






transformer 来源于谷歌论文《Attention Is All You Need》
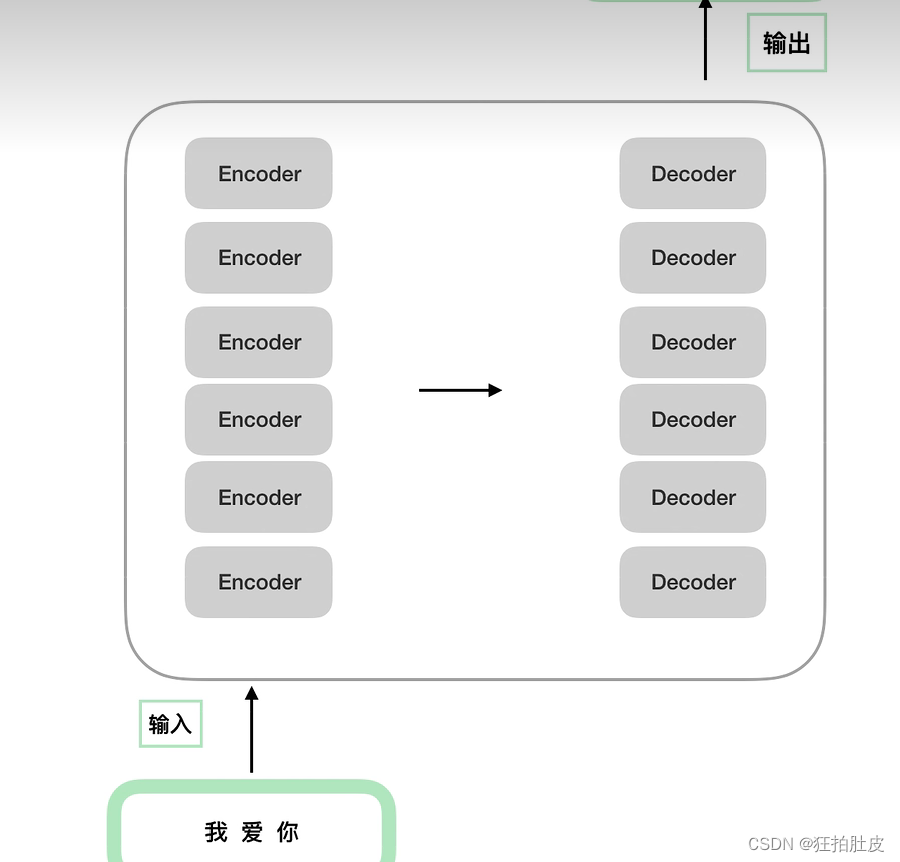
transformer主要就是在输入输出之间做机器翻译

可以再将transformer细化成encoders—decoders(编码--解码)

encoders—decoders(编码--解码)可以由多个小encoder—decoder组成,数量可以自己定,是一个×N的结构,所有的小encorder结构式完全相同的,小decorder结构式也完全相同的。结构上是完全相同的,但区别是输入的参数不同。
将Encoders部分分解
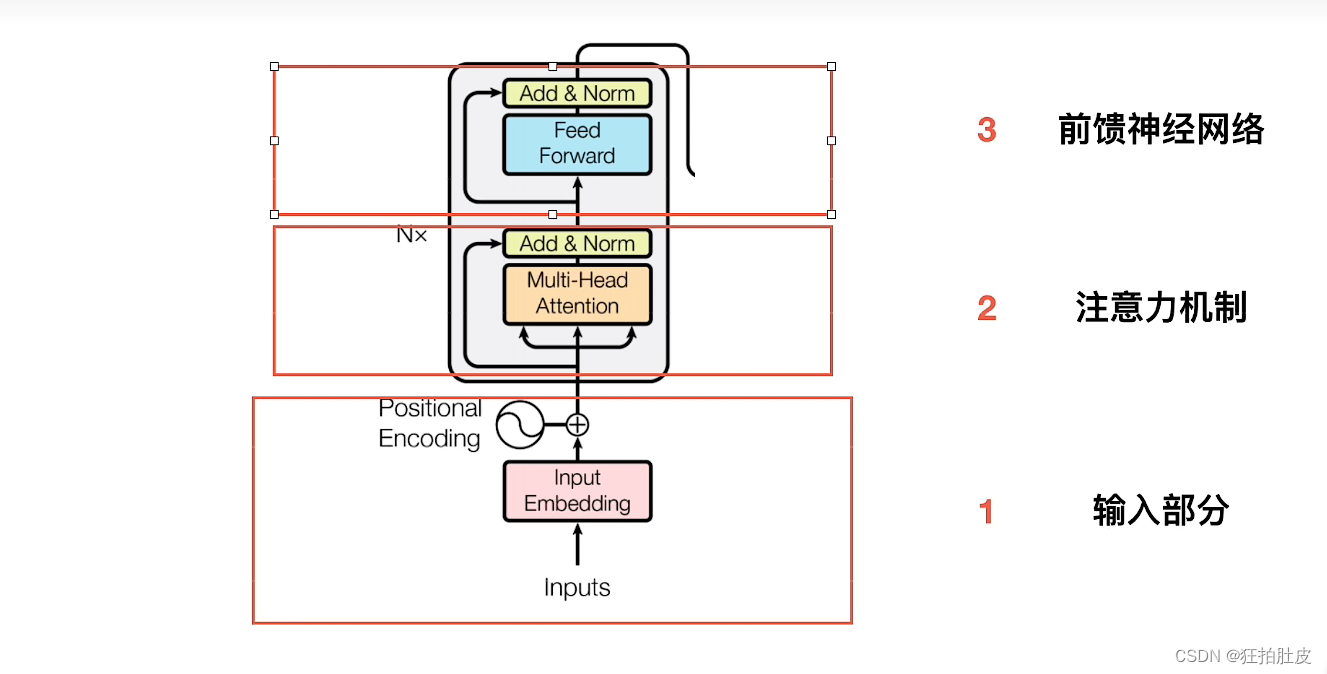
1.输入部分
可以分为embedding和位置嵌入两个小部分
(1)embedding是NLP的知识
对于输入按字切分,每一个字对应一个512维度的字向量,对于字向量可以使用word2vec

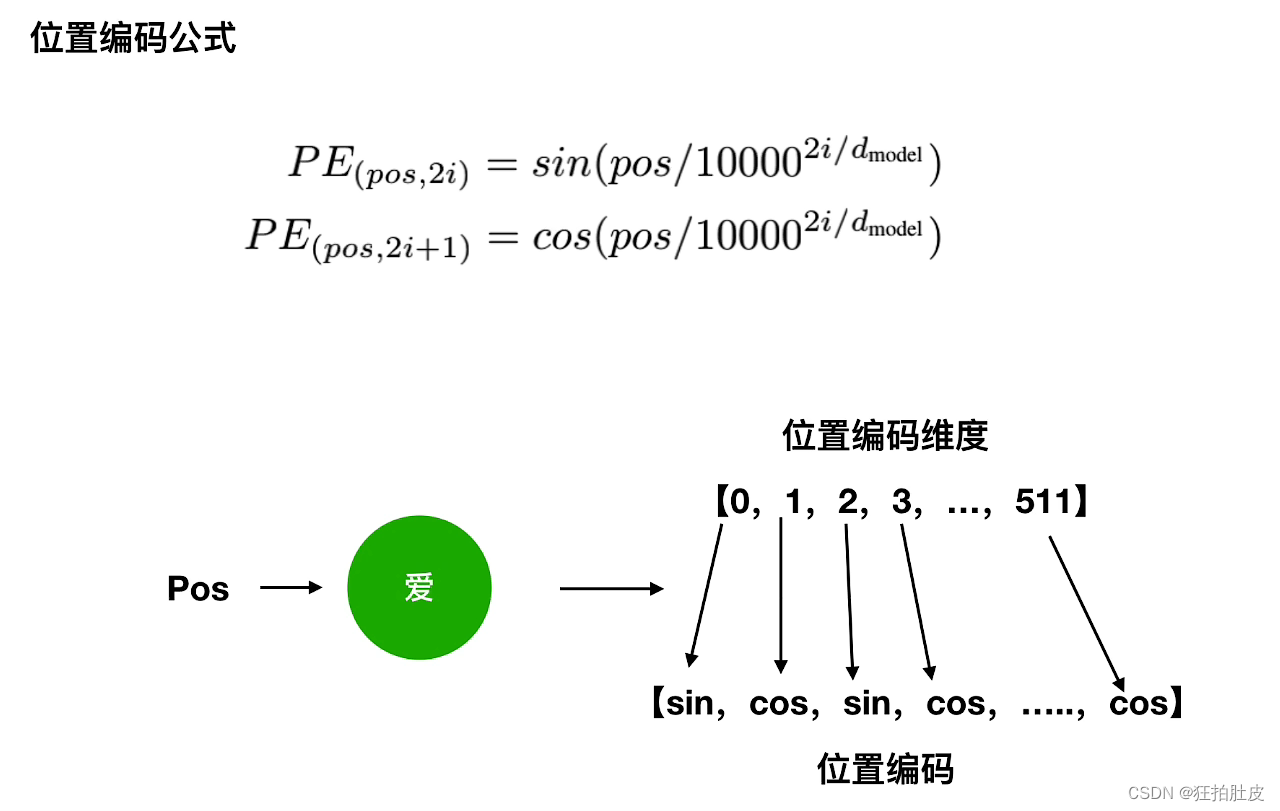
(2)位置编码
对于RNN ,U输入参数,W隐藏参数,V输出参数,对于RNN所有的timestamp公用一套参数,RNN是先后依次处理的,是串行的,速度慢
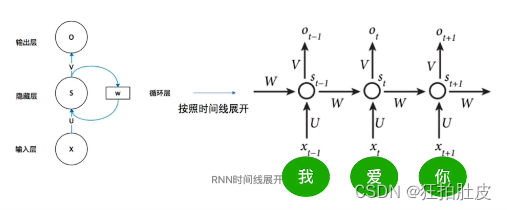
Transformer模型没有循环神经网络的迭代操作,而是使用全局信息,不能利用字的顺序,所以Transformer中使用位置编码来保存其相对或者绝对位置,从而识别字在序列中的顺序关系。 相较于RNN,Transformer是并行化一起处理的,增加了速度,但是忽略掉了序列关系。如何来保持序列关系呢?对每一个字的512字向量维度位置进行区分,以2i表示偶数位置,2i+1表示奇数位置

2.注意力机制
注意力机制公式
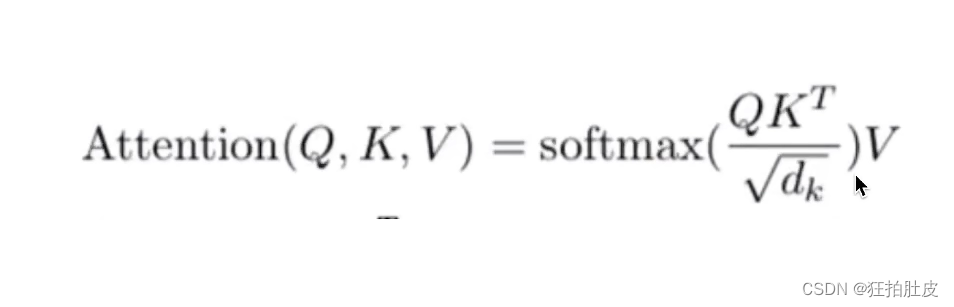
对公式进行图解,Q与K进行点乘,对结果进行softmax()归一化求相似度,再将得到的结果a与V相乘,结果相加求和即得到Attention Value
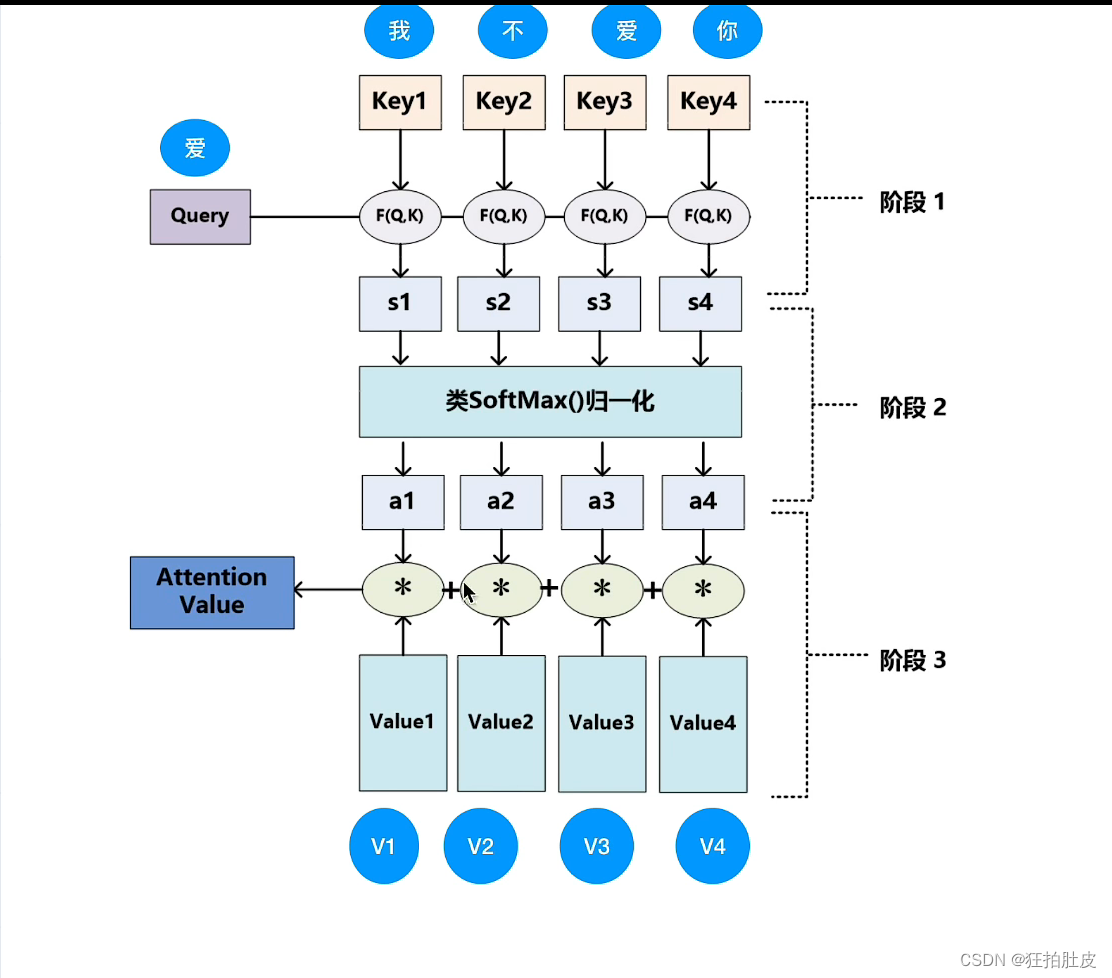
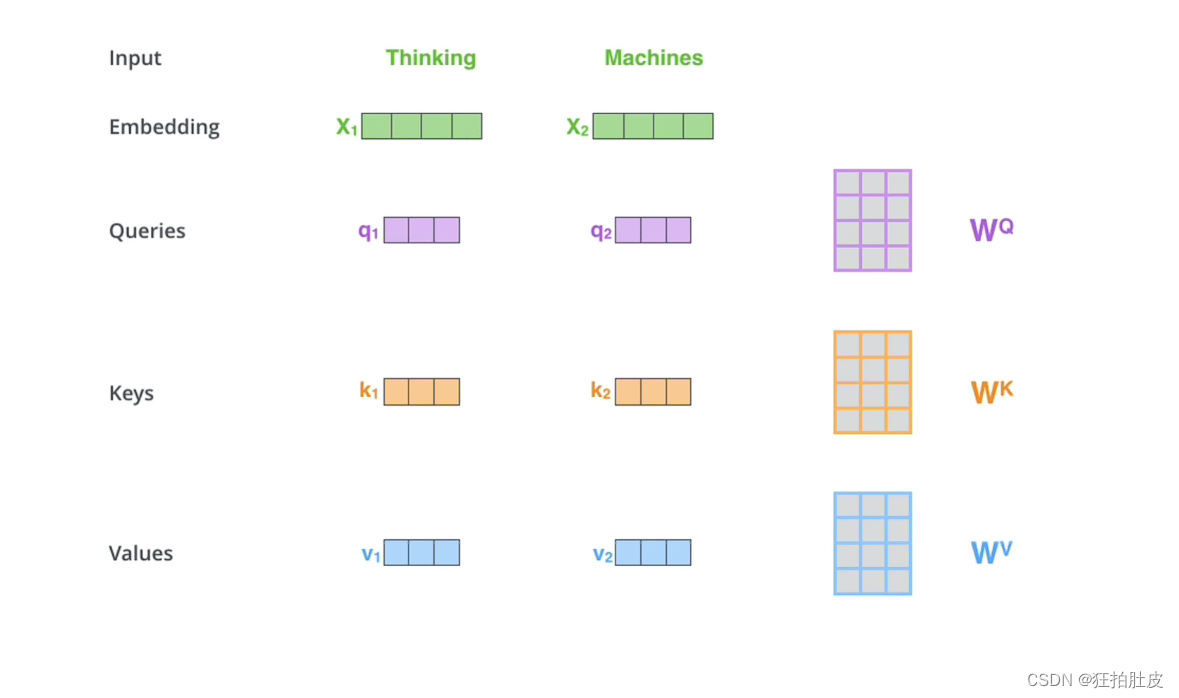
Q、K、V的获取,Q即用X矩阵乘W矩阵得到,K、V同理
对于公式中的d k是因为QK的值很大,softmax()反向传播的时候,梯度很小,可能会梯度消失,除以根号d k可以让方差为1

多头注意力就是多参数并行,提高过程运行效率
3.前馈神经网络
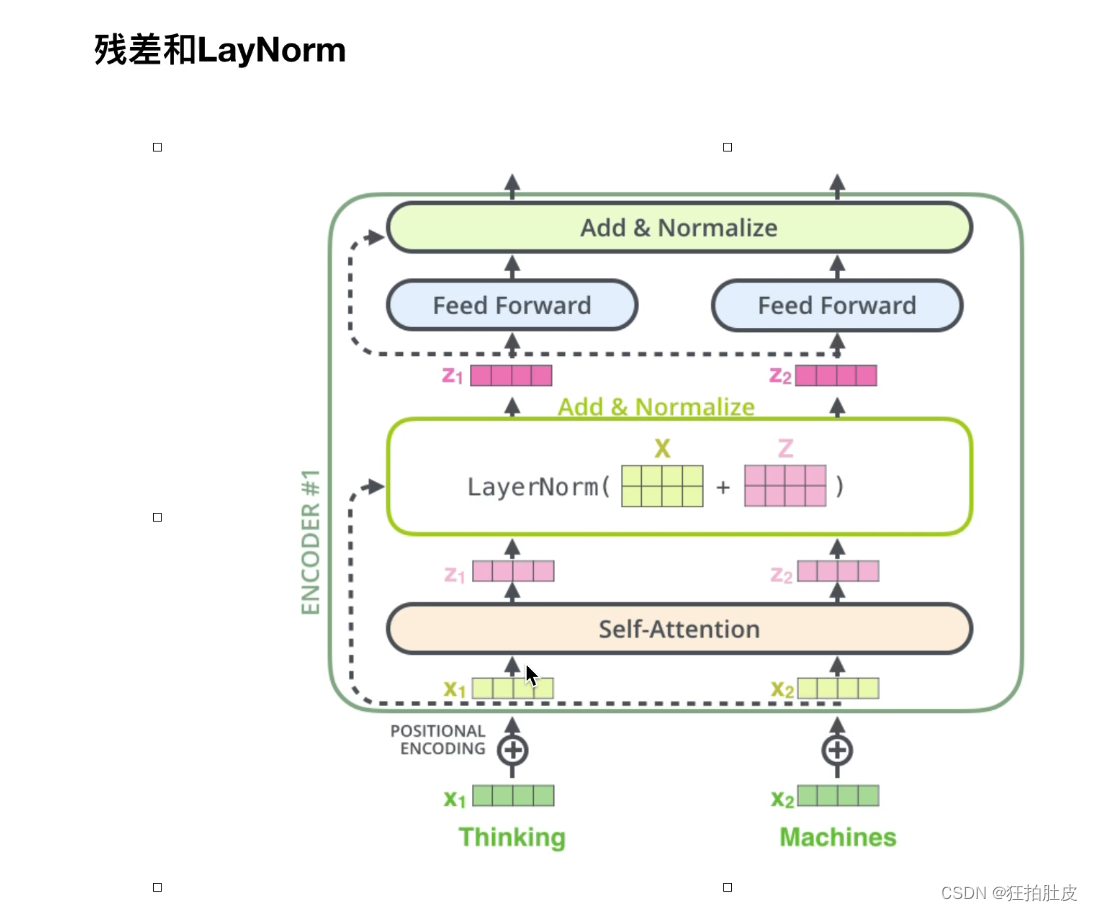
字向量经过embedding对位相加得到新的X,经过自注意力得到Z,Z和A对位相加,残差结果输出,经过两层的全连接,经过残差做最终输出结果。
二、Decoder
1、mask
Decoder有时序需要一个一个输入,需要通过mask来错开位置,否则输出会受到多输入影响
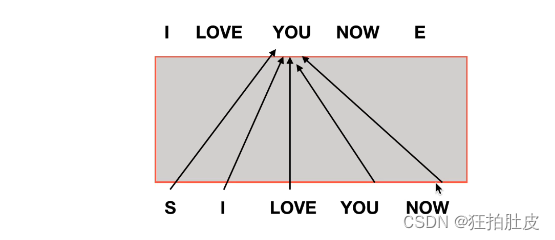
2、交互式
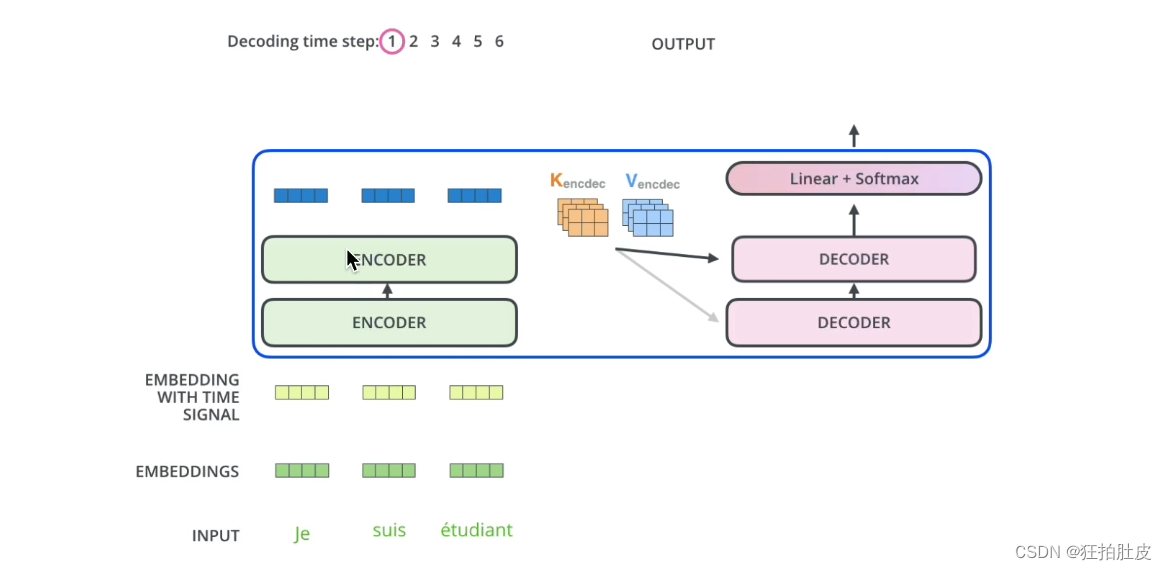
由encoder生成K、V矩阵,交由decoder生成Q矩阵,encoder的输出要和每一个decoder做交互















 26万+
26万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









