






随着人脸识别系统在安全关键环境中的部署日益增多,威胁行为者正在开发针对各种攻击点的复杂攻击策略。在这些攻击策略中,面部重建攻击是一个主要的威胁。面部重建攻击的主要目的是创建伪造的生物特征图像,这些图像类似于存储的生物特征模板中的真图,然后利用这些图像来绕过系统。
现有人脸重建攻击的局限性:
- 主要针对目标系统: 现有研究主要集中在攻击目标系统,即使用伪造图像绕过同一个系统。
- 缺乏迁移攻击场景: 对迁移攻击场景,即使用伪造图像绕过其他未知的系统,关注不足。
本文讲述的人脸重建转移攻击(FRTA)成功重建一个可以替换真实人脸图像的图像,并在未知的编码器上成功攻击。相比于普通攻击,FRTA 具有更大的破坏性,因为它可以绕过更广泛的人脸识别系统。

1 相关背景
1.1 基于特征的人脸重建方法
- NBNet: 首先提出基于特征的人脸重建方法,但重建质量较差。
- LatentMap: 将特征投影到 StyleGAN2 的潜在空间,生成逼真的人脸图像,但存在身份错乱问题。
- DiBiGAN: 基于可逆度量学习的生成框架,实现一对一的特征和图像配对,但需要大量数据和时间进行训练。
- GaussBlob: 通过迭代采样随机高斯块来生成人脸图像,但质量较低。
- EigenFace: 基于特征相似度进行人脸重建,但图像存在严重噪声。
- FaceTI: 利用 StyleGAN3 的潜在空间进行人脸重建,但 GAN 框架容易发生模式坍塌。
1.2 OOD 泛化相关研究
- 寻找平坦最小值: 研究表明,损失函数表面的平坦性与泛化能力相关。
- 权重平均: 通过平均不同训练轨迹上的模型参数,寻找平坦最小值,从而提高泛化能力。
- 伪标签: 在标签信息稀缺的情况下,通过生成伪标签来提高泛化能力。
2 方法论
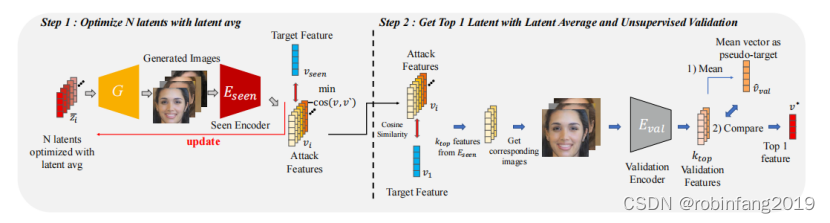
为了解决面部重建转移攻击(FRTA)问题,本文提出了一种新颖的方法,称为平均潜在搜索与伪目标无监督验证(Averaged Latent Search with Unsupervised Validation with pseudo target,简称ALSUV)。这个方法是受OOD(Out-of-Distribution,分布外)泛化启发的,目的是在未见过的编码器上提高生成样本的泛化能力。
ALSUV方法包括以下几个关键步骤:
2.1 多潜在优化
优化多个潜在向量。我们初始化多个潜在向量并使用基于梯度的更新方法(如Adam优化器)并行优化它们。
关键点如下:
- 初始化多个潜在向量:随机初始化多个潜在向量 z1, z2, …, zn。这些潜在向量可以随机生成,也可以从潜在空间中采样得到。
- 并行优化潜在向量:使用梯度下降法或其他优化算法,同时优化每个潜在向量。每个潜在向量的优化目标是使其生成的图像在已知编码器 θseen 上与目标特征 vθseen 具有高相似度。
- 生成候选样本:通过优化得到的潜在向量,生成多个候选图像。这些候选图像可以用于后续的无监督验证步骤,以选择最佳的泛化样本。
2.2 潜在平均
在优化过程中,记录每个潜在向量的轨迹,即在每个优化步长处得到的潜在向量值。在优化轨迹上平均潜在向量,以平滑损失函数表面并提高泛化能力。
2.3无监督验证
- 使用验证编码器:选择一个与已知编码器 θseen 不同的编码器作为验证编码器 Eval。验证编码器 Eval 不参与优化过程,只用于评估重建图像的质量。
- 使用替代的验证编码器来评估重建样本,并构造一个伪目标,该目标是通过平均攻击目标中排名靠前的k个潜在向量重建的特征来形成的。
- 使用验证编码器 Eval 计算所有候选图像与伪目标之间的距离。选择距离伪目标最近的候选图像作为最佳泛化样本。
3 实验
本文在 LFW、CFP-FP 和 AgeDB-30 数据集上进行了实验,并与多种基线方法进行了比较。实验结果表明,本文方法在攻击成功率和识别率方面均优于现有方法,并且在未知编码器上取得了良好的泛化能力。
3.1 实验配置
- 生成模型: StyleGAN2,训练数据集为 FFHQ-256。
- 优化器: Adam,学习率从 0.1 开始,迭代 50 次后除以 10。
- 超参数: n = 100 (潜在向量数量), t = 70 (潜在平均轨迹长度), ktop = 10 (无监督验证样本数量)。
- 验证编码器: Swin-T。
3.2 数据集和网络
3.2.1 数据集
3.2.1.1 LFW(Labeled Faces in the Wild)
一个无约束自然场景人脸识别数据集,包含超过13,000张从互联网上获取的人脸图像。
- 数据集中共有5749个身份,其中1680个人有两张或两张以上的人脸图片。
- 图片尺寸为250x250,绝大部分为彩色图像,但也存在少许黑白人脸图片。
- LFW数据集主要用于测试人脸识别的准确率,包含一些难以处理的问题,如光照变化、表情、年龄和姿势等。
3.2.1.2 CFP-FP(Celebrities in Frontal Pro文件)
一个姿态变化影响较大的数据集,包含500个人物对象,每个人物有10张正面照和4张形象照。数据集主要用于验证人脸识别算法在不同姿态下的表现。
3.2.1.3 AgeDB-30
AgeDB-30是AgeDB数据集的一个子集,包含440个人的脸,共计12,240张人脸图像。
- 数据集的主要特点是年龄变化差异大,适用于研究与年龄相关的识别问题。
- AgeDB-30数据集还包括模拟口罩人脸数据集,进一步增加了识别任务的复杂性。
3.2.2 网络
FaceNet、MobFaceNet、ResNet50、ResNet100、Swin-S 和 VGGNet。
3.3 评估指标
- 攻击成功率 (SAR): 测量重建图像通过正面验证测试的比例。
- 识别率: 测量重建图像在人脸识别任务中的识别准确率。
3.4 实验结果
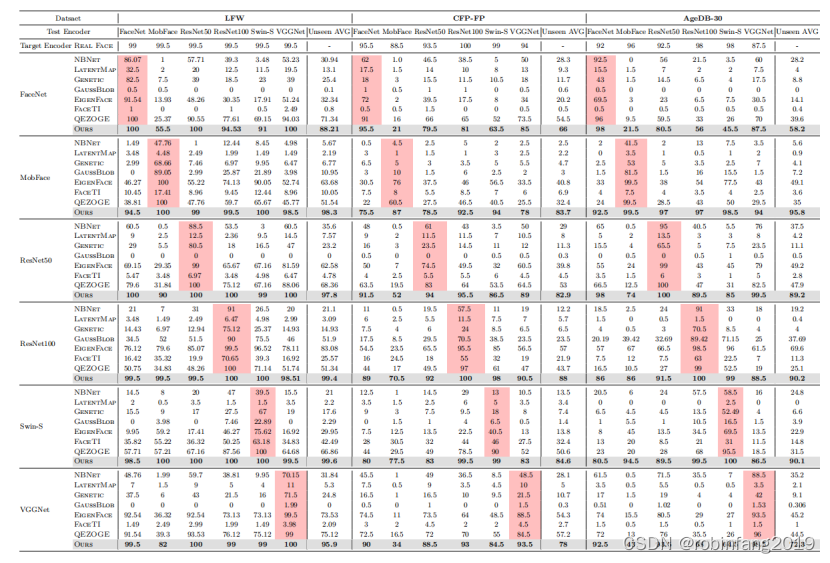
本文方法在所有数据集和编码器上均取得了最佳的攻击成功率和识别率。
3.4.1 消融实验
通过控制 ALSUV 的各个组件,验证了多潜在优化、潜在平均和无监督验证的有效性。
3.4.2 超参数分析
分析了潜在向量数量、潜在平均轨迹长度和无监督验证样本数量对攻击性能的影响。
3.4.3 潜在平均和损失函数表面
通过可视化损失函数表面,验证了潜在平均对平滑损失函数表面和提高泛化能力的作用。
3.4.4 无监督验证与伪目标
在本文提出的 FRTA 方法中,无监督验证和伪目标两个组件起着至关重要的作用,共同提高了攻击图像在未见编码器上的泛化能力。
3.4.4.1 无监督验证
- 目标: 利用未见编码器的特征空间来搜索更具泛化能力的样本。
- 方法: 使用一个额外的编码器作为验证编码器,评估每个优化后的潜在向量在未见编码器上的表现,并选择表现最好的潜在向量作为最终攻击图像的生成依据。
- 优势:
避免了仅使用已知编码器进行优化导致的过拟合问题。
能够发现更接近真实图像特征的潜在向量,从而生成更具欺骗性的攻击图像。
3.4.4.2 伪目标
由于无监督学习的特点,验证编码器没有对应的标签信息,因此无法直接使用真实图像特征作为目标进行评估。构建伪目标,作为评估潜在向量的替代目标。
3.4.4.2.1 方法
- 使用已知编码器生成多个潜在向量的对应图像。
- 从中选出与目标特征最相似的 k 个潜在向量。
- 将这 k 个潜在向量生成的图像在验证编码器上提取的特征进行平均,得到伪目标。
3.4.4.2.2 优势
- 伪目标虽然不是真实目标的精确近似,但能够有效缓解潜在向量优化过程中的过拟合问题。
- 使用多个潜在向量的特征进行平均,比单个潜在向量的特征更能代表真实图像特征,从而提高攻击图像的泛化能力。
3.4.5 图像质量
通过定性和定量分析,验证了本文方法重建的图像质量较高。
3.4.5.1 定性分析
- 视觉评估: 通过观察重建图像的视觉效果,评估其是否真实、自然,以及是否保留了目标身份的特征。
- 与真实图像的比较: 将重建图像与真实图像进行比较,评估其相似度。
3.4.5.2 定量分析
- SER-FIQ: 一种基于随机嵌入鲁棒性的无监督人脸图像质量评估指标,其值越高表示图像质量越好。
- CR-FIQA: 一种基于样本相对可分类性的无监督人脸图像质量评估指标,其值越高表示图像质量越好。















 2089
2089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









