






归因方法也叫特征重要性方法,旨在计算每个输入变量对模型输出的贡献,以便挖掘出对模型起重要贡献的特征。特征归因广泛应用于计算机视觉,生物信息学等领域,在机器学习方法(例如随机森林,XGBoost)中,大多采用基于SHAP值的特征重要性筛选,但是在深度学习这样的黑匣子模型中往往存在很多限制。下面重点介绍几种归因方法。
在理解深度模型特征归因之前,要先了解深度学习归因的定义(此处参考帖子【1】)
1. 归因的定义
人类做归因通常是依赖于反事实直觉。当人类将某些责任归因到一个原因上,隐含地会将缺失该原因的情况作为比较的基线(baseline)。例如,想睡觉的原因是困了,那么不困的时候就不想睡觉。
基于人类归因的原理,深度网络归因也需要一个基线(baseline)输入来模拟原因缺失的情况。在许多深度网络中,输入空间天然存在着一个baseline。例如,在目标识别网络中,纯黑图像就是一个基线。因此,深度网络归因的正式定义为:
假设一个目标函数F:Rn→[0,1]表示一个神经网络,它接受 n 维输入向量 x,并输出一个值(可以是分类概率或其他指标)。该网络的输入向量是x=(x1,x2,…,xn)∈Rn,基线输入为x′∈Rn代表归因分析的参考点,归因分析的目标是计算 当前输入 x 相较于基线 x′ 的贡献,用一个 归因向量 AF(x,x′)=(a1,a2,…,an)∈Rn表示,其中 ai 代表 输入特征 xi 对最终输出 F(x) 的贡献。
解读:当时看到这段话时一直理解不了基线。现在感觉基线就是一个起点,对比这个起点,来看当前模型输入对输出的贡献。比如NLP 任务中,基线可能是全零的词向量(即没有信息的输入);计算机视觉任务中,可能是全黑或全白的图像;其他任务中,可能是均值填充的数据。
下面是一个具体的例子:
假设你在训练一个房价预测模型 F(x),输入 x代表 房子的面积、房龄、地理位置,输出 F(x)代表房价。
如果我们选择基线输入 x′ 代表 一栋 0 平米、房龄 0 年、位置为空的房子,那么:
- a1 代表 房子的面积 对预测房价的贡献。
- a2 代表 房龄 的贡献。
- a3代表 地理位置 的贡献。
如果我们换一个基线,比如选择 市场均价房(平均面积、平均房龄、平均地理位置) 作为基线 x′,那么归因结果就会有所不同。
2. 基于梯度的归因
集成梯度 (Integrated Gradients, IG)
假设我们有一个深度网络的正式表示,F: Rn → [0, 1]。设x ∈ Rn为当前输入,x′ ∈ Rn为基线输入。从基线x′到输入x,对实数空间Rn中的所有点计算梯度。通过累积这些梯度,可以生成积分梯度。积分梯度被定义为从基线x′到输入x的直接路径上梯度的路径积分。此方法满足Sensitivity和Implementation Invariance(这两个性质的理解见帖子【1】)。这个公式的核心思想是:如果一个特征 xi 变化时,对模型输出 F(x) 影响很大,那么它的 IG 也会很大。在实际计算中,我们无法直接计算积分,所以通过从基线到x采样多个点(通过α调整输入),这样就能在整个路径上累积梯度变化。此外,IG看的是输入 x 的变化如何影响模型输出的梯度,而不是直接看预测概率与真实标签的差距。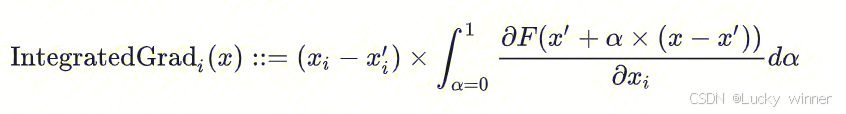
解读:当时看到这段话时又理解不了什么是路径了(难道是隐藏层的神经网络吗),以及为啥要对α求积分。后面理解的是路径指的是 输入特征从基线 x′ 逐渐变化到真实输入 x 的连续过程,用一个参数 α∈[0,1] 来控制,x(α)=x′+α(x−x′)。这个连续的过程就叫做路径,沿着这条路径计算当前x(α)的梯度,并累积贡献。
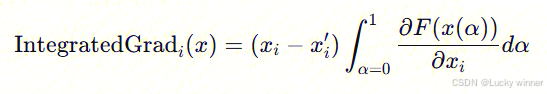
因此,普通梯度只考虑单个输入点 x 的瞬时变化率,但神经网络的梯度是 非线性变化的,所以不能直接用单个梯度值。集成梯度沿着整个路径计算平均梯度,这样可以更准确地衡量 xi 这个特征对输出 F(x) 的贡献。
举个小例子也就是:比如基线的输入是0,模型真实输入为3,那么集成梯度会计算 从 0 变化到 3 的过程中,求得每个时刻模型输出对此时输入的梯度,并对这些梯度求积分,来衡量 输入 3 对模型预测结果的贡献。
----------------------参考:
【1】【深度学习】【可解释性】深度网络的公理归因(Axiomatic Attribution for Deep Networks) - 知乎

















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









