







 FlowFusion是一个动态稠密RGB-DSLAM系统,使用光流残差来识别和分割动态物体,同时优化相机位姿估计和静态背景重建。通过比较光流估计和静态假设的光流,能有效检测动态物体,减少静态背景的分割错误。相比现有方法,FlowFusion在动态和静态环境中都展现出更高精度和效率。
FlowFusion是一个动态稠密RGB-DSLAM系统,使用光流残差来识别和分割动态物体,同时优化相机位姿估计和静态背景重建。通过比较光流估计和静态假设的光流,能有效检测动态物体,减少静态背景的分割错误。相比现有方法,FlowFusion在动态和静态环境中都展现出更高精度和效率。
FlowFusion:Dynamic Dense RGB-D SLAM Based On Optical Flow
FlowFusion: 基于光流法的动态稠密RGB-D SLAM
Abstract
- 动态的环境对于视觉SLAM来说是很有挑战性的因为运动的物体会遮挡静态环境特征,并且导致错误的相机运动估计。
- 在这篇文章中,我们提出了一个新的稠密的RGB-D SLAM方案,它可以同时完成动态/静态分割和相机自我运动估计,以及静态背景重建。我们的新颖之处在于用光流残差来突出(highlight)RGB-D点云中的动态语义,同时为相机追踪和背景重建提供更多精确和有效的动态/静态分割。
- 在公开数据集和实际动态场景上的稠密的重建结果表明了,相对于SOTA方法,我们提出的方法无论在动态还是静态环境实现了精确和有效的表现。
(动态分割、ego-motion、背景重建;技术:光流残差)
I. Introduction
动态环境会对视觉SLAM的运动估计造成影响,因此语义分割以及目标检测被引入其中,作为一个预处理步骤。
但是这两种方法都只能处理已知的物体,在未知物体的情况下会漏检。而基于光流的方法则可以检测到一切种类的动态物体。并且基于光流的方法对微小的运动很敏感,对非刚体也有优势。
但是基于光流的方法需要设置复杂的惩罚项(complex penalty setting),并且分割边缘也不太好。
本文的方法 基于残差的光流法(optical flow residuals)
II. Related Work
暂时略
III. Optical Flow Based Joint Dynamic Segmentaion and Dense Fusion
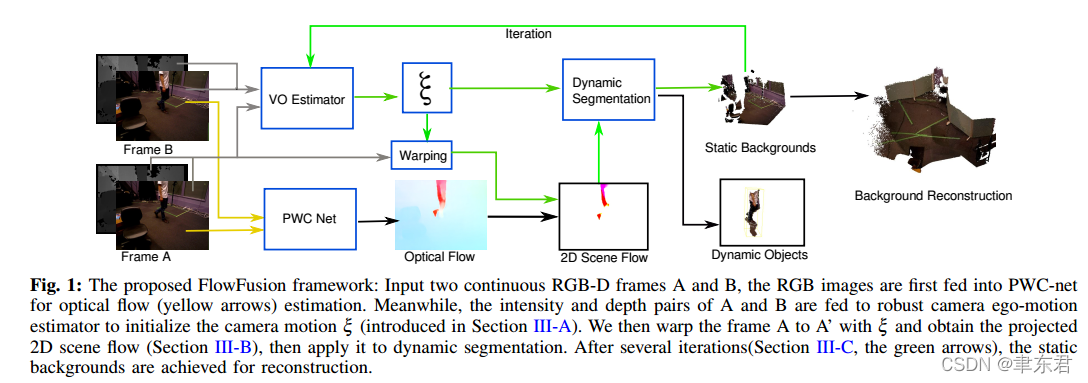
-
简而言之,就是先通过一般的视觉里程计来计算相机位姿,尽管会受到动态点影响,但是也可以得到一个不差的位姿。
-
然后通过该相机位姿将前一帧warping(偏移)得到一个基于全静态假设的光流图,然后和经过PWC Net的真正光流图进行比较,就可以把其中的动态物体找出来。
-
把去掉动态物体的背景图再送回视觉里程计再估计一次,就可以得到更好的相机位姿了。(上一次估计的值可以作为初值,所以收敛比较快吧)
【这种先大概估一下,再精确估一下的做法似乎和DynalSLAM有相似之处。不过感觉很浪费,还不如直接在光流估计后面接个神经网络呢。而且这里边也没有对光流估计的值进行进一步利用】 -
最后就是静态重建了。
A. Visual Odometry in Dense RGB-D Fusion
VO前端被构造成一个优化问题,注意这里不是BA的重投影误差,而是光度误差+深度误差,也即photometric + depth residuals
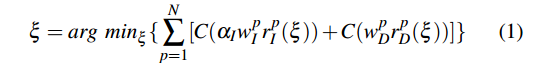
第一项为光度误差,第二项为深度误差。
α
I
\alpha_I
αI是用以平衡光度误差和深度误差的数值比例。
w I p w^p_I wIp和 w D p w^p_D wDp是误差权重,就是观测噪声的方差的倒数 1 / σ 2 1/\sigma^2 1/σ2,和BA优化中的信息矩阵 Σ − 1 \Sigma^{-1} Σ−1差不多。
C
(
r
)
C(r)
C(r)是Cauchy鲁棒核函数(Cauchy robust penalty),主要来用抑制误差偏大的项(outliers),它比直接采用
L
1
L_1
L1或
L
2
L_2
L2范数要更好。
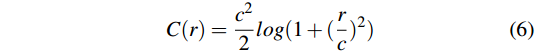
光度误差
这里其实是直接法。
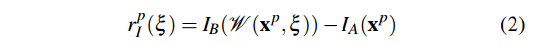
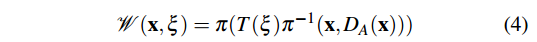
公式(4)将A帧中的像素坐标反投影为A相机坐标系下的三维坐标(
D
A
(
x
)
D_A(\mathbf{x})
DA(x)指的是相机坐标系下的深度),之后通过变换矩阵
T
(
ξ
)
T(\xi)
T(ξ)变换到B相机坐标系下,再次投影到相机坐标系下。
公式(2)将投影到B帧下的像素灰度和原来的A帧下的像素灰度作差,这里应用了光度不变假设。
(值得注意的是,灰度和光度是有区别,灰度考虑了光投影到成像平面的光学模型,理论上更精确,可以参考DSO。但是这里不确定指的是真正的光度,还是只是和灰度混用了)
深度误差
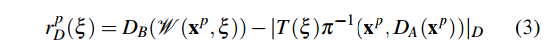
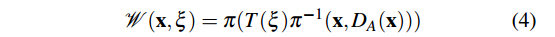
公式(4)与前面一样,都是讲A帧中的像素坐标反投影,再变换,投影到B帧中。
D
B
D_B
DB通过深度图获得了像素在B帧中的深度。而右边那项与此很相似,A帧中的像素反投影,再变换成B帧中的三维坐标,只不过这次,不再从B帧中获得观测的深度,而是直接从三维坐标中提取深度。
在上述直接法的计算中,优化变量应该只有位姿。
B. Optical Flow Residual Estimated by Projecting the Scene
这是本文最重点的部分。
聚类(这部分原来属于A,这里放到B来讲)
对相机测得的所有点根据灰度值,采用超像素聚类分成
N
N
N类,第
i
i
i类表示成
V
i
V_i
Vi。
动静判别
A部分中,优化完成后可以获得相机位姿
ξ
\xi
ξ,该位姿的主要贡献来源于视野中的静态环境点。每个聚类的点在优化完成之后都会获得两个误差,即光度误差和深度误差,可以算法每个聚类中点的平均误差。误差越大,说明这个聚类与相机位姿越格格不入,有理由认为这个聚类是动态物体。
但是由于深度图的种种缺点(与灰度图时间上对不齐、边缘处不连续、越远误差越大),这里不采用这种方法,而是采用光流误差(optical flow resisual)来作动静判别。
在正式讲光流误差前,先区分几个概念:
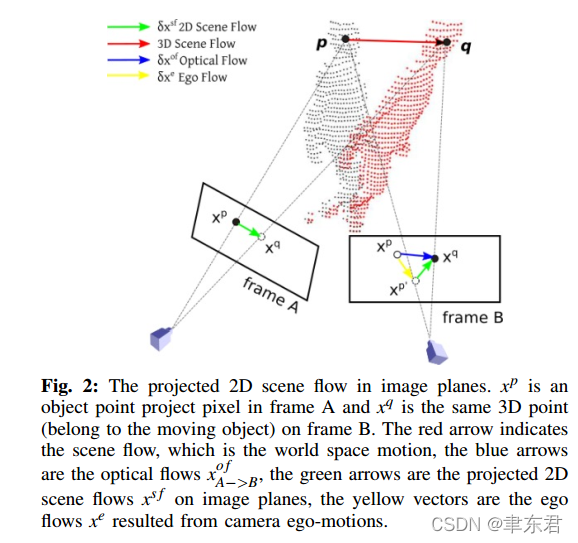
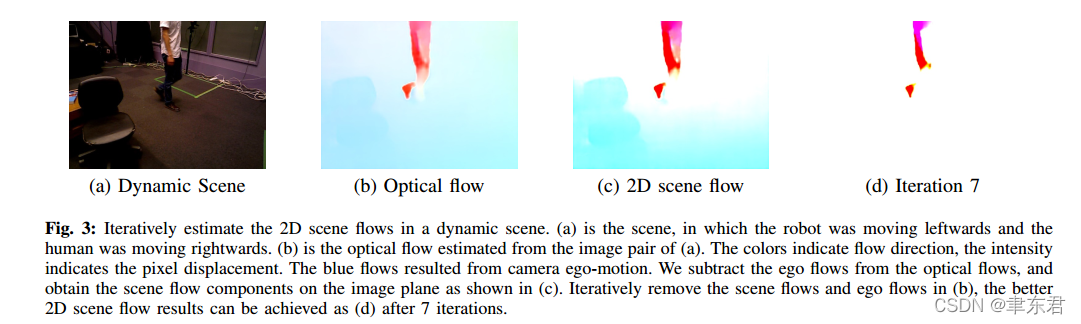
光流 Optical Flow
前后两张图片上所有像素的偏移。
场景流 Scene Flow
在世界坐标系中(也可以把前一帧作为世界坐标系),3D点的运动
2D 场景流 2D Scene Flow
场景流中3D点的运动在像素平面上的投影。
对于光流而已,其中同时包含了相机和动态对象的运动,而2D场景流只包含了动态对象的运动,通过将相机运动的运动分量从光流中删除,可以获得2D场景流。
【从位姿估计的角度讲,直接拿光流去计算动态对象的运动,出来的姿态变换同时包含了相机运动以及它自身的运动,还需要一个解耦的过程才能把相机运动从中去除。以VDO为例,是先计算相机运动,然后算出动态点在世界坐标系下的坐标,然后再计算动态对象在世界坐标系下的坐标,如果我们能够直接获得2D场景流,那么就可以直接从相机坐标中解耦,获得基于前一帧相机坐标系的动态对象变换。】
我们希望从聚类中找出动态的物体,如果有场景流当然是最好的,但是实际上最容易获得的是光流,因此我们需要从光流中删除相机运动分量,从而得到2D的场景流,也就得到动态物体的掩膜。
2D场景流 = 光流 - 相机运动流
δ
x
s
f
=
δ
x
o
f
−
δ
x
e
\delta x^{sf} = \delta x^{of} - \delta x^e
δxsf=δxof−δxe
光流误差
光流计算:
虽然有公式,但是实际上是用PWC-Net计算出来的。
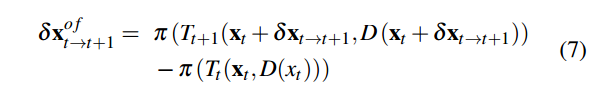
相机运动流计算:
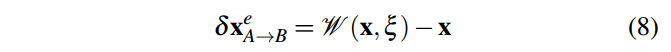
所以2D场景流为:
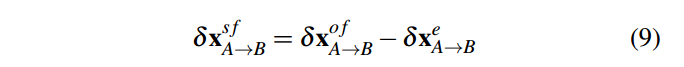
C. Dynamic Clusters Segmentation
把三类误差平均一下:
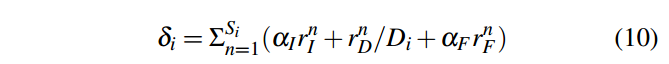
省略了…
IV. Dynamic SLAM Experiments and Evaluations
【在什么设备上,在什么数据集上,和什么对象,就什么指标进行了对比实验】
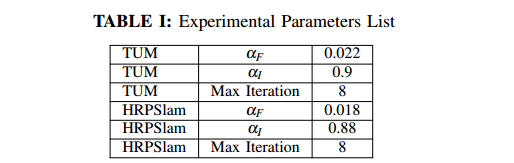
为了估计提出的FlowFusion的动态分割和稠密重建方法,我们再公开的TUM和HRPSlam数据集上比较FF和最先进的动态SLAM方法SF,JF和PF的VO和Mapping结果。为前者提供了被广泛接受的SLAM评估指标:ATE(Absolute Trajectory Error)和RPE(Relative Pose Error)。为了计算一个轨迹的ATE,首先用最小二乘法将它和Ground Truth对齐,然后直接比较在同个时间戳下估计的position和ground truth的距离。RPE是经过一个时间间隔的相对位姿误差。我们的实验是在一个带有Intel Xeon® CPU E5-1650 v4 @ 3.50 GHz x 8,64GiB 系统内存和双GeForce GTX 1080 Ti GPUs上实现的【真有钱】。FF的实验设定在Tab.I中给出。我们设置图像金字塔的层数为4层,每层两次迭代,这样全部的迭代次数就是8次。在对比实验中,我们采用了它们的默认参数。
【在哪些序列上进行,图表展示了什么对象的什么指标对比】
【不同序列,不同对象的指标不同,是因为什么(序列的原因+对象的特点)】
我们首先在TUM RGB-D动态序列 fr3/walking_xyz上评估提出的动态分割方法,其中包含了827张RGB-D图像,包含了两个移动的人类和轻微的物体运动(e.g.,椅子被人轻微地移动了)。Figure 4 展示理论JF,SF,PF和FF的动态分割表现。第一行是输入的RGB帧,其他行是每种方法的动态/静态的分割,最后一列展示了背景重建结果(除了JF,因为它们的开源版本没有提供重建功能)。Tab.II 和Tab.III展示了比较结果。 其中,在静态的序列
f
r
1
/
x
y
z
fr1/xyz
fr1/xyz和
f
r
1
/
d
e
s
k
2
fr1/desk2
fr1/desk2,这四种方法的VO表现是相似的,因为SF,PF和FF都是基于EF框架。EF是是用于静态局部区域或者(轻微动态)的重建的,因此在静态的序列中,这三种方法都收敛到EF的表现。

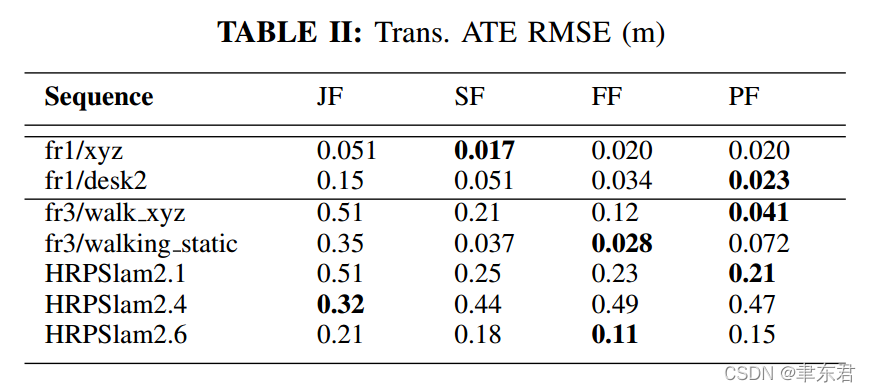
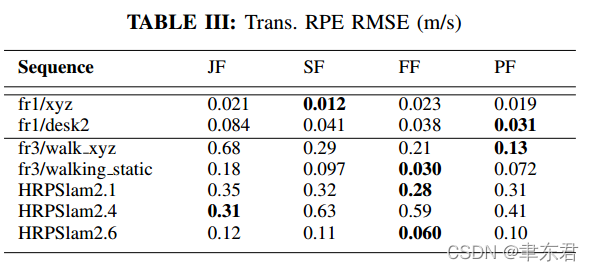
在高度动态的序列中,这四种方法展示了不同的优点和缺点(pros and cons)。我们先前的工作PF在只包含人类对象的场景中实现了很小的误差。依赖于基于深度学习的检测方法,PF同时检测动态和静态的人类对象,具有清晰的检测边缘(看Fig. 4中的第四行)。但是,PF的缺点是总是倾向于将与人类相接触的物体分割到前景(foreground),可以看到与人接近的椅子和桌子被错误分割了。并且,因为PF的物体检测前端OpenPose[21]对于某头的输入图片表现不是很好,所以PF在HRPSlam序列(因为在HRPSlam数据集中,相机是被安装在151cm高的人形机器人上的,不能很好地感知人脸)。JF和SF通过联合优化强度和深度能量函数来检测移动的物体,但是这些能量函数缺少动态属性,这会导致错误动态/静态分割(Fig.4中的第二和第三行)。因为提出的FF包含了光流误差,可以很好地体现像素的移动情况,FF在帧4和帧606实现了动态的物体提取,并且减少了帧184和帧506的错误静态背景分割。
Fig.5 中的图像描绘了fr3/walking_xyz序列的ATE和RPE。其中,PF实现了最小的轨迹误差。在不需要模型的动态SLAM方法中,FF比其他的表现得都要更好。PF实现非常小的轨迹达4.1cm,而FF则是12cm。
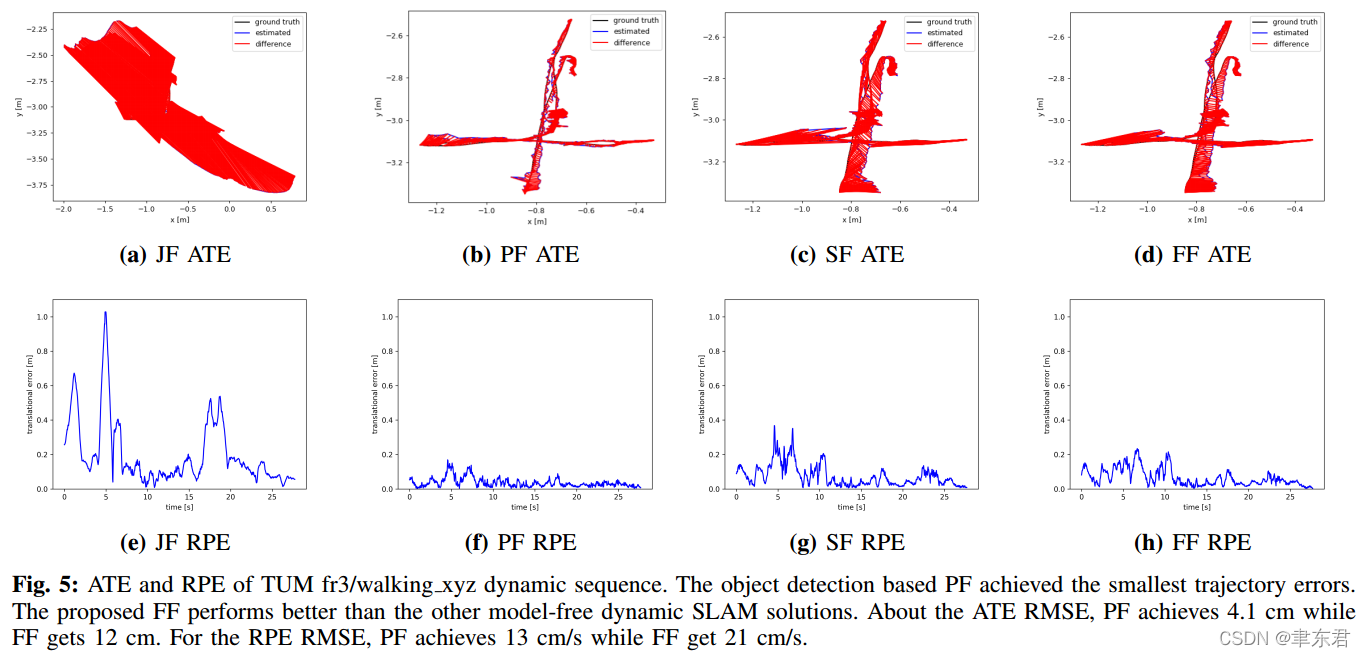
【这个JF真是笑死个人,全是红线,是被拉来凑数的模型吧,总得有一个表现最差的比较对象】
【总结一波】
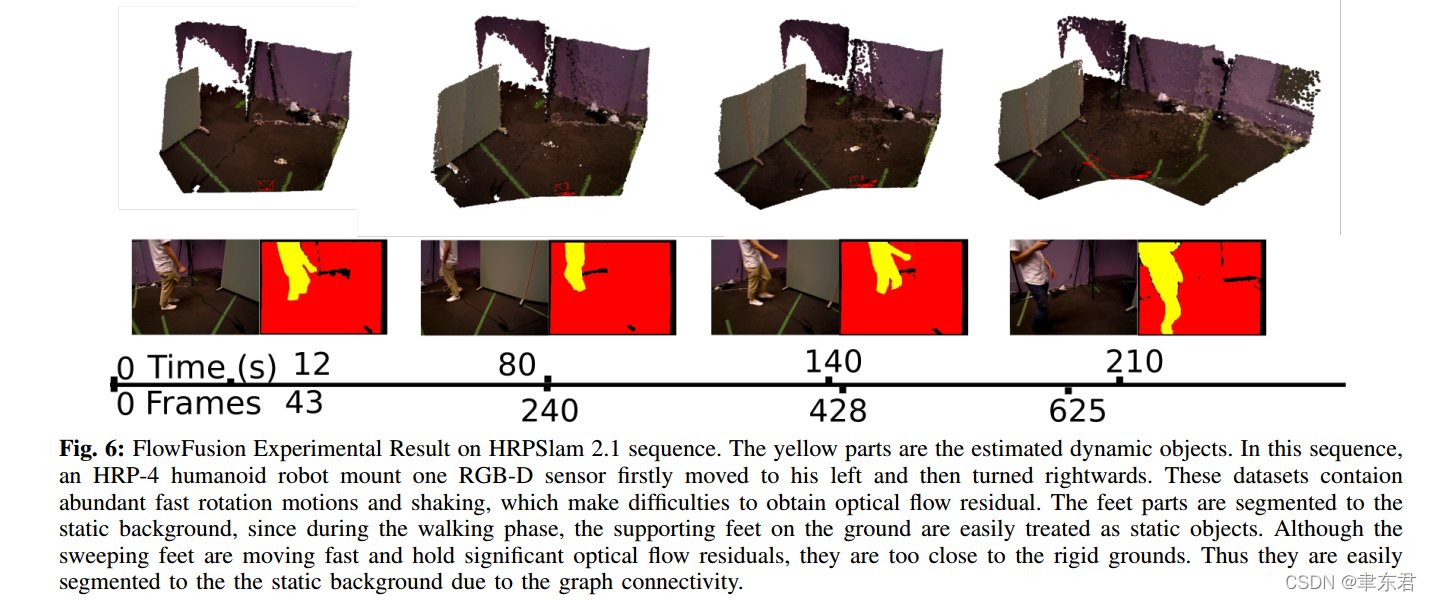
这些结果表明了提出的基于光流残差的静态/动态语义分割方法在RGB-D benchmarks中实现了高效的动态前景提取。类似于PF,FF在静态场景中表现得与EF差不多。FF的优势在于不依赖于物体模型。FF可以提取不同种类的移动物体,而PF只能提取人类对象。FF的劣势在于(和其他的model-free的方法一样,e.g.,SF,JF)对轻微的运动不敏感,或者非常快的运动,比如机器人倒下来【确实啊】。在Fig. 6中展示了非常快速的运动往往会导致错误的光流估计。
V. Conclusion
在这篇文章中,我们提供了一个新颖的稠密RGB-D SLAM算法可以解决动态分割和静态环境重建。本方法应用先进的稠密光流估计器,提供了动态分割和稠密融合功能,可以在精度和效率上增强动态分割表现。在线的数据集和实际机器人应用场景的呈现展示了在静态场景和动态场景中的竞争力。
总结点评
为了将动态物体从图像中分割出来,首先对整张图像利用直接法通过VO计算粗略的相机位姿。同时对整张图像进行聚类,并借助直接法优化后的误差,即光度误差和深度误差,再另外加上光流误差,对聚类的动态性进行判断,并将某些聚类进行融合。将动态对象进行分割后,再将纯静态的图像再次送入VO中计算更为准确的相机位姿。
通过PWC-Net可以获得光流估计,光流估计是由相机运动分量和2D场景流相加得到的,通过粗略的相机位姿我们可以获得相机运动分量,从而做差获得2D场景流。2D场景流反映了像素的动态性,我们将它称为光流误差。
直接法是进行动态物体追踪的好办法,可以利用非常多的点。
RGBD相机可以获得一个深度观测的约束。
相机位姿的多次计算,以及相机运动分量的计算显得比较笨拙,如果可以用网络替代会好很多。网络可以直接输出2D场景流和动态掩膜,但是它相比于语义分割的优势在哪儿呢?
光流分割最重要的是可以提供未知标签物体的分割,其他的还有提供光流估计,避免了动静判断的环节,从而减少将静态物体也分割出来。
语义分割尽管在边缘的地方表现更好,但是只能分割有标签物体,并静态物体也被分割出来,还有即便是有标签的物体也容易漏检(比如没脸的人)
并且对于SLAM而言准确的边缘分割的作用并不是太大,因为提取特征前通常会腐蚀一下边缘
不需要担心出来的代码指标不如语义分割,反正怎么着都可以找到理由来贬低语义分割,田忌赛马就是了。
另一个指的注意的点是,只分割动态物体有个专门的邻域是motion segmentation.
文献总结:
FlowFusion combines optical flow estimation and clustering methods to detect all kinds of dynamic objects, realizing accurate and efficinet ego-motion estimation and static background reconstructions. However, it requires a pre-estimation of ego-motion to transform the optical flow field to 2D scene flow field and furethermore update the ego-motion. It contains cumbersome【繁琐】procedures and consumes much time.

















 1371
1371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









