







前言
TAL(Temporal Action Localization)任务是一种计算机视觉任务,旨在从视频中准确定位和识别动作的时间段。与传统的动作识别任务不同,TAL任务不仅需要识别视频中的动作类别,还需要确定每个动作在视频时间轴上的起始时间和结束时间,TAL任务通常包括以下两个关键步骤:
动作检测(Action Detection):这一步骤的目标是在视频中检测出存在的动作,并确定它们的时间段。通常使用滑动窗口或候选区域的方法来生成候选动作片段,然后通过分类器或回归器来判断每个候选片段是否包含特定的动作类别,并预测其起始和结束时间。
动作分类(Action Classification):在动作检测的基础上,这一步骤的目标是对每个检测到的动作片段进行分类,即确定该片段属于哪个动作类别。通常使用分类器来对每个动作片段进行分类,可以是基于传统的机器学习方法,也可以是基于深度学习的方法。
一、TemporalMaxer论文摘录
论文地址: https://arxiv.org/abs/2303.09055
源码仓库: https://github.com/TuanTNG/TemporalMaxer
1、研究动机
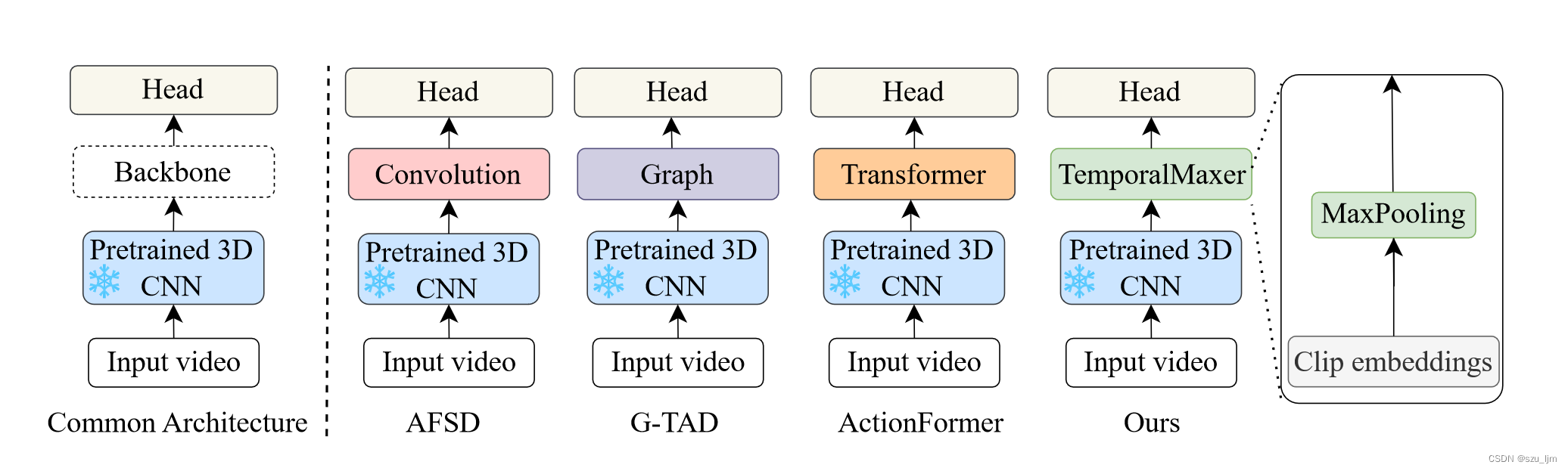
最近在视频理解领域的研究强调了对提取的视频片段特征应用长时序情境建模(TCM)模块的重要性,例如采用复杂的自我注意机制等方法来建模这种长时序的语境关系。现有的TAL模型可以大致拆解为,首先使用从预训练好的 3D-CNN 网络(如 I3D 和 TSN)中提取的特征作为输入,然后编码器(称为骨干网络)将特征编码到潜在空间,解码器(称为检测头)预测动作实例。
现有骨干网络可以大致分成几种,AFSD模型中提出用一维卷积层捕捉局部时间上下文关系,G-TAD 模型创新性利用图结构建模特征间的时空语义关系,ActionFormer将Transformer架构用于建模长期时序上下文依赖。
但现有方法存在以下几点问题:
1、这种长时序情景建模的代价是高昂的计算成本和开销,而且这些方法,包括Transformer的自注意力机制和GNN的信息聚合机制的有效性尚未得到仔细分析。骨干网络局限于需要昂贵参数和计算的Transformer架构。
2、与其他领域(如机器翻译任务中的输入特征序列具有较大差异)不同的是,视频片段呈现出较高的冗余度,这导致了预提取特征的高度相似性,而自注意力机制和图结构会让特征序列相似度变高,不利于做特征区分。
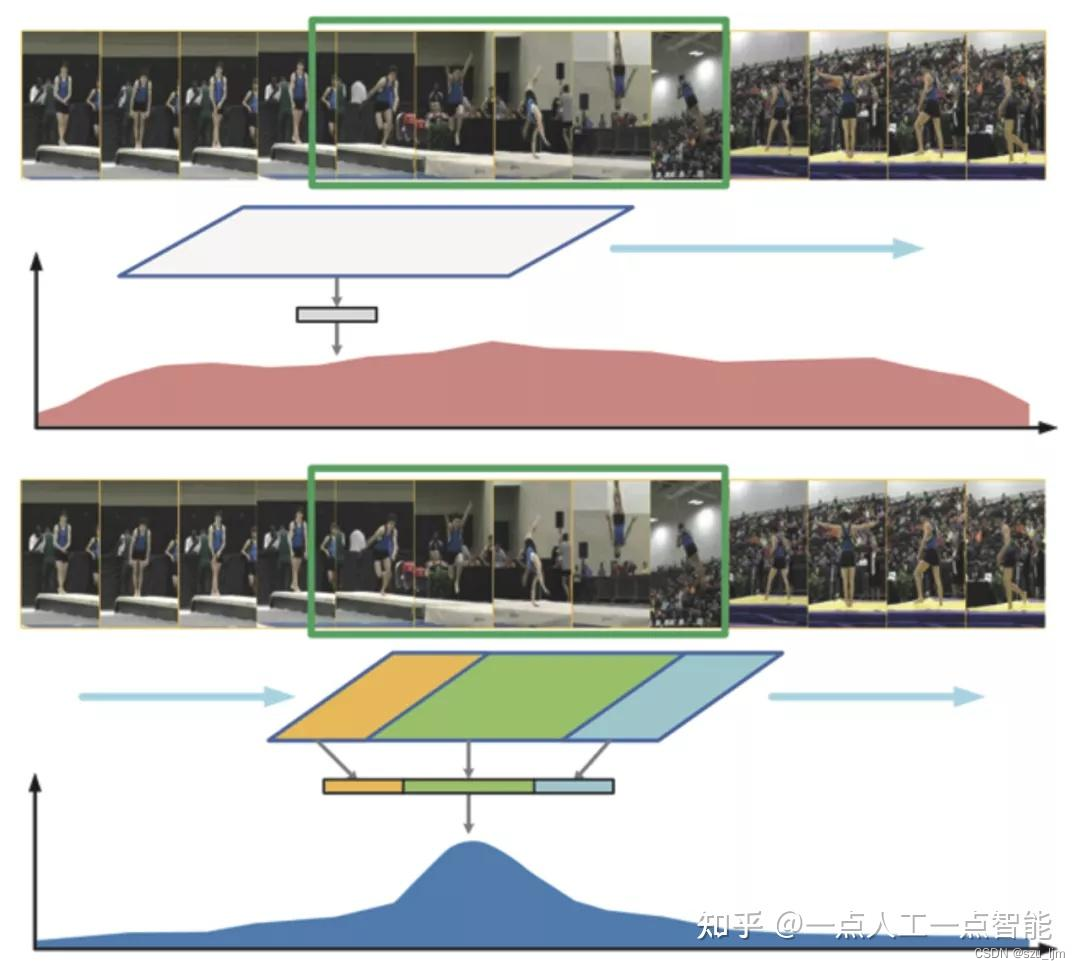
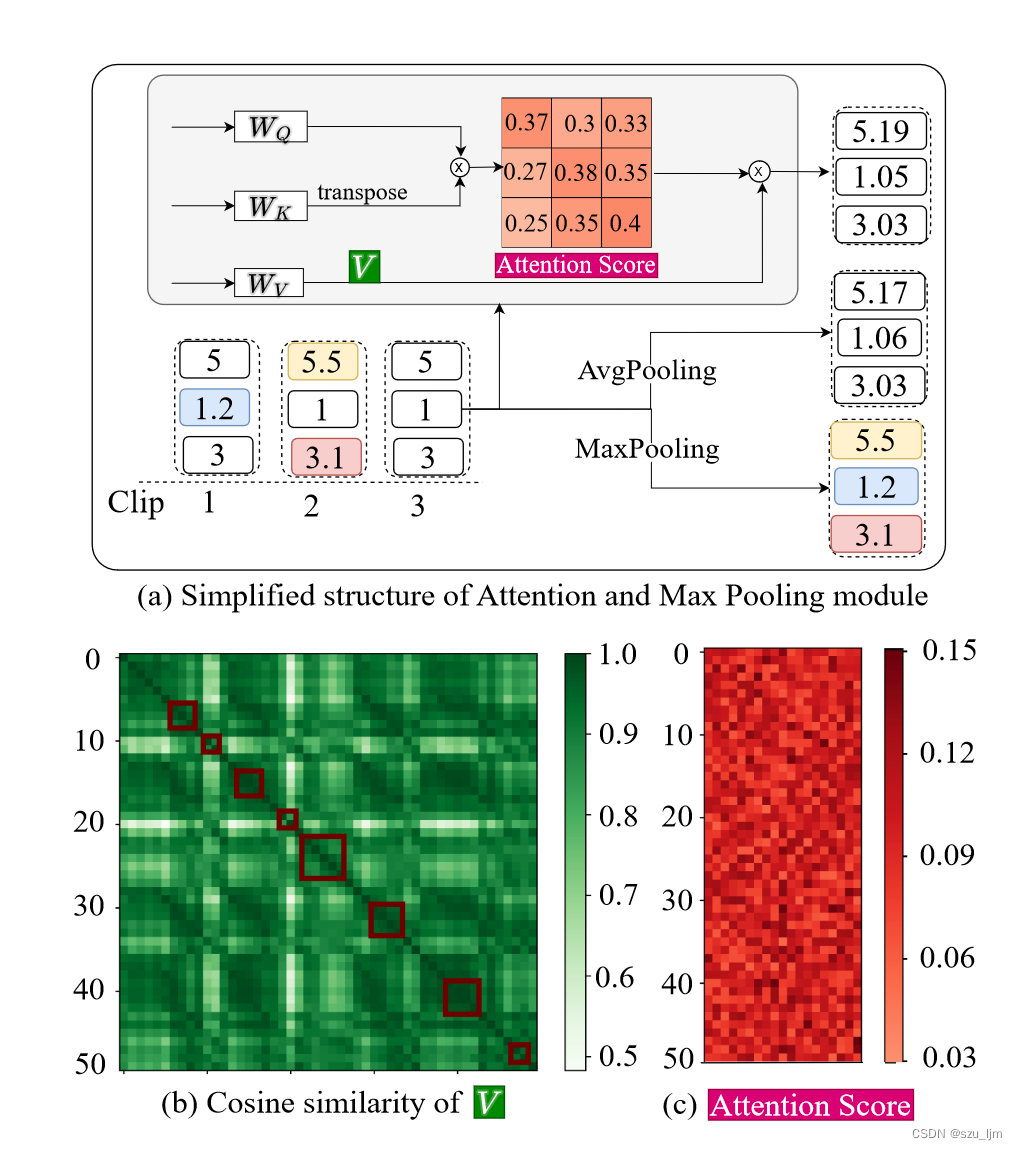
研究者通过实验分析还发现,自注意力机制会将嵌入的特征序列平均化,这样的效果近似于平均池化,在长时序情境建模下,冗余的相似帧会导致丢失时序上局部的微小变化。
当输入的片段嵌入高度相似时,考虑到值特征 V 高度相似且注意力得分平均分配,Transformer倾向于像平均池化那样对嵌入的序列特征进行平均池化。相比之下,最大池化可以保留相邻嵌入的特征序列的最关键信息,并进一步去除视频中的冗余信息,从而加强了动作边界特征和背景特征的区分度,提高了的定位准确性。
2、改进方法分析
研究者受最近用类似 MLP 的模块或傅立叶变换取代注意力模块的成功方法的启发,他们认为这些模块的基本要素是标记混合器,可汇总标记间的信息。基于将骨干网络参数最小化,集中精力最大限度地提高关键信息量的想法,研究者提出了TemporalMaxer模型,它通过一个基本的、无参数的、局部区域运行的最大池化块,在最大化提取的视频片段特征信息的同时,最小化了长时序时空语义关系建模。
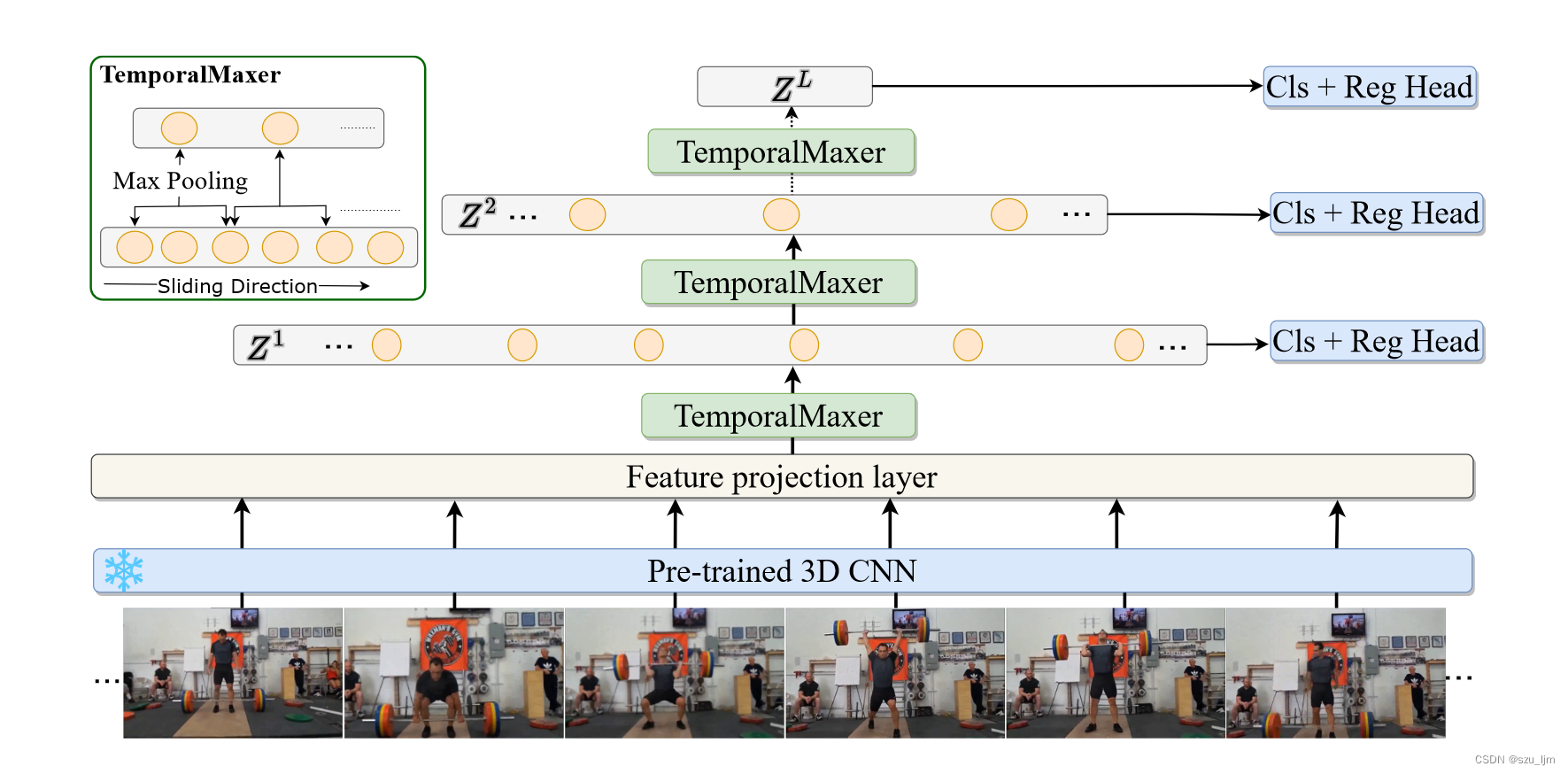
TemporalMaxer利用最大池化块(Max Pooling)来动态建模时序上下文依赖,最大池化块(Max Pooling)应用于时序特征金字塔层级之间,以最大限度地提高高相似度的嵌入序列特征的关键信息特征的传递。具体来说,它首先使用预先训练好的 3D CNN 提取视频中每个片段的特征。接着骨干网对片段特征进行编码,形成多尺度特征金字塔。骨干网络由一维卷积层和 TemporalMaxer 层组成,最后轻量级分类和回归头将特征金字塔解码为每个输入时刻的候选动作。
下面具体看看编码器和解码器的网络细节:
编码器部分主要由投影层和最大池化模块组成。输入的视频特征序列可以表达为 X = x 1 , x 2 , . . . , x T , x i ∈ R 1 × D i n X = {x_1, x_2, ..., x_T }, x_i ∈ R^{1×D_{in}} X=x1,x2,...,xT,xi∈R1×Din, 首先在特征序列的第一维度上进行拼接,然后输入中的两个特征投影模块 E1 和 E2,得到具有 D D D 维特征空间的投影特征 X p ∈ R T × D X_p ∈ R^{T ×D} Xp∈
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











