






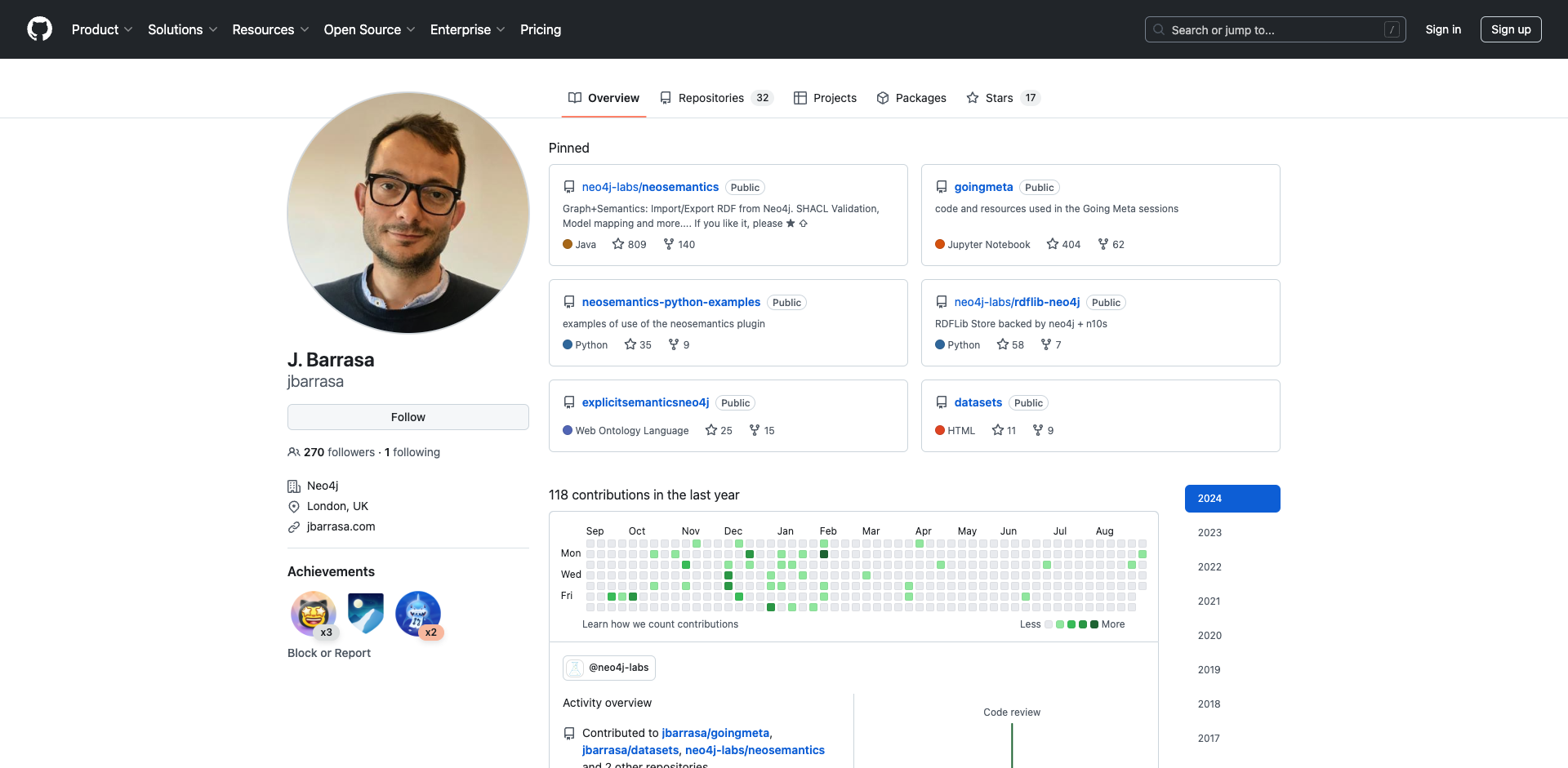
Going Meta 项目概述
Going Meta 是一个由 J. Barrasa 创建和维护的开源项目,致力于探索和分享知识图谱、语义技术和图数据科学领域的前沿内容。该项目通过每月一次的直播会话,为开发者和研究人员提供了一个学习和交流的平台。
项目背景和宗旨
在当今数据驱动的世界中,如何有效地组织、连接和利用海量信息成为了一个关键挑战。知识图谱作为一种强大的数据表示和推理工具,正在各个领域发挥着越来越重要的作用。Going Meta 项目正是在这样的背景下应运而生,旨在推动知识图谱和相关技术的发展与应用。
项目创始人 J. Barrasa 是这一领域的资深专家,他希望通过 Going Meta 搭建一个开放的平台,让更多人能够接触到最新的技术和实践。正如项目名称所暗示的那样,"Going Meta"意味着超越表面,深入探索数据背后的结构和语义。
项目特色和运作方式
Going Meta 最显著的特色是其定期举办的直播会话。这些会话通常在每月的第一个星期二举行,时间为英国标准时间下午 4 点(北京时间晚上 11 点)。会话通过 Twitch 和 YouTube Live 进行直播,确保全球各地的观众都能方便地参与其中。

每次会话都会聚焦于一个特定的主题,涵盖了从基础概念到高级应用的广泛内容。会话中不仅有理论讲解,还包括大量的实践演示,让参与者能够直观地理解和掌握相关技术。所有会话的资源,包括代码、数据集和演示文稿,都会在 GitHub 上的 Going Meta 仓库中公开分享。这种开放的态度极大地促进了知识的传播和社区的参与。
核心技术和主题
Going Meta 项目涵盖了知识图谱和语义技术领域的多个关键主题,以下是一些核心技术和主题的概述:
1. 图数据库和查询语言
-
Neo4j 和 Cypher: Neo4j 是一个广泛使用的图数据库,而 Cypher 是其专用的查询语言。多个会话探讨了如何使用 Cypher 进行高效的图查询和分析。
-
SPARQL: 作为 RDF 数据的标准查询语言,SPARQL 在语义网技术中扮演着重要角色。项目中介绍了 SPARQL 的基本用法和高级技巧。
2. 知识表示和推理
-
RDF 和 OWL: 资源描述框架(RDF)和 Web 本体语言(OWL)是语义网的基础。Going Meta 深入讲解了如何使用这些技术来表示和推理复杂的知识。
-
本体工程: 多个会话专注于如何设计和应用本体,以及如何使用 Protégé 等工具进行本体开发。
3. 数据集成和迁移
-
RDF 集成模式: 项目探讨了将不同来源的数据集成到 RDF 知识图谱中的常见模式和最佳实践。
-
从三元存储到图数据库的迁移: 介绍了如何将 RDF 三元存储中的数据无缝迁移到 Neo4j 等图数据库中。
4. 语义搜索和相似度计算
-
向量嵌入: 讨论了如何使用向量嵌入技术来增强语义搜索的能力。
-
本体驱动的搜索: 展示了如何利用本体知识来改进搜索结果的相关性和准确性。
5. 自然语言处理与生成
-
从知识图谱生成自然语言: 通过注释本体来实现从结构化数据到自然语言描述的自动生成。
-
NLTK 应用: 使用自然语言工具包(NLTK)进行语义相似度计算和文本分析。
6. 机器学习与图算法
-
图算法应用: 探讨了如何将经典的图算法应用于知识图谱分析。
-
本体学习: 介绍了从图数据中自动学习本体结构的技术。
7. 大型语言模型(LLM)与知识图谱
-
检索增强生成(RAG): 结合知识图谱和 LLM 实现更精准的信息检索和生成。
-
LLM 辅助知识图谱构建: 探索使用 LLM 来自动化知识图谱的构建过程。
技术实践与应用案例
Going Meta 项目不仅关注理论,更注重实际应用。以下是一些典型的技术实践和应用案例:
1. 语义数据应用开发
在第 15 次会话中,项目展示了如何使用 Streamlit 构建语义数据应用。这个案例完美地展示了如何将本体知识与现代 Web 应用开发技术相结合,为用户提供直观的数据交互界面。
import streamlit as st
import rdflib
# 加载本体和数据
g = rdflib.Graph()
g.parse("ontology.ttl", format="turtle")
# Streamlit 界面
st.title("语义数据浏览器")
# 用户交互逻辑
selected_class = st.selectbox("选择一个类:", [str(c) for c in g.subjects(rdflib.RDF.type, rdflib.OWL.Class)])
instances = g.subjects(rdflib.RDF.type, rdflib.URIRef(selected_class))
for instance in instances:
st.write(f"- {instance}")
2. 知识图谱增强的问答系统
第 22 和 23 次会话深入探讨了如何将知识图谱与检索增强生成(RAG)技术结合,以构建更智能的问答系统。这种方法不仅提高了回答的准确性,还能提供更丰富的上下文信息。
from langchain import OpenAI, GraphDatabase
from langchain.chains import GraphQAChain
# 初始化 Neo4j 连接和 OpenAI
graph = GraphDatabase("bolt://localhost:7687", ("neo4j", "password"))
llm = OpenAI(temperature=0)
# 创建 GraphQAChain
chain = GraphQAChain.from_llm(llm, graph=graph, verbose=True)
# 用户查询
query = "谁是莎士比亚最著名的悲剧角色?"
result = chain.run(query)
print(result)
3. 本体版本控制
第 19 次会话介绍了如何在 Neo4j 中实现本体的版本控制。这对于管理复杂的、不断演化的知识模型至关重要,特别是在大型协作项目中。
// 创建新版本的本体
MATCH (o:Ontology {name: 'MyOntology', version: 'v1.0'})
CREATE (newO:Ontology {name: 'MyOntology', version: 'v1.1'})
WITH o, newO
MATCH (o)-[:CONTAINS]->(c:Class)
CREATE (newO)-[:CONTAINS]->(newC:Class)
SET newC = c
RETURN newO, count(newC) as classesCopied
4. 语义相似度计算
第 16 次会话探讨了如何在分类法中计算语义相似度。这种技术在推荐系统、信息检索等多个领域都有重要应用。
from nltk.corpus import wordnet as wn
def semantic_similarity(word1, word2):
synsets1 = wn.synsets(word1)
synsets2 = wn.synsets(word2)
max_sim = 0
for s1 in synsets1:
for s2 in synsets2:
sim = s1.path_similarity(s2)
if sim and sim > max_sim:
max_sim = sim
return max_sim
# 使用示例
similarity = semantic_similarity("cat", "dog")
print(f"'cat' 和 'dog' 的语义相似度: {similarity}")
项目影响和社区贡献
自 2022 年初启动以来,Going Meta 项目已经产生了显著的影响,并吸引了一个活跃的社区。
社区规模和参与度
- GitHub 仓库已获得超过 400 个星标,表明了项目的受欢迎程度。
- 62 次 fork 显示了许多开发者正在基于该项目进行自己的探索和开发。
- 37 个 watching 用户时刻关注着项目的最新动态。

技术贡献
Going Meta 项目不仅分享知识,还通过实际的代码和工具对社区做出了贡献:
-
代码示例库: 项目仓库包含了大量可直接使用的代码示例,涵盖了从基础查询到复杂应用的各个方面。
-
工具集成示例: 展示了如何将不同的工具和技术(如 Neo4j、RDFLib、NLTK 等)整合在一起,为开发者提供了实用的参考。
-
最佳实践指南: 通过会话和文档,项目总结并分享了知识图谱和语义技术领域的最佳实践。
教育价值
Going Meta 的一个重要贡献是其教育价值:
- 入门指南: 对于刚接触知识图谱和语义技术的人来说,这些会话提供了很好的入门指导。
- 深度探讨: 对于有经验的开发者,项目也提供了深入探讨高级主题的机会。
- 实践导向: 通过大量的实践案例,帮助学习者将理论知识转化为实际技能。
跨领域合作
项目还促进了不同领域间的合作:
- 学术界和工业界的桥梁: Going Meta 的内容既有学术深度,又注重实际应用,为学术研究和工业实践之间搭建了桥梁。
- 技术融合: 通过探讨如何将知识图谱与其他技术(如机器学习、自然语言处理)结合,推动了技术的融合创新。
未来展望
Looking Meta 项目的未来充满了机遇和挑战。以下是一些可能的发展方向:
-
深化 LLM 与知识图谱的结合: 随着大型语言模型的快速发展,探索如何更好地将 LLM 与知识图谱结合,可能会成为项目的重要方向。
-
扩展到更多领域: 虽然项目目前主要关注技术层面,但未来可能会更多地探讨知识图谱在特定领域(如生物医学、金融、法律等)的应用。
-
工具和框架开发: 基于项目积累的经验,可能会开发一些专门的工具或框架,以简化知识图谱的构建和应用过程。
-
社区驱动的内容创作: 随着社区的成长,可以预见会有更多的社区成员参与到内容的创作和分享中来,使项目的覆盖面更广,内容更加丰富。
-
国际化和本地化: 考虑到全球范围内对这些技术的需求,项目可能会着手进行更广泛的国际化,包括多语言支持和针对不同地区的本地化内容。
总的来说,Going Meta 项目展现了知识图谱和语义技术的巨大潜力。通过持续的探索和分享,它正在推动这个领域的发展,并为构建更智能、更互联的信息系统贡献力量。无论你是初学者还是专家,Going Meta 都为你提供了一个宝贵的学习和交流平台。加入这个充满活力的社区,一起探索数据的未来吧!
项目链接:
Going Meta 项目概述Going
Going Meta 是一个由 J. Barrasa 创建和维护的开源项目,致力于探索和分享知识图谱、语义技术和图数据科学领域的前沿内容。该项目通过每月一次的直播会话,为开发者和研究人员提供了一个学习和交流的平台。
项目背景和宗旨
在当今数据驱动的世界中,如何有效地组织、连接和利用海量信息成为了一个关键挑战。知识图谱作为一种强大的数据表示和推理工具,正在各个领域发挥着越来越重要的作用。Going Meta 项目正是在这样的背景下应运而生,旨在推动知识图谱和相关技术的发展与应用。
项目创始人 J. Barrasa 是这一领域的资深专家,他希望通过 Going Meta 搭建一个开放的平台,让更多人能够接触到最新的技术和实践。正如项目名称所暗示的那样,"Going Meta"意味着超越表面,深入探索数据背后的结构和语义。
项目特色和运作方式
Going Meta 最显著的特色是其定期举办的直播会话。这些会话通常在每月的第一个星期二举行,时间为英国标准时间下午 4 点(北京时间晚上 11 点)。会话通过 Twitch 和 YouTube Live 进行直播,确保全球各地的观众都能方便地参与其中。
每次会话都会聚焦于一个特定的主题,涵盖了从基础概念到高级应用的广泛内容。会话中不仅有理论讲解,还包括大量的实践演示,让参与者能够直观地理解和掌握相关技术。所有会话的资源,包括代码、数据集和演示文稿,都会在 GitHub 上的 Going Meta 仓库中公开分享。这种开放的态度极大地促进了知识的传播和社区的参与。
核心技术和主题
Going Meta 项目涵盖了知识图谱和语义技术领域的多个关键主题,以下是一些核心技术和主题的概述:
1. 图数据库和查询语言
-
Neo4j 和 Cypher: Neo4j 是一个广泛使用的图数据库,而 Cypher 是其专用的查询语言。多个会话探讨了如何使用 Cypher 进行高效的图查询和分析。
-
SPARQL: 作为 RDF 数据的标准查询语言,SPARQL 在语义网技术中扮演着重要角色。项目中介绍了 SPARQL 的基本用法和高级技巧。
2. 知识表示和推理
-
RDF 和 OWL: 资源描述框架(RDF)和 Web 本体语言(OWL)是语义网的基础。Going Meta 深入讲解了如何使用这些技术来表示和推理复杂的知识。
-
本体工程: 多个会话专注于如何设计和应用本体,以及如何使用 Protégé 等工具进行本体开发。
3. 数据集成和迁移
-
RDF 集成模式: 项目探讨了将不同来源的数据集成到 RDF 知识图谱中的常见模式和最佳实践。
-
从三元存储到图数据库的迁移: 介绍了如何将 RDF 三元存储中的数据无缝迁移到 Neo4j 等图数据库中。
4. 语义搜索和相似度计算
-
向量嵌入: 讨论了如何使用向量嵌入技术来增强语义搜索的能力。
-
本体驱动的搜索: 展示了如何利用本体知识来改进搜索结果的相关性和准确性。
5. 自然语言处理与生成
-
从知识图谱生成自然语言: 通过注释本体来实现从结构化数据到自然语言描述的自动生成。
-
NLTK 应用: 使用自然语言工具包(NLTK)进行语义相似度计算和文本分析。
6. 机器学习与图算法
-
图算法应用: 探讨了如何将经典的图算法应用于知识图谱分析。
-
本体学习: 介绍了从图数据中自动学习本体结构的技术。
7. 大型语言模型(LLM)与知识图谱
-
检索增强生成(RAG): 结合知识图谱和 LLM 实现更精准的信息检索和生成。
-
LLM 辅助知识图谱构建: 探索使用 LLM 来自动化知识图谱的构建过程。
技术实践与应用案例
Going Meta 项目不仅关注理论,更注重实际应用。以下是一些典型的技术实践和应用案例:
1. 语义数据应用开发
在第 15 次会话中,项目展示了如何使用 Streamlit 构建语义数据应用。这个案例完美地展示了如何将本体知识与现代 Web 应用开发技术相结合,为用户提供直观的数据交互界面。
import streamlit as st
import rdflib
# 加载本体和数据
g = rdflib.Graph()
g.parse("ontology.ttl", format="turtle")
# Streamlit 界面
st.title("语义数据浏览器")
# 用户交互逻辑
selected_class = st.selectbox("选择一个类:", [str(c) for c in g.subjects(rdflib.RDF.type, rdflib.OWL.Class)])
instances = g.subjects(rdflib.RDF.type, rdflib.URIRef(selected_class))
for instance in instances:
st.write(f"- {instance}")
2. 知识图谱增强的问答系统
第 22 和 23 次会话深入探讨了如何将知识图谱与检索增强生成(RAG)技术结合,以构建更智能的问答系统。这种方法不仅提高了回答的准确性,还能提供更丰富的上下文信息。
from langchain import OpenAI, GraphDatabase
from langchain.chains import GraphQAChain
# 初始化 Neo4j 连接和 OpenAI
graph = GraphDatabase("bolt://localhost:7687", ("neo4j", "password"))
llm = OpenAI(temperature=0)
# 创建 GraphQAChain
chain = GraphQAChain.from_llm(llm, graph=graph, verbose=True)
# 用户查询
query = "谁是莎士比亚最著名的悲剧角色?"
result = chain.run(query)
print(result)
3. 本体版本控制
第 19 次会话介绍了如何在 Neo4j 中实现本体的版本控制。这对于管理复杂的、不断演化的知识模型至关重要,特别是在大型协作项目中。
// 创建新版本的本体
MATCH (o:Ontology {name: 'MyOntology', version: 'v1.0'})
CREATE (newO:Ontology {name: 'MyOntology', version: 'v1.1'})
WITH o, newO
MATCH (o)-[:CONTAINS]->(c:Class)
CREATE (newO)-[:CONTAINS]->(newC:Class)
SET newC = c
RETURN newO, count(newC) as classesCopied
4. 语义相似度计算
第 16 次会话探讨了如何在分类法中计算语义相似度。这种技术在推荐系统、信息检索等多个领域都有重要应用。
from nltk.corpus import wordnet as wn
def semantic_similarity(word1, word2):
synsets1 = wn.synsets(word1)
synsets2 = wn.synsets(word2)
max_sim = 0
for s1 in synsets1:
for s2 in synsets2:
sim = s1.path_similarity(s2)
if sim and sim > max_sim:
max_sim = sim
return max_sim
# 使用示例
similarity = semantic_similarity("cat", "dog")
print(f"'cat' 和 'dog' 的语义相似度: {similarity}")
项目影响和社区贡献
自 2022 年初启动以来,Going Meta 项目已经产生了显著的影响,并吸引了一个活跃的社区。
社区规模和参与度
- GitHub 仓库已获得超过 400 个星标,表明了项目的受欢迎程度。
- 62 次 fork 显示了许多开发者正在基于该项目进行自己的探索和开发。
- 37 个 watching 用户时刻关注着项目的最新动态。
技术贡献
Going Meta 项目不仅分享知识,还通过实际的代码和工具对社区做出了贡献:
-
代码示例库: 项目仓库包含了大量可直接使用的代码示例,涵盖了从基础查询到复杂应用的各个方面。
-
工具集成示例: 展示了如何将不同的工具和技术(如 Neo4j、RDFLib、NLTK 等)整合在一起,为开发者提供了实用的参考。
-
最佳实践指南: 通过会话和文档,项目总结并分享了知识图谱和语义技术领域的最佳实践。
教育价值
Going Meta 的一个重要贡献是其教育价值:
- 入门指南: 对于刚接触知识图谱和语义技术的人来说,这些会话提供了很好的入门指导。
- 深度探讨: 对于有经验的开发者,项目也提供了深入探讨高级主题的机会。
- 实践导向: 通过大量的实践案例,帮助学习者将理论知识转化为实际技能。
跨领域合作
项目还促进了不同领域间的合作:
- 学术界和工业界的桥梁: Going Meta 的内容既有学术深度,又注重实际应用,为学术研究和工业实践之间搭建了桥梁。
- 技术融合: 通过探讨如何将知识图谱与其他技术(如机器学习、自然语言处理)结合,推动了技术的融合创新。
未来展望
Looking Meta 项目的未来充满了机遇和挑战。以下是一些可能的发展方向:
-
深化 LLM 与知识图谱的结合: 随着大型语言模型的快速发展,探索如何更好地将 LLM 与知识图谱结合,可能会成为项目的重要方向。
-
扩展到更多领域: 虽然项目目前主要关注技术层面,但未来可能会更多地探讨知识图谱在特定领域(如生物医学、金融、法律等)的应用。
-
工具和框架开发: 基于项目积累的经验,可能会开发一些专门的工具或框架,以简化知识图谱的构建和应用过程。
-
社区驱动的内容创作: 随着社区的成长,可以预见会有更多的社区成员参与到内容的创作和分享中来,使项目的覆盖面更广,内容更加丰富。
-
国际化和本地化: 考虑到全球范围内对这些技术的需求,项目可能会着手进行更广泛的国际化,包括多语言支持和针对不同地区的本地化内容。
总的来说,Going Meta 项目展现了知识图谱和语义技术的巨大潜力。通过持续的探索和分享,它正在推动这个领域的发展,并为构建更智能、更互联的信息系统贡献力量。无论你是初学者还是专家,Going Meta 都为你提供了一个宝贵的学习和交流平台。加入这个充满活力的社区,一起探索数据的未来吧!
文章链接:www.dongaigc.com/a/going-meta-exploring-knowledge-graphs
https://www.dongaigc.com/a/going-meta-exploring-knowledge-graphs















 685
685

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









