







系列文章目录
第1章 专家系统
第2章 决策树
第3章 神经元和感知机
识别手写数字——感知机
第4章 线性回归
第5章 逻辑斯蒂回归和分类
第5章 支持向量机
第6章 人工神经网络(一)
第6章 人工神经网络(二) 卷积和池化
第6章 使用pytorch进行手写数字识别
文章目录
前言
在此之前,我们都是用模型解决简单的二分类、多分类问题或者是回归问题。这一篇开始解决稍微复杂的问题:物体检测。
不同于图片分类时的输入图片仅包含一个物体,并且位于图片中央,占据图片的大部分未知;物体检测的任务恰与之相反,任务目标主要是识别图像中的物体位置,用矩形框标注出物体的位置,同时给出物体类别。

物体检测技术,已经广泛应用于人脸检测 \行人检测系统 \辅助驾驶 车辆检测等等中.
一、物体检测技术
在传统方法中,物体识别可以拆分为两个步骤。第1步是从图像中识别局部特征,物体由局部特征组合构成。第2步是找到能够组合成物体的局部特征,判断它们所属的物体类别,进而确定物体的位置和大小。
图像的局部特征通常是将局部图像颜色和梯度分布描述为向量,相似的纹理或者形状通常具有类似的分布。将物体描述为局部特征组合的方法大致可以分为两类,一类方法类似于自然语言处理中的"词袋模型"。词袋模型将句子和文章描述为单词出现的频率,忽略了单词之间的位置关系。我们也可以忽略局部特征之间的位置关系,将物体视为局部特征的无序组合。另一类方法则把位置关系作为约束条件,那么寻找能够构成物体的特征组合就变成了有约束的优化问题。
人们在使用神经网络解决物体检测问题的时候,最初也采取了分步的策略。由于神经网络已经解决图像分类问题,于是可以将图片的局部拿来进行分类。只要用分类器扫描整幅图像的各个位置,就可以找到物体并将它的类别识别出来。暴力扫描的方式显然是效率低下的,于是人们提出了各种算法来筛选可能存在物体的候选框,减少候选框的数量来提高算法的性能。另一种策略是单步的方法,也叫作端到端的方法,即将整幅图像直接作为输入,同时输出物体框和类别,没有中间步骤。两种方法各有千秋。分步方法通常具有更高的准确率,可以处理大量小物体,但是提取候选框的过程中无法利用物体类别信息,进行物体分类时无法利用图像其他位置的背景信息。端到端的单步方法实现起来更为直接,运行速度通常更快,在识别物体时能够利用整幅图像的背景信息,但是有时会漏掉一些数量较多的小物体。
物体检测算法的发展经历了从传统方法到深度学习方法的转变。以下是一些重要的算法和它们的特点:
- 传统物体检测算法
Haar特征+Adaboost:2001年Viola和Jones提出了基于Haar特征和Adaboost的快速人脸检测方法。这种方法通过集成多个弱分类器来构建一个强分类器,能够实现实时检测。
HOG(Histogram of Oriented Gradients):HOG是一种描述图像局部特征的方法,通过统计图像局部区域的梯度方向直方图来构建特征,广泛应用于物体检测和行人检测。
SVM(Support Vector Machine):支持向量机是一种监督学习模型,用于分类和回归分析。在物体检测中,SVM可以作为分类器来识别图像中的目标。 - 深度学习物体检测算法
R-CNN(Regions with CNN features):R-CNN首先使用选择性搜索(Selective Search)提取候选区域,然后使用CNN提取特征,最后通过SVM进行分类。R-CNN开启了深度学习在物体检测领域的应用。
Fast R-CNN:Fast R-CNN改进了R-CNN的效率问题,通过RoI(Region of Interest)Pooling层来提取固定大小的特征,并且实现了网络的端到端训练。
Faster R-CNN:Faster R-CNN引入了RPN(Region Proposal Network)来自动生成高质量的候选区域,进一步提高了检测速度。
YOLO(You Only Look Once):YOLO将物体检测问题视为一个回归问题,通过单个神经网络直接从图像像素到边界框坐标和类别概率的映射,实现了实时检测。
SSD(Single Shot MultiBox Detector):SSD在不同尺度的特征图上进行检测,能够同时处理不同大小的目标,也适用于实时检测场景。
常用的物体检测数据集
- PASCAL VOC:PASCAL VOC挑战赛是物体检测领域的一个重要基准,提供了丰富的图像和标注,用于评估和训练物体检测算法。
- COCO(Common Objects in Context):COCO数据集包含了大量图像,每张图像中都包含多个目标,提供了更加复杂和多样的场景,是目前最流行的物体检测数据集之一。
- ImageNet:虽然ImageNet主要以分类任务著称,但它也提供了物体检测的挑战,即ImageNet Large Scale Visual Recognition Challenge(ILSVRC)中的物体检测任务。
- Objects365:由旷视科技发布的Objects365数据集是目前最大的物体检测数据集之一,包含63万张图像,覆盖365个类别,提供了更加丰富和多样的数据用于训练和测试物体检测算法。
这些算法和数据集共同推动了物体检测技术的发展和进步,使得计算机视觉系统能够更好地理解和解释图像内容。随着技术的不断演进,未来可能会出现更多高效、准确的物体检测算法和更加丰富多样的数据集。
二、YOLO模型
YOLO模型的全称是You Only Look Once,也就是说,神经网络模型只“看”一次,就输出物体检测的结果,是一种端到端的方法。
前反馈神经网络的输出长度一般是固定的(带有反馈的循环神经网络确实可以产生不固定长度的输出,也可以用于物体检测任务),然而一张图像中物体的数量是不确定的,如何将数量不确定的物体用固定长度的输出向量表示出来,这就是YOLO的关键。
模型设计思路
模型的思路是:将图像划分为大小相等的网格,每个网格负责输出中心点落在其中的物体框。假设物体类别数量为
K
K
K,那么,每个物体框可以用一个长度为
5
+
K
5+K
5+K的向量表示,即
(
t
x
,
t
y
,
t
w
,
t
h
,
c
,
p
1
,
p
2
,
.
.
.
,
p
K
)
(t_x,t_y,t_w,t_h,c,p_1,p_2,...,p_K)
(tx,ty,tw,th,c,p1,p2,...,pK)。前4个元素分别用来计算物体框的中心坐标和物体框的尺寸,第5个元素用于表示物体框中是否识别出物体的置信度(confidence);剩余
K
K
K个元素表示物体属于各个类别的概率。如果将图片切割为
S
×
S
S \times S
S×S个网格,那么神经网络的输出维度为
S
×
S
×
(
5
+
K
)
S \times S \times (5+K)
S×S×(5+K)。
实际物体框的形状并不是完全随机的,如果对图片数据集中的标记进行统计,可以发现,物体框总是接近一些“常见”的尺寸。通过对训练数据集中的物体框尺寸进行聚类,可以得到若干个最常见的物体框尺寸,其他物体框可以看作这些常见物体框上进行“微调”的结果。这些聚类得出的常见物体框被称作“先验物体框”(prior)或“锚定物体框”(anchor)。
假设取A个先验物体框,那么神经网络的输出维度应该为
S
×
S
×
A
×
(
5
+
K
)
S \times S \times A \times (5+K)
S×S×A×(5+K),即每个网格输出A个物体框,分别基于先验物体框进行微调。
物体框的位置计算方式
设每个网格的长宽为单位1,每个网格输出的前两维
(
t
x
,
t
y
)
(t_x,t_y)
(tx,ty)经过Sigmoid函数之后,变成
(
0
,
1
)
(0,1)
(0,1)之间的数值,用来表示物体中心距离网格左上角的偏移量, 加上网格左上角的坐标
(
c
x
,
c
y
)
(c_x,c_y)
(cx,cy),就得到了物体框中心的坐标
(
b
x
,
b
y
)
=
(
c
x
+
σ
(
t
x
)
,
c
y
+
σ
(
t
y
)
)
(b_x,b_y)=(c_x+\sigma(t_x),c_y+\sigma(t_y))
(bx,by)=(cx+σ(tx),cy+σ(ty))。对于物体框的尺寸,网格输出的第3、4维
(
t
w
,
t
h
)
(t_w,t_h)
(tw,th)经过指数函数,得到正实数值
(
e
t
w
,
e
t
h
)
(e^{t_w},e^{t_h})
(etw,eth),再乘以先验物体框尺寸
(
p
w
,
p
h
)
(p_w,p_h)
(pw,ph),就得到了预测物体框的尺寸
(
b
w
,
b
h
)
=
(
p
w
e
t
w
,
p
h
e
t
h
)
(b_w,b_h)=(p_we^{t_w},p_he^{t_h})
(bw,bh)=(pwetw,pheth)。

YOLO模型的损失函数
YOLO的损失函数分为3个部分:物体框位置误差 识别物体的置信度误差 物体类别的误差.
物体框位置误差使用朴素的均方误差 , 只在有物体的框中计算位置误差. 我们用标记变量
1
i
o
b
j
\mathbb{1}_i^{obj}
1iobj表示编号为i的物体框中是否有物体,当有物体时该变量为1,反之为0. 物体框位置的预测值用
(
x
i
^
,
y
i
^
,
w
i
^
,
h
i
^
)
(\hat{x_i},\hat{y_i},\hat{w_i},\hat{h_i})
(xi^,yi^,wi^,hi^)表示, 真实物体框尺寸表示为
(
x
i
,
y
i
,
w
i
,
h
i
)
({x_i},{y_i},{w_i},{h_i})
(xi,yi,wi,hi).
于是:
L
coord
=
λ
coord
∑
i
1
i
obj
[
(
x
i
−
x
^
i
)
2
+
(
y
i
−
y
^
i
)
2
]
+
λ
coord
∑
i
1
i
obj
[
(
w
i
−
w
^
i
)
2
+
(
h
i
−
h
^
i
)
2
]
\begin{aligned} L_{\text {coord }}= & \lambda_{\text {coord }} \sum_{i} \mathbb{1}_{i}^{\text {obj }}\left[\left(x_{i}-\hat{x}_{i}\right)^{2}+\left(y_{i}-\hat{y}_{i}\right)^{2}\right] \\ & +\lambda_{\text {coord }} \sum_{i} \mathbb{1}_{i}^{\text {obj }}\left[\left(\sqrt{w_{i}}-\sqrt{\hat{w}_{i}}\right)^{2}+\left(\sqrt{h_{i}}-\sqrt{\hat{h}_{i}}\right)^{2}\right] \end{aligned}
Lcoord =λcoord i∑1iobj [(xi−x^i)2+(yi−y^i)2]+λcoord i∑1iobj [(wi−w^i)2+(hi−h^i)2]
其中,
λ
c
o
o
r
d
\lambda_{coord}
λcoord是用来调整位置误差所占比例的系数.
误差的第2部分是检测到物体的置信度误差. 在实际图片中, 有标记物体的网格但愿是户量要远小于没有物体的网格单元数量, 这实际上是一个不平衡的二分类问题. 为了改进平衡性, 防止误差函数引导网络输出的置信度向0靠近, 我们需要减弱没有物体的网格单元的误差惩罚. 这是通过引入系数
λ
n
o
o
b
j
\lambda _{noobj}
λnoobj实现的,这个系数小于1. 下面是置信度误差, 其中
c
i
^
\hat{c_i}
ci^ 表示物体框
i
i
i 有物体的预测值,
1
i
n
o
o
b
j
=
1
−
1
i
o
b
j
\mathbb{1}_i^{noobj}=1-\mathbb{1}_i^{obj}
1inoobj=1−1iobj表示物体框
i
i
i中没有物体的标记变量.
L
c
o
n
f
i
d
e
n
c
e
=
−
∑
i
1
i
o
b
j
ln
c
i
^
−
∑
i
1
i
n
o
o
b
j
ln
(
1
−
c
i
^
)
L_{confidence}=-\sum_i \mathbb{1}_i ^{obj} \ln{\hat{c_i}}-\sum_i \mathbb{1}_i^{noobj} \ln{(1-\hat{c_i})}
Lconfidence=−i∑1iobjlnci^−i∑1inoobjln(1−ci^)
第3部分是物体分类误差,其中,
p
i
,
k
p_{i,k}
pi,k是第
i
i
i个物体属于类别
k
k
k的概率, 为神经网络的Soft Max输出值,
k
i
k_i
ki 为物体框里面的物体的真实类标签. 物体分类误差只在有物体的框中计算.
L
c
l
a
s
s
=
∑
i
1
o
b
j
ln
p
i
,
k
i
L_{class}=\sum_i \mathbb{1}_obj \ln{p_{i,k_i}}
Lclass=i∑1objlnpi,ki
YOLO模型最终的损失函数为上面3部分的和 .
L
c
o
o
r
d
+
L
c
o
n
f
i
d
e
n
c
e
+
L
c
l
a
s
s
L_{coord}+L_{confidence}+L_{class}
Lcoord+Lconfidence+Lclass
缩微YOLO模型的网络结构
YOLO模型的神经网络结构是一个以卷积为主的多层前馈神经网络。这里我们介绍一个缩微版本模型,这个模型叫作YOLO v2tiny (模型配置文件下载地址),它是使用Pascal VOC数据集(数据集主页)训练得到的,可以识别20个类别的不同物体。
采用缩微版本,我们可以在CPU机器上快速实现物体识别,甚至可以使用CPU机器实现模型训练。Pascal VOC数据集包含 10000多幅图片,图片中包含了 20000多个20个不同类别的物体。在该数据集上完整训练一轮,CPU机器大约耗时十几个到几十个小时不等。而采用GPU 则能够极大地加速训练过程,以几十倍的比例压缩训练时间。
这个网络有9个卷积层,除了最后一个卷积层,每个卷积层后都增加了批归一化处理,用来加速训练过程,防止过拟合和梯度爆炸;激活函数采用了带泄露的修正线性单元(LeakyReLU),当卷积之后有池化层时,激活函数安排在池化层之后,对于没有池化层的卷积,激活函数直接作用于卷积层输出。
网络的前8个卷积层采用了大小为3×3的卷积核,较小的卷积核级联叠加,可以实现与较大的卷积核相似的效果,但是参数量较少,降低了模型的复杂度。比如,5×5的卷积核, 每个卷积核需要25个权值; 如果采用两个 3×3 的卷积核级联处理, 同样可以实现每个输出单元覆盖 5×5 范围内的输入, 但是, 卷积核的权值数量减少到 2×3×3=18 个. 压缩权值数量可以有效避免模型参数规模过度增长, 从而加速训练过程, 避免过拟合.
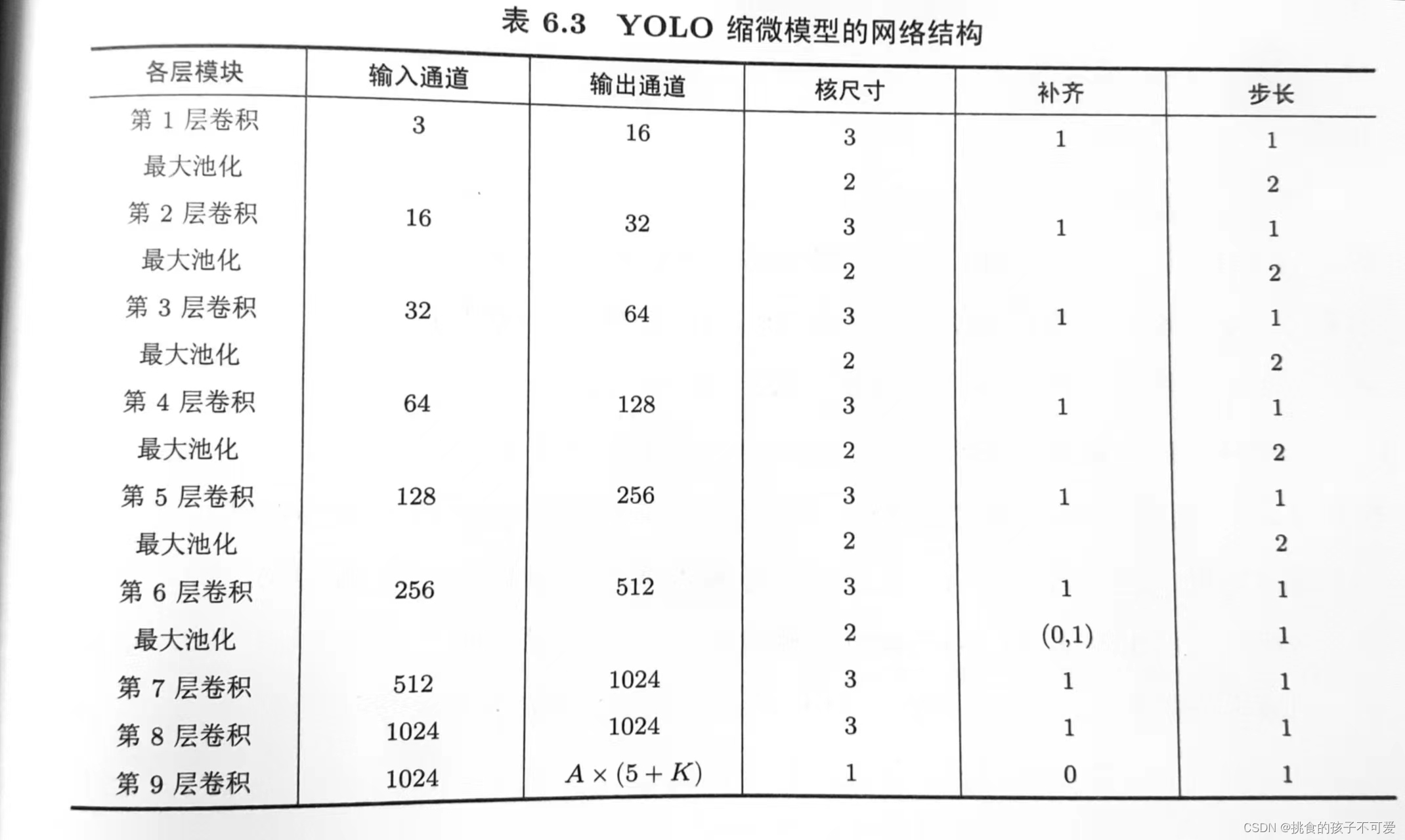
为了保证卷积输出结果尺寸的确定性, 卷积层都在输入的行列方向各补齐一行(或者一列)数据, 经过数据补齐, 3x3 的卷积输出尺寸就不会发生变化, 否则, 没经过一次3x3 卷积, 行列数都会各减少2, 控制网络输出尺寸会变得更加复杂. 因此, 数据补齐是一个简化网络设计的技巧.
卷积输出的尺寸不发生变化,只有通道数量不断增加。这是因为随着卷积和池化的不断级联叠加处理,每个神经元所感知的图像区域不断扩大,描述图像局部特征需要的容量(特征向量的长度)也相应增长。卷积结果从“通道”这个维度看,每个位置就是一个局部特征向量,向量长度就是通道的数量(即卷积核的数量)。因此,卷积层的输出通道数逐层加倍,从第1层到第7层,卷积层从16个输出通道增加到1024个输出通道。
数据的空间压缩过程由池化层完成。前5层卷积之后的最大池化层,采用2×9大小的核,以2为步长进行扫描,每经过一次这样的池化层,可以将数据长宽尺寸各缩小一半。这样5层过后,数据的尺寸缩小到原来的 1 / 32 1/32 1/32。后面的卷积层和池化层不再继续缩小数据尺寸,采取了步长为1,配合补齐数据,保持了输出数据的尺寸。其中,第6层卷积之后的池化层只在行列方向单侧补齐一行或者一列数据,这样,对于步长为1、尺寸为2×2的池化层,就可以保持输/入输出的尺寸相同。
网络最终输出的数据尺寸是原始输入的1/32。举例来说,如果输入图像大小为320×320像素,那么,输出网格的数量则为10×10。在实际训练过程中,训练图片被调整为 416×416像素作为输入,产生13×13个网格。模型有A=5个先验物体框,所以,每个网格单元产生5个物体框,最终将产生13×13×5个物体框。
值得注意的是最后一个卷积层,这一层卷积核大小为1×1。这是一种特殊的卷积核尺寸,它不进行空间上的数据整合,而是在每个局部的“点”(也就是网格单元)的输入通道维度上进行数据整合。它可以看作输入通道维度上的“全连接层”,用于产生每个网格单元的最终输出。当先验物体框数量为A,物体类别数量为K时,每个网格单元的输出值数量为Ax(5+K)。由于 Pascal VOC数据集中有20类物体,同时,模型聚类产生了5个先验物体框,因此,每个网格单元的输出长度为5×(5+20)=125。网络的最后一个卷积层的输出通道数就是125。
三、实现缩微YOLO模型
接下来使用pytorch实现缩微版本的YOLO模型.
定义模型类TinyYoloNetwork
首先,定义模型类TinyYolo-Network, 在构造函数中定义先验物体框 物体类别数量和网络的各层单元模块.
import torch
import torch.nn as nn
# 缩微YOLO网络模型
class TinyYoloNetwork(nn.Module):
def __init__(self):
super(TinyYoloNetwork, self).__init__()
# 从训练数据集中聚类得到的 先验物体框尺寸
# 这些是物体框 最有可能的各种尺寸
anchors = (
(1.08,1.19),(3.42,4.41),(6.63,11.38),(9.42,5.11),(16.62,10.52)
)
self.register_buffer("anchors",torch.tensor(anchors))
# 物体类别数
self.num_classes = 20
# LeakyReLU 作为激活函数, 输入小于0时, 斜率为0.1
self.relu = torch.nn.LeakyReLU(0.1, inplace=True)
# 最大值池化层
self.pool = torch.nn.MaxPool2d(2, stride=2)
self.lastpool = torch.nn.MaxPool2d(2, 1)
# 最后一个 池化层之前的数据补齐
self.pad = torch.nn.ReflectionPad2d((0,1,0,1))
# 批归一化层和卷积层
self.norm1 = torch.nn.BatchNorm2d(16)
self.conv1 = torch.nn.Conv2d(3, 16, 3, stride=1, padding=1, bias=False)
self.norm2 = torch.nn.BatchNorm2d(32)
self.conv2 = torch.nn.Conv2d(16, 32, 3, stride=1, padding=1, bias=False)
self.norm3 = torch.nn.BatchNorm2d(64)
self.conv3 = torch.nn.Conv2d(32, 64, 3, stride=1, padding=1, bias=False)
self.norm4 = torch.nn.BatchNorm2d(128)
self.conv4 = torch.nn.Conv2d(64, 128, 3, stride=1, padding=1, bias=False)
self.norm5 = torch.nn.BatchNorm2d(256)
self.conv5 = torch.nn.Conv2d(128, 256, 3, stride=1, padding=1, bias=False)
self.norm6 = torch.nn.BatchNorm2d(512)
self.conv6 = torch.nn.Conv2d(256, 512, 3, stride=1, padding=1, bias=False)
self.norm7 = torch.nn.BatchNorm2d(1024)
self.conv7 = torch.nn.Conv2d(512, 1024, 3, stride=1, padding=1, bias=False)
self.norm8 = torch.nn.BatchNorm2d(1024)
self.conv8 = torch.nn.Conv2d(1024, 1024, 3, stride=1, padding=1, bias=False)
# 最后一个卷积层
self.conv9 = torch.nn.Conv2d(1024, len(anchors)*(5+self.num_classes), 1, stride=1, padding=0)
关于上面代码的几点解释:


- 批归一化层BatchNorm2d是作用于卷积输出的,在每个通道上独立进行归一化,它的参数是通道数量。
- 最后一个池化层使用特殊的数据补齐ReflectionPad2d,在行列方向的单侧各补齐一行或者一列数据。
定义模型的前向计算过程
定义模型的前向计算过程,将各个模块连接在一起。
def forward(self, x, yolo=True):
# 将各个模块组织 为 神经网络
x = self.relu(self.pool(self.norm1(self.conv1(x))))
x = self.relu(self.pool(self.norm2(self.conv2(x))))
x = self.relu(self.pool(self.norm3(self.conv3(x))))
x = self.relu(self.pool(self.norm4(self.conv4(x))))
x = self.relu(self.pool(self.norm5(self.conv5(x))))
x = self.relu(self.lastpool(self.pad(self.conv6(x))))
x = self.relu(self.norm7(self.conv7(x)))
x = self.relu(self.norm8(self.conv8(x)))
x = self.conv9(x)
# 从神经网络的输出计算物体框位置和物体类别
return self.yolo(x)
定义YOLO 输出 (yolo) 方法
下面定义yolo方法,将网络输出重新组织,使其包含每个锚框的位置、宽高、置信度和类别概率(第一部分提到过的形式),使用 torch.cat 将这些信息合并为一个张量,并返回。
# 将卷积层的输出结果转换为物体框的位置、检测到物体的置信度和分类结果
def yolo(self, x):
# 神经网络输出的结果形状如下:
# 各维度依次是批次样本索引, 输出通道, 输出高度, 输出宽度
n_batch, n_channel, height, width = x.shape
# 将输出通道拆分为 若干先验物体框
x = x.view(n_batch, self.anchors.shape[0], -1, height, width)
# 重新调整 各个维度的顺序如下
# 样本索引, 先验物体框编号, 网格纵向和横向序号, 物体框维度
# 其中, 位置及分类输出的维度尺寸是 (5+类别数)
x = x.permute(0, 1, 3, 4, 2)
# 准备用于计算物体框位置的 辅助张量
# 首先是先验物体框的尺寸
anchors = self.anchors.to(dtype=x.dtype, device=x.device)
anchor_width, anchor_height = anchors[:, 0], anchors[:, 1]
# 然后是网格的偏移量
grid_y, grid_x = torch.meshgrid(
torch.arange(height, dtype=x.dtype, device=x.device),
torch.arange(width, dtype=x.dtype, device=x.device),
)
# 计算物体框位置 和 物体分类输出, 最后一维各列分别是:
# 中心位置坐标, 物体框宽高, 检测到物体的置信度, 物体类别概率
return torch.cat([
(x[:, :, :, :, 0:1].sigmoid()+grid_x[None, None, :, :, None])/width,
(x[:, :, :, :, 1:2].sigmoid()+grid_y[None, None, :, :, None])/height,
(x[:, :, :, :, 2:3].exp()*anchor_width[None, :, None, None, None])/width,
(x[:, :, :, :, 3:4].exp()*anchor_height[None, :, None, None, None])/height,
x[:, :, :, :, 4:5].sigmoid(),
x[:, :, :, :, 5:].softmax(-1),
], -1)
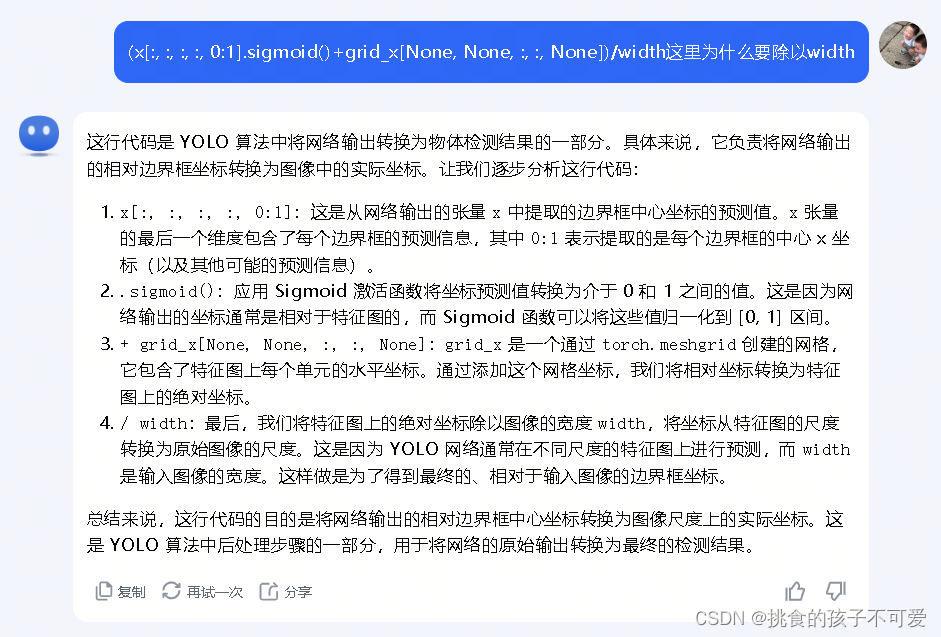
关于softmax(-1)的理解:查到一个不错的解答,点此跳转
简单说,softmax(-1) 表示 softmax 函数将在张量的最后一个维度上操作。在 PyTorch 中,-1 被用作维度的占位符,它告诉函数在输入张量的最后一个维度上应用 softmax 函数。
现在测试一下网络模型是否工作正常,
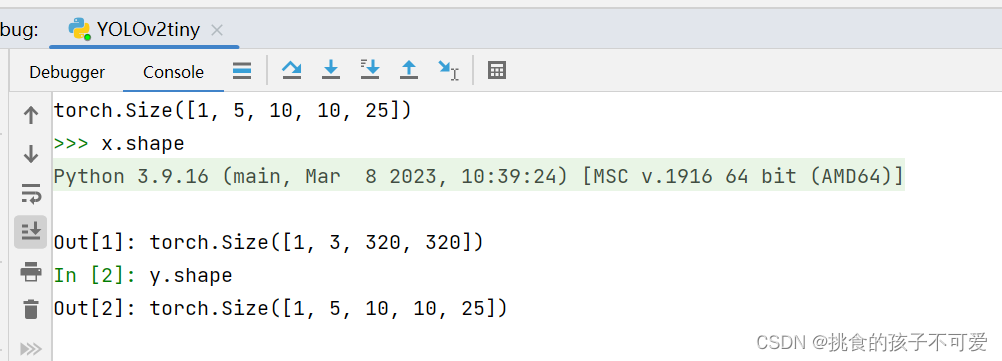
# 先测试一下网络模型工作是否正常, 填入一个320x320像素的随机图像作为输入, 输出的网格数量为10x10
# 每个网格单元的物体框数量为5, 每个物体框表示为长度为25的向量
x = torch.rand((1, 3, 320, 320))
net = TinyYoloNetwork()
y = net(x)
print(y.shape)
使用Debugger工具追踪,可以得到以下输出,在上面的测试代码中,我们随机生成了一个形状为(1,3,320,320)的张量, 其中第一个维度 1 表示批次大小(batch size),在这里是 1,意味着这个张量代表一个单独的图像样本。第二个维度 3 表示图像的通道数(channels),在这里是 3,对应于 RGB 彩色图像的三个颜色通道:红色(R)、绿色(G)和蓝色(B)。第三个维度 320 表示图像的高度(height),即图像有 320 像素高。第四个维度 320 表示图像的宽度(width),即图像有 320 像素宽。

加载模型权值数据
这里我们直接加载YOLO模型的作者提供的预训练好的模型权值文件,直接省去了训练模型的过程。但如果我们需要处理自己的数据集,还是需要在这个的基础上进行增量训练。与从头开始训练相比,这种方法可以节省训练时间。YOLO模型权值文件下载地址:https://pjreddie.com/media/files/yolov2-tiny-voc.weights
# 读取权值的辅助函数
# 从weights中offset位置读取权值到target
def load_weight_to(weights, offset, target):
n = target.numel()
target.data[:] = torch.from_numpy(weights[ offset : offset+n]).view_as(target.data)
return offset+n
import numpy
# 从文件加载训练好的网络权值
def load_weights(network, filename="G:\\BrowserDownload\\2024-03\\yolov2-tiny-voc.weights"):
with open(filename, "rb") as file:
# 读取版本号 和 训练状态记录
header = numpy.fromfile(file, count=4, dtype=numpy.int32)
# 其余所有值都是网络权值
weights = numpy.fromfile(file, dtype=numpy.float32)
idx = 0
for layer in network.children():
# 读取卷积层权值
if isinstance(layer, torch.nn.Conv2d):
if layer.bias is not None:
idx = load_weight_to(weights, idx, layer.bias)
idx = load_weight_to(weights, idx, layer.weight)
# 读取批归一化层权值
if isinstance(layer, torch.nn.BatchNorm2d):
idx = load_weight_to(weights, idx, layer.bias)
idx = load_weight_to(weights, idx, layer.weight)
idx = load_weight_to(weights, idx, layer.running_mean)
idx = load_weight_to(weights, idx, layer.running_var)
# 调用函数加载权值
load_weights(net)
这段代码提供了两个函数,用于将训练好的 YOLOv2-tiny 模型权重从 Darknet 格式加载到 PyTorch 模型中。
load_weight_to 函数
这是一个辅助函数,用于从权重数组中加载权重到 PyTorch 模型的特定参数中。它接受三个参数:
weights:一个 NumPy 数组,包含了从权重文件中读取的所有权重。offset:一个整数,表示在weights数组中当前要读取的起始位置。target:一个 PyTorch 参数(例如,nn.Conv2d的权重或偏置),它是要更新的目标参数。
函数执行以下步骤:
- 使用
target.numel()获取目标参数中的元素数量n。 - 使用
torch.from_numpy将权重数组的一部分转换为 PyTorch 张量,并使用view_as方法调整张量的形状以匹配目标参数的形状。 - 将转换后的张量赋值给目标参数的数据。
- 返回更新后的偏移量
offset+n,用于后续加载其他层的权重。
load_weights 函数
这个函数用于遍历 PyTorch 模型的所有层,并加载预训练的权重。它接受两个参数:
network:要加载权重的 PyTorch 网络模型。filename:包含预训练权重的文件路径。
函数执行以下步骤:
- 打开权重文件进行二进制读取。
- 读取文件头部信息,通常包括版本号和训练状态记录,但在此代码中未使用。
- 读取剩余的文件内容作为权重值。
- 遍历网络的每一层,对于每种类型的层(卷积层和批归一化层),使用
load_weight_to函数加载权重和偏置。 - 对于批归一化层,除了权重和偏置外,还需要加载
running_mean和running_var。
这个权重加载过程假设 Darknet 格式的权重文件与 PyTorch 模型的结构是匹配的。如果结构不匹配,需要对加载过程进行相应的调整。这个过程是将预训练模型的权重迁移到 PyTorch 框架中,以便可以在 PyTorch 环境中使用这些模型进行推理或继续训练。
处理真实图像
真实图像的尺寸各不相同,网络模型通常需要特定输入的尺寸。YOLO模型需要图像的长度和宽度都是32的整倍数,每32x32个像素对应一个网格。
在YOLO模型训练阶段,输入图像都为426x416, 所以在使用模型时, 也要尽量输入与训练图片尺寸接近或一致的图片.
下面的代码用来加载真实图像, 并且对图像进行缩放和补齐, 使得图像与我们期望的输入尺寸一致, 是以哦那个Pillow包进行图像的读取; 再使用PyTorch软件包中的torchvision视觉模块进行图像缩放,补齐操作, 将图像转化为网络模型可以接受的张量.
import torchvision
from PIL import Image
def load_image(filename, width, height):
img = Image.open(filename)
scale = min(width / img.width, height / img.height)
new_width, new_height = int(img.width * scale), int(img.height * scale)
diff_width, diff_height = width-new_width, height-new_height
padding = (diff_width // 2, diff_height // 2,
diff_width // 2 + diff_width % 2,
diff_height // 2 + diff_height % 2)
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(size=(new_height, new_width)),
torchvision.transforms.Pad(padding=padding),
torchvision.transforms.ToTensor()
])
# 用unsqueeze 方法增加一维样本编号
# 网络模型是成批接受输入的
# 即 一批只有一个样本
return transform(img).unsqueeze(0)
下面准备绘制物体框,要在输出绘制的物体框中对物体类别进行标注, 我们需要提前准备VOC数据集中的20个物体类别的名字.
# 准备工作: 将网络模型的输出可视化
class_labels = (
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor",
)
网络模型会产生大量物体框, 以320x320像素的输入图像为例, 网络会产生100个网格, 每个网格产生5个物体框. 显然, 我们不能把所有500个物体框都绘制出来, 只需要通过一个threshold过滤掉置信度不高的物体框, 同时, 我们希望物体类别的softmax输出也比较大, 因此, 过滤时比较的是置信度与softmax输出的乘积,将这个乘积显示出来,用来观察网络模型认为某处存在某种物体的概率大小.
# 下面是绘制物体框的函数
def show_images_with_boxes(input_tensor, output_tensor, class_labels, threshold):
# 区分不同物体框的颜色表
colors = ['r', 'g', 'b', 'y', 'c', 'm', 'k']
to_img = torchvision.transforms.ToPILImage()
img = to_img(input_tensor[0])
# 显示图片
plt.imshow(img)
axis = plt.gca()
# 将网络输出提取为numpy数组
output = output_tensor[0].cpu().detach().numpy().reshape((-1, 5+len(class_labels)))
classes = numpy.argmax(output[:, 5:], axis=-1)
confidences = output[:, 4] * numpy.max(output[:, 5:], axis=-1)
# 将物体框调整到输入图片的尺寸
boxes = output[:, 0:4]
boxes[:, 0::2] *= img.width
boxes[:, 1::2] *= img.height
boxes[:, 0:2] -= boxes[:, 2:4] / 2
# 逐个显示物体框
for box, confidence, class_id in zip(boxes, confidences, classes):
# 忽略置信度较低的物体框
if confidence < threshold: continue
# 绘制物体框
color = colors[class_id % len(colors)]
rect = patches.Rectangle(box[0:2], box[2], box[3],
linewidth=1, edgecolor=color, facecolor='none')
axis.add_patch(rect)
label = class_labels[class_id]
label = '{0}{1:.2f}'.format(label, confidence)
plt.text(box[0], box[1], label, color='w', backgroundcolor=color)
plt.show()

接下来,输入真实的图像,测试一下啊
net = TinyYoloNetwork()
load_weights(net)
imgs = load_image('D:\\For_Study\\SelfLearn\\ForPythonArcgis\\demo1\\data\\dogs.jpg', 320, 320)
output_tensor = net(imgs)
show_images_with_boxes(imgs, output_tensor, class_labels, 0.3)

从输出结果中,我们可以看到有若干个位置相似的物体框套在同一个物体上,它们可能来自相邻的网格单元, 或者来自同一网格单元内不同的先验物体框。更加完善的处理是,计算这些重叠物体框的重叠比例,当重叠比例超过一定阈值时,认为它们描述的时同一个物体,选择其中置信度最高的物体框,忽略其他物体框。这个过程叫作最大值抑制,可以有效地过滤重复的物体框。
总结
今天学习的是使用预训练好的YOLO模型对真实图片进行物体检测的代码.















 1621
1621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









