







————————
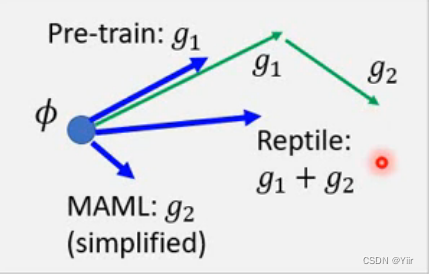
当时写下这个可能是为了记录Reptile的这张图,后来结果也忘记更新了
更新一个自己学习元学习的课程:
李宏毅大佬讲的,讲的超好!感兴趣可以看,时间也很短,入股不亏:【元学习】【李宏毅】少样本&元学习( Meta Learning)最新机器学习课程!_哔哩哔哩_bilibili
最后,贴上来我项目中用的关于meta-learning的代码吧,如果有不对的地方还请大家多多指教。
#首先进行一步meta-training
for iteration in range(niterations):
loop = tqdm(range(task_num))
for i in loop:
# Generate task
(true_pha, true_fgr), true_bgr = next(iter(dataloader_train_meta))#随机取bn个数据
weights_before = deepcopy(model.state_dict()) # 得到weight
# true_pha=1*512*512 true_fgr=3*512*512 true_bgr=3*512*512
true_pha = true_pha.cuda(non_blocking=True)
true_fgr = true_fgr.cuda(non_blocking=True)
true_bgr = true_bgr.cuda(non_blocking=True)
true_pha, true_fgr, true_bgr = random_crop(true_pha, true_fgr,
true_bgr) # 在这里进行了一个随即裁剪,把他们都变成了383*463(这个h和w都是随机数生成出来的)
# true-src是background的clone()
true_src = true_bgr.clone()
# Augment with shadow
aug_shadow_idx = torch.rand(len(true_src)) < 0.3
if aug_shadow_idx.any():
aug_shadow = true_pha[aug_shadow_idx].mul(0.3 * random.random())
aug_shadow = T.RandomAffine(degrees=(-5, 5), translate=(0.2, 0.2), scale=(0.5, 1.5), shear=(-5, 5))(
aug_shadow)
aug_shadow = kornia.filters.box_blur(aug_shadow, (random.choice(range(20, 40)),) * 2)
true_src[aug_shadow_idx] = true_src[aug_shadow_idx].sub_(aug_shadow).clamp_(0, 1)
del aug_shadow
del aug_shadow_idx
# Composite foreground onto source
true_src = true_fgr * true_pha + true_src * (1 - true_pha)
# Augment with noise
aug_noise_idx = torch.rand(len(true_src)) < 0.4
if aug_noise_idx.any():
true_src[aug_noise_idx] = true_src[aug_noise_idx].add_(
torch.randn_like(true_src[aug_noise_idx]).mul_(0.03 * random.random())).clamp_(0, 1)
true_bgr[aug_noise_idx] = true_bgr[aug_noise_idx].add_(
torch.randn_like(true_bgr[aug_noise_idx]).mul_(0.03 * random.random())).clamp_(0, 1)
del aug_noise_idx
# Augment background with jitter 这一块都是数据增强的操作了,
aug_jitter_idx = torch.rand(len(true_src)) < 0.8
if aug_jitter_idx.any():
true_bgr[aug_jitter_idx] = kornia.augmentation.ColorJitter(0.18, 0.18, 0.18, 0.1)(
true_bgr[aug_jitter_idx])
del aug_jitter_idx
# Augment background with affine
aug_affine_idx = torch.rand(len(true_bgr)) < 0.3
if aug_affine_idx.any():
true_bgr[aug_affine_idx] = T.RandomAffine(degrees=(-1, 1), translate=(0.01, 0.01))(
true_bgr[aug_affine_idx])
del aug_affine_idx
for _ in range(innerepochs): # 在里面的内循环,其实就是k
pred_pha, pred_fgr, pred_err = model(true_src, true_bgr)[:3]
loss = compute_loss(pred_pha, pred_fgr, pred_err, true_pha, true_fgr)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
optimizer.zero_grad()
loop.set_postfix(loss = loss.item())
# for param in model.parameters():
# param.data -= innerstepsize * param.grad.data
# Interpolate between current weights and trained weights from this task
# I.e. (weights_before - weights_after) is the meta-gradient
weights_after = model.state_dict()
outerstepsize = outerstepsize0 * (1 - iteration / niterations) # linear schedule
model.load_state_dict({name:
weights_before[name] + (
weights_after[name] - weights_before[name]) * outerstepsize
for name in weights_before})
weights_after = model.state_dict()
model.load_state_dict({name:
weights_before[name] + (weights_after[name] - weights_before[name]) / task_num
for name in weights_before})
torch.save(model.state_dict(), f'checkpoint/{args.model_name}/meta.pth')(主要看多层循环)
此外,对于不同学习方法的总结如下:
















 2751
2751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









