






以下是文章《Mixture of Experts Pattern for Transformer Models》的中文翻译
Mixture of Experts Pattern for Transformer Models
传统的Transformer模型是密集激活的,这意味着在每次前向传播过程中都会使用到模型的所有参数。因此,参数数量的增加会导致训练和推理过程中计算复杂度和内存消耗的增加。
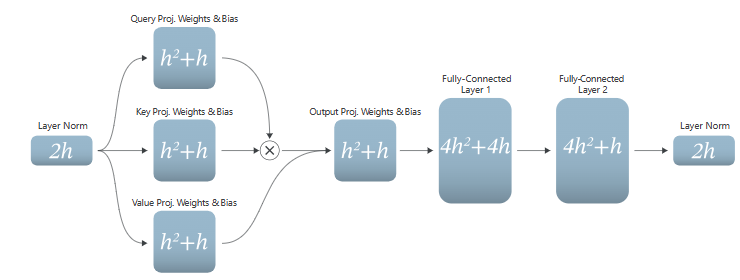
在给定的Transformer层中,参数数量N由模型的隐藏层大小h决定,并且(假设注意力头的维度乘以头的数量等于隐藏层大小,并且假设前馈网络的维度是隐藏层大小的4倍)可以计算为:
下图展示了这些参数如何在典型的Transformer层的不同子模块中分布:
计算复杂度可以通过前向传播过程中执行的浮点运算(FLOPs)数量来衡量。我们可以估计给定Transformer块的FLOPs数量为:
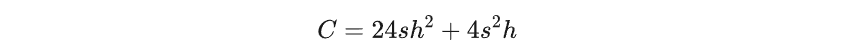
其中s是序列长度(输入中的token数量),为了简化,假设批量大小为1。
因此,计算复杂度随着隐藏层大小的增加而呈二次方增加,并且在给定固定序列长度的情况下,随着参数数量的增加而线性增加:
已经观察到,增加基于Transformer的语言模型的参数数量可以提高它们的学习能力[4][5]。然而,这些改进是以增加计算复杂度为代价的,意味着更慢和更昂贵的预训练、微调和推理。
image
这种关系提出了机器学习中一个仍然重要的研究问题:我们如何在不增加复杂度和成本的情况下,实现增加模型大小的好处(即,执行更复杂任务的能力)?
在这篇文章中,我将探讨Mixture of Experts(MoE)模式,它已经被应用于Transformer模型,以努力解决这个问题。
1. Mixture of Experts
在机器学习中,Mixture of Experts(MoE)的概念比Transformer架构早了几十年。Jacobs等人在1991年将MoE方法应用于元音识别问题[5]。
尽管MoE模式的实现各不相同,但基本思想是一致的:不是使用单一的参数集来计算每个输入的输出,而是将每个输入路由到模型参数的一个特定子集中。然后,每个可能的参数子集可以被视为一个专家,负责处理特定类型的输入。
下图提供了这个想法的粗略说明:
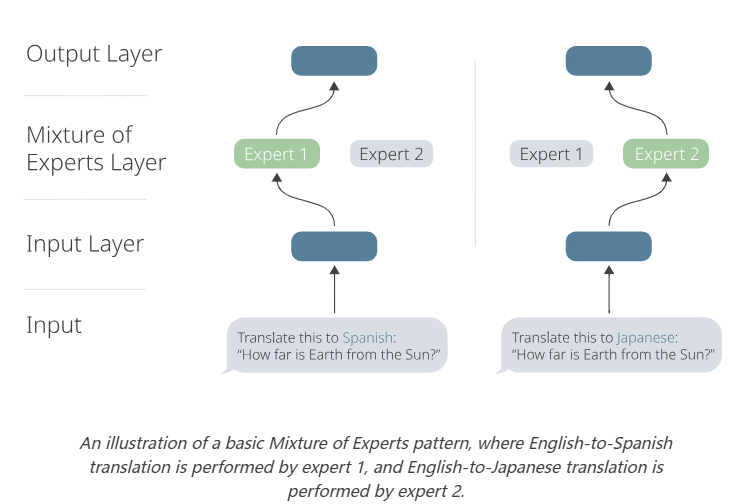
一个基本的Mixture of Experts模式的说明: 其中英语到西班牙语的翻译由专家1执行,英语到日语的翻译由专家2执行。(就是上面图上的第一个专家和第二个专家)。
2. 路由
任何Mixture-of-Experts实现的一个重要细节是路由算法,它决定对于给定的输入使用哪个专家(或一组专家)。
2.1 软选择
一些早期的工作将软选择路由算法(也称为连续混合专家)应用于深度学习模型[6]。在这种方法中,每个专家都用于每个输入,但是每个专家的贡献由一个门控函数加权,这是一个学习到的函数,它为每个专家计算一个权重或重要性,使得所有专家的权重之和为1。
由于每个专家都用于每个输入,这种方法仍然导致一个密集激活的模型,因此没有解决增加计算复杂度的问题。然而,这项工作为更先进的MoE实现提供了重要的垫脚石。
以下代码展示了一个连续混合专家层的实现,如[6]中描述的。在这种情况下,专家是单独的线性层,每个都有自己的一组参数,门控函数本身是一个两层的前馈网络。对于每个输入,门控函数为每个专家计算一个权重,连续混合专家层的输出是各个专家输出的加权和:
class ContinuousMixtureOfExpertsLayer(torch.nn.Module):
def __init__(self, in_features: int, out_features: int,
num_experts: int, gating_network_hidden_units: int):
super().__init__()
self.experts = torch.nn.ModuleList([
torch.nn.Linear(in_features, out_features)
for _ in range(num_experts)
])
self.gating_function_input = torch.nn.Linear(
in_features,
gating_network_hidden_units
)
self.gating_function_output = torch.nn.Linear(
gating_network_hidden_units,
num_experts
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 计算每个专家的输出
expert_outputs = []
for expert in self.experts:
expert_output = expert(x)
expert_output = torch.nn.functional.relu(expert_output)
expert_outputs.append(expert_output)
expert_outputs = torch.stack(expert_outputs, dim=1)
# 执行门控函数以计算每个专家的权重
gating_function_hidden_state = self.gating_function_input(x)
gating_function_hidden_state = torch.nn.functional.relu(gating_function_hidden_state)
gating_function_output = self.gating_function_output(gating_function_hidden_state)
expert_weights = torch.nn.functional.softmax(gating_function_output, dim=1)
# 计算层的输出作为专家输出的加权和
return torch.sum(
expert_outputs * expert_weights.unsqueeze(-1),
dim=1
)
在训练过程中,每个专家变得专门处理特定类型的输入,门控函数学会将每个输入路由到最适合处理它的专家。
为了更好地理解不同专家如何专门处理某些类型的输入,我在MNIST数据集上训练了一个连续混合专家模型。对于训练模型的隐藏层中的四个专家,下图显示了被赋予9个最高专家权重的测试示例:
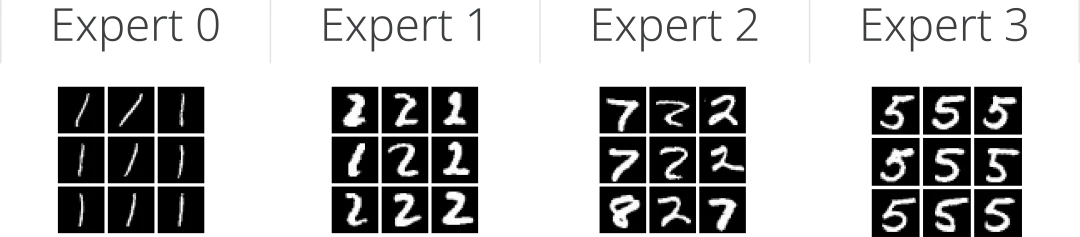
一个连续混合专家模型中每个专家权重最高的示例。
2.2 硬选择
后来的工作通过应用硬选择路由算法扩展了MoE模式,其中只有一部分专家用于任何给定的输入,标志着从密集激活到稀疏模型的转变。Shazeer, Noam等人引入了稀疏门控混合专家层,并在大规模自然语言处理中应用硬选择,使用的门控函数与上述连续混合专家层类似。
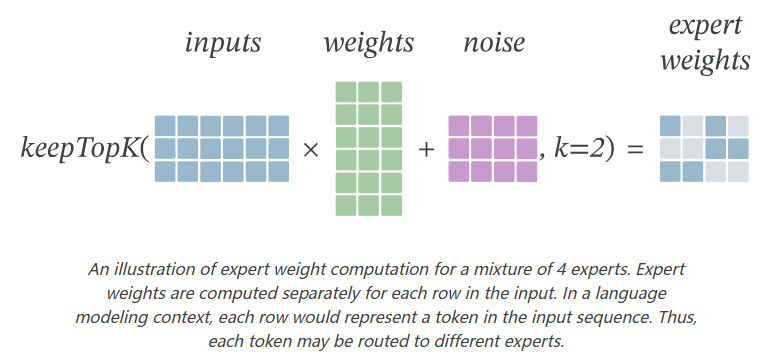
门控函数由一个线性层组成,它计算每个专家的权重,并添加随机噪声以帮助负载均衡(下面将进一步讨论负载均衡问题)。在Softmax函数应用于专家权重之前,执行一个KeepTopK操作,将除前k个专家之外的所有专家的权重设置为-∞。这确保了只有前k个专家在应用Softmax后权重大于0。
下图说明了4个专家的专家权重计算。专家权重是为输入的每一行单独计算的。在语言建模的上下文中,每一行将表示输入序列中的一个token。因此,每个token可以路由到不同的专家。
以下代码包括了稀疏门控混合专家层的门控函数的基本实现:
class SparselyGatedMixtureOfExpertsLayer(torch.nn.Module):
def __init__(self, in_features: int, num_experts: int):
super().__init__()
self.w_g = torch.nn.Parameter(torch.zeros(in_features, num_experts))
self.w_noise = torch.nn.Parameter(torch.zeros(in_features, num_experts))
def tunable_noise(self, x):
"""计算门控函数输出的可调噪声。"""
weighted_noise = torch.matmul(x, self.w_noise)
return torch.randn_like(weighted_noise) * torch.nn.functional.softplus(weighted_noise)
def compute_expert_weights(self, x, k):
noise = self.tunable_noise(x)
expert_weights = torch.matmul(x, self.w_g) + noise
print("Raw Expert Weights: \n", expert_weights)
# 获取底部k个权重的索引
_, bottom_k_indices = torch.topk(expert_weights, k=k, dim=1, largest=False)
print("Bottom K Expert Indices: \n", bottom_k_indices)
# 将底部k个权重设置为-inf
expert_weights = expert_weights.scatter(dim=1, index=bottom_k_indices, value=-float("inf"))
# 对专家权重应用softmax
expert_weights = torch.nn.functional.softmax(expert_weights, dim=1)
print("Final Expert Weights: \n", expert_weights)
return expert_weights
为了看到这一点,我们可以使用与上图相同的输入形状和专家数量来执行门控函数:
layer = SparselyGatedMixtureOfExpertsLayer(in_features=6, num_experts=4)
x = torch.randn(3, 6)
layer.compute_expert_weights(x, k=2)
Raw Expert Weights:
tensor([[ 0.3931, 0.8921, -0.9925, -1.1449],
[ 0.3835, 0.3427, -0.0513, -0.2176],
[-0.3423, 0.4838, 0.0443, 1.7873]], grad_fn=<AddBackward0>)
Bottom K Expert Indices:
tensor([[3, 2],
[3, 2],
[0, 2
]])
Final Expert Weights:
tensor([[0.3778, 0.6222, 0.0000, 0.0000],
[0.5102, 0.4898, 0.0000, 0.0000],
[0.0000, 0.2136, 0.0000, 0.7864]], grad_fn=<SoftmaxBackward0>)
稀疏门控混合专家层最初应用于LSTM模型的语言建模[8],但后来成功地将基于前k个专家权重的硬选择路由的想法应用于Transformer模型中,引入了Switch Transformers(Fedus, W., Zoph, B.和Shazeer, N., 2022)。
2.3 Switch Transformer
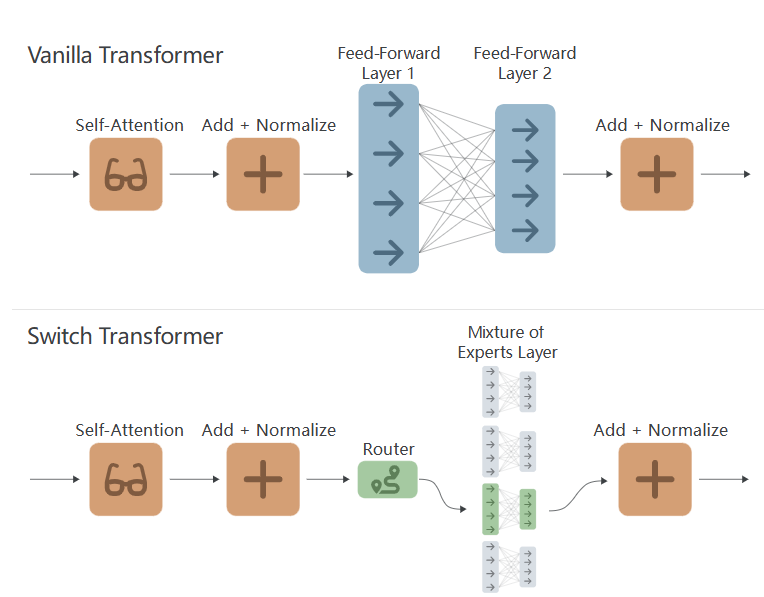
Switch Transformer是对传统密集激活Transformer模型的修改。具体来说,Switch Transformers用稀疏激活的混合专家层替换了Transformer块中的全连接前馈网络。然而,在这种情况下,每个专家本身是一个两层前馈网络。
下图说明了典型的“vanilla”Transformer块和Switch Transformer块之间的区别:
对于具有隐藏层大小h和专家数量E的Switch Transformer块,总参数数量由以下公式给出:
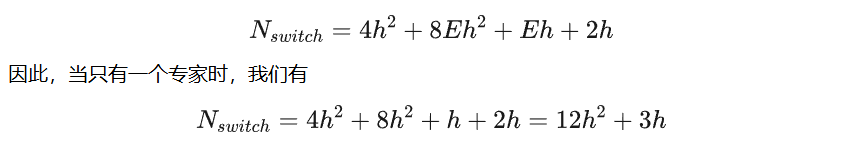
这几乎与密集激活Transformer的参数数量相同。微小的区别在于Switch Transformer不包括其任何线性层的偏置项,并且路由器的权重引入了额外的Eh参数。
为了说明这一点,我们可以使用开源HuggingFacetransformers库中包含的Switch Transformer的PyTorch实现[10]。以下代码展示了如何使用SwitchTransformersBlock类实例化Switch Transformer层,然后计算不同值的h和E的参数数量:
import itertools
from tabulate import tabulate
from transformers.models.switch_transformers.modeling_switch_transformers import SwitchTransformersBlock, SwitchTransformersConfig
from utils import human_readable
if __name__ == "__main__":
hidden_sizes = [768, 1024, 2048]
number_of_experts = [1, 2, 4]
table_data = []
for hidden_size, num_experts in itertools.product(hidden_sizes, number_of_experts):
config = SwitchTransformersConfig(
d_model=hidden_size,
num_heads=hidden_size // 64,
num_layers=1,
d_ff=4*hidden_size,
num_experts=num_experts
)
layer = SwitchTransformersBlock(config, is_sparse=True)
parameter_count = sum([p.numel() for p in layer.parameters()])
table_data.append((hidden_size, num_experts, human_readable(parameter_count)))
print(tabulate(
table_data,
headers=["Hidden Size", "Number of Experts", "Parameter Count"],
tablefmt="fancy_grid"
))
╒═══════════════╤═════════════════════╤═══════════════════╕
│ Hidden Size │ Number of Experts │ Parameter Count │
╞═══════════════╪═════════════════════╪═══════════════════╡
│ 768 │ 1 │ 7.08M │
├───────────────┼─────────────────────┼───────────────────┤
│ 768 │ 2 │ 11.80M │
├───────────────┼─────────────────────┼───────────────────┤
│ 768 │ 4 │ 21.24M │
├───────────────┼─────────────────────┼───────────────────┤
│ 1024 │ 1 │ 12.59M │
├───────────────┼─────────────────────┼───────────────────┤
│ 1024 │ 2 │ 20.98M │
├───────────────┼─────────────────────┼───────────────────┤
│ 1024 │ 4 │ 37.75M │
├───────────────┼─────────────────────┼───────────────────┤
│ 2048 │ 1 │ 50.34M │
├───────────────┼─────────────────────┼───────────────────┤
│ 2048 │ 2 │ 83.89M │
├───────────────┼─────────────────────┼───────────────────┤
│ 2048 │ 4 │ 151.01M │
╘═══════════════╧═════════════════════╧═══════════════════╛
Switch Transformer块的计算复杂度,以前向传播FLOPs的数量来衡量,可以估计为:
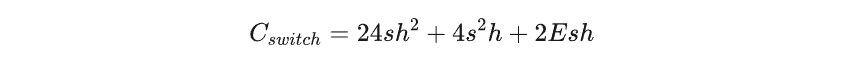
注意vanilla和Switch Transformer计算复杂度之间的唯一区别是路由器引入的额外2Esh FLOPs。这意味着通过增加专家数量E,我们可以显著增加模型参数的数量,而只增加微不足道的计算复杂度。
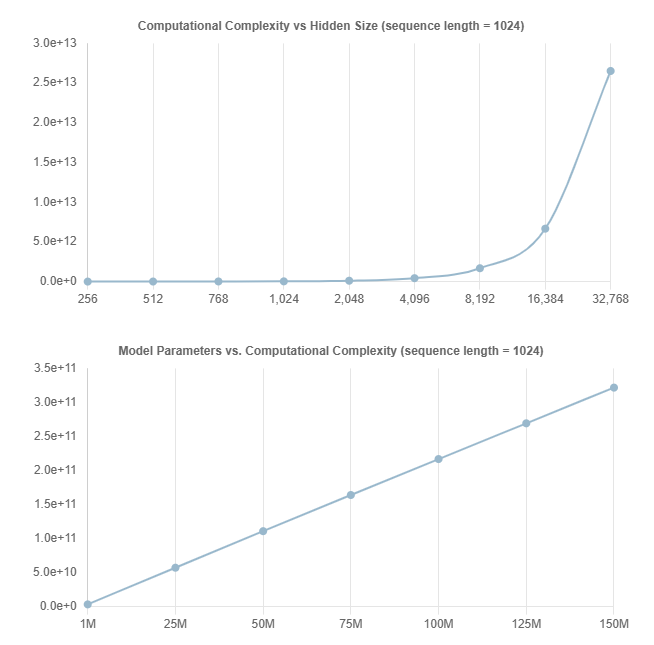
下图绘制了不同E值下的模型参数与计算复杂度的对比图。
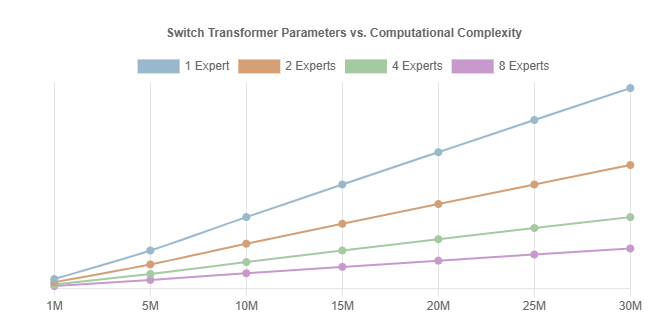
给定相同数量的参数,具有更多专家的Switch Transformer比密集激活的Transformer更具计算效率。例如,具有3000万参数和8个专家的Switch Transformer在前向传播期间执行约13.62亿FLOPs,而相同大小的密集激活Transformer执行约68.06亿FLOPs。
负载均衡
训练混合专家模型的一个挑战是需要在专家之间平衡责任。如果所有输入都路由到仅有的一两个可用专家,那么其余的专家基本上是无用的,因为它们的参数在预测输出时从未被使用。
如果没有额外的保护措施,这种专家不平衡可能会在训练过程中自然发生。Eigen, D., Ranzato, M.A.和Sutskever很好地描述了这一点,当他们写道:
《每个层中表现最好的专家最终会压倒其余的专家。这是因为前几个例子增加了这些专家的门控权重,这反过来导致它们以更高的门控权重更频繁地被选择。这导致它们训练更多,它们的门控权重再次增加,如此循环。》
在训练MNIST数字分类的连续混合专家模型时,我遇到了同样的现象。下图显示了训练过程中观察到的平均专家权重:
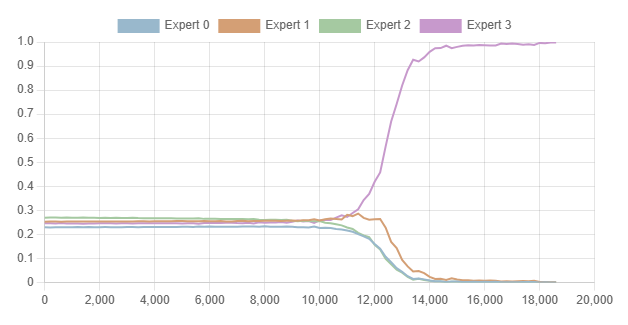
为了对抗这种不平衡,实施了各种负载均衡技术,目的是确保所有专家在训练过程中大致承担相等的责任。Eigen, D., Ranzato, M.A.和Sutskever通过“丢弃”任何开始压倒其他专家的专家来解决这个问题。
维护并更新每个专家的门控权重的累积总数,并在每个训练步骤中更新。如果任何专家的门控权重之和远远高于所有专家的门控权重的平均总和,那么该专家在训练步骤中的门控权重将被设为0。
以下代码展示了一个修改后的ContinuousMixtureOfExpertsLayer实现,其中包括了这种负载均衡技术:
def forward(self, x: torch.Tensor) -> torch.Tensor:
# 计算每个专家的输出
expert_outputs = []
for expert in self.experts:
expert_output = expert(x)
expert_output = torch.nn.functional.relu(expert_output)
expert_outputs.append(expert_output)
expert_outputs = torch.stack(expert_outputs, dim=1)
# 执行门控函数以计算每个专家的权重
gating_function_hidden_state = self.gating_function_input(x)
gating_function_hidden_state = torch.nn.functional.relu(gating_function_hidden_state)
gating_function_output = self.gating_function_output(gating_function_hidden_state)
expert_weights = torch.nn.functional.softmax(gating_function_output, dim=1)
step_total_assignment = torch.sum(expert_weights, dim=0)
self.running_total_assignment += step_total_assignment
if self.balance:
mean_total_assignment = torch.mean(self.running_total_assignment)
expert_mask = self.running_total_assignment.clone()
expert_mask = expert_mask.detach()
expert_mask[self.running_total_assignment - mean_total_assignment > self.threshold] = 0
expert_mask[self.running_total_assignment - mean_total_assignment <= self.threshold] = 1
expert_weights = expert_weights * expert_mask
expert_weights = torch.nn.functional.softmax(expert_weights, dim=1)
# 计算层的输出作为
专家输出的加权和
return torch.sum(
expert_outputs * expert_weights.unsqueeze(-1),
dim=1
)
在添加负载均衡约束后,门控权重在整个训练过程中更加均匀地分布: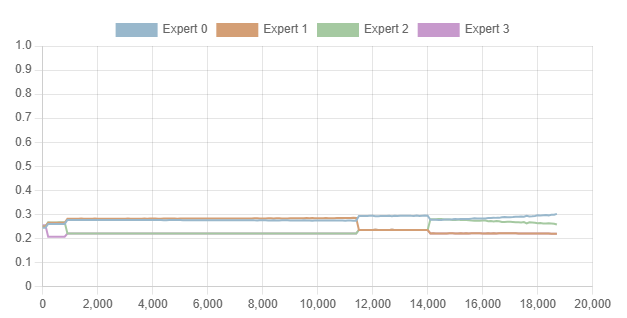
负载均衡损失
其他人通过引入额外的损失项来解决负载均衡问题,这些损失项被添加到训练目标中。Switch Transformer模型是用辅助负载均衡损失训练的,该损失计算为两个向量ff和PP的点积,两者的长度均为E,其中ff是路由到每个专家的token比例,PP是对应于每个专家的门控权重比例。
例如,考虑一个包含三个输入token的批次,其对应的门控权重对应于4个专家:
# 门控权重的形状为[sequence_length, num_experts]
gating_weights = torch.tensor([
[0.25, 0.50, 0.00, 0.25],
[0.70, 0.10, 0.10, 0.10],
[0.30, 0.40, 0.20, 0.10],
])
使用Switch Transformer的top-1路由算法,我们知道第一个token将被路由到索引为1的专家,第二个token将被路由到索引为0的专家,第三个token将被路由到索引为1的专家。我们可以将这些路由决策表示为一个一位有效张量:
# 一位有效路由决策的形状为[sequence_length, num_experts]
# 如果索引i,j为1,则token i被路由到专家j
routing_decisions = torch.tensor([
[0, 1, 0, 0],
[1, 0, 0, 0],
[0, 1, 0, 0],
])
然后我们可以按如下方式计算向量ff和PP:
# f的值为[0.33, 0.67, 0.00, 0.00],
#因为1/3的token被路由到专家0,
#2/3的token被路由到专家1,
#0个token被路由到专家2和3。
f = routing_decisions.mean(axis=0, dtype=torch.float32)
# P的值为[0.41, 0.33, 0.10, 0.15]。所有token和专家的门控权重之和为3.0,因此为了得到专家0的门控权重比例,我们计算
# (0.25 + 0.70 + 0.30) / 3.0 = 0.41,以及其他每个专家的计算。
P = gating_weights.mean(axis=0, dtype=torch.float32)
为了计算辅助负载均衡损失Laux,我们计算ff和PP的点积,然后将结果乘以E,以便损失不依赖于专家的绝对数量:
# 辅助负载均衡损失为1.44
auxillary_loss = torch.dot(f, P) * num_experts
用于训练模型的完整损失函数结合了辅助负载均衡损失Laux和标准交叉熵损失LCE。使用额外的超参数α来控制辅助损失的相对重要性:
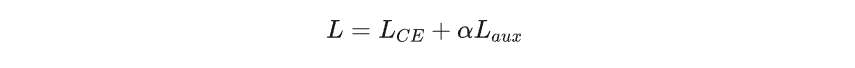
专家容量
一些MoE实现[9][11]使用固定的专家容量来限制可以路由到任何一个专家的最大token数量。任何路由到已满容量的专家的token都被视为溢出token,并且不会被路由到任何专家。溢出token的嵌入表示被传递到下一层不变。
这里先扯一下相关概念,不然你后面看的可能有有点懵
名词:“拍卖”和“出价”是在一个算法或模型的上下文中使用的比喻,它们用来描述一种资源分配策略,特别是在混合专家(Mixture of Experts, MoE)模型中路由输入到不同专家的过程。这里并不是指真实的拍卖过程,而是一种算法上的类比。
拍卖(Auction)
在MoE模型中,所谓的“拍卖”是指一个过程,其中每个专家(或处理单元)“竞标”处理输入数据(如token)的机会。这个概念来自于在真实的拍卖中,不同的参与者出价以赢得物品或服务。在MoE模型的背景下,每个专家根据其对输入数据的处理能力或相关性来“出价”,以决定哪个专家最适合处理特定的输入。
出价(Bidding)
“出价”在这里指的是每个专家根据其门控权重(gating weights)对处理特定输入的“意愿”或“能力”的量化表示。在BASE(Balanced Assignment of Experts)层的例子中,每个专家对每个输入token的出价是基于该token的门控权重,即专家处理该token的偏好程度。出价最高的专家将获得处理该token的权利。
这种拍卖机制的目的是为了在多个专家之间公平地分配输入数据,确保每个专家都能获得一定数量的输入来处理,从而避免某些专家过载而其他专家闲置的情况。这种方法有助于提高模型的整体效率和效果,因为它允许每个专家专注于其最擅长处理的输入类型。
通过设计平衡
通过重新设计路由算法,其他MoE实现能够在不引入辅助损失项或设置专家容量限制的情况下实现专家之间的平衡。Lewis, Mike等人引入了平衡分配专家(BASE)层,它将每个输入token的相等数量路由到每个专家,而不是简单地选择每个单独token具有最高门控权重的专家。
BASE层使用拍卖算法[13]进行路由,每个专家对最优token出价(对于任何专家来说,最优token是具有该专家最高门控权重的token)。拍卖结束时,每个专家都剩下相等数量的token。例如,如果有16个专家和1024个token在输入序列中,每个专家将被分配102416=64个token。
为了理解拍卖算法的工作原理,考虑一个有3个专家、3个输入token和一个3x3门控权重矩阵的场景。在最简单的情况下,每个专家将对不同的token出价并赢得该token:
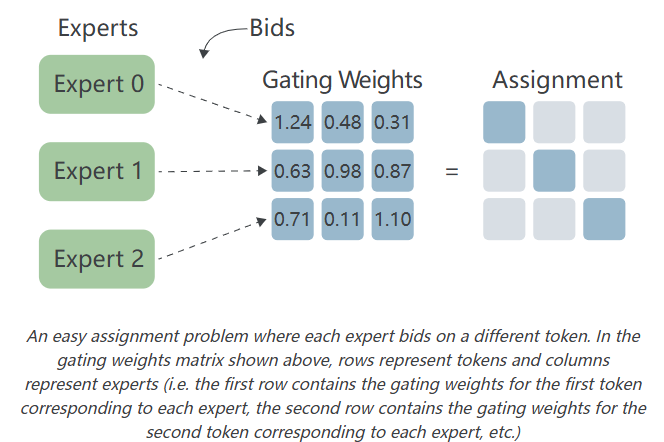
一个简单的分配问题,每个专家对不同的token出价。在上面显示的门控权重矩阵中,行代表token,列代表专家(即,第一行包含每个专家对应的第一个token的门控权重,第二行包含每个专家对应的第二个token的门控权重,等等)。
然而,如果有足够多的专家和token,两个专家对同一个token出价的可能性极小。几乎可以肯定的是,多个专家会对同一个token出价,在这种情况下,拍卖算法必须决定哪个专家赢得该token:
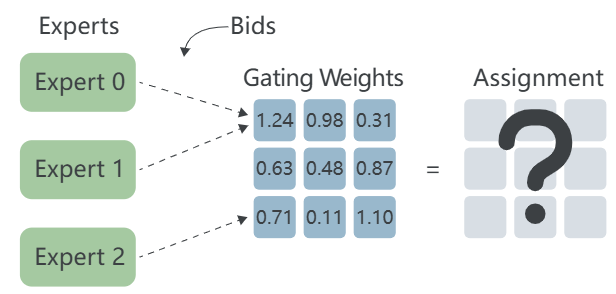
就像在真正的拍卖中一样,这样的冲突通过将token给予最高出价者来解决。每个专家的出价金额由该专家的最高和第二高门控权重之间的差值决定。在上面的示例中,专家0将为Token 0出价1.24−0.71=0.53,专家1将出价0.98−0.48=0.50,因此Token 0将被分配给专家0。
如果第一轮出价后有任何token尚未被分配(如示例中的Token 1),则执行后续轮次的出价,直到所有token都被分配。
哈希层
Roller, Stephen, Sainbayar Sukhbaatar和Jason Weston探索了使用哈希层在不需要任何可训练的门控权重或分配算法的情况下实现平衡路由。对于每个输入token,使用哈希函数将该token的ID(即token在模型词汇表中的索引)映射到可用专家之一。
例如,一个简单的哈希函数可能是
其中x是token ID,E是专家数量。这个函数将每个token ID映射到专家之一,并且映射是确定性的(即,同一个token ID总是被映射到同一个专家)。
num_experts = 8
input_sequence = "This is a hash layer example."
# 标记输入序列
input_ids = tokenizer.encode(input_sequence, return_tensors='pt')
print("Token ids:", input_ids)
# 使用`x % num_experts`将每个token映射到专家
expert_assignment = torch.fmod(input_ids, num_experts)
print("Expert assignment:", expert_assignment)
Token ids: tensor([[ 1212, 318, 257, 12234, 7679, 1672, 13]])
Expert assignment: tensor([[4, 6, 1, 2, 7, 0, 5]])
还探索了其他更复杂的哈希函数,例如通过对单独预训练的Transformer模型产生的token嵌入应用k-means聚类,或者根据训练数据中token频率预计算一个哈希表,将token ID映射到专家,从而确保token到专家的分配更加平衡。
总结
这次对混合专家模式及其在Transformer语言模型领域的应用的探讨,帮助我理解了许多实现MoE模型的细节和考虑因素。值得注意的是,这里没有涵盖一些重要主题(还有许多其他我可能不知道的主题):
-
MoE模型与它们的密集对应物的性能:我们看到了如何在不增加任何额外计算成本的情况下增加MoE模型的参数数量;然而,这并不一定意味着MoE模型的性能将与具有相同参数数量的密集模型相匹配。Clark, Aidan等人更详细地探讨了这个话题,并发现引入MoE路由通常可以提高语言建模任务的性能。然而,MoE模型通过微调适应下游任务的倾向尚不清楚。
-
MoE之外的稀疏性:混合专家模式并不是引入Transformer模型稀疏性的唯一方式。还实现了许多其他稀疏注意力机制、稀疏前馈网络和模型剪枝技术。我将这些主题的探索留待另一天。
如何系统学习掌握AI大模型?
AI大模型作为人工智能领域的重要技术突破,正成为推动各行各业创新和转型的关键力量。抓住AI大模型的风口,掌握AI大模型的知识和技能将变得越来越重要。
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份
全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2024行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

参考文献
[1] Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017).
[2] Narayanan, Deepak, et al. “Efficient large-scale language model training on gpu clusters using megatron-lm.” Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 2021.
[3] Korthikanti, Vijay Anand, et al. “Reducing activation recomputation in large transformer models.” Proceedings of Machine Learning and Systems 5 (2023).
[4] Hoffmann, Jordan, et al. “Training compute-optimal large language models.” arXiv preprint arXiv:2203.15556 (2022).
[5] R. A. Jacobs, M. I. Jordan, S. J. Nowlan and G. E. Hinton, “Adaptive Mixtures of Local Experts,” in Neural Computation, vol. 3, no. 1, pp. 79-87, March 1991, doi: 10.1162/neco.1991.3.1.79.
[6] Eigen, David, Marc’Aurelio Ranzato, and Ilya Sutskever. “Learning factored representations in a deep mixture of experts.” arXiv preprint arXiv:1312.4314 (2013).
[7] Shazeer, Noam, et al. “Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.” arXiv preprint arXiv:1701.06538 (2017).
[8] Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long Short-Term Memory. Neural Comput. 9, 8 (November 15, 1997), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
[9] Fedus, William, Barret Zoph, and Noam Shazeer. “Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.” The Journal of Machine Learning Research 23.1 (2022): 5232-5270.
[10] https://huggingface.co/docs/transformers/v4.32.0/en/model_doc/switch_transformers
[11] Lepikhin, Dmitry, et al. “Gshard: Scaling giant models with conditional computation and automatic sharding.” arXiv preprint arXiv:2006.16668 (2020).
[12] Lewis, Mike, et al. “Base layers: Simplifying training of large, sparse models.” International Conference on Machine Learning. PMLR, 2021.
[13] Bertsekas, D.P. Auction algorithms for network flow problems: A tutorial introduction. Comput Optim Applic 1, 7–66 (1992). https://doi.org/10.1007/BF00247653
[14] Roller, Stephen, Sainbayar Sukhbaatar, and Jason Weston. “Hash layers for large sparse models.” Advances in Neural Information Processing Systems 34 (2021): 17555-17566.
[15] Clark, Aidan, et al. “Unified scaling laws for routed language models.” International Conference on Machine Learning. PMLR, 2022.

















 724
724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









