







本文是对我们 CVPR 2021 接收的工作 "ACTION-Net: Multipath Excitation for Action Recognition" 的介绍。主要针对强时序依赖行为识别这个场景,设计了一组卷积模块。

作者单位:都柏林圣三一大学,字节跳动
论文地址:https://arxiv.org/abs/2103.07372
项目地址:https://github.com/V-Sense/ACTION-Net
01
ACTION模块
ACTION 的核心思想是生成三个 attention map 即时空 attention map, channel attention map 和 motion attention map 来激发相应视频中的特征。因为 ACTION 模块是基于 2D CNN 的,所以 ACTION 的输入是一个 4D
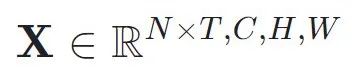
(N: batch size, T: number of segments, C: number of channels, H: hegith, W: width)。下面我们将介绍三个模块分别对于输入 X 的处理。
1.1时空注意力 (Spatial-Temporal Excitation: STE)
该模块通过产生时空 attention map 来提取视频中的时空(spatio-temporal)特征。传统的时空特征提取主要使用3D卷积,但直接对输入引入3D卷积会大大的增加模型的计算量。所以我们先对 X 做一个channel average得到一个对于时空的 global channel 的特征
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3111
3111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









