







文献阅读笔记5
一、文章信息
1、 作者
Berta Bescos, Jose M. F ´ acil, Javier Civera and Jos ´ e Neira
2、单位
University of Zaragoza, Zaragoza, Spain
3、期刊
IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 4076-4083, Oct. 2018
4、题目
DynaSLAM: Tracking, Mapping and Inpainting in Dynamic Scenes
二、 背景、目的
1、背景
slam可以分为两类,基于特征的以及直接法。基于特征的方法利用特征提取以及特征匹配来计算相机位姿变化情况,直接法则是直接计算图像的梯度。
(1)基于特征提取的slam
1)将地图的特征投影到当前的框架中以核实结构的合理性。
2)跟踪已知的3D物体。
3)使用深度边缘点,利用它的关联的权重推测它属于动态物体的可能性。
(2)直接法的slam
直接法对动态物体更加敏感。
1)使用双目相机通过场景流表示法检测到运动的物体。
2)使用RGB光流法分割动的物体。
3)在同一平面上投影出连续的深度图得到静止的部分。
4)计算连续RGB图像的亮度,并通过深度图完成像素的分类。
不管是(1)还是(2)都是从结果得到静止物体的信息,没有考虑到一开始静止之后可能运动的物体比如说停泊的车以及坐着的人。此外,一些文献中也没考虑一些静止物体由于外力开始运动的情况比如说被人推动的椅子或丢出去的球。
2、目的
本文结合了多视角几何以及深度学习解决检测活物、静物受到外力开始运动的情况,此外,有关研究"Unsupervised object segmen-
tation through change detection in a long term autonomy scenario"中将多视角几何与动态分类器结合。
三、术语解释
1、pixel-wise
表示像素级别的,文中意思是利用CNN(卷积神经网络)先进行像素级别的分割。类似的,还有图像级别的、块级别的,一块由许多像素组成,比整个图像小。
2、ROI
感兴趣区域,在Halcon、OpenCV、Matlab等机器视觉软件上常用到各种算子(Operator)和函数来求得感兴趣区域的ROI,并进行图像的下一步处理,使用ROI圈住想读的目标可以减少处理时间,增加精度。
3、RPN网络
全称是region proposal network,是用来提取候选框的网络,真正意义上把物体检测整个流程融入到一个神经网络。
相关链接:
链接: RPN
4、ATE、RMSE、RPE
RPE:相对位姿误差(relative pose error),在用时间戳对齐之后,真实位姿和估计位姿均每隔一段相同的时间计算位姿的变化量,然后对该变化量做差,以获得相对位姿误差,适合于估计系统的漂移。第i帧RPE定义如下;

已知帧总数n以及时间间隔
Δ
\Delta
Δ的情况下,可以得到m=n-
Δ
\Delta
Δ,RMSE表示用均方根误差统计这个误差,得到一个整体值,但是只统计平移部分的误差
t
r
a
n
s
(
E
i
)
trans(E_i)
trans(Ei),而RPE包含了旋转误差和平移误差。
R
M
S
E
(
E
1
:
n
)
=
(
1
m
∑
i
=
1
m
∣
∣
t
r
a
n
s
(
E
i
)
∣
∣
2
)
RMSE(E_{1:n})=\sqrt(\frac{1}{m}\displaystyle\sum_{i=1}^{m}||trans(E_i)||^2)
RMSE(E1:n)=(m1i=1∑m∣∣trans(Ei)∣∣2)
ATE:Absolute trajectory error绝对轨迹误差,直接计算真实位姿与估计值之间的差,但两者通常不在同意坐标系中,需要先对齐。
1)对于双目和RGB_D,尺度统一,用最小二乘法算估计位姿到真实位姿的转换矩阵
S
∈
S
E
(
3
)
S\in SE(3)
S∈SE(3)
2)对于单目,具有尺度不确定性,计算相似转换矩阵
S
∈
S
i
m
(
3
)
S\in Sim(3)
S∈Sim(3)
ATE定义:
F
i
=
Q
i
−
1
S
P
i
F_i=Q_i^{-1}SP_i
Fi=Qi−1SPi
R
M
S
E
(
F
i
:
n
,
Δ
)
=
(
1
m
∑
i
=
1
m
∣
∣
t
r
a
n
s
(
F
i
)
∣
∣
2
)
RMSE(F_{i:n},\Delta)=\sqrt(\frac{1}{m}\displaystyle\sum_{i=1}^{m}||trans(F_i)||^2)
RMSE(Fi:n,Δ)=(m1i=1∑m∣∣trans(Fi)∣∣2)
链接: 具体解释
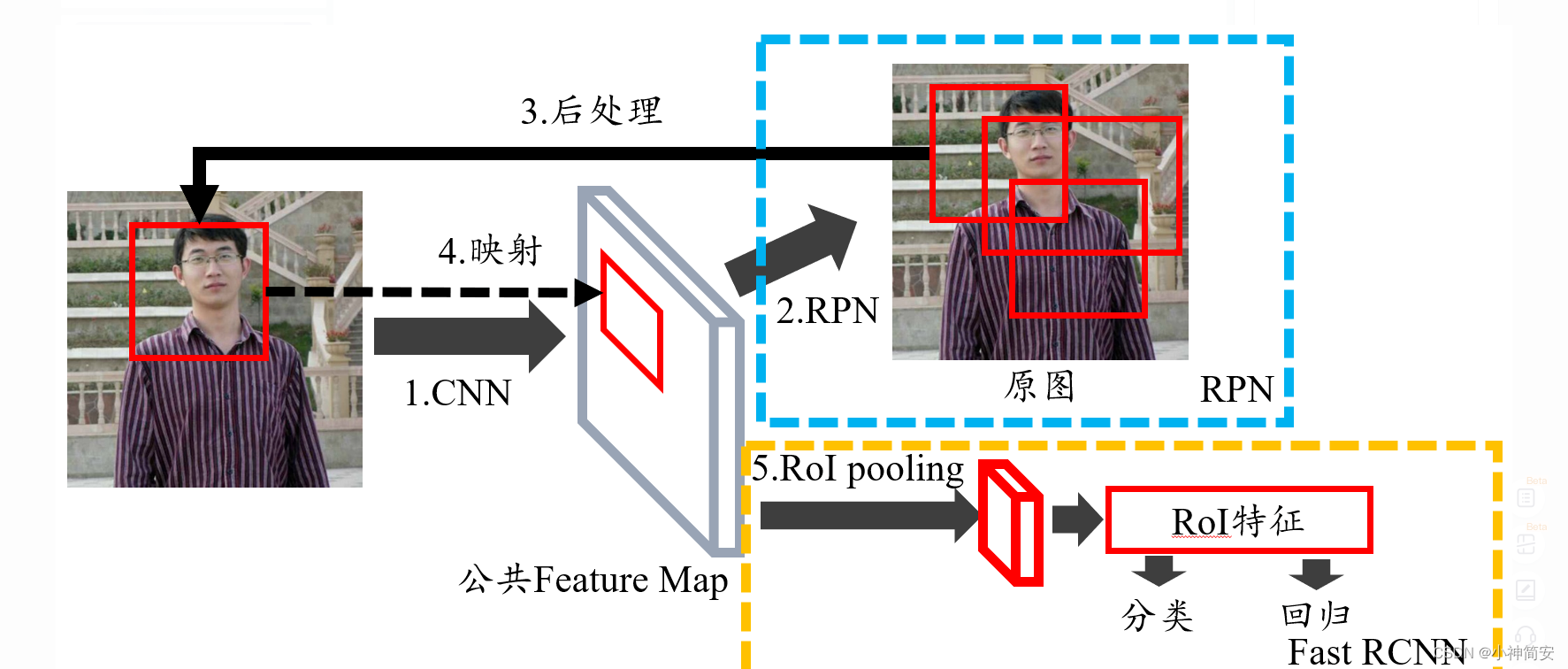
四、网络结构

分为两部分,RGB路径以及单目/双目相机。
1、RGB-D的情况
使用多视角几何在两方面提升了动态内容的分割结果。一方面,改善了由卷积网络识别出的动态物体。另一方面,可以给原来静止而现在运动的物体加标签。
2、单目相机和立体相机
利用卷积神经网络获得图像的分割,以使得属于动态物体的点不会被用于追踪以及建图。
3、Mask R-CNN
Mask R-CNN是一个实例分割(Instance segmentation)算法,主要是在目标检测的基础上再进行分割。Mask R-CNN算法主要是Faster R-CNN+FCN,更具体一点就是ResNeXt+RPN+RoI Align+Fast R-CNN+FCN。实例分割的意思是虽然很多个物体属于一种物种,但由于是不同的个体,因此被识别成不同的物体,标上不同的颜色。

是在Faster R-CNN的基础上添加了一个预测分割mask(FCN层)的分支,将Rol Pooling 层替换成了RolAlign层。
4、bounding-box regression(BB回归)
对于窗口一般用四维向量(x,y,w,h)来表示,分别代表窗口的中心点坐标以及窗口的宽高。我们的目标是寻找一种联系使得输入原始的窗口P经过映射得到和真实窗口D更接近的回归窗口D1.从P到D1,首先需要先做平移然后再做尺度缩放。
链接: mask rcnn涉及点——BB回归
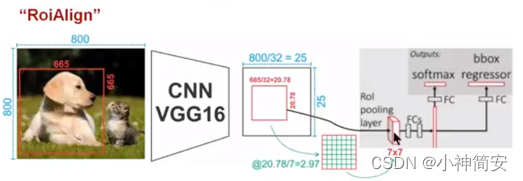
1)RolAlign
RolPooling的目的是为了从RPN网络确定的ROI中导出较小的特征图,ROI的大小各不相同,但是经过RolPool之后都变成了7x7大小,这其中由于舍去的误差以及放大倍数的影响会使得特征对应的原图像选取不准确。从RPN网络输出的特征图分辨率可能不能使得输入像素和输出像素一一对应,对分割影响大,而对分类影响不大。RolAlign的输出坐标用双线性插值算法得出,使用双线性插值算法将虚拟的浮点型像素对应到原图像对应区域可以提高检测算法的性能。
5、识别并分割活动物体的步骤
1)使用Mask R-CNN将可能活动的物体分割出来
2)低成本跟踪
使用的是ORB-SLAM2中跟踪的轻便版本,它将地图特征映射到图像中,寻找图像静止区域的联系,并减小重投影误差优化相机位姿。
3)使用Mask R-CNN和多视角几何分割出动态物体
在前一帧投影过的点X投影到当前帧得到
x
′
x'
x′,并得到一个深度
z
′
z'
z′,当
z
p
−
z
′
z_p-z'
zp−z′大于某个阀值时就判定
x
′
x'
x′实际是一个运动物体的投影。在TUM数据集中,如果视差角大于
3
0
o
30^o
30o,则也可以说明是运动物体的投影。
文中使用的阀值是
0.7
×
P
r
e
c
i
s
i
o
n
+
0.3
×
R
e
c
a
l
l
0.7\times Precision+0.3\times Recall
0.7×Precision+0.3×Recall
具体值为0.4

为了分配所有属于动态物体的像素,在深度图中我们扩大了动态像素周围的区域。
使用多视角几何由于RGB-D的限制,可能会检测不到较远地方的活动物体,而使用CNN会检测不到可能会动的静止物体(比如说书),因此将两种方法结合在一起可以获得更完整的检测结果。

4)跟踪和建图
这一阶段输入的信息有RGB和深度图以及分割的mask
5)背景的修复
当去除动态物体,我们想修复原来被动态物体遮挡的静态背景,以合成没有动态物体的图像。

图中有些区域不能被修复,是因为相关部分在关键帧中从未出现,或者即使出现了也没有有效的深度信息。
这些合成框架有个作用就是可以在静止环境的假设下用于SLAM系统。
五、实验结果
1、使用的数据集
TUM RGB-D以及KITTI
2、实验结果
1)多种相机位姿、两种检测动态物体的组合
使用TUM RGB_D数据集,这个数据集使用的传感器是Microsoft Kinect 传感器,其中“坐姿系列”和“行走系列”有四种相机运动:绕着一个直径为1米的半圆运动;沿着x-y-z轴运动;绕滚转轴、俯仰轴、偏航轴旋转;相机保持不动。本文使用的绝对轨迹来自于论文”A bench mark for the evaluation of RGB-D SLAM systems“

DynaSLAM(N)表示只用mask R-CNN,DynaSLAM(G)表示只用RGB_D的深多视角几何信息,N+G表示两种都用,N+G+BI表示还包括了背景修复阶段(background impainting)。下图表示N+G+BI的流程图。

加入修复之后的背景图,误差一般都更大了,因为修复的部分和相机位姿有很大的关系,对于相机有旋转运动(特别是纯旋转运动)位姿估计误差大,重建也不是很准确。
2)与ORB_SLAM2对比

下图表示了DynaSLAM估计出来的轨迹与ORB-SLAM2、真实运动轨迹之间的对比。

3)与DSLAM、DVO-SLAM对比

六、自我想法
本文选取了目标检测中很强的Mask R-CNN用于slam的提取特征与分割,并通过几何优化和深度学习相结合的方式提升了分割效果,用于后期跟踪和建图,且可以去除动态物体得到静止背景。但是在数据集上的表现并不全都是好于传统的slam系统(如ORB-slam,因为某些数据图上全是移动的物体),另一方面,整个系统比较复杂,要同时用到深度学习和多视角几何优化,落地困难;且只有静止部分出现过才能在去除动态物体后重建得到这一部分,否则就是空白,这也是一个缺陷。
文献阅读笔记6
一、文章信息
1、作者
Ross Girshick Jeff Donahue Trevor Darrell Jitendra Malik
2、单位
UC Berkeley
3、期刊
2014 IEEE Conference on Computer Vision and Pattern Recognition
4、题目
Rich feature hierarchies for accurate object detection and semantic segmentation(RNN)
二、背景、目的
CNN在物体分类中要解决两个问题:物体定位以及训练CNN
三、术语解释
1、region proposal
候选区域,就是预先找出图中目标可能出现的位置,利用图像的纹理边缘颜色等信息保证选取的窗口较少。这篇文章中选出候选区域的方法是运行图像分割算法,先找出多个色块,然后在这些色块上放置边界框并运行分类器,可以减少卷积网络分类器运行时间,比在图像所有位置运行一遍快。
2、histogram of oriented gradient(HOG)
方向梯度直方图,是一种用于目标识别的特征描述子。HOG的各个处理环节包括:
1)图像预处理
(1)Gamma校正
减少光度的影响,避免光线太强或太弱对算法的影响。
(2)灰度化
就是转换为灰度图像,计算公式为
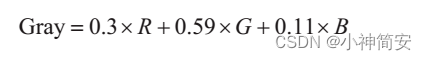
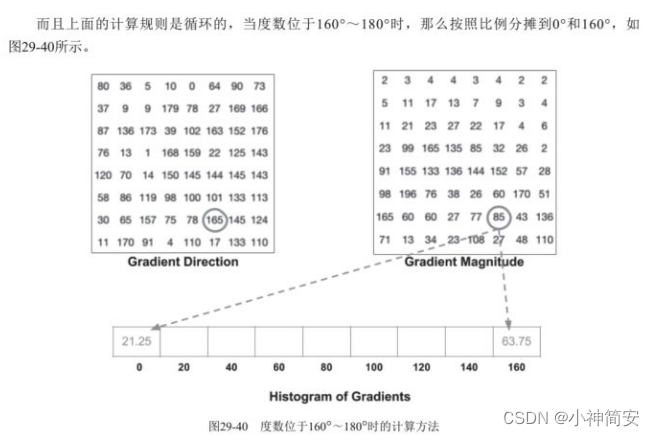
2)梯度值计算




3)块正则化
前面算出了梯度值,但是这个值受图像亮度影响较大,比如说将所有图像像素都乘以3,梯度值也会乘以3,块正则化就是为了解决上面的问题。
一个三维数据点[100 64 45]
L
=
(
10
0
2
+
6
4
2
+
4
5
2
)
=
126.96
L=\sqrt (100^{2}+64^{2}+45^{2})=126.96
L=(1002+642+452)=126.96
[
100
64
45
]
/
L
=
[
0.787
0.504
0.354
]
[100\ 64\ 45]/L=[0.787\ 0.504\ 0.354]
[100 64 45]/L=[0.787 0.504 0.354]
就算先把所有数据乘以2,最后得到的结果是一样的。
4)HOG特征向量
一般以16x16大小的块做归一化,一个格子是8x8,一个块就包含了4个格子,又因为梯度值统计在九个维度上,所以一共4x9=36维数组。这里的块在实际中是滑动窗口。对于一幅64x128的图像,以16x16的块进行移动,可以得到:
横向:
(
64
−
16
)
/
8
+
1
=
7
(64-16)/8+1=7
(64−16)/8+1=7
纵向:
(
128
−
16
)
/
8
+
1
=
15
(128-16)/8+1=15
(128−16)/8+1=15
每个窗口有36维数据,因此整个HOG特征向量就包含:
105
X
36
=
3780
105X36=3780
105X36=3780维数据。
四、内容
1)R-CNN结构

(1)输入一张图片
(2)提取出2000个候选区域,方法有:objectness,selective search,category-independent object proposals,constrianed parametric min-cuts,multi-scale combinatorial grouping
(3)使用卷积网络提取特征,使用的是caffe框架下的CNN,图像经过了5层卷积以及2层全连接。CNN产生的特征向量相比于通过图像金字塔获得的特征向量是低维的,需要的储存空间更小。
(4)使用SVM分类每一个区域
文献阅读笔记7
一、文章信息
1、作者
Sourav Garg 1∗ , Niko Sünderhauf 1 , Feras Dayoub 1 , Douglas Morrison 1 ,
Akansel Cosgun 2 , Gustavo Carneiro 3 , Qi Wu 3 , Tat-Jun Chin 3 ,
Ian Reid 3 , Stephen Gould 4 , Peter Corke 1 , Michael Milford
2、单位
1)QUT Centre for Robotics and School of Electrical Engineering and Robotics, Queensland University of Technology, Brisbane, Australia
2 )Department of Electrical and Computer Systems Engineering, Monash University, Melbourne, Australia
3 )School of Computer Science, University of Adelaide, Adelaide, Australia
4 )College of Engineering and Computer Science, Australian National University, Canberra, Australia
All authors are with the Australian Research Council (ARC) Centre of Excellence for Robotic Vision, Australia (Grant: CE140100016)
3、期刊
Foundations and Trends ® in Robotics
(2020), Vol. 8: No. 1–2, pp 1-224
4、题目
Semantics for Robotic Mapping, Perception and Interaction: A
Survey
语义在机器人建图、感知与交互中的研究综述
二、内容
1)子文章1:
A survey of image semantics-based visual simultaneous localization
and mapping: Application-oriented solutions to autonomous navigation
of mobile robot(也是综述)
(1)用深度学习检测物体的两个阶段:阶段一进行2D物体定位,阶段二进行物体的分类。

(2)用于语义slam的网络

用于分割的网络有两个指标:技术指标(包括准确性和有效性)和适用情况(是适用于视频分割还是3D图片分割)
FCN:将流行的网络(AlexNet,VGG-16,GoogleNet)修改并组合在一起
SegNet:解码和编码的框架
DeepLab:从多个角度融合了一张图片的信息,是一个系列,v1版本加入了CRF,计算量很大。
pointNet以及clockwork convnet:可以直接语义分割没有建立的3D点云,后一种和视频或图片序列有关。
(3)视觉slam的结构框架


(4)语义slam在环境鲁棒性上相关研究

a、感兴趣区域特征选取
将热图(visual saliency map)和语义分割图(semantics segmentation map)结合;将动态物体去除
b、信息丰富区域特征选取
引入信息熵的概念,减少了特征数量。
c、动态特征选取
使用多层稠密CRF工具用于分割图片;将语义分割和运动一致性检验结合起来。
(5)优化数据关联
视觉slam的数据关联可以分成两大类:短时间(特征匹配)和长时间(回环检测)保证数据关联的可靠性。但是当回环检测失败(如汽车沿笔直的路一直走)视觉里程计会发生漂移。有研究提出了中期关联机制(visual
semantic odometry. In: 15th European conference on computer vision)
(6)在slam准确性方面的研究

a、单目相机比例初始化
考虑物体尺寸进行初始化,以及大小场景是否都适用。
b、分割和几何联合优化
联合关联分为两步:离散的分割关联以及连续的位姿估计。
使用2D物体检测来推测3D物体的bounding box.
c、重定位和回环检测
几何定位依赖于图像之间的相似性,季节性的改变使得图像相似性不易辨认。有研究(Gawel A, Del Don C, Siegwart R, et al. X-view: graph-based
semantic multi-view localization. IEEE Robot Autom Lett
2018; 3(3): 1687–1694.)将关键帧进行语义分割,转换成一系列3D图像,这些3D图像用于和周围地图进行匹配。除了季节变换,语义也用于解决光线变化以及大视点(larger viewpoint)问题。随着CNN的提出,整个算法的鲁棒性会有更大的提升,但CNN的一般化还比较困难。
语义slam系统的结构:
三、术语解释
1)信息熵
所谓信息熵,是一个数学上颇为抽象的概念,在这里不妨把信息熵理解成某种特定信息的出现概率。而信息熵和热力学熵是紧密相关的。根据Charles H. Bennett对Maxwell’s Demon的重新解释,对信息的销毁是一个不可逆过程,所以销毁信息是符合热力学第二定律的。而产生信息,则是为系统引入负(热力学)熵的过程。所以信息熵的符号与热力学熵应该是相反的。
2)语义分割分类
把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。在这个过程中,图像中的每个像素都与一个对象类型相关联。图像分割主要有两种类型:语义分割和实例分割。语义分割不同的实现架构:
(1). 编码器-解码器的构架(FCN、SegNet、U-Net)
编码器一般采用图像分类预训练得到的网络,采用不断的max pooling和strided convolution有利于获得长范围的语境信息从而得到更好的分类结果。然而在此过程中特征分辨率不断降低,图像细节信息丢失,对于分割任务而言具有巨大的挑战。因此在编码器之后需要利用解码器进行图像分辨率的恢复;
(2). 语境模块(Multi-scale context aggregation、DeepLab V1、V2和CRF-RNN等)
语境模块一般是级联在模型后面,以获得长距离的语境信息。以DenseCRF级联在DeepLab之后理解,DenseCRF能够对于任意长距离内像素之间的关系进行建模,因此改善逐项素分类得到的分割结果;
(3). 金字塔池化方法(PSPNet、DeepLab V2、V3、V3+等)
金字塔池化的方法作用在卷积特征上,能够以任意的尺度得到对应的语境信息。一般采用平行的多尺度空洞卷积(ASPP)或者多区域池化(PSPNet)得到对应尺度语境信息的特征,最后再将其融合形成综合多个尺度语境的特征向量。
3)CRF(条件随机场)
条件随机域(场)(conditional random fields,简称 CRF,或CRFs),是一种判别式概率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或是生物序列。 条件随机场是条件概率分布模型 P(Y|X) ,表示的是给定一组输入随机变量 X 的条件下另一组输出随机变量 Y 的马尔可夫随机场,也就是说 CRF 的特点是假设输出随机变量构成马尔可夫随机场。条件随机场可被看作是最大熵马尔可夫模型在标注问题上的推广。
链接: 条件随机场
四、自我想法
文章总结了语义slam各个角度的结构,另一方面综述了slam在准确性、鲁棒性方面的研究,总结了语义slam的优点和不足,但由于时间为2019年,对于近几年的研究还没有总结到位,对于深度学习在slam中的应用没有详细介绍,只是从总体上介绍语义slam的结构。
slam知识
一、相机
1、单目相机
单目slam估计的轨迹和地图与真实的轨迹和地图相差一个因子,是尺度,由于单目slam无法仅凭图像确定真实的尺度,所以又称为尺度不确定性。
2、双目相机和深度相机
双目相机和深度相机可以克服单目相机的缺陷,测量距离,但原理不同。双目相机通过两个相机之间的基线测深度,而深度相机(RGB-D相机)通过红外结构光或(ToF)原理,测量物体与相机之间的距离。
二、视觉里程计
视觉里程计关心相邻图像之间的相机运动,通过相邻帧间的图像估计相机运动,恢复场景的空间结构。
三、后端优化
后端优化主要处理SLAM过程中的噪声问题,考虑的是如何从这些带有噪声的数据中估计整个系统的状态,以及这个状态估计的不确定性有多大。相对的,视觉里程计更像是前端。
四、三维刚体运动
1、两向量外积写成矩阵与向量内积的形式
a
×
b
=
∣
∣
e
1
e
2
e
3
a
1
a
2
a
3
b
1
b
2
b
3
∣
∣
=
∣
a
2
b
3
−
a
3
b
2
a
3
b
1
−
a
1
b
3
a
1
b
2
−
a
2
b
1
∣
=
[
0
−
a
3
a
2
a
3
0
−
a
1
−
a
2
a
1
0
]
b
=
a
a\times b=\left|| \begin{array}{ccc} e_1&e_2&e_3\\\\ a_1&a_2&a_3\\\\ b_1&b_2&b_3\\\\ \end{array} \right||=\left|\begin{array}{ccc} a_2b_3-a_3b_2\\\\ a_3b_1-a_1b_3\\\\ a_1b_2-a_2b_1\\\ \end{array} \right|=\left[\begin{array}{ccc} 0&-a_3&a_2\\\\ a_3&0&-a_1\\\\ -a_2&a_1&0\\\ \end{array} \right]b=a
a×b=∣
∣∣e1a1b1e2a2b2e3a3b3∣
∣∣=∣
∣a2b3−a3b2a3b1−a1b3a1b2−a2b1 ∣
∣=⎣
⎡0a3−a2 −a30a1a2−a10⎦
⎤b=a^b
^符号引入之后,a就写成了反对称矩阵
2、旋转矩阵
旋转矩阵各分量是两个坐标系基的内积,实际上是各基向量夹角的余弦值,是行列式为1的正交矩阵,可定义n维旋转矩阵的集合SO(n),称为特殊正交群。
a
1
=
R
12
a
2
+
t
12
a_1=R_{12}a_2+t_{12}
a1=R12a2+t12
R
12
R_{12}
R12表示把坐标系2的向量变换到坐标系1中。
3、变换矩阵
T
=
[
R
t
0
T
1
]
T=\left[\begin{array}{ccc} R&t\\\\ 0^T&1\\\\ \end{array} \right]
T=⎣
⎡R0Tt1⎦
⎤
左上角为旋转矩阵,右侧为平移量,左下角为0,右下角为1.这种矩阵又称为特殊欧氏群SE(3)
4、SVM
SVM方法是通过一个非线性映射p,把样本空间映射到一个高维乃至无穷维的特征空间中(Hilbert空间),使得在原来的样本空间中非线性可分的问题转化为在特征空间中的线性可分的问题.简单地说,就是升维和线性化.升维,就是把样本向高维空间做映射,一般情况下这会增加计算的复杂性,甚至会引起"维数灾难",因而人们很少问津.但是作为分类、回归等问题来说,很可能在低维样本空间无法线性处理的样本集,在高维特征空间中却可以通过一个线性超平面实现线性划分(或回归).一般的升维都会带来计算的复杂化,SVM方法巧妙地解决了这个难题:应用核函数的展开定理,就不需要知道非线性映射的显式表达式;由于是在高维特征空间中建立线性学习机,所以与线性模型相比,不但几乎不增加计算的复杂性,而且在某种程度上避免了"维数灾难".这一切要归功于核函数的展开和计算理论.
Linux知识
一、库文件
1、在linux中,库文件分为静态库和共享库两种,静态库的后缀名为.a,共享库以.so结尾,所有库都是一些函数打包后的集合,差别在于静态库每次调用都会生成一个副本,而共享库只有一个副本,更省空间,想用共享库则需在CMakeList.txt中加:
add_library(hello_shared SHARED libHelloSLAM.cpp)
2、为了让别人能调用库文件,需要提供一个头文件(xxx.h)文件
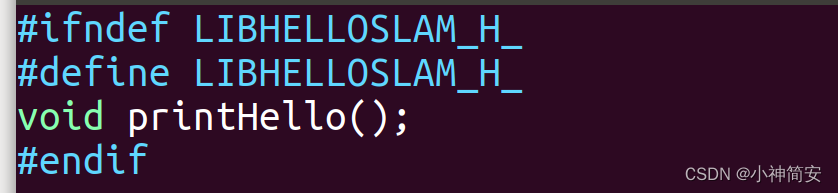
3、然后再编写一个可执行程序来调用函数
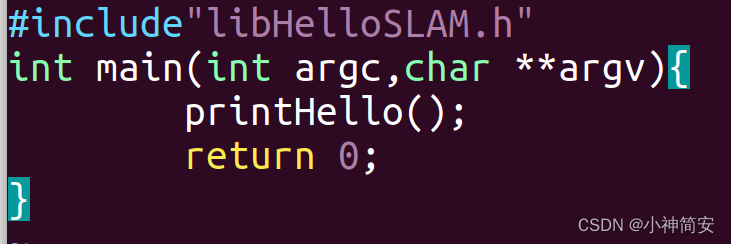
4.再在CMakeLists.txt文件中添加一个可执行程序的生成命令,连接到刚刚生成的库上

深度学习在windows中配置环境
1、通过NAVIDA控制面板查看自己显卡支持的CUDA,去官网下载CUDA和CuNN。
2、进入anaconda prompt创建虚拟环境。conda create 虚拟环境名称 python=版本号
3、输入 conda install pytorch
4、通过python测试import pytorch是否有效。















 113
113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









