






1、FCN(全连接卷积神经网络)
FCN是深度学习来做语义分割的奠基性工作
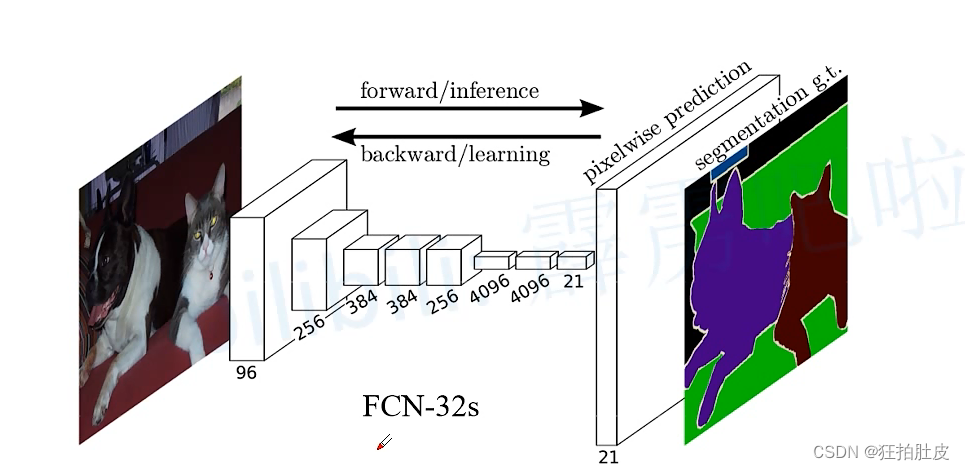
96,256,384,384,256前五层是卷积层,后三层为全连接层,用转置卷积层来替换CNN最后的全连接层,从而实现像素预测
为解决卷积和池化导致图像尺寸的变小,使用上采样方式对图像尺寸进行恢复
2、PSPNET
该模型提出是为了解决场景分析问题。针对FCN网络在场景分析数据集上存在的问题,Pspnet提出一系列改进方案,以提升场景分析中对于相似颜色、形状的物体的检测精度。
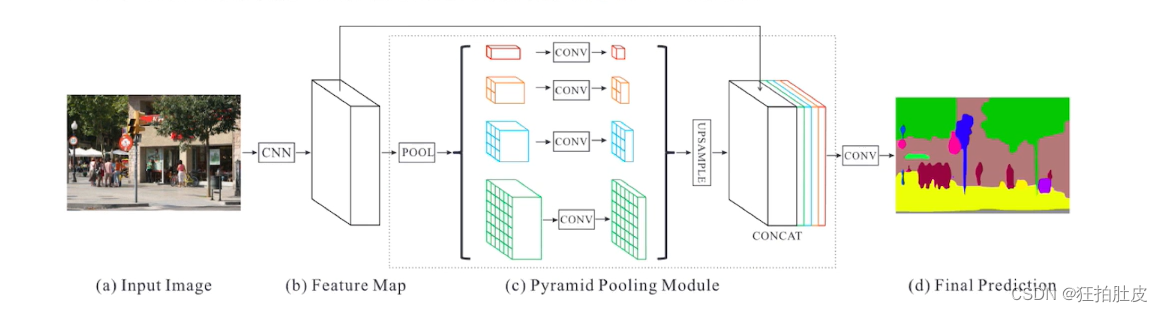
PSPNet用带有空洞卷积的预训练的ResNet作为backbone,最后一层提取的feature map大小为输入图像的1/8。PSPNet为四级模块,其二进制大小分别为1×1、2×2、3×3和6×6。因此,通过融合四个不同金字塔尺寸的特征,将输入的feature map分为不同的子区域并生成不同位置的池化表示,从而产生不同尺寸的输出,为了强化全局特征的权重,在金字塔层数为N的情况下,利用一个1x1的卷积将上下文表示的维度降到1/N。然后将得到的特征通过双线性插值上采样至相同尺寸,进行拼接后作为最终的全局金字塔池化特征。
3、Deeplab-V3
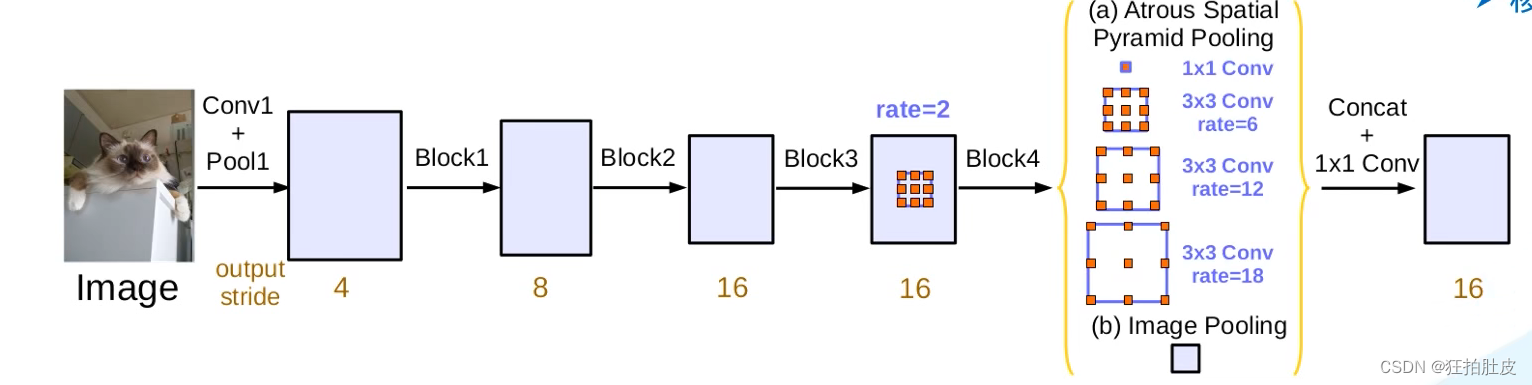
空洞卷积编码器(Dilated Convolutional Encoder):使用了空洞卷积来扩大感受野,从而更好地捕捉上下文信息。
空洞卷积(Dilated Convolution):DeepLab-v3中的关键是采用多尺度空洞卷积来捕捉不同尺度下的上下文信息。通过在卷积核中引入不同的空洞率,网络可以学习到不同尺度下的特征。这样可以提高模型对细节和边界的感知能力。
解码器模块(Decoder Module):引入了解码器模块,包括上采样和融合操作,以将特征图的分辨率还原到原始输入图像的大小。这有助于提高分割的准确性。















 5648
5648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









