







一、实验目的
了解主成分分析算法的基本思想、实现步骤,并用代码实现。
二、实验内容
CPU数据集是加州大学欧文分校机器学习数据库(UC irvine machine learning repository,网址为http://archive.ics.uci.edu/ml/)中的一个,名为computer hardware,或者CPU performance,缩写为CPU(“machine.data”文件中为数据,“machine.names”文件中为数据说明)。该数据完整版包括209个样本,每个样本有10个属性,选择其中的6个数值属性,如表1所示,这是该数据集的一个子集。
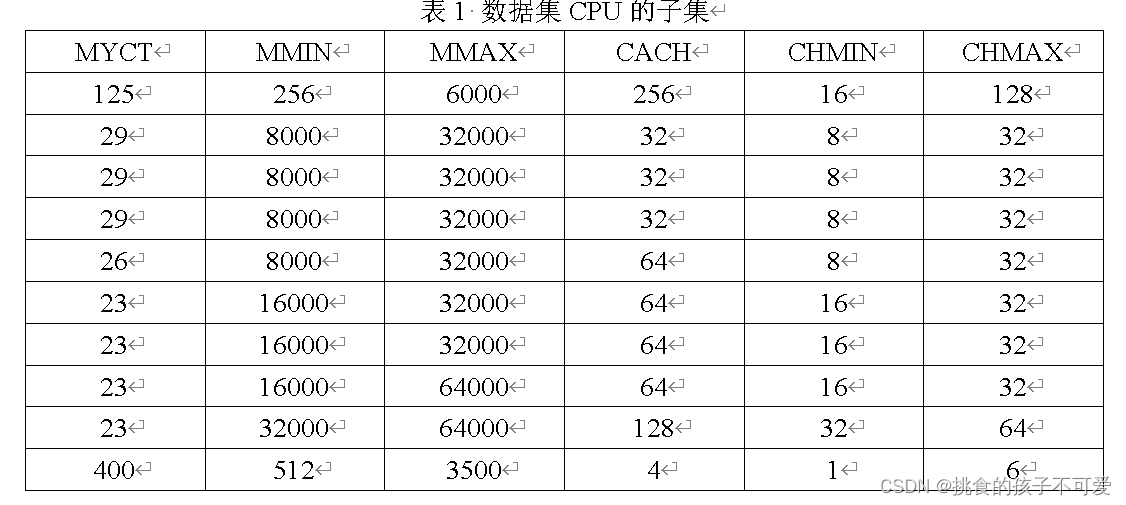
对该数据集利用主成分分析属性选择方法,为此包含6个属性值209个样本的数据集进行属性提取(用原始属性的线性组合表达),累积贡献率设为90%。
三、实验代码以及结果:
import numpy as np
import pandas as pd
# 绘图
import seaborn as sns
import matplotlib.pyplot as plt
from factor_analyzer.factor_analyzer import calculate_bartlett_sphericity
from factor_analyzer.factor_analyzer import calculate_kmo
from sklearn import preprocessing
def loadData(fn):
data = pd.read_csv(fn,sep=',',names=['vendor_name','Model','MYCT','MMIN','MMAX','CACH','CHMIN','CHMAX','PRP','ERP'])
print(data)
return data
'''进行球形检验'''
def Bartlett(df):
chi_square_value,p_value = calculate_bartlett_sphericity(df)
print("球形检验卡方、P值:",chi_square_value,p_value)
'''KMO检验'''
def KMO(df):
kmo_all,kmo_model = calculate_kmo(df)
print("KMO检验:",kmo_all)
'''求相关矩阵'''
def RelationMatrix(df):
zdf = preprocessing.scale(df) # 进行标准化
print("标准化后的矩阵:\n",zdf)
print(zdf.shape)
print("*********************")
covZ = np.around(np.corrcoef(zdf.T),decimals=3)
print(covZ.shape)
print(covZ)
return covZ
'''求解特征值和特征向量'''
def FeatureValVec(relationMatrix):
featVal,featVec = np.linalg.eig(relationMatrix)
sortfeatVal = sorted(featVal)[::-1]
sortfeatVec = np.zeros(featVec.shape)
k = 0
for val in sortfeatVal:
print("val:",val)
i = list(featVal).index(val)
sortfeatVec[k] = featVec[i]
k = k+1
return featVal,featVec
'''求均值'''
def MeanX(dataX):
return np.mean(dataX,axis=0)
if __name__ == "__main__":
fn = 'D:\For_Study\BusinessIntelligent\Exp4_PCA\machine.data'
df = loadData(fn)
# 选出相应的列
df_part = df[['MYCT','MMIN','MMAX','CACH','CHMIN','CHMAX','PRP','ERP']]
average = MeanX(df_part)
cov = RelationMatrix(df_part)
featval,featvec = FeatureValVec(cov) #计算特征值、特征向量
print("特征值:",featval)
print("特征向量:",featvec)
# 绘制散点图和折线图
plt.scatter(range(1,df_part.shape[1]+1),featval)
plt.plot(range(1,df_part.shape[1]+1),featval)
plt.title("scree Plot")
plt.xlabel("Factors")
plt.ylabel("Eigenvalue")
plt.grid()
plt.show()
# 求特征值的贡献度
gx = featval/np.sum(featval)
print("各特征根的贡献度:",gx)
# 求特征值的累计贡献度
lg = np.cumsum(gx)
print("各特征根的累计贡献度:",lg)
# 选出主成分
k = [i for i in range(len(lg)) if lg[i] <= 0.90]
if lg[len(k)-1] < 0.90:
k.append(len(k))
k = list(k)
print("选出的主成分:",k)
# 选出主成分对应的特征向量矩阵
selectVec = np.matrix(featvec.T[k]).T
selectVe = selectVec*(-1)
print("主成分对应的特征向量:",selectVec)
# 主成分得分
finalData = np.dot(df_part,selectVec)
print(finalData)
四、小结
本次实验完成了python主成分分析的实现,涉及了较多numpy库中一些函数的使用以及pandas读取文件的内容。主成分分析的主要目的是为了降维,如上题所示,通过降维将8个变量降成了4个变量,他们包含了原始变量的大部分信息。















 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









