








论文地址:[2104.02273v1] Multi-View Multi-Person 3D Pose Estimation with Plane Sweep Stereo (arxiv.org)
1.文章介绍
这篇文章提出了基于平面扫描立体的多视图三维姿态估计方法,以联合解决单次拍摄中的跨视图融合和三维姿态重建问题 ,采用了从粗到细的方案,首先回归个人层面的深度,然后进行每人联合层面的相对深度估计。
2.文章结构
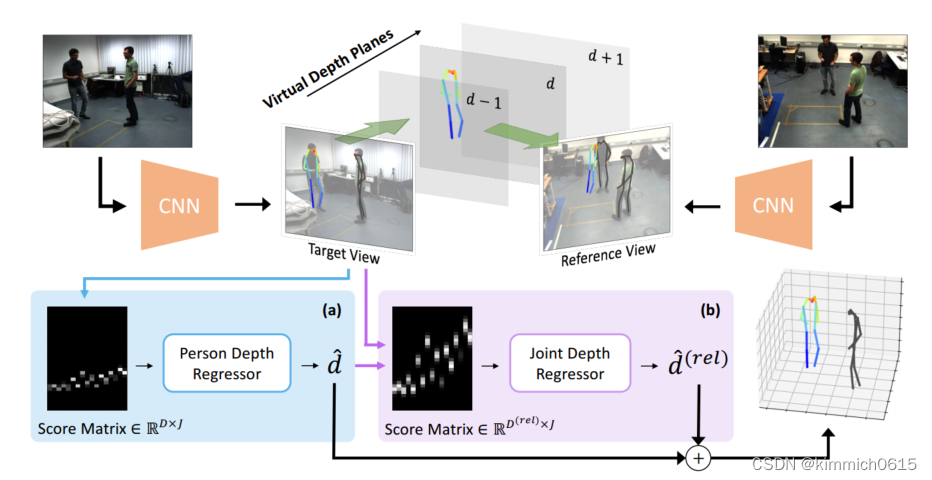
a.首先使用自上而下的方法多人姿态估计方法,HRnet,获取每个相机的2D姿态估计
b.第二步是利用平面扫描立体的基本思想是将目标视图图像反向投影到一组连续的虚拟深度平面,然后将这些投影扭曲到参考视图图像,从而可以测量光度一致性,以确定每个目标视图像素的深度。
其先设置一个D[dmin,dmax]深度的虚拟平面,使得深度足够大,能覆盖到所选的相机区域空间。一个候选的2D姿态p(target view)被投影到虚拟深度平面d,然后投影至Reference view的2D姿态记作q(d),然后在Reference view上搜索最近的2D姿态p',利用argmin函数
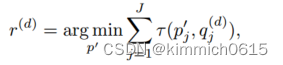
然后生成得分矩阵,通过高斯分布
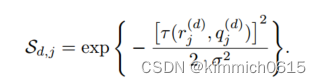
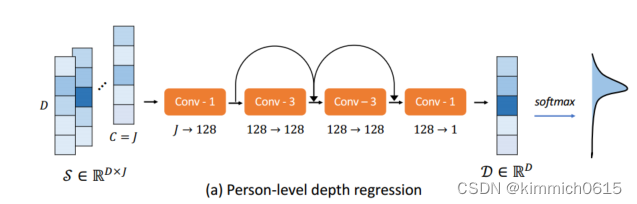
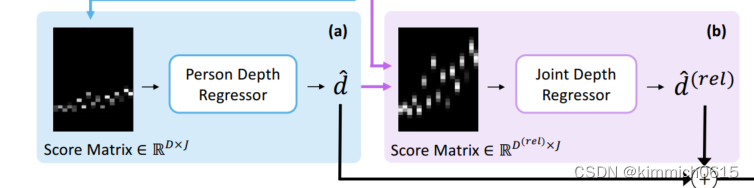 c. 然后进行粗回归,将目标姿态p的得分矩阵S视为具有J个特征通道的长度为D的1D信号,并利用1D卷积神经网络(1D-CNN)将其映射到深度向量,使用了一个具有残差链接的简单架构,该架构足以粗略估计人级深度。
c. 然后进行粗回归,将目标姿态p的得分矩阵S视为具有J个特征通道的长度为D的1D信号,并利用1D卷积神经网络(1D-CNN)将其映射到深度向量,使用了一个具有残差链接的简单架构,该架构足以粗略估计人级深度。
对输出深度向量D应用软argmax运算,以获得标量深度值^d
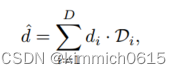
软argmax操作在单人情况下有效,但它假设输入分布为单一模式,这在多人场景中可能会失败。为了克服这一限制,我们建议使用自适应的“局部”软argmax:
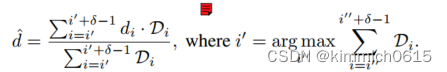
通过最小化目标视图中所有2D姿态fpg的回归深度^d和地面实况人物级深度d*之间的L1损失来训练网络
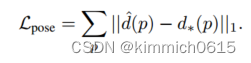
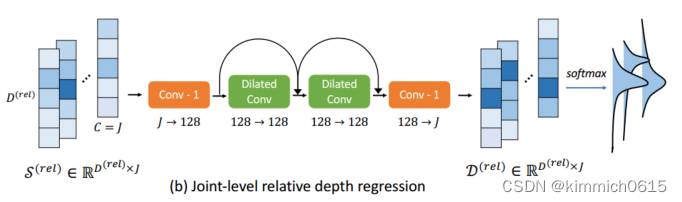
d.下步进行细回归,从每个相对深度层的每个关节j的参考视图中汇总得分矩阵S(rel),使用了一组不同的D(rel)虚拟深度平面,其范围为[-1000;+1000]mm,足以覆盖任意姿态变化的深度范围
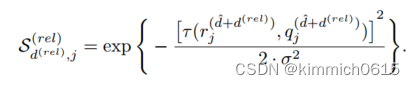
使用另一个1D-CNN从得分矩阵S(rel)回归每个关节的相对深度,由于关节级深度平面紧密地围绕着每个目标人物,因此预计在得分矩阵中会看到分布更广的峰值,因此,与人水平的深度回归相比,需要沿着深度维度的更大的感受野来对所有身体关节的深度进行联合推理 ,网络的输出是相对深度矩阵D(rel)2RD(rel)×J。每个接头的相对深度通过标准的软argmax操作获得
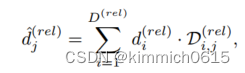
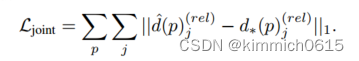
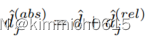
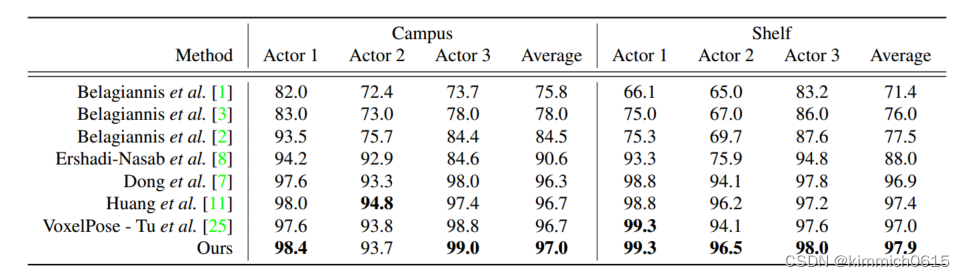
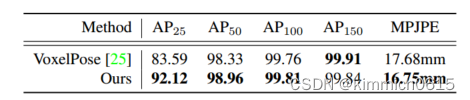
3.实验数据
4.可视化
















 222
222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









