






原论文链接:https://arxiv.org/pdf/1911.05722.pdf
本文若有讲述错误或不妥之处,欢迎大佬在评论区纠正!
论文总览
论文详细解读
1. 相关名词解释
- contrastive learning(对比学习):设计方法生成无标签数据的正负样本对,同时通过设计前置任务(pretext task)与损失函数(loss function)学习正样本对的相似性与负样本对的差异性从而学习到通用的高级特征。
- pretext task:非实际需求任务,为contrastive learning而专门设计的任务,最著名的如instance discrimination(个体判别)
- 动量更新(momentum update):变量
在迭代更新时不仅依赖其他变量
的最新值,还依赖自身的上一时刻值,可以使得
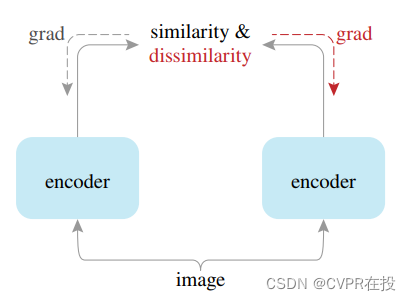
2. 对比学习基本架构
对比学习的基本架构主要包括两个并行的encoder,分别为 main encoder 和 auxiliary encoder(一般为相同架构,可以贡献参数也可以不共享)。其中 main encoder 接受原始数据的输入并将其投射到特征空间,auxiliary encoder 接受正负样本的输入并将其投射到特征空间,通过特定的损失函数刻画正样本对的相似性和负样本对的差异性。
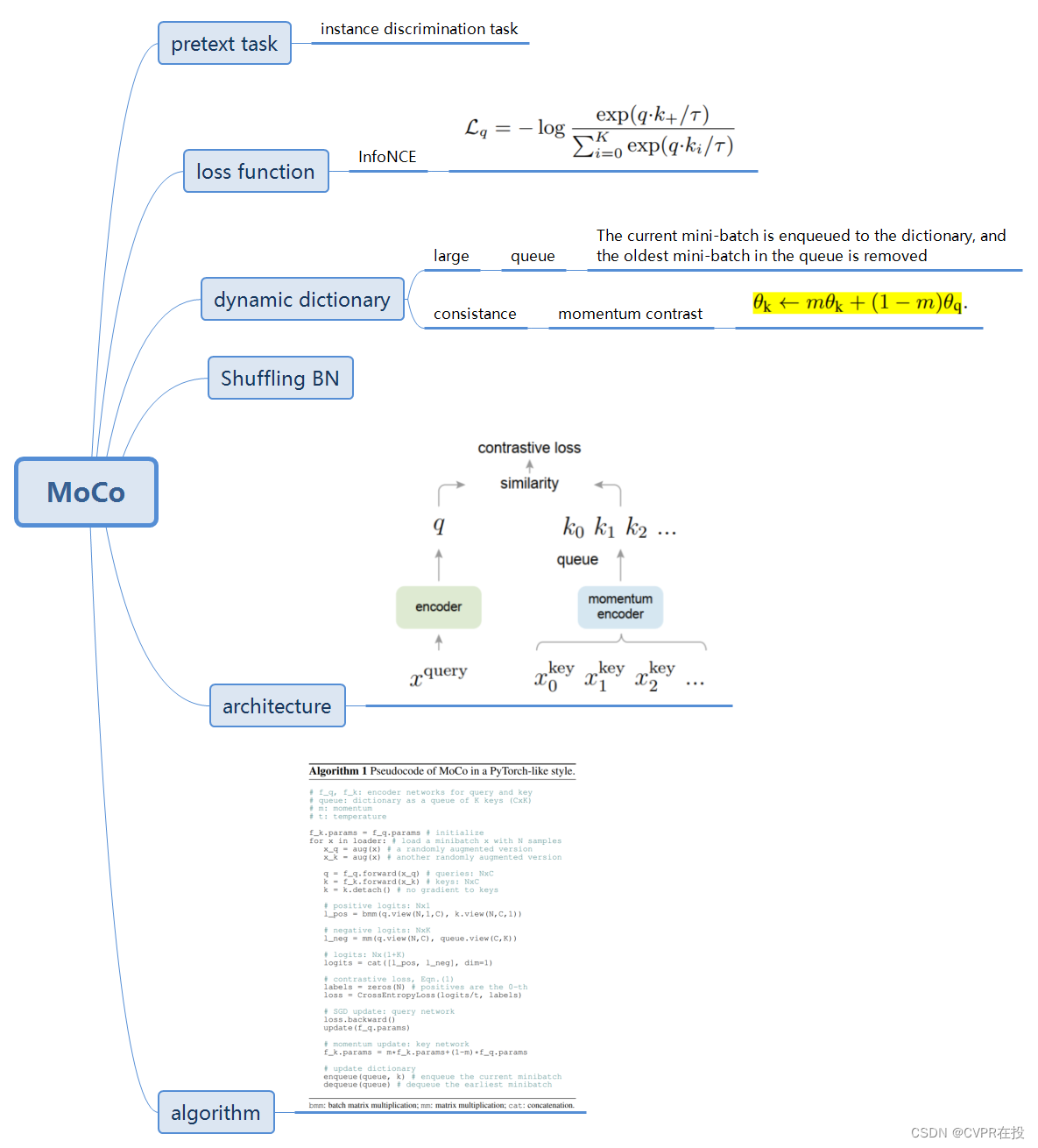
3. MoCo创新
通常来说,正样本通过相对应的数据进行 data augment 获得,而负样本则是除此之外的其他数据(包括其他数据的 data augment)。通常,训练时的负样本数量越多(指在一次step中),且它们的一致性越好(即由相同或相似的 encoder 编码)会使得 contrastive learning 效果更好,所以,MoC在这两方面进行了改进。
- 负样本数量更多:MoCo通过 queue 来储存之前的 mini-batch 的所有数据的特征(包括 data augment),同时通过将最早的 mini-batch 数据 dequeue,将最新的 mini-batch 数据 enqueue,这样便使得 queue 的大小与 mini-batch 解耦合,可以有足够多的负样本;同时,由于最早的 mini-batch 数据与当前的 mini-batch 数据最不一致(因为 encoder 变化最大),所以也可更好地保持一致性。
- 一致性更好:如果直接将所有的负样本进行 auxiliary encoder 的参数更新(BP算法),则会使得GPU的内存需要很大,同时不好优化,通过上述提到 动量更新 可以更好地保持一致性,所以MoCo决定 auxiliary encoder 不用 BP 算法更新,使用动量更新,具体格式如下:
4. MoCo伪代码

个人总结
MoCo不愧为 contrastive learning 的里程碑工作。它提出的两种改进工作都完美地同时改进了 负样本数量和一致性问题;同时 MoCo 也是一个通用架构可以嵌入不同的 encoder(CNN、transformer等)进行实验,kai ming 大佬真的太强了。

















 1510
1510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









