






一、安装ollama
安装过程需要访问github,如果网络不好,可以根据自己的实际需要预先进行如下代理设置(所以看自己的代理,):
git config --global url."https://github-proxy,XXX.com/".insteadOf "https://github.com/"
也可以使用如下的方式配置代理:
export HTTPS_PROXY=XXX.com:8080 export HTTP_PROXY=XXX.com:8080
再执行以下命令:
curl -fsSL https://ollama.com/install.sh | sh
如果由于网络原因,也可以直接下载Linux版本,然后重命名为ollama,再修改install.sh中的TEMP_DIR路径为ollama文件所在目录。最后执行bash install.sh直接进行安装。
Linux上更具体的安装细节可以参考官方说明。
在安装完Ollama之后,我们需要准备一个已经训练好的大型语言模型。Ollama支持多种不同的模型格式,包括Hugging Face的Transformers模型、PyTorch模型等。
二、启动服务
如何利用ollama快速启动一个大模型服务?
方法1:Ollama官方下载
可以通过ollama library直接查阅目标模型是否存在,比如想要运行Qwen,可以直接运行如下:
ollama run qwen
方法2:本地模型
将从hf上下载的pytorch模型文件转为UUGF格式。
clone ollama/ollama 仓库:
git clone git@github.com:ollama/ollama.git ollama
cd ollama
fetch 该仓库中的 llama.cpp submodule:
git submodule init
git submodule update llm/llama.cpp
安装Python依赖:
pip3 install -r llm/llama.cpp/requirements.txt -i https://mirrors.cloud.tencent.com/pypi/simple
模型格式转换:
python3 llm/llama.cpp/convert-hf-to-gguf.py /model_zoo/LLM/Qwen/Qwen1.5-4B-Chat/ --outtype f16 --outfile qwen1.5-4B-chat.gguf
构建quantize工具:
make -C llm/llama.cpp quantize
当然,如果此前已经使用过llama.cpp,那么可以直接使用已经编译出的llama.cpp/build/bin/quantize工具。
模型量化:
/Repository/LLM/llama.cpp/build/bin/quantize qwen1.5-4B-chat.gguf qwen1.5-4B-chat_q4_0.gguf q4_0
至此,生成量化后的模型qwen1.5-4B-chat_q4_0.gguf
-rw-r--r-- 1 root root 7.4G Apr 13 08:08 qwen1.5-4B-chat.gguf
-rw-r--r-- 1 root root 2.2G Apr 13 08:12 qwen1.5-4B-chat_q4_0.gguf
新建Modelfile,比如名为 qwen1.5-4B-chat_q4_0.mf
FROM qwen1.5-4B-chat_q4_0.gguf
# set the temperature to 1 [higher is more creative, lower is more coherent]
PARAMETER temperature 0.7
PARAMETER top_p 0.8
PARAMETER repeat_penalty 1.05
PARAMETER top_k 20
TEMPLATE """{{ if and .First .System }}<|im_start|>system
{{ .System }}<|im_end|>
{{ end }}<|im_start|>user
{{ .Prompt }}<|im_end|>
<|im_start|>assistant
{{ .Response }}"""
# set the system message
SYSTEM """
You are a helpful assistant.
"""
在创建模型之前需要注意检测是否已经启动 ollama 服务,如果没有启动,则通过以下命令启动:
ollama serve &
可以通过以下命令查看model清单:
ollama list
结果如下:
[GIN] 2024/04/13 - 08:29:44 | 200 | 43.91µs | 127.0.0.1 | HEAD "/"
[GIN] 2024/04/13 - 08:29:44 | 200 | 5.550372ms | 127.0.0.1 | GET "/api/tags"
创建模型:
ollama create qwen1.5-4B -f qwen1.5-4B-chat_q4_0.mf
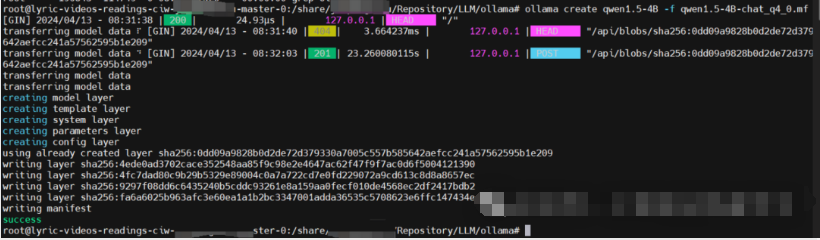
此时再运行ollama list,结果如下:
[GIN] 2024/04/13 - 08:33:33 | 200 | 31.789µs | 127.0.0.1 | HEAD "/"
[GIN] 2024/04/13 - 08:33:33 | 200 | 13.834699ms | 127.0.0.1 | GET "/api/tags"
NAME ID SIZE MODIFIED
qwen1.5-4B:latest 2ca4f59f16eb 2.3 GB About a minute ago
启动模型服务:
ollama run qwen1.5-4B
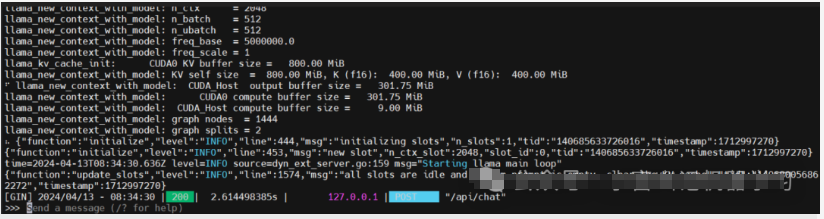
输入,“你好,你是谁”
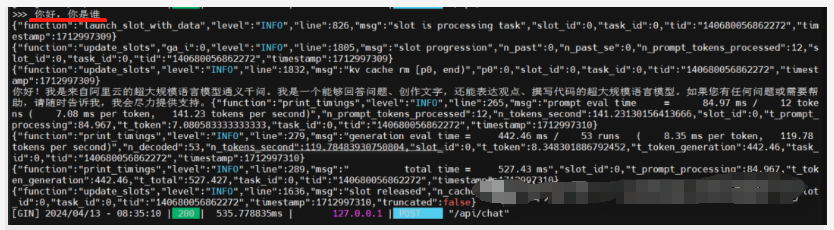
三、API测试
如何通过API测试模型服务?API的详情可以参考官方说明。
对Chat接口进行测试:
curl http://localhost:11434/api/chat -d '{
"model": "qwen1.5-4B",
"messages": [
{ "role": "user", "content": "你好,你是谁" }
],
"stream": false
}'
以上设置非流式返回:
{"model":"qwen1.5-4B","created_at":"2024-04-13T08:41:52.481530089Z","message":{"role":"assistant","content":"你好,我是通义千问。我是一个基于阿里云的大规模语言模型,能够回答各种问题、创作文字,还能表达观点、撰写代码。有什么我可以帮助你的吗?"},"done":true,"total_duration":367232392,"load_duration":8591084,"prompt_eval_duration":26868000,"eval_count":40,"eval_duration":331108000}
对 generate 结果进行测试:
curl http://localhost:11434/api/generate -d '{
"model": "qwen1.5-4B",
"prompt": "你是谁?",
"stream": false
}'
接口返回:
{"model":"qwen1.5-4B","created_at":"2024-04-13T08:50:19.674913783Z","response":"我是阿里云开发的超大规模语言模型,我叫通义千问。","done":true,"context":[151644,872,198,105043,100165,11319,151645,198,151644,77091,198,104198,102661,99718,100013,9370,71304,105483,102064,104949,3837,35946,99882,31935,64559,99320,56007,1773],"total_duration":180988339,"load_duration":7694382,"prompt_eval_duration":26834000,"eval_count":18,"eval_duration":145800000}
四、总结
本文主要介绍如何安装ollama,并演示2种加载模型的方法:
(1)拉取ollama官方已经有的模型,进行LLM服务部署。
(2)加载本地模型部署大模型服务。
最后,对部署的LLM服务的接口进行测试。
五、最后分享
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

5. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









