






Slam知识点
Harris响应
最近学习了一下关于Harris响应的相关知识,主要用于角点的提取上,它主要是利用一个滑动的窗口,对于某个固定方向的(u,v),我们可以得到在当前像素下的窗口进行移动所产生的像素差,公式如下:
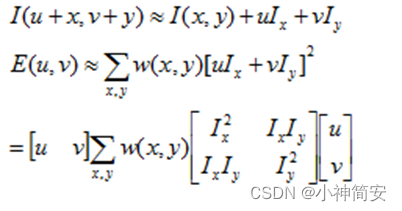
w为窗口函数,代表了窗口下每个像素点的权重,一般采用高斯函数,表示越靠近所选点,其权值越大。
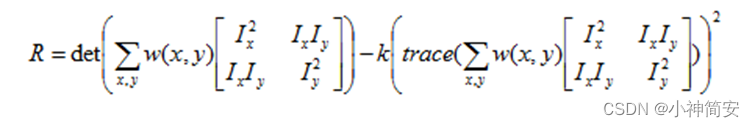
然后对于变化的像素点,我们为了加速,用泰勒展开
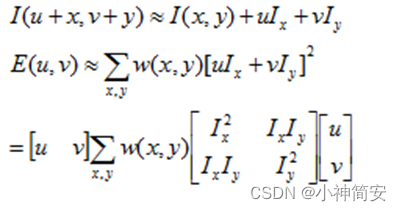
这样我们成功将差值转换为了这样的二次型,然后对中间的A求它的特征值,如果两个特征值都很大,那么认为是角点,都很小,那么认为是平滑的区域,否则认为是边线
我们将其进一步转换得
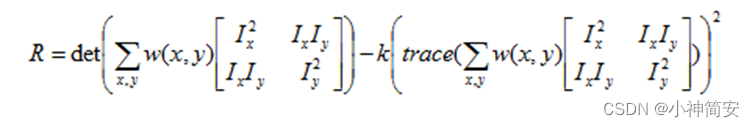
k一般取0.04-0.06
这样如果R很大的正数认为是角点,很大的负数是边线,一般的正数是平滑区域。
至此,算法结束,可以看出Harris响应还是比较容易理解的,且代码实现不困难,因为偏导数就用差值来计算即可。
八叉树

高斯模糊




源码解释



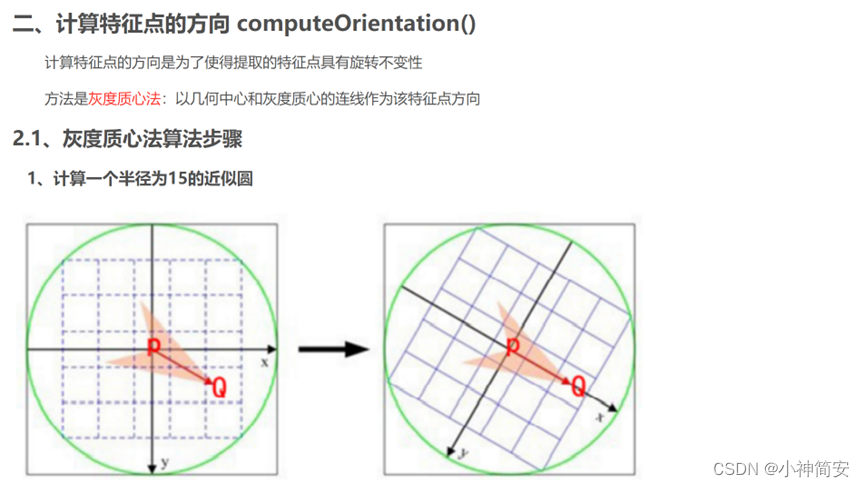
(67条消息) ORB_SLAM2 源码解析 ORB特征提取(二)_小负不负的博客-CSDN博客_灰度质心法
HOG特征

(67条消息) HOG特征—简介_flyingpig851334799的博客-CSDN博客_hog特征
DPM目标检测算法
Ceres的基本用法
(67条消息) Ceres入门——Ceres的基本使用方法_Andy是个男子名的博客-CSDN博客_ceres使用
DBOW原理以及使用方法
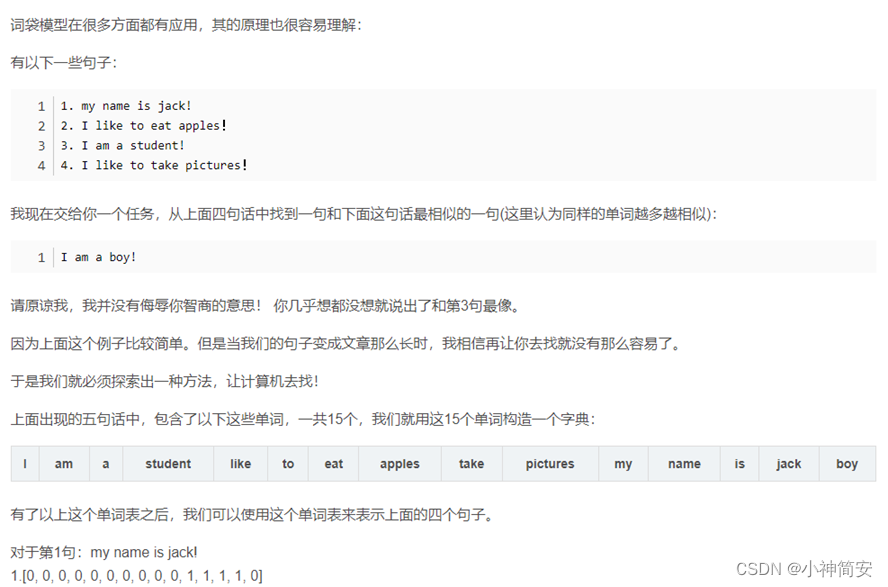

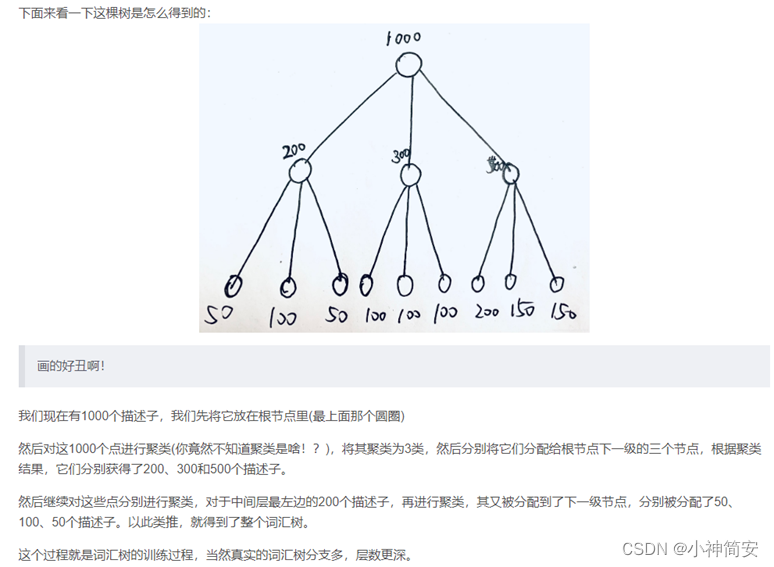
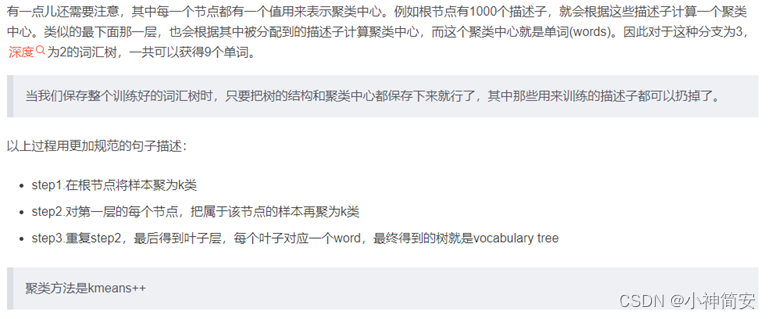
文献阅读笔记1(详细)
1.名称
GeoNet: Unsupervised Learning of Dense Depth, Optical Flow and Camera Pose
2、主要内容
1)提出了一种几何一致性损失函数提高算法对outliner、non-lambertian(遮挡、光度不一致问题)鲁棒性
2)视频中的几何关系采用动静物体的分离方法,先采用隔离出来的模块,然后算损失函数。结合在一起就是提出了一种无监督学习框架Geonet,整个框架有两部分,刚性结构重构器(rigid structure reconstructor)以及非刚性结构重构器(non-rigid motion localizer).
刚性静态物体如树木、房屋以及道路等在视频帧之间的2D投影图像完全由深度结构和相机运动决定。
3)非刚性结构重构器为ResFlowNet,用于学习剩余的非刚性流,且在估计时采用了刚性区域的约束性质,可用于纠正运动物体预测的错误,还可以纠正第一阶段高饱和度和极端照明条件产生的不完美结果。
3、一些看不懂的名词解释
1)结构自运动(SFM)

(67条消息) Sfm方法过程及原理_清楼小刘的博客-CSDN博客_sfm原理
传统的SFM以整合深度恢复、光流估计以及距离
2)场景流估计
场景流是指空间中场景的三维运动场,即空间中每一点的位置信息和其相对于摄像头的移动,场景流估计的一种方式是光流估计和深度估计的结合。深度估计是指获取图像上每一点距离测量平面的深度信息,分为基于激光雷达的深度估计、基于光学图像的深度估计,其中基于光学图像的深度估计又分为双目深度估计、单目深度估计。基于重构的单目深度估计有两种方法:1、基于视频的方法,重构视频中的前后帧;2、给定左图重构右图的方法,在训练时需要成对的图像,测试要一张图像。其中基于视频的单目深度估计方法包括两个子问题:预测出每一帧的深度图和车辆自身运动状态。
3)刚性流(rigid flow)
相机运动控制的场景级一致性运动,区别于物体运动。
4)光度一致性假设(photometric consistency)
光度是指不是亮度,也不是一个物理量,用于光度函数。光度函数指的是任意频率的光和波长为550nm的光产生同样亮暗感觉所需的辐射通量之比。光度一致性假设是指同一空间的点在不同视角的投影应当具有相同的颜色。但由于相机曝光等因素,同一个像素点在不同视图上的光度信息存在一定差异性。因此对于夜间场景,由于非单一光源就会导致完全不满足光度一致性假设,无监督框架无法使用。
5)静态场景假设
投影函数是基于相机的运动T进行构建的,动态物体是不满足该投影函数的,若场景中存在其他未考虑其运动的动态物体,投影关系就会不准确。
6)遮挡/视野变化
由于相机的运动,在当前帧被遮挡的信息,在下一帧由于相机视角的变化,该信息在下一帧可见;或者,由于相机运动,在当前帧可见的信息在下一帧不可见。
解决方法:
(1)借助于掩膜神经网络,估计这些不一致区域,并进行消除;(嫁接在位姿网络之后,对对应区域损失进行重新加权,削弱其影响)
(2)利用前后帧的视野信息互补,解决信息遮挡和信息缺失问题。(即monodepth2 中最小化视图重构损失的基本思想,也是目前视图重构损失构建的主流方案)
4、文中定义的一些名词的计算方法
1)从t帧(目标帧)到s帧(源帧)的刚性流估计
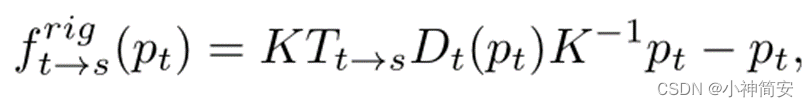
2)光度损失(photomatric loss)

用于测量刚体部分的rigid warping loss,即用刚性流重建目标帧与原真实目标帧之间的差距测量。
3)边缘感知深度平滑损失(edge-aware depth smoothness loss)
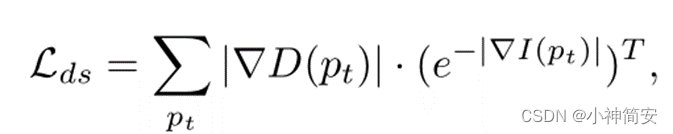 用于过滤掉错误的预测并保留清晰的细节信息,使得预测深度更加平滑/
用于过滤掉错误的预测并保留清晰的细节信息,使得预测深度更加平滑/
4)几何一致性损失
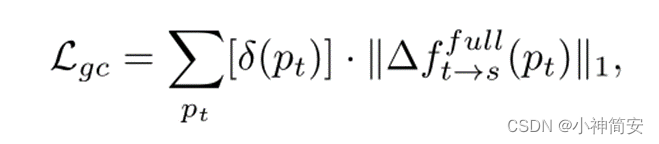
几何一致性是指同一个静态点在相邻帧之间的尺度(尺寸大小)几乎不会有变化。几何一致性损失是指两帧之间图片之间的位姿变化不会有较大波动。
5)整个网络的损失函数
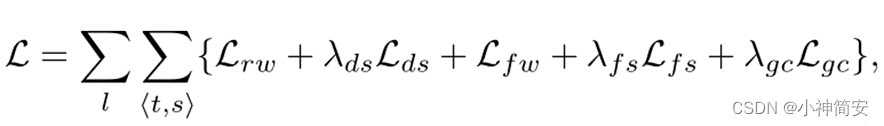
6)结合动静框架的估计获得全域的感知深度平滑损失(Lfs)
5、网络结构
GeoNet主要包含三个子网络,即DepthNet&PoseNet组成刚性结构重构器。ResFlowNet实现非刚体运动的定位。
- depthnet和resflownet
推测的是像素级的几何关系,采用文献阅读笔记2中的网络结构
2)Posenet
参考文献阅读笔记3的结构网络
6、未来工作
1)解决warping loss的局部梯度性问题
2)将语义信息引入到GeoNet中
文献阅读笔记2
1、名称
Unsupervised Monocular Depth Estimation with Left-Right Consistency
2、主要内容
1)在利用一些对极几何约束的情况下,会产生视差损失。作者还发现只用图像重建结果会产生低质量的深度图。为了克服这个困难,相比于笔记1的论文,提出了一种新型的训练损失函数,加强左右视差图的一致性,且作者的方法在KITTI数据集的单目深度估计上超过了用ground-truth深度训练的有监督方法。
2)评估几种训练损失以及图像结构模型说明作者方法的高效。
3)除了展示驾驶的数据集上完成的结果,作者也用这个模型泛化到3个不同的数据集上,包括一个自己采集的室外城市数据集。
4)在与作者工作相似的Deep3D对比时可以发现,Deep3D的组成模型是不可微的,他们用taylor近似去线性化损失函数;而作者采用了双线性采样生成图像,得到全可微的训练损失函数。
3、一些看不懂的名词解释
1)视差图
同一个场景在两个相机下成像的像素的位置偏差。比如说场景中的X点在左相机是x坐标,那么在右相机成像则是(x+d)坐标
2)深度图
场景中每个点离相机的距离,与视差图可以相互转换。
3)双线性采样(bilinear sampling)
双线性采样主要用于增强生成的视差图,因为视差图经常会出现一些噪点、空洞。
(1)双线性插值原理
插值在数学上指的是一种估计方法,根据已知的离散数据点去构造新的数据点。一维曲线的插值的原理可以推广到任意维度的数据形式上。
(2)双线性采样以及grid_sample
采样原理是双线性插值,在深度学习框架pytorch中提供了一种称之为双线性采样的函数torch.nn.functional.grid_sample
4)左右一致性检查left-right consistency check
作用是实现遮挡检测,得到左图对应的遮挡图像。具体做法:根据左右两幅输入图像分别得到左右两幅视差图。对于左图中的一个点P,求得的视差值是d1,那么p在右图中的对应点应该是(p-d1),其视差值记作d2,若|d1-d2|>threshold,p标记为遮挡点。
5)基线距离(baseline distance)
双目相机是通过两个单目相机组成的,这两个相机之间的距离称为基线距离。
6)’纹理拷贝‘人工合成 ’texture-copy’artifacts
OpenGL将一个纹理拷贝到另一个纹理的方式
- 添加目标纹理为FBO的颜色附着(颜色缓冲区),绑定源纹理渲染到目标纹理。
- 添加目标纹理为FBO的颜色附着(颜色缓冲区),使用glCopyTexlmage2D拷贝当前FBO的颜色缓冲区到目标纹理。
- glBlitFramebuffer
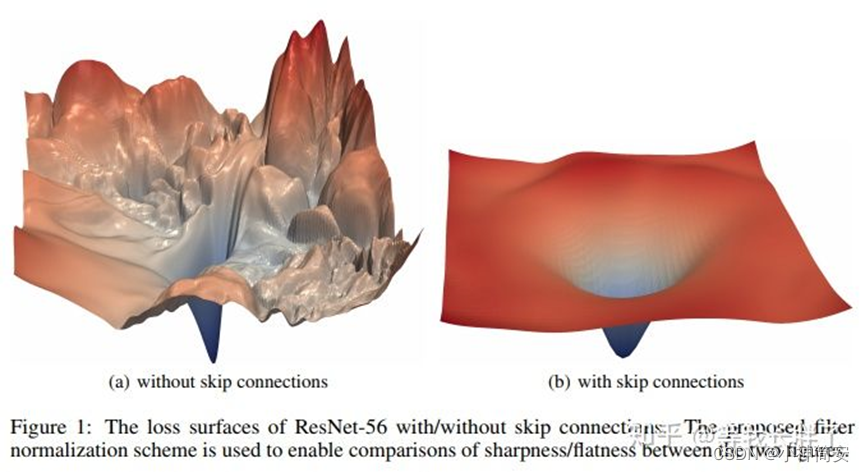
7)skip connection
中文翻译叫跳跃连接,通常用于残差网络。它的作用是在比较深的网络中解决训练过程中梯度爆炸和梯度消失的问题,残差块中直接将第I层传出到I+2层,使得a[I+2]=g(z[I+2]+a[I])
8)SSIM(结构相似性评价)
SSIM是一种衡量两幅图片相似度的指标。它的输入是两张图像,其中一张是未经压缩的无失真图像(即ground truth),另一张就是恢复出的图像。
假设输入的两张图像分别是x和y,SSIM的定义为:
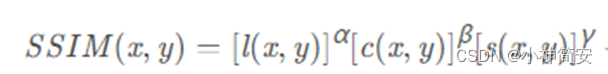
其中,
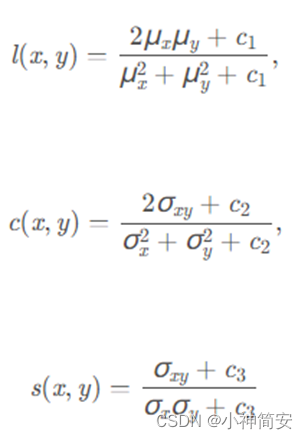
- l(x,y)是亮度比较,c(x,y)是对比度比较,s(x,y)是结构比较,ux、uy分别代表x,y的平均值,σx、σy分别代表x、y的标准差,c1、c2、c3分别为常数,避免分母为零带来的系统错误。
- SSIM是0到1之间的数,越大表示输出图像与原图像差距越小,图像质量越好。
在实际应用中,可以利用滑动窗将图像分块,令分块总数为N,考虑到窗口形状对分块的影响,采用高斯加权计算每一窗口的均值、方差以及协方差,然后计算对应块的结构相似度SSIM,最后将平均值作为两图像的结构相似性度量,即平均结构相似性MSSIM。
![]()
4、网络结构
作者的网络主要由两个部分组成:编码器:从第一层卷积到第七层卷积b;解码器:从反卷积7.解码器是从编码器的激活块做skip connections的,这样可以让它能够分解更高的分辨细节。作者输出4种不同尺度(从disp4到disp1)的视差预测。然后根据左右相机的距离b以及相机焦距f可以通过公式计算出最终的深度。
5、文中定义的一些名词的计算方法
1)总体损失C
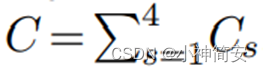
由每个输出尺度s之和组成总体损失。
2)每个输出尺度Cs的损失组成

Cap:激励重建图像表现的像与对应的训练输入更加接近
Cds:增强视差的平滑性
Clr:使预测的左右视差图保持一致
3)光度图像重建损失Cap
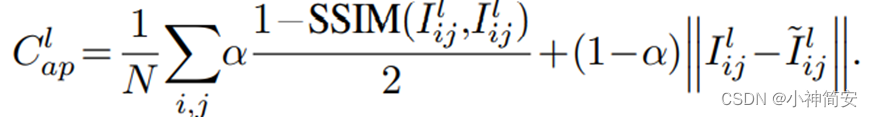
4)视差平滑度损失

文中所说的无监督是指没有深度信息,而不是没有真实的左右视图。这个损失函数主要用于检测视差图生成的效果好坏,对于区域内部要求视差图区域平滑,梯度要很小。当有噪声点、边缘或者空洞的时候,梯度变化较大,损失函数值不会很小,要使其最小,则应使梯度足够小。
5)左右视差一致性损失
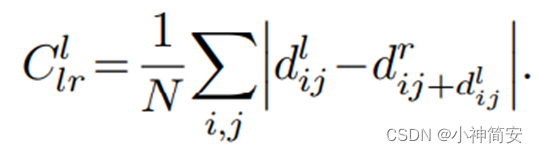
试图让左视差图等于被投影的右视差图,这一项和其他像一样,是左右视差图镜像的。
源码地址:
文献阅读笔记3
- 名称
Unsupervised learning of depth and ego-motion from video
- 主要内容
- 使用KITTI数据集证明了合成的深度图与监督学习的方法是可比的。
- 在可比较的输入设置下,姿态估计与已建立的SLAM系统相比性能优越
- 名词解释
1)explainability
可解释性不是为了一个明确的目标(像是一个待优化的目标函数)而存在,而是为了确保一些方面因为可解释性本身而得到保障。可以理解为具体的某一个模型中,模型结构、模型参数、数据输入等是如何得到数据输出的。这是一个更加形象、具体的后验概念(也就是事情发生之后,我想着怎么去解释,让别人理解我)。
2)interpretability
分为两个方面,数据的interpretability以及结构的interpretability
(1)数据的interpretability是指让神经网络具有清晰的符号化的内部知识表达,去匹配人类自身的知识框架,从而人们可以在语义层面对神经网络进行诊断和修改。
(2)结构的interpretability是指为什么这样设计可以得到好的结果,比如说深度学习中的各种网络结构、各种损失函数、各种激活函数以及参数设置,结构的可解释性通常和神经网络的优化理论有关。
相关链接:可解释性(interpretability) - 知乎 (zhihu.com)
- 跳层连接的作用
3)SGD
梯度下降法,具体解释:梯度下降法(SGD)原理解析及其改进优化算法 - 知乎 (zhihu.com)
4)bottleneck

5)multi-scale side prediction
Single scale是指给CNN一种图片,而multi-scale是指给CNN多张图片(比如说10张),产生数据增强的效果,在使用PIL.Image获取图片之后,常用的数据增强方式有7种:中心裁剪、随机裁剪、Resize图像、随机长宽比裁剪、随机水平翻转、随机垂直翻转以及随机旋转。
6)flowaugmentation
Augmentation表示增强,flowaugmentation表示对ground truth进行和图片相同的变换,dataaugmentation表示对数据集进行扩充。
7)stride
是图像处理中常用的手段,比如说一行有12个像素,对一个64位(每个像素8字节)的图像,stride=12x8=96.由于按照4字节对齐,因此当算的不是4的倍数时,要进行补齐。
- 网络结构
- single-view depth
采用的是dispnet的结构,主要是编码以及解码的过程添加了跳跃连接以及multi-scale side prediction.dispnet的网络结构是在flownet的结构上进行的修改,先介绍flownet的网络,然后介绍dispnet的变化部分。
- flownet
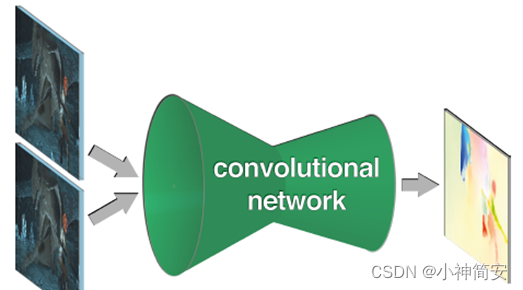
收缩部分主要由卷积组成,用于深度地提取两张图片的一些特征;扩大部分在把结果恢复到高像素。
缩小部分:
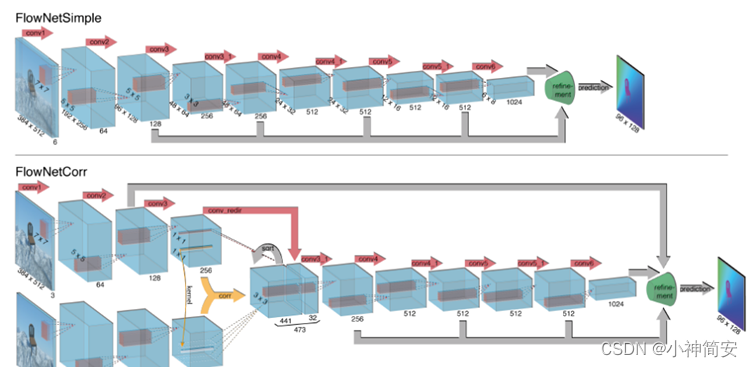 Corr层用于比较两个特征图的各个块,以卷积的形式联系在一起。
Corr层用于比较两个特征图的各个块,以卷积的形式联系在一起。
放大部分:

一边向后反卷积,一边直接在小的特征图上预测,然后把结果合并在反卷积之后的特征图上,往后传4次,得到的预测光流分辨率依然是输入的1/4,直接用双线性插值得到和输入相同分辨率的光流预测图。
- dispnet的结构相比之下有3点改变
- 有DummyData层,用于产生一些随机数,虚拟数据用于这一层模拟预测过程,常用来debug,也可以用来测试网络传递时间
- 放大部分在每个反卷积和前一预测结果组合之后增加了卷积层,使得结果图更平滑
- 放大部分比flownet多了一次反卷积,得到的图像分辨率更高。相反,卷积会使得图像更加模糊。
5、文中定义的一些名词的计算方法
1)视图合成误差(view synthesis objective)
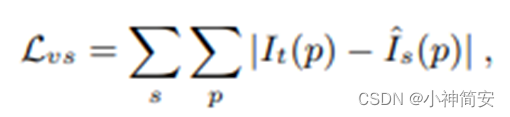
2)位于源图像上的目标图像的投影点ps

文献阅读笔记4
- 名称
Visual semantic odometry
- 主要内容
改善slam积累的误差有两种:第一种使用图像之间的短期关联来获得暂时的漂移矫正,通过过渡性地建立连续相机帧之间的约束;第二种通过回环检测在远帧之间建立长距离约束,适用于相机重复访问之前的位置。本文提出的语义信息来改正第一种漂移矫正策略,建立点的中期连续跟踪。
- 推导一种独特的最小化语义投影误差的损耗函数,可以用(EM)期望最大法最小化损耗函数,且可以与任何语义分割算法结合。
- 将语义误差整合到VO算法中显著改善平移漂移问题
- 做实验分析什么条件下有改善,并讨论限制
3、一些名词的计算方法
- 输入图像
![]()
2)相机姿态
![]()
3)地图点
![]()
4)基本里程计目标函数
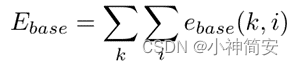
5)点Pi属于分类c的概率
![]()
6)语义cost function

7)优化的总目标函数
![]()
λ与语义的可信度有关















 1406
1406











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









