






YOLO实现了统一网络。因此YOLO的优势在于不需要RPN网络。
1. YOLO v1
YOLO实现了统一网络。尽管Faster R-CNN中实现了RPN网络和Fast RCNN共享卷积层,但在模型训练中需要反复训练RPN和Fast R-CNN。相对于Faster R-CNN中,先生成Region Proposal再放入Fast R-CNN的两步走战略,YOLO只需要一步。YOLO将网络统一为一个回归问题。
- 核心思想:将整张图片作为网络的输入,并直接在输出层对bounding box的位置和分类进行回归。
1.1 全部流程
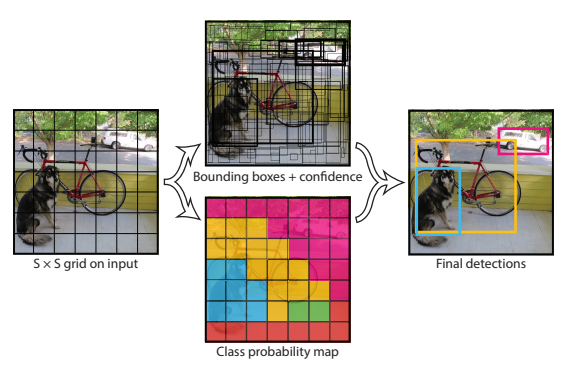
1.1.1 分割
将一幅图像分割为 S × S S \times S S×S的单元格grid cell。如果某个object的中心落在这个单元格中,则这个单元格就负责预测这个物体。
1.1.2 每个单元格预测bbox
每个单元格预测两个bbox的location(四个参数)和confidence。如果单元格负责预测前景,则置信度等于IoU;如果单元格是背景,则confidence=0。
bbox的位置预测是(x, y, w, h), x和y代表相对于每个单元格左上角坐标点的偏移,w, h表示相对于整张图宽和高的比例。因此理论上,四个值都在[0, 1]之间
- 以PASCAL VOC数据集为例(分割为 7 ∗ 7 7*7 7∗7个单元格,每个单元格预测两个bbox)
1.1.3 NMS过滤
最后输出的是 7 ∗ 7 ∗ 30 7*7*30 7∗7∗30,代表一共49个grid cell,每个cell拥有30个值( 2 ∗ 4 + 2 ∗ 1 + 20 2*4+2*1+20 2∗4+2∗1+20)
P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I o U = P r ( C l a s s i ) ∗ I o U Pr(Class_{i} | Object) * Pr(Object) * IoU = Pr(Class_{i}) * IoU Pr(Classi∣Object)∗Pr(Object)∗IoU=Pr(Classi)∗IoU
- 公式的含义为:物体是前景的情况下为类别 i i i的概率 ∗ * ∗ 1(是前景) ∗ * ∗ IoU,以这个结果作为单元格中置信度高的bbox的class-specific confidence score。之后设置阈值,先过滤掉得分低的box,对剩下的boxes进行NMS过滤,最终得到结果。
1.2 损失函数

原文中对于误差的计算采用误差平方和
∑
(
X
p
r
e
d
−
X
G
T
)
2
\sum{(X_{pred} - X_{GT})^{2}}
∑(Xpred−XGT)2
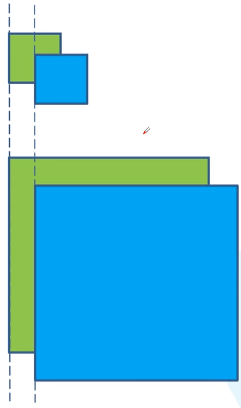
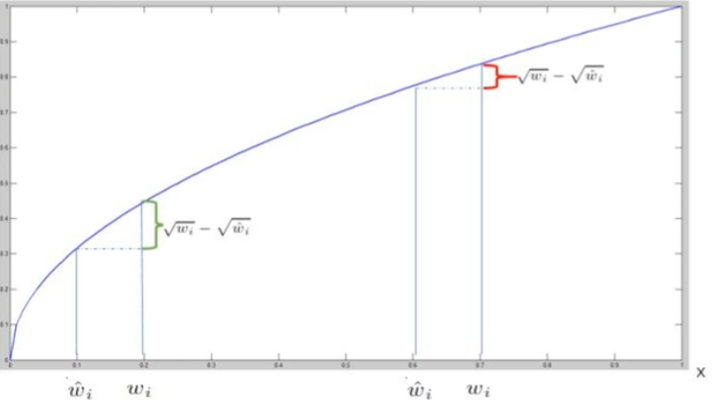
注意在计算bounding box的location的宽和高的损失时,并不是 ( w − w ^ ) 2 (w-\hat{w})^{2} (w−w^)2而是 ( w − w ^ ) 2 (\sqrt{w}-\sqrt{\hat{w}})^{2} (w−w^)2。原因在于,对于不同大小的框,相同的w\h差应该具有不同的价值。即对于相同的位置偏差,大尺寸物体的预测更准确一些
而
f
(
x
)
=
x
f(x) = \sqrt{x}
f(x)=x的曲线则符合这一特点, 因此在计算loss函数时对w和h进行了开方。
缺陷
- 8维的loc 损失和20维的cls 损失同等重要显然是不合理的。为了更重视8维坐标的预测,可以给loc损失赋予更大的权重
- 无物体的grid cell会将这个cell中的bbox的conf都设为0,如果原始图片中object较少,会导致网络发散。因此对没有object的bbox的conf loss 赋予小的loss权重。
- 小的群体检测效果不好
- 同一类物体长宽比不同时泛化能力弱
2. YOLO v2
YOLOv1算法最明显的缺陷在于
- 定位不准确
- 相对于RPN,召回率较低(TP/(TP + FN))
提出了新颖的多尺度训练方法,可以在不同尺寸下运行,并提出了一种目标检测和分类的联合训练方法。即使用庞大的图像分类数据集来帮助图像检测算法。相对于YOLOv1,主要改进了三部分——Better, Faster, Stronger。
2.1 Better
2.1.1 BN层
Batch Normalization,对网络的每一层的输入都做了归一化(YOLOv1的backbone–GoogleNet没有BN层)。另外由于BN可以规范模型,所以加入BN后扔掉了dropout层。
2.1.2 High Resolution Classifier(高分辨率图像分类器)
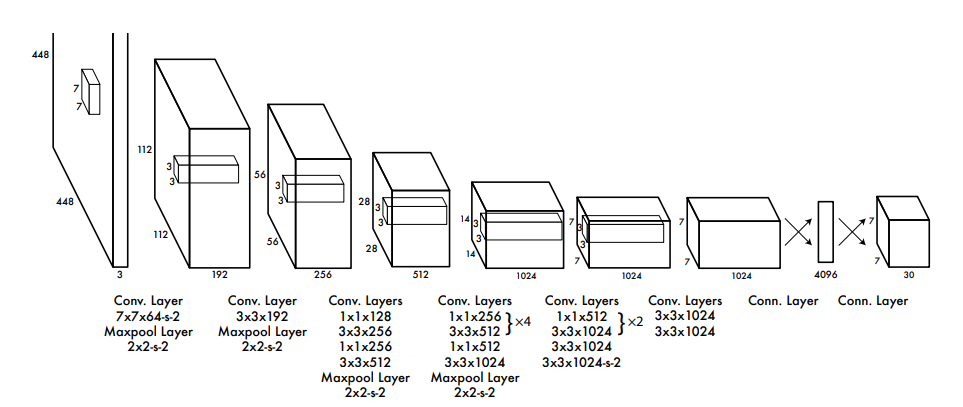
这一层体现在预训练阶段的不同。YOLOv1在预训练时采用 224 ∗ 224 224*224 224∗224的输入(根据ImageNet决定),但在detection的时候使用的是 448 ∗ 448 448*448 448∗448的输入,这就导致从classification切换到detection时还要学习图像分辨率的改变。
YOLOv2则将预训练阶段直接分为两步,从 224 ∗ 224 224*224 224∗224开始进行与训练,进行到一定epoch时调整输入尺寸,例如将输入调整为 448 ∗ 448 448*448 448∗448训练10个epoch,使模型逐渐适应 448 ∗ 448 448*448 448∗448的分辨率。以上都是预训练操作,只进行在ImageNet数据集上。最后在自己数据集上finetune即可
2.1.3 Convolutional with Anchor Boxes
YOLOv1利用fc层直接预测bbox的坐标,YOLOv2则重新引入anchors。因为作者发现,学习坐标偏移要比直接学习坐标位置容易实现的多。
首先将原网络的全连接层和最后一个pooling层去掉,使得最后的卷积层可以有更高分辨率的特征。然后收缩网络,让其运行在 416 ∗ 416 416*416 416∗416的输入而不是 448 ∗ 448 448*448 448∗448。因为网络会缩小32倍,以 416 ∗ 416 416*416 416∗416的尺度输入到网络会得到 13 ∗ 13 13*13 13∗13,奇数维度的feature map便于只产生一个center cell(而不是偶数情况下的四个)
2.1.4 Dimension Clusters(维度聚类)
作者使用k-means对训练集的bbox做聚类,目的旨在得到合适的anchor尺寸(而非像Faster RCNN那样,人为预设)。作者发现,如果使用常用的欧氏距离来衡量k-means的差异,会导致大的bbo误差也更大。因此重新定义了距离函数,使误差与bbox的尺寸无关
d
(
b
o
x
,
c
e
n
t
e
r
)
=
1
−
I
o
U
(
b
o
x
,
c
e
n
t
e
r
)
d(box, center) = 1 - IoU(box, center)
d(box,center)=1−IoU(box,center)
其中center是聚类时被选作中心的边框。
原文中令聚类k = 5
2.1.5 Direct Location prediction(约束预测边框的位置)
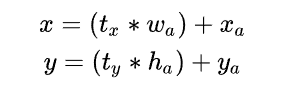
其中, x , y x, y x,y是预测边框的中心, x a , y a x_{a}, y_{a} xa,ya 是先验框(anchor)的中心点坐标, w a , h a w_{a}, h_{a} wa,ha是先验框(anchor)的宽和高, t x , t y t_{x}, t_{y} tx,ty是要学习的参数。因为 t x , t y t_{x}, t_{y} tx,ty的取值没有约束,所以anchor可能出现在任意位置,这就导致了前期训练的不稳定。
对此YOLOv2的解决办法是,**将anchor的中心约束在特定gird网格内。**这样做的好处是规范化模型,使得模型更容易收敛
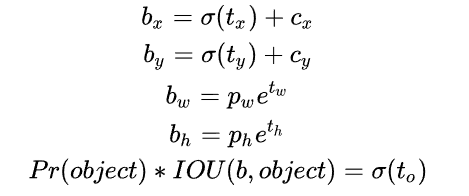
- b x , b y , b w , b h b_{x}, b_{y}, b_{w}, b_{h} bx,by,bw,bh是anchor的中心和宽高。
- 对预测参数 t 0 t_{0} t0 进行σ变换后作为置信度的值。
- c x , c y c_{x}, c_{y} cx,cy是当前网格左上角到图像左上角的距离,要先将网格大小归一化,即令一个网格的宽=1,高=1
- p w , p h p_{w}, p_{h} pw,ph是先验框的宽和高。
t x , t y , t w , t h , t o t_{x}, t_{y}, t_{w}, t_{h}, t_{o} tx,ty,tw,th,to 是要学习的参数,分别用于预测边框的中心和宽高,以及置信度。
2.1.6 Fine-Grained Features(passthrough层检测细粒度特征)
主要是添加了一个层:passthrough layer。
思想类似于ResNet,但实现方法不同。最后一层 13 ∗ 13 13*13 13∗13用于预测体积较大的物体绰绰有余,但是会丢失很多小物体的信息。因此通过合并前一层的size大一点的feature map,可以有效检测小的object。根据YOLO2的代码,特征图先用11卷积从 2626512 降维到 2626*64,再做1拆4并passthrough。具体实现参见原文, 或参考知乎
2.1.7 Multi-ScaleTraining(多尺度图像训练)
作者为了实现模型使用多尺寸的训练集,因此令训练时输入图像的size是动态变化的,而且不同于前文提到的High Resolution Classifier,多尺度图像训练操作是在finetune阶段采用的。
YOLOv2采用每迭代几次网络都会随机的选择一个新的图片尺寸。因为网络结构的下采样参数是32(从输入到输出缩小32倍),因此输入的尺度也应该是32的整数倍,文中采用{ 320 ∗ 320 , 352 ∗ 352 , . . . 320*320, 352*352, ... 320∗320,352∗352,...}。
下图是上述7个操作带来的提升效果

2.2 Faster
作者采用了全新的分类网络作为backbone,即Darknet-19。
2.2.1 Darknet-19
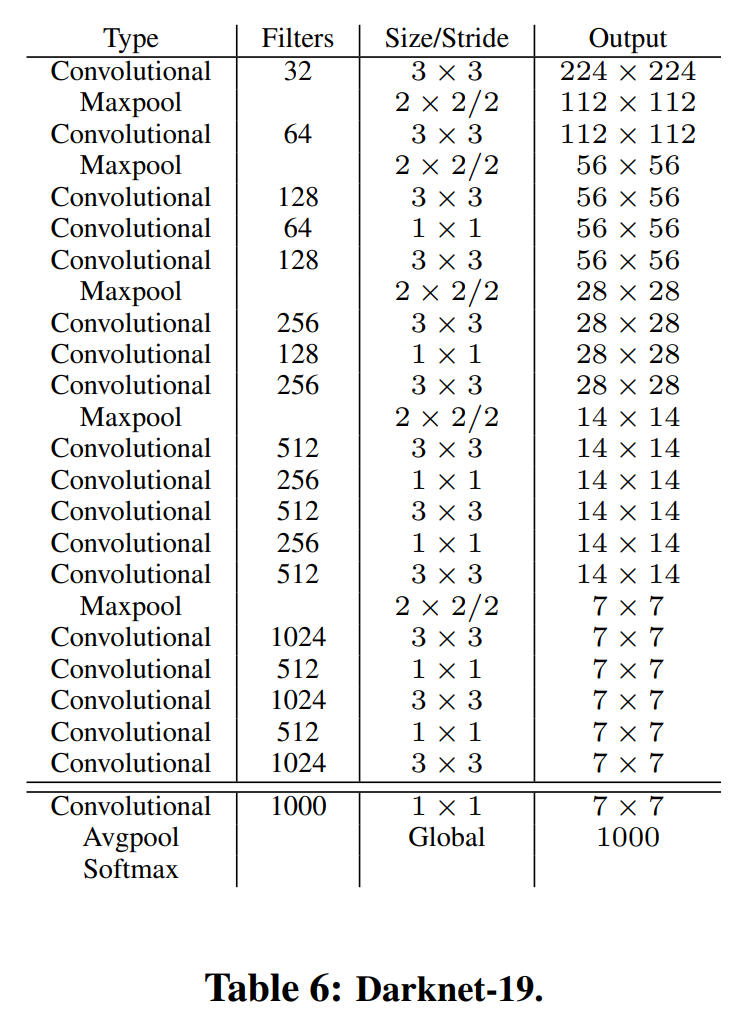
2.2.2 Hierarchical classification(分层分类)
作者提出了一种在分类数据集和检测数据集上联合训练的机制。通过ImageNet训练分类、COCO和VOC数据集来训练检测。
2.3 Stronger
WordTree。日后补充
3. YOLOv3
YOLO将输入图片统一成
416
∗
416
416*416
416∗416尺寸,然后将图片分成三个网格图片(
13
∗
13
,
26
∗
26
,
52
∗
52
13*13, 26*26, 52*52
13∗13,26∗26,52∗52)
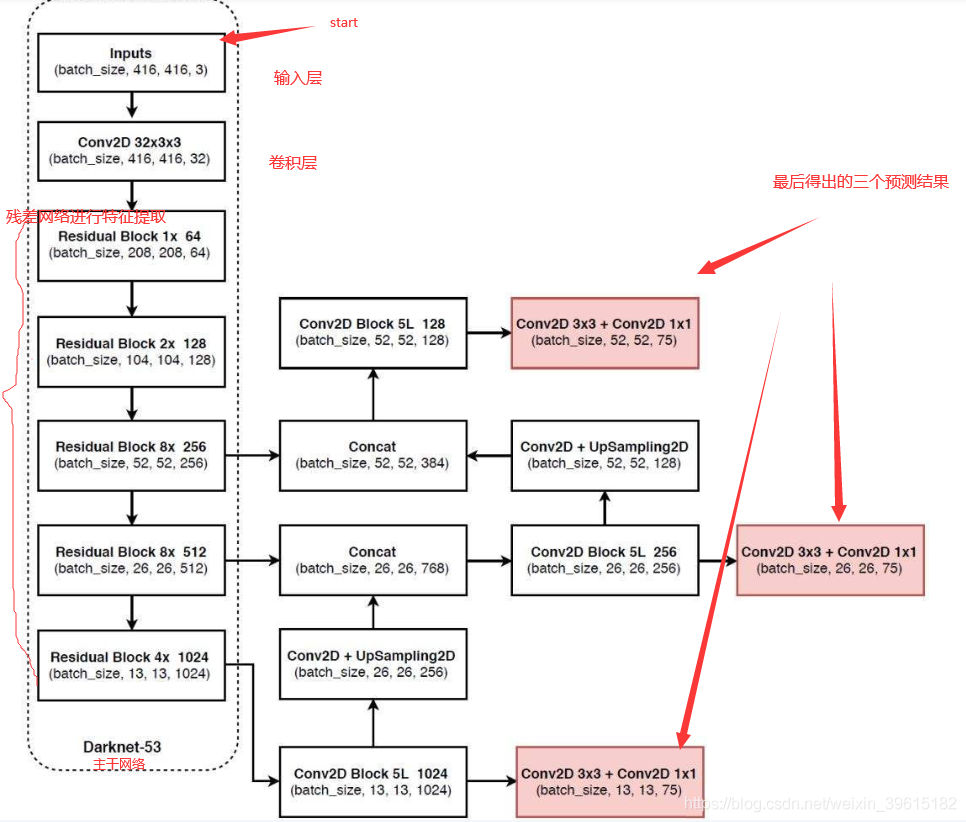
最下面的红框表示一种(共13,26,52三种)输出结果,
13
∗
13
∗
75
=
13
∗
13
∗
3
∗
25
13*13*75 = 13*13*3*25
13∗13∗75=13∗13∗3∗25,表示结果有
3
∗
3
3*3
3∗3个grid cell,每个cell中预测3个bbox,每个bbox含25个参数(4loc + 1conf + 20cls)
3.1 DarknetConv2D
YOLOv3的backbone采用Darknet53,采用了残差的思想。每个卷积部分采用独特的DarknetConv2D结构,每一次卷积的时候进行L2Norm,完成卷积后进行BN与LeakyReLU。
from functools import wraps
#-----------------
# 单次卷积
#-----------------
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
#------------------
# 卷积块
# DarknetConv2D + BatchNormalization + LeakyReLU
#------------------
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),# 调用单次卷积函数进行正则化
BatchNormalization(), # 标准化
LeakyReLU(alpha=0.1)) # 激活函数
上采样:放大图像或图像插值。为了使图像可以显示在更高分辨率的显示设备上
3.2 从特征获取预测结果
yolov3提取多特征层进行目标检测,文中一共提取了三个feature map,分别位于darknet53的中间层( 52 ∗ 52 ∗ 256 52*52*256 52∗52∗256),中下层( 26 ∗ 26 ∗ 512 26*26*512 26∗26∗512)和底层( 13 ∗ 13 ∗ 1024 13*13*1024 13∗13∗1024)。这三个特征层后续会与上采样后的其他特征层堆叠拼接。
- 特征层[13, 13, 1024]进行5次卷积处理,一部分用于卷积+上采样,另一部分用于卷积后(一个 3 ∗ 3 3*3 3∗3和一个 1 ∗ 1 1*1 1∗1)输出预测结果[13, 13, 75]
- [13, 13, 1024]上采样得到[26, 26, 256]和Darknet得到的[26, 26, 512]拼接得到[26, 26, 768],再进行5次卷积。一部分用于采样,另一部分用于卷积后(一个 3 ∗ 3 3*3 3∗3和一个 1 ∗ 1 1*1 1∗1)输出结果[26, 26, 75]
- 拼接后卷积(一个 3 ∗ 3 3*3 3∗3和一个 1 ∗ 1 1*1 1∗1)得到输出结果[52, 52, 75]
3.3 解码
3.4 得分排序&nms
1、取出每一类得分大于一定阈值的框和得分进行排序。
2、利用框的位置和得分进行非极大抑制。最后可以得出概率最大的边界框,也就是最后显示出的框
















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









