






QM9700和QM9790交换机

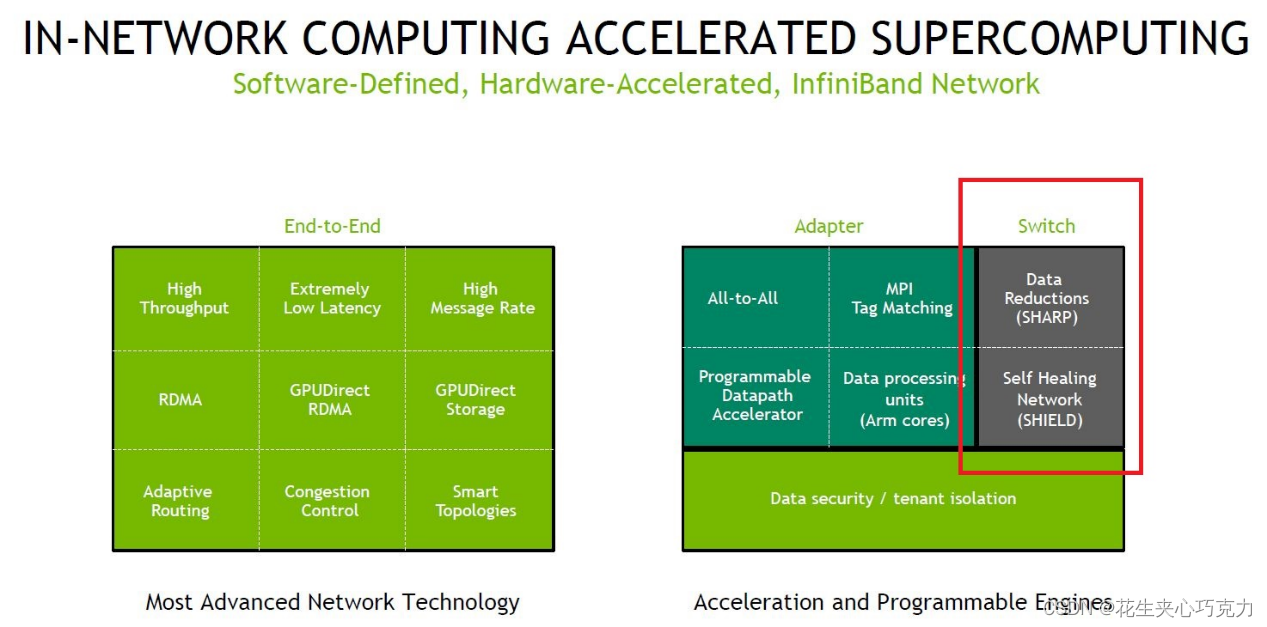
QM9700和QM9790交换机采用1U 标准机箱设计,具有32个800G物理接口,支持64个NDR 400Gb/s InfiniBand端口(可拆分多达128个 200Gb/s端口)。支持第三代NVIDIA SHARP、高级拥塞控制、自适应路由和自我修复网络技术。与上一代HDR产品相比,NDR实现了两倍的端口速度,三倍的交换机的端口密度,五倍的交换机系统容量,以及32 倍的交换机AI加速能力。

QM9700和QM9790交换机产品包括风冷式和液冷式、内部管理和外部管理(也称为非管理)交换机。每台交换机能够承载51.2Tb/s 的双向聚合带宽,支持超过每秒665亿数据包(BPPS)的惊人吞吐能力。交换能力上超出上一代 Quantum-1 约5倍。
作为理想的机架式InfiniBand解决方案,QM9700和QM9790交换机具有强大的灵活性,可支持 Fat Tree、DragonFly+、多维Torus等各种网络拓扑。同时支持向后兼容前几代产品,有着广泛的软件系统支持。
Quantum-2 ConnectX-7智能网卡
ConnectX-7 基于7纳米工艺设计,包含 80 亿个晶体管,其数据传输速率是目前世界领先的高性能计算网络芯片NVIDIA ConnectX-6的两倍,还使 RDMA、GPUDirect® Storage、GPUDirect RDMA 和网络计算的性能翻倍。
NDR HCA还包括多个可编程计算内核,可将预处理数据算法和应用程序控制路径从CPU或GPU卸载到网络,从而提供更高的性能、可扩展性和计算与通信任务之间的重叠。可满足传统企业乃至全球要求最苛刻的人工智能、科学计算和超大规模云数据中心工作负载的需求。

LinkX InfiniBand光连接件
纳多德提供灵活的400Gb/s InfiniBand光连接方案,包括使用单模和多模收发器、MPO光纤跳线、有源铜缆(ACC)和无源铜缆(DAC),用以满足搭建各种网络拓扑的需要。
>配有带鳍设计的 OSFP 连接器的双端口收发器适用于风冷固定配置交换机,而配有扁平式OSFP 连接器的双端口收发器则适用于液冷模块化交换机和 HCA 中。
>在交换机互连上,可选择采用全新OSFP封装 2xNDR (800Gbps) 光模块进行两台QM97XX交换机的互连,带鳍的设计,可以大大提高光模块散热性。
>交换机和HCA的互联上,交换机端采用OSFP封装2xNDR (800Gbps)带鳍光模块,网卡端采用带有扁平OSFP 400Gbps光模块,MPO光纤跳线可提供3-150米,一对二分光器光纤可提供3-50米。

>交换机到HCA的连接也提供DAC(最长1.5米)或者ACC(最长3米)的解决方案,一对二式分接线缆可用于交换机的一个OSFP端口(配备两个400Gb/s InfiniBand端口)和两个独立的400Gb/s HCA。一分四式分接线缆可用于连接交换机的一个OSFP交换机端口和四个200Gb/s HCA。

NDR方案优势
NVIDIA Quantum-2 InfiniBand平台持续创造高性能网络的世界新高,每个端口可实现400Gb/s 的传输速度。
在端口密度上,与上一代HDR相比,通过实施 NVIDIA 端口拆分技术,实现了两倍的端口速度,三倍的交换机的端口密度,五倍的交换机系统容量,如果采用Dragonfly+ 拓扑,基于 Quantum-2 的网络可在 3 个 hop 内实现百万余个节点的 400Gb/s 连接能力,同时可降低功耗、延迟和空间需求。
在性能上,引入了第三代NVIDIA SHARP技术,即SHARPv3。SHARPv3通过可扩展网络为大型数据聚合创造近乎无限的可扩展性,支持多达64个并行流,与上一代HDR产品相比,AI 加速能力提升32倍。
在用户成本上,与上一代HDR相比,使用NDR设备可减低网络复杂度,提高效率,后续进行速率升级时可直接替换线缆和网卡即可,NDR网络在支持同样网络的情况下需要的设备数量少,对于整体的预算和后期的投入都更为划算。

















 6268
6268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









