







系列文章目录
第1章 专家系统
第2章 决策树
第3章 神经元和感知机
识别手写数字——感知机
第4章 线性回归
第5章 逻辑斯蒂回归和分类
第5章 支持向量机
第6章 人工神经网络(一)
第6章 人工神经网络(二) 卷积和池化
第6章 使用pytorch进行手写数字识别
实操练习 使用Yolo模型进行物体检测
前言
群体的智慧常常优于单个个体的决策。正所谓,“三个臭皮匠顶个诸葛亮”,集成学习的思路正是如此。单个模型的预测误差可能比较大,但将若干个比较弱的模型组织再一起,则可以减少误差,产生较强的预测模型。
一、集成学习
集成学习就是将若干个弱模型结合成为一个强模型。我们选取某一种分类器作为”基分类器“,然后利用这种方法产生若干”基分类器“的实例,用它们投票的结果作为一个更强的分类器。
集成学习的一般结构
先产生一组”个体学习器”(individual learner),再利用某种策略将它们结合起来。如果集成中只包含同种类型的个体学习器,例如“决策树集成”中全是决策树,“神经网络集成”中全是神经网络,这样的集成就叫做 “同质" 的;反之,一个集成中包含不同类型的个体学习器,例如同时包含决策树和神经网络,这样的集成就是 “异质” 的。
在同质集成中的个体学习器也称作“基学习器" base learner,相应的学习算法被称作”基学习算法”base learning algorithm。而在异质集成中的个体学习器由不同的学习算法生成,其中的个体学习器就成为“组件学习器” component learner。
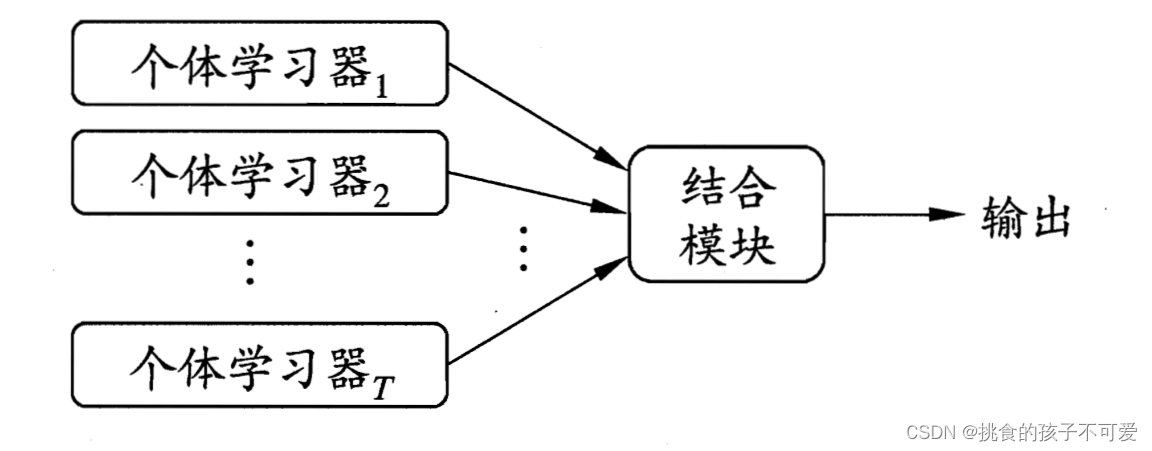
上图来自周志华《机器学习》第8章。
将多个学习器进行结合,最终得到比单一学习器显著优越的泛化性能,这在弱学习器中尤为明显。弱学习器一般是指,泛化性能略高于随即猜测的学习器,例如在二分类问题上,精度略高于50%的分类器。
集成学习需要关注的问题:如何得到弱学习器?如何将弱学习器组合起来?
二、随机森林
以决策树为例,单个决策树虽然思路直观、训练方法比较直接、执行速度快,然而却非常容易出现过拟合的问题,它在没有见过的真实样本上表现不佳,泛化能力不够好。我们可以通过构造一棵庞大的决策树,通过增加树的深度来解决,但是我们发现,越接近末梢的节点,落入这些节点的样本量就越小。根据概率统计的规律,当样本量小的时候,真实的规律往往呈现得不够明显,导致决策树算法可能选取错误的分支判定条件。特别是对于包含噪声的训练样本集,倘若某些样本标记错误,这些末端分支就会完美地拟合错误的标记,从而产生错误的分类结果。
对于单个决策树,可以限制树的尺寸,避免把树分支得太深、太大。于是提出了各种剪枝策略,这些策略往往行之有效,能够保持节点和分支有足够的样本数据作为支持,使真实的统计规律浮现出来,同时忽略占比重不大的噪声。然而,剪枝策略需要依靠经验,树过小时,虽然避免过拟合的风险,但有可能无法捕捉到全部分类依据;树过大时,容易出现过拟合的风险。
于是提出了随机森林。即构造多个不同的决策树,构成一个森林,用它们的结果进行多数投票,作为最终的决策结果。
如何利用相同的训练数据创建多个不同的决策树呢?
有很多种方法,我们希望得到的这些树再训练集上有100%的准确率,但是泛化错误要尽可能不相同。随机化是引入分类器差异性的有力工具,因此算法的名称就叫作随机决策森林。
对于维度比较高的训练数据,可以采用随机选择特征空间的子空间的方法,比如,训练样本具有
m
m
m个不同的特征,我们可以选取一个特征子集作为构建决策树的依据,这样总共有
2
m
2^m
2m种不同的选择方案,可以构造出
2
m
2^m
2m个决策树。
训练样本的特征维度不够大的时候,也可以采用对样本集合重新采样的方式构造若干新的样本集合,这种方法也叫Bagging。采样的方式是有放回的采样,所以可能会产生重复的样本。
三、自适应增强算法AdaBoost
一般经验中,把一些好坏不等的东西惨到一起,那么结果通常比最坏的要好一些,而比最好的要坏一些。那么如何才能使多个学习器结合起来的性能变得更好呢?
随机森林所采用的投票法中,每个决策树对最终分类结果的投票所占的比重都是均等的。但事实上,不同的弱学习器的性能也存在差异,如果赋予不同的权值,是否有可能提高最终的准确性呢?
根据这样的思路提出了自适应增强算法(AdaBoost, Adaptive Boosting)就根据这样的思路给若干弱分类器加上权重,进而整合成为一个强分类器。
弱分类器的迭代组合
从最基本的二分类问题来看AdaBoost算法。
假设共有
N
N
N个训练样本,
(
x
1
,
y
1
)
,
⋯
,
(
x
N
,
y
N
)
(x_1,y_1),\cdots,(x_N,y_N)
(x1,y1),⋯,(xN,yN),其中
x
x
x为输入特征,
y
y
y为类标签,
y
∈
{
0
,
1
}
y \in \left \{0,1\right \}
y∈{0,1}。将弱分类器记作
h
(
x
)
h(x)
h(x),它的输出范围是
[
0
,
1
]
[0,1]
[0,1]之间的值,表示样本类别为1的概率。
AdaBoost是一个迭代的算法,每次迭代产生一个弱分类器,每个弱分类器有不同的权重,最终的强分类器就是这些弱分类器的加权线性组合。
算法1:自适应增强算法 AdaBoost
初始化样本权值 ω i 1 = D ( i ) \omega_i^1=D(i) ωi1=D(i)其中 i = 1 , ⋯ , N i=1,\cdots,N i=1,⋯,N
for t = 1 , 2 , ⋯ , T t=1,2,\cdots,T t=1,2,⋯,T do
计算分布 p t = ω t ∑ i = 1 N ω i t p^t=\frac{\mathbb {\omega}^t}{\sum_{i=1}^{N} {\omega_i^t}} pt=∑i=1Nωitωt
调用弱学习算法,以 p t p^t pt作为训练样本分布,学习弱分类器 h t h_t ht
计算弱分类器 h t h_t ht的误差 ϵ t = ∑ i = 1 N p i t ∣ h t ( x i ) − y i ∣ \epsilon_t=\sum_{i=1}^{N}{p_i^t |h_t(x_i)-y_i|} ϵt=∑i=1Npit∣ht(xi)−yi∣
计算权值调整因子 β t = ϵ t / ( 1 − ϵ t ) \beta_t = \epsilon_t/(1-\epsilon_t) βt=ϵt/(1−ϵt)
更新样本权值 ω i t + 1 = ω i t β t 1 − ∣ h t ( x i ) − y i ∣ \omega_i^{t+1}=\omega_i^t\beta_t^{1-|h_t(x_i)-y_i|} ωit+1=ωitβt1−∣ht(xi)−yi∣
end
输出强分类器
h f ( x ) = { 1 如果 ∑ i = 1 N l o g ( 1 / β t ) h t ( x ) ≥ 1 2 ∑ t = 1 T l o g 1 / β t 0 其他 h_f(x)=\begin{cases} & 1 \text{ 如果 } \sum_{i=1}^{N} {log(1/\beta_t)h_t(x)\ge \frac{1}{2}\sum_{t=1}^{T} log 1/\beta_t } \\ & 0 \text{ 其他 } \end{cases} hf(x)={1 如果 ∑i=1Nlog(1/βt)ht(x)≥21∑t=1Tlog1/βt0 其他
AdaBoost常用决策树作为基分类器。与随机森林中的每个决策树在训练集上几乎都是误差接近于0而泛化能力较差不同,AdaBoost通常采用较小的决策树作为基分类器,通常我们将树的深度限制为1,也就是只有一个根分支,这样的决策树也叫做决策树桩。这样产生的基分类器几乎完全没有过拟合的问题,但是通常在训练集上的误差比较大。但AdaBoost对于基分类器的误差几乎没有要求,只要稍好于随即猜测,就能保证得到较强的分类器。
AdaBoost如何使每次迭代产生的弱分类器不同呢?AdaBoost采用了调整训练样本的分布的方法。接下来分析以上的算法。
设第
i
i
i个训练样本在第
t
t
t次迭代时的权重是
ω
i
t
\omega_i^t
ωit,对权重进行归一化,就得到了样本分布
p
t
p_t
pt。每次学习弱分类器的时候,都采用不同的分布,以得到不同的分类器。训练样本i的初始权值是
D
(
i
)
D(i)
D(i),这可以是训练集本身包含的权值信息,也可以是一个常数(即所有样本具有同样的权重)。
每次迭代时,根据当前弱分类器的分类结果调整样本权重,调整因子是
β
\beta
β,它取(0,1)之间的值。算法将分类正确的样本权重乘以
β
\beta
β,以缩小后续训练中这些样本的比重,使得训练过程更加关注之前没有分类正确的样本。
β
\beta
β 的取值根据当前弱分类器的训练误差
ϵ
\epsilon
ϵ 得到,
β
=
ϵ
/
(
1
−
ϵ
)
\beta=\epsilon/(1-\epsilon)
β=ϵ/(1−ϵ)。误差
ϵ
\epsilon
ϵ 越小,则
β
\beta
β 越小,于是分配给错误分类样本的权值比例越大。由于
β
\beta
β相当于错误分类样本和正确分类样本的权值和的比值,权值调整的过程实际上是重新分配了权值的比例,使得错误分类样本和正确分类样本的权值和相等,这就抹去了之前分类器的优势,尽可能地使新的分类器与之前的分类器相互独立。
同时,
β
\beta
β 也决定了每个弱分类器在最终输出的强分类器中所占比重。弱分类器的最终投票权值是
l
o
g
1
/
β
log1/\beta
log1/β,分类器误差越小,它在最终强分类器的输出中所占比重越大。
与随机决策森林相比,AdaBoost的基分类器较为简单,这样的基分类器误差一般比较大,但是不存在泛化能力的缺陷。AdaBoost最终产生的强分类器通常能够有效避免过拟合,具有较好的泛化能力。
AdaBoost算法的正确性
Yoav Freund等人在提出AdaBoost算法时证明,每次迭代产生的弱分类器只要稍好于随即猜测,就能够不断改进最终输出的强分类器的结果。证明过程十分巧妙。
打公式太痛苦啦,于是手写了一下。





总结
以上就是今天的学习内容,本文仅仅简单介绍了集成学习的思想,详细了解了AdaBoost算法的设计过程。















 3915
3915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









