






1、pytorch的安装版本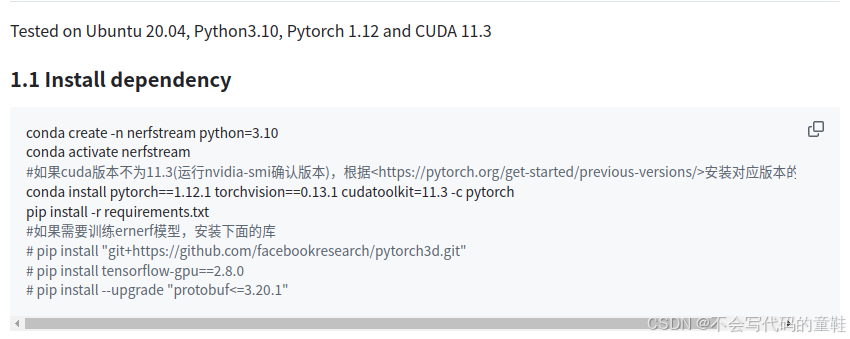
作者的cuda版本是11.4的,而代码作者的是11.3的,原则上来说按照作者的操作步骤是没有问题的。但是却会出现软件包版本不兼容等各种问题。pytorch版本跟原作者一样会导致和numpy冲突,而降低numpy又会导致和别的包冲突,具体和什么冲突作者忘了,具体表现在项目中就是向数字人发送文字,她不会读,只是傻傻的一直重复一个表情,控制台会报错。pytorch版本太高会导致无法使用gpu。
2、作者的操作方法
一、创建和激活环境
conda create -n nerfstream python=3.10
conda activate nerfstream二、安装pytorch 2.0.0,建议全程使用pip安装
pip install torch==2.0.0 torchvision==0.15.1 torchaudio==2.0.1 -i https://pypi.tuna.tsinghua.edu.cn/simplepytorch2.0.0既可以兼容numpy<2的版本,也可以支持cuda11.4
三、安装 requirements.txt指定的包
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple四、检查问题
作者开始不是按照这个步骤来的,只是后面不断试错解决的问题,但最后包的版本都是这些 。可以用命令conda list查看torch版本是否跟前面安装一致,不一致重新安装。再查看numpy版本是否为1.26.4,不是的话执行pip install numpy==1.26.4 -i https://pypi.tuna.tsinghua.edu.cn/simple



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









