






想到三个点:①运用字典的对应关系,找到所需要的序列(将原来的cds文件里的基因名和序列转为字典的key:value,然后编写代码)②下载并使用脚本(难点:怎么运行脚本)③运用列表的索引关系
① 字典:(前面都是正确对应的,多了一个不知道为啥。。。)
import os
os.chdir('D:\生信题')
f0 = open('yinwen.txt','w')
f1 = open('Pdan_new.cds','r')
f2 = open('gene_name.txt','r')
dict1 = {}
list2 = list(f2)
for line in f1:
if line.startswith('>'):
name = line
dict1[name] = ''
else:
dict1[name] += line.replace('\r\n','')
for each in list2:
for key in dict1.keys():
if each in key:
f0.write(key)
f0.write(dict1[key] + '\n')
break
f0.close()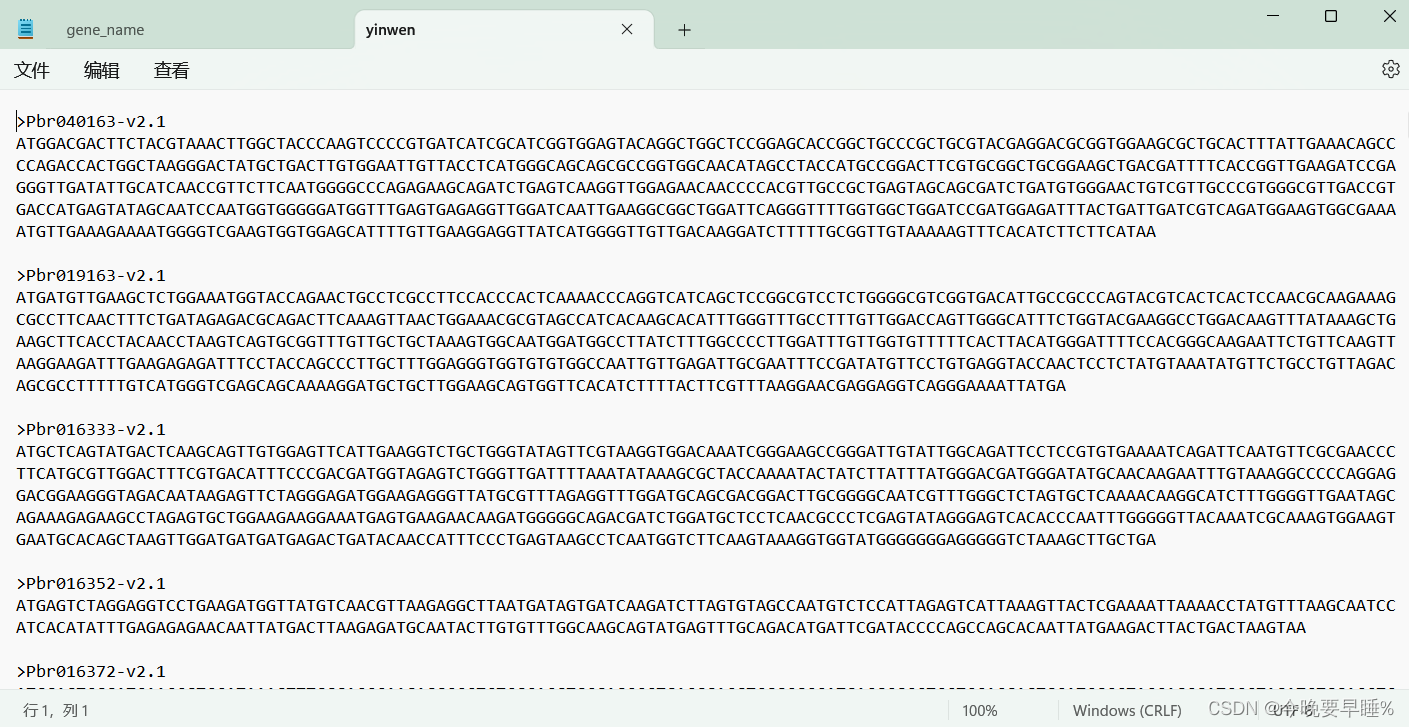
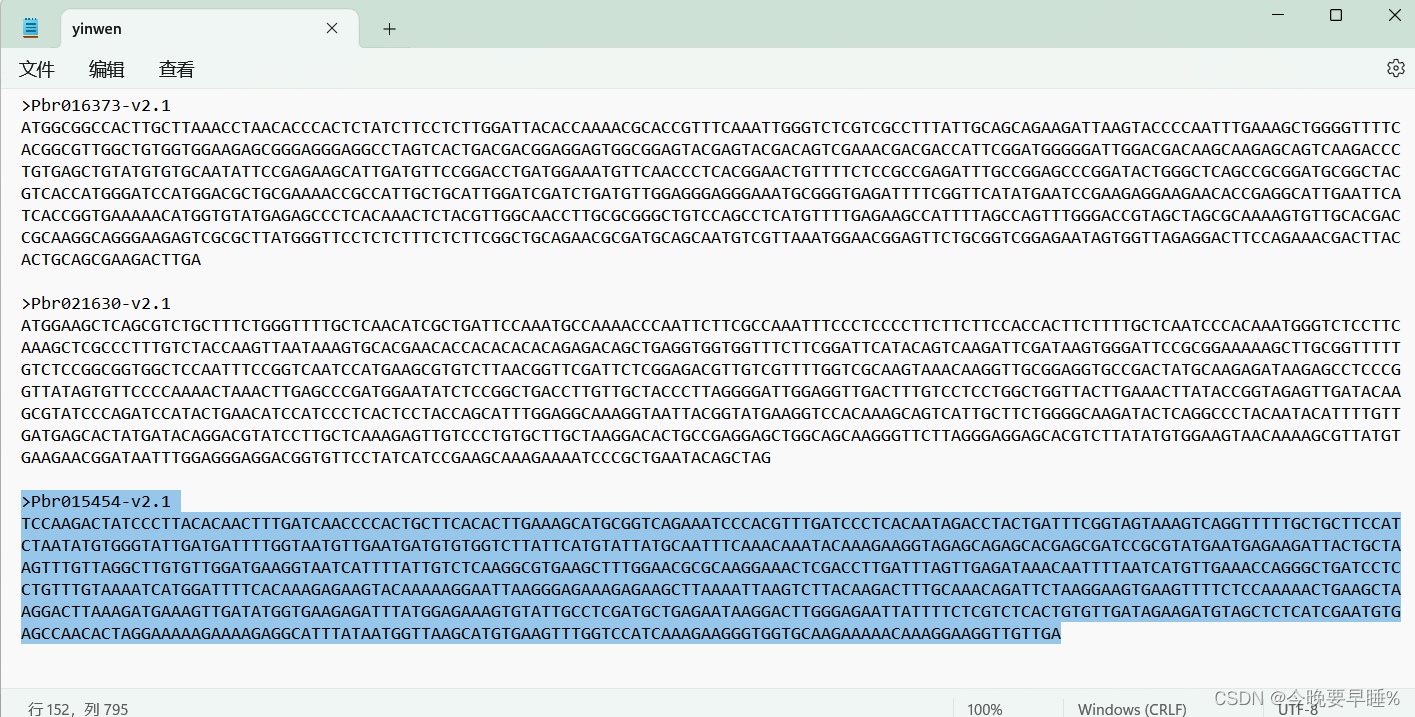
思考:好像多读的是基因组库中的第一个。。。/(ㄒoㄒ)/~~存疑。
import os
os.chdir('D:\生信题')
f1 = open('Pdan_new.cds')
f2 = open('gene_name.txt')
list1 = []
list2 =list(f2)
for line in f1:
if line.startswith('>'):
name = line[1:]
list1.append(name)
else:
value = line
list1.append(value)
for each1 in list1:
for each2 in list2:
if each1 == each2:
address =list1.index(each1)
print(list1[address])
print(list1[address+1])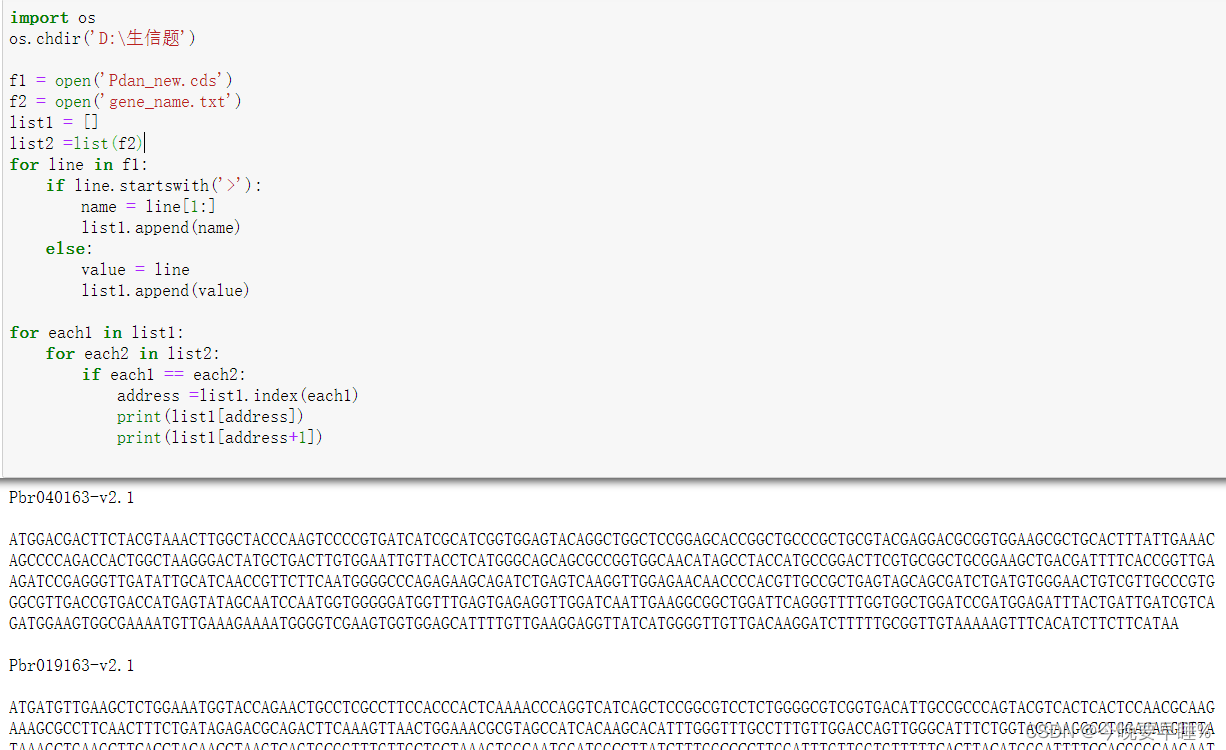
③ 脚本
下载了不会用,以后再说。。。















 1940
1940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









