序列的变量视为独立的,并采用共享主干,作为一种无架构方法,在预测中越来越受欢迎,并提高了性能。最近的研究(Han等人,2023;Li等人,2023)发现,虽然通道依赖性(CD)在理想情况下受益于更高的容量,但由于样本稀缺,CI可以极大地提高性能,因为目前大多数预测基准都不够大。我们认为使变量独立是至关重要的,特别是当存在如附录E.3中提到的嵌入潜在风险时,这会导致CD的理想模型容量受到过度局部化感受野的限制。然而,CI的本质,即单变量地看待多元时间序列,可能会导致训练和推理耗时,并成为可扩展性的障碍。此外,多元相关性无法被明确利用。与这些研究垂直,iTransformer利用原生Transformer模块重新调整架构以解决这些问题。RevIN(Kim等人,2021)和平稳化(Liu等人,2022b)作为无架构技术已广泛应用于分布偏移(非平稳性)。这些研究努力更好地揭示时间依赖性。这在iTransformer中通过层归一化实现,但仍有进一步改进的空间来处理分布偏移。
G.2对线性预测器的讨论
线性预测器在建模时间依赖性方面具有天然优势。密集加权(Zeng等人,2023;Li等人,2023)可以揭示同一变量的时间点之间的无测量关系。更先进的线性预测器专注于结构逐点建模(Oreshkin等人,2019;Liu等人,2022a;2023)。相比之下,iTransformer特别擅长预测高维时间序列(具有复杂相关性的众多变量,这在实际预测应用中对从业者来说可能是常见和现实的)。对于变量相关性,嵌入保持变量独立,并且注意力模块可以应用于挖掘它。在单变量场景下,iTransformer实际上变成了一个可堆叠的线性预测器(注意力退化),这为更好地利用时间依赖性留下了进一步增强的空间。
G.3对Transformer的讨论
我们强调,iTransformer实际上提出了一种思考多元时间序列模态的新视角,具体来说,如何考虑变量和标记化。我们在图19中列出了几个代表。Transformer将时间序列视为自然语言,但时间对齐的嵌入可能会在多维序列中带来风险。通过扩大感受野可以缓解这个问题。虽然人们认为补丁(Zhang和Yan,2023;Nie等人,2023)可以更细粒度,但它也带来了更高的计算复杂性以及时间未对齐补丁之间的潜在交互噪声。如果当前由多层感知机(MLP)实现的嵌入通过更多归纳偏差(如时间卷积网络(TCN))得到增强,它可能在变量标记范式下处理更稳健的情况,并享受Transformer具有可变数量标记的灵活性。
我们相信Transformer的能力和可扩展性已经在广泛的领域中得到了验证,但在基于倒置架构精心设计组件方面仍有改进空间,例如用于多元相关性的高效注意力、分布偏移下的结构时间依赖性建模、精细变量标记化和精心设计的嵌入机制。
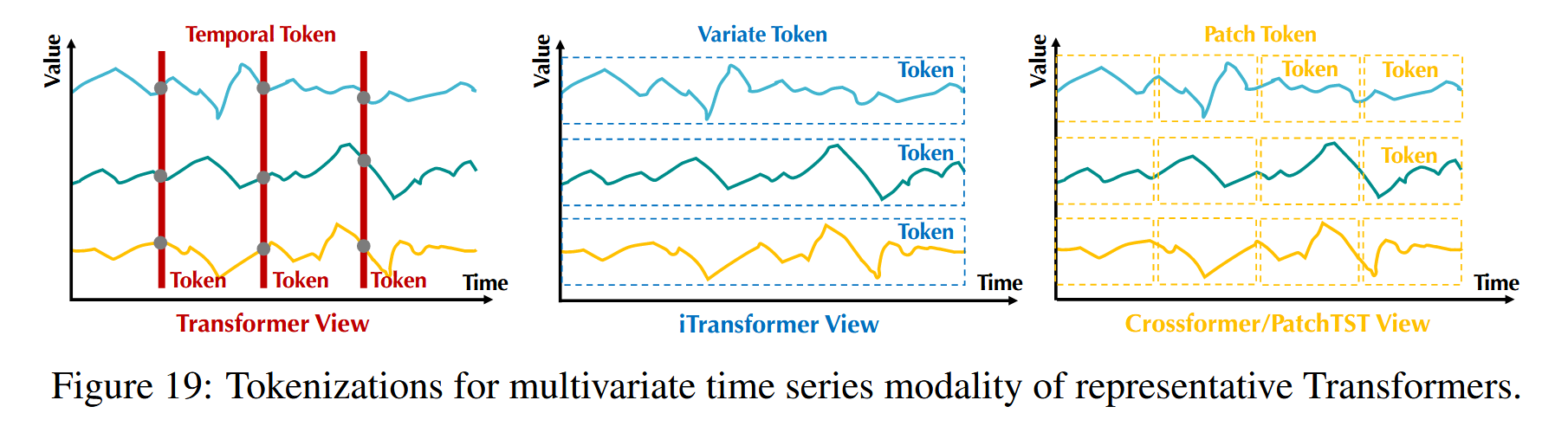
image-20241129214554851
图19:代表性Transformer的多元时间序列模态的标记化。

















 1447
1447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









