










FuseMoE: Mixture-of-Experts Transformers for Fleximodal Fusion
NeurIPS Poster FuseMoE: Mixture-of-Experts Transformers for Fleximodal Fusion


As machine learning models in critical fields increasingly grapple with multimodal data, they face the dual challenges of handling a wide array of modalities, often incomplete due to missing elements, and the temporal irregularity and sparsity of collected samples. Successfully leveraging this complex data, while overcoming the scarcity of high-quality training samples, is key to improving these models' predictive performance. We introduce ``FuseMoE'', a mixture-of-experts framework incorporated with an innovative gating function. Designed to integrate a diverse number of modalities, FuseMoE is effective in managing scenarios with missing modalities and irregularly sampled data trajectories. Theoretically, our unique gating function contributes to enhanced convergence rates, leading to better performance in multiple downstream tasks. The practical utility of FuseMoE in the real world is validated by a diverse set of challenging prediction tasks.
随着关键领域中的机器学习模型越来越多地处理多模态数据,它们面临着双重挑战:处理种类繁多的模态(通常由于缺失元素而不完整),以及收集样本的时间不规则性和稀疏性。 成功利用这些复杂数据,同时克服高质量训练样本稀缺的问题,是提高这些模型预测性能的关键。我们引入了“FuseMoE”,一种结合创新门控函数的混合专家框架。 该框架旨在整合多种模态,能够有效应对缺失模态和不规则采样数据轨迹的场景。从理论上讲,我们独特的门控函数有助于提高收敛速度,从而在多个下游任务中表现更优。 FuseMoE 在现实世界中的实用性通过一系列具有挑战性的预测任务得到了验证。
Introduction
Multimodal fusion is a critical and extensively studied problem in many significant domains , such as sentiment analysis, image and video captioning, and medical prediction. Previous research has shown that embracing multimodality can improve predictive performance by capturing complementary information across modalities, outperforming single-modality approaches in similar tasks. However, an ongoing challenge lies in the creation of scalable frameworks for fusing multimodal data under a variety of conditions, and in creating reliable models that consistently surpass their single-modal counterparts.
Handling a variable number of input modalities remains an open challenge in multimodal fusion, due to challenges with scalability and lack of unified approaches for addressing missing modalities. Many existing multimodal fusion methods are designed for only two modalities, rely on costly pairwise comparisons between modalities, or employ simple concatenation approaches, rendering them unable to scale to settings with a large number of input modalities or adequately capture inter-modal interactions. Similarly, existing works are either unable to handle missing modalities entirely or use imputation approaches of varying sophistication. The former methods restrict usage to cases where all modalities are completely observed, significantly diminishing their utility in settings where this is often not the case (such as in clinical applications); the latter can lead to suboptimal performance due to the inherent limitations of imputed data. In addition, the complex and irregular temporal dynamics present in multimodal data have often been overlooked, with existing methods often ignoring irregularity entirely or relying on positional embedding schemes that may not be appropriate when modalities display a varying degree of temporal irregularity. Consequently, there is a pressing need for more advanced and scalable multimodal fusion techniques that can efficiently handle a broader set of modalities, effectively manage missing and irregular data, and capture the nuanced inter-modal relationships necessary for robust and accurate prediction.
We use the term FlexiModal Data to capture several of these key aspects, which haven’t been well-addressed by prior works:
“Flexi” suggests flexibility, indicating the possibility of having any combination of modalities, even with arbitrary missingness or irregularity.
FlexiModal data is most evident in clinical scenarios, where extensive monitoring results in the accumulation of comprehensive electronic health records (EHRs) for each patient. A typical EHR encompasses diverse data types, including tabular (e.g., age, demographics, gender), images (X-rays, magnetic resonance imaging, and photographs), clinical notes, physiological time series (ECG and EEG), and vital signs (blood chemistry, heart rate). In this setting, we observe a variety of modalities, sampled with varying irregularity and a high degree of missingness and sparsity.
Contributions
In this paper, we introduce a novel mixture-of-experts (MoE) framework, which we call FuseMoE, specifically designed to enhance the multimodal fusion of FlexiModal data. FuseMoE incorporates sparsely gated MoE layers in its fusion component, which are adept at managing distinct tasks and learning optimal modality partitioning. In addition, FuseMoE surpasses previous cross-attention-based methods in scalability, accommodating an unlimited array of input modalities. Furthermore, FuseMoE routes each modality to designated experts that specialize in those specific data types. This allows FuseMoE to effectively handle scenarios with missing modalities by dynamically adjusting the influence of experts primarily responsible for the absent data, while still utilizing the available modalities. Lastly, FuseMoE integrates a novel Laplace gating function, which is theoretically proven to ensure better convergence rates compared to traditional Softmax functions, thereby enhancing predictive performance. We have conducted comprehensive empirical evaluations of FuseMoE across a range of application scenarios to validate its effectiveness.
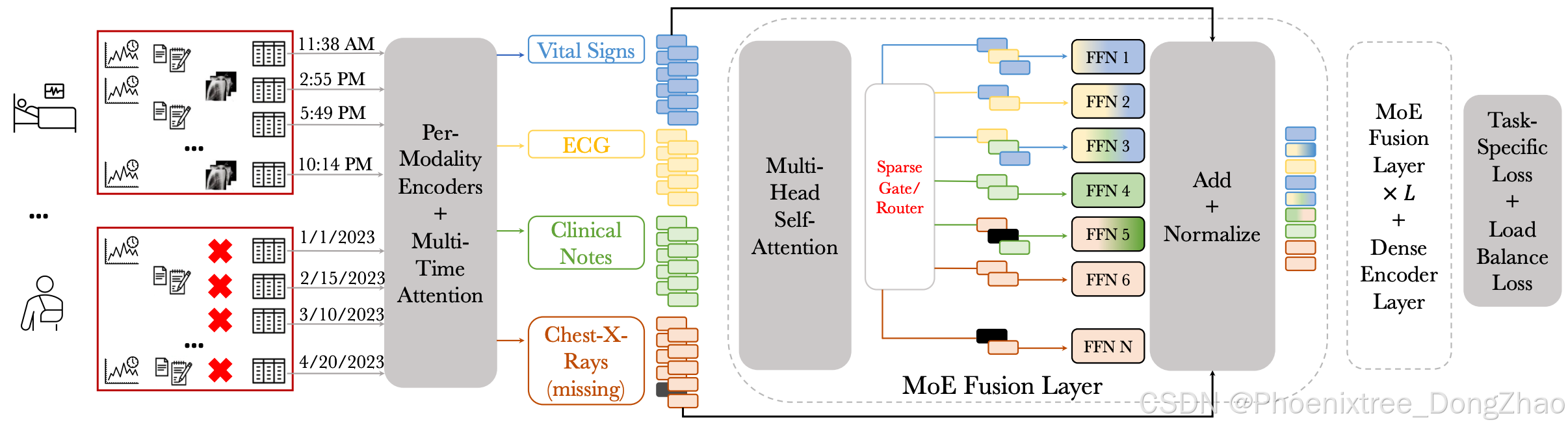
Figure 1: An example of addressing the challenge of FlexiModal Data: patients in ICUs often have extensive and irregular health status measurements over time; patients with milder conditions only require monitoring across fewer categories. FuseMoE is adept at handling inputs featuring any combination of modalities, including those with missing elements. It starts by encoding inputs using modality-specific feature extractors, followed by employing a multi-time attention mechanism [Shukla and Marlin, 2021] to address temporal irregularities. The core of FuseMoE lies the MoE Fusion Layer, where a routing mechanism is trained to categorize multimodal inputs and direct them to the appropriate combinations of MLPs. The outputs from these MLPs are weighted through a gating function, resulting in fused embeddings, which are subsequently utilized for further processing.
引言
多模态融合是许多重要领域中一个关键且广泛研究的问题,例如情感分析、图像和视频字幕生成以及医学预测。先前的研究表明,采用多模态可以捕获跨模态的互补信息,从而在类似任务中优于单模态方法。然而,如何在各种条件下创建可扩展的多模态数据融合框架,并构建始终超越单模态模型的可靠模型,仍然是一个持续的挑战。
处理可变数量的输入模态仍然是多模态融合中的一个开放性问题,主要受到可扩展性挑战和缺乏统一方法来解决模态缺失的限制。 许多现有的多模态融合方法仅设计用于两种模态,依赖于昂贵的模态间成对比较,或采用简单的拼接方法,导致它们无法扩展到大量输入模态的场景,也无法充分捕捉模态间的交互。同样,现有工作要么完全无法处理缺失模态,要么使用不同程度复杂的插补方法。前者将使用限制在所有模态均完全观察到的情况下,显著降低了其在实际场景(如临床应用)中的实用性;后者由于插补数据的固有限制可能导致次优性能。此外,多模态数据中存在的复杂且不规则的时间动态往往被忽视,现有方法通常完全忽略不规则性,或依赖可能不适合不同模态时间不规则性程度的位置嵌入方案。因此,迫切需要更先进且可扩展的多模态融合技术,能够高效处理更广泛的模态,有效管理缺失和不规则数据,并捕捉实现稳健和准确预测所需的细微模态间关系。
我们使用术语“FlexiModal 数据”来描述这些关键方面,而这些问题尚未被先前的工作很好地解决:
- “Flexi”表示灵活性,意味着可以包含任意组合的模态,即使存在任意的缺失或不规则性。
- FlexiModal 数据在临床场景中最为明显,其中广泛的监测导致每位患者积累了全面的电子健康记录 (EHR)。 典型的 EHR 包含多种数据类型,包括表格数据(如年龄、人口统计、性别)、图像(X 射线、磁共振成像和照片)、临床笔记、生理时间序列(心电图和脑电图)以及生命体征(血液化学、心率)。在这种场景中,我们观察到多种模态,采样具有不同的不规则性,并且存在高度的缺失和稀疏性。
贡献
在本文中,我们提出了一种新颖的混合专家 (MoE) 框架,称为 FuseMoE,专门设计用于增强 FlexiModal 数据的多模态融合。 FuseMoE 在其融合组件中采用了稀疏门控 MoE 层,擅长处理不同任务并学习最优的模态划分。此外,FuseMoE 在可扩展性方面超越了以前基于交叉注意力的方法,能够容纳无限数量的输入模态。 此外,FuseMoE 将每个模态路由到专门处理特定数据类型的专家模块。这使得 FuseMoE 能够通过动态调整负责缺失数据的主要专家的影响,同时仍然利用可用模态,从而有效应对缺失模态的场景。最后,FuseMoE 集成了一个新的拉普拉斯门控函数,理论证明其相比传统 Softmax 函数能够确保更好的收敛速度,从而提升预测性能。 我们在一系列应用场景中对 FuseMoE 进行了全面的实证评估,以验证其有效性。
总结
本文的核心思想在于提出了一种名为 FuseMoE 的混合专家框架,旨在解决多模态数据融合中的关键挑战,特别是处理缺失模态、不规则采样和稀疏数据的能力。以下是本文的主要贡献和创新点:
-
问题定义的清晰性 :
作者明确指出了当前多模态融合领域的核心问题,包括模态数量的可扩展性、缺失模态的处理以及时间动态的不规则性。 这些问题在临床等实际场景中尤为突出。 -
方法的创新性 :
- Sparse Gating Mechanism :通过稀疏门控机制实现对不同模态的动态路由,确保模型能够高效处理任意数量的模态。
- Laplace Gating Function :引入了一种新颖的拉普拉斯门控函数,理论证明其比传统 Softmax 更具收敛优势,从而提升了预测性能。
-
应用的广泛性 :
FuseMoE 在多个实际场景中进行了验证,展示了其在处理复杂多模态数据时的优越性和鲁棒性。

















 121
121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









