







KL散度(Kullback-Leibler divergence)是一种用来衡量两个概率分布之间的差异性的度量方法。它的本质是衡量在用一个分布来近似另一个分布时,引入的信息损失或者说误差。KL散度的概念来源于概率论和信息论中。KL散度又被称为:相对熵、互熵、鉴别信息、Kullback熵、Kullback-Leible散度(即KL散度的简写)。在机器学习、深度学习领域中,KL散度被广泛运用于变分自编码器中(Variational AutoEncoder,简称VAE)、EM算法、GAN网络中。
通常在概率和统计中,我们会用更简单的近似分布来代替观察到的数据或复杂的分布。KL散度帮助我们衡量在选择近似值时损失了多少信息。KL散度可以用来比较两个概率分布的相似程度,并且常常被用在概率模型比较、信息检索、数据压缩、语音识别、图像识别等领域中。
1.KL散度的定义


2.使用KL散度测量丢失的信息
在信息论中,KL散度被称为相对熵(relative entropy)。假设有两个离散的概率分布 和 Q(x),其中 x 表示分布的取值。KL散度的定义如下:
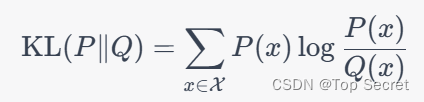
其中 是所有可能的 x 的集合,
可以是以任意正数为底数的对数函数。注意到 KL 散度不具备对称性,即
与
的值可能不同。
KL散度可以被理解为在用 近似
时,每个样本的损失。也就是说,KL散度可以度量从
转换成
所需的额外信息量,或者说是
相对于
的不确定性。如果两个分布相同,KL散度为零;如果两个分布差异越大,则 KL 散度越大。
在机器学习中,KL散度常被用于比较两个概率分布,例如比较真实分布和模型预测分布之间的差异。在深度学习中,KL散度也被用于量化生成模型中生成样本和真实样本的分布之间的差异。KL散度还被用于优化深度神经网络中的训练目标,例如最大化后验概率、最小化数据重构误差等。
本质上,我们用KL散度看的是对原始分布中的数据概率与近似分布之间的对数差的期望。再说一次,如果我们考虑log2,我们可以将其解释为“我们预计有多少比特位的信息丢失”。我们可以根据期望重写公式:
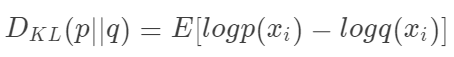
查看KL散度的更常见方法如下:
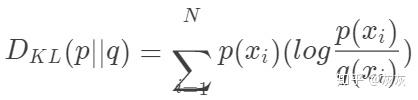
因为
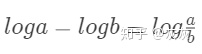
利用KL散度,我们可以精确地计算出当我们近似一个分布与另一个分布时损失了多少信息。让我们回到我们的数据,看看结果如何。
内容参考:【数学知识】KL散度 - 知乎 (zhihu.com)















 1016
1016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









