






前言
最近刚看完陆宇杰翻译的《深度学习入门-基于Python的理论与实践》这本书,封面是一个鱼的那本,如果有感兴趣的朋友可以去可看一看,他会把一些晦涩难懂的的理论比拟成生活中很容易理解的例子,讲的比较通俗易懂。很适合入门。下面就一起看一下这本书大概讲了写什么内容。
第1章 Python入门?
• Python是一种简单易记的编程语言。
• Python是开源的,可以自由使用。
• 本书中使用Python 3.x实现深度学习。
• 本书中使用NumPy和Matplotlib这两种外部库。
• Python有“解释器”和“脚本文件”两种运行模式。
• Python能够将一系列处理集成为函数或类等模块。
• NumPy中有很多用于操作多维数组的便捷方法。
第2章 感知机
• 感知机是具有输入和输出的算法。给定一个输入后,将输出一个既定的值。
• 感知机将权重和偏置设定为参数。
• 使用感知机可以表示与门和或门等逻辑电路。
• 异或门无法通过单层感知机来表示。
• 使用2层感知机可以表示异或门。
• 单层感知机只能表示线性空间,而多层感知机可以表示非线性空间。
• 多层感知机(在理论上)可以表示计算机。
第3章 神经网络
• 神经网络中的激活函数使用平滑变化的sigmoid函数或ReLU函数。
• 通过巧妙地使用NumPy多维数组,可以高效地实现神经网络。
• 分类问题中,输出层的神经元的数量设置为要分类的类别数。
• 输入数据的集合称为批。通过以批为单位进行推理处理,能够实现高速的运算。
• 神经网络中使用的是平滑变化的sigmoid函数,而感知机中使用的是信号急剧变化的阶跃函数。
• sigmoid函数是一条曲线,阶跃函数是一条像阶梯一样的折线,两者都属于非线性的函数。
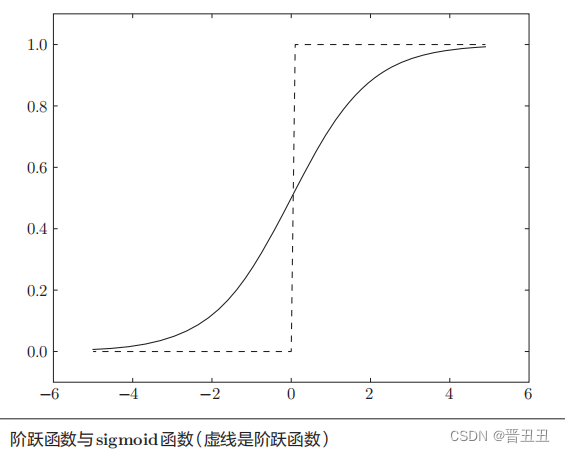
• 神经网络的激活函数必须使用非线性函数。换句话说,激活函数不能使用线性函数。为什么不能使用线性函数呢?因为使用线性函数的话,加深神经网络的层数就没有意义了。
• 介绍了作为激活函数的阶跃函数和sigmoid函数。在 神经网络发展的历史上,sigmoid函数很早就开始被使用了,而最近则主要使用ReLU(Rectified Linear Unit)函数。
• 神经网络可以用在分类问题和回归问题上,不过需要根据情况改变输出层的激活函数。一般而言,回归问题用恒等函数,分类问题用softmax函数。
• 机器学习的问题大致可以分为分类问题和回归问题。分类问题是数据属于哪一个类别的问题。而回归问题是根据某个输入预测一个(连续的)数值的问题。
第4章 神经网络的学习
• 常见的特征量(SIFT、SURF和HOG)–向量–分类器(机器学习中的SVM、KNN等)【特征量中人为干预,分类器中的机器学习没有人为介入】
• 神经网络/深度学习【没有人为介入】
• 深度学习有时也称为端到端机器学习(end-to-end machine learning)。这里所说的端到端是指从一端到另一端的意思,也就是从原始数据(输入)中获得目标结果(输出)的意思
• 训练数据也可以称为监督数据
• 泛化能力是指处理未被观察过的数据的能力。获得泛化能力是机器学习的最终目标。
• 损失函数可以使用任意函数, 但一般用均方误差和交叉熵误差等。
• 交叉熵误差的值是由正确解标签所对应的输出结果决定的。(两者成反比)
• 神经网络的学习分成下面4个步骤。
步骤1(mini-batch) 从训练数据中随机选出一部分数据,这部分数据称为mini-batch。我们的目标是减小mini-batch的损失函数的值。
步骤2(计算梯度) 为了减小mini-batch的损失函数的值,需要求出各个权重参数的梯度。梯度表示损失函数的值减小最多的方向。
步骤3(更新参数) 将权重参数沿梯度方向进行微小更新。
步骤4(重复) 重复步骤1、步骤2、步骤3。
• params 保存神经网络的参数的字典型变量(实例变量),保存 了权重参数。
• grads 保存梯度的字典型变量(numerical_gradient()方法的返回值)。
• 用误差反向传播法求到的梯度和数值微分的结果基本一致(都是求梯度),但差反向传播法可以高速地进行处理。数值微 分虽然简单,也容易实现,但缺点是计算上比较费时间。
• 神经网络学习的最初目标是掌握泛化能力。
• 过拟合是指,虽然训练数据中的数字图像能被正确辨别,但是不在训练数据中的数字图像却无法被识别的现象
• 神经网络学习的目标,为了找到尽可能小的损失函数值
• 机器学习中使用的数据集分为训练数据和测试数据。
• 神经网络用训练数据进行学习,并用测试数据评价学习到的模型的泛化能力。
• 神经网络的学习以损失函数为指标,更新权重参数,以使损失函数的值减小。
• 利用某个给定的微小值的差分求导数的过程,称为数值微分。
• 利用数值微分,可以计算权重参数的梯度。
• 数值微分虽然费时间,但是实现起来很简单。下一章中要实现的稍微复杂一些的误差反向传播法可以高速地计算梯度。
第5章 误差反向传播法
• 神经网络的正向传播+矩阵的乘积运算=放射变换
• 介绍了两种求梯度的方法。一种是基于数值微分的方法,另一种是解析性地求解数学式的方法。后一种方法通过使用误差反向传播法,即使存在大量的参数,也可以高效地计算梯度。
•通过使用计算图,可以直观地把握计算过程。
• 计算图的节点是由局部计算构成的。局部计算构成全局计算。
• 计算图的正向传播进行一般的计算。通过计算图的反向传播,可以计算各个节点的导数。
• 通过将神经网络的组成元素实现为层,可以高效地计算梯度(反向传播法)。
• 通过比较数值微分和误差反向传播法的结果,可以确认误差反向传播法的实现是否正确(梯度确认)。
第6章 与学习相关的技巧
• 参数的更新方法,除了SGD之外,还有Momentum、AdaGrad、Adam等方法。
• 权重初始值的赋值方法对进行正确的学习非常重要。
• 作为权重初始值,Xavier初始值、He初始值等比较有效。
• 通过使用Batch Normalization,可以加速学习,并且对初始值变得 健壮。
• 抑制过拟合的正则化技术有权值衰减、Dropout等。
• 逐渐缩小“好值”存在的范围是搜索超参数的一个有效方法。
第7章 卷积神经网络
• 和“现在的CNN”相比,LeNet有几个不同点。第一个不同点在于激活函数。
LeNet中使用sigmoid函数,而现在的CNN中主要使用ReLU函数。
此外,原始的LeNet中使用子采样缩小中间数据的大小,而现在的CNN中Max池化是主流。
• CNN在此前的全连接层的网络中新增了卷积层和池化层。
• 使用im2col函数可以简单、高效地实现卷积层和池化层。
• 通过CNN的可视化,可知随着层次变深,提取的信息愈加高级。
• LeNet和AlexNet是CNN的代表性网络。
• 在深度学习的发展中,大数据和GPU做出了很大的贡献。
第8章 深度学习
• 深度学习是加深了层的深度神经网络
• VGG是由卷积层和池化层构成的基础的CNN。它的特点在于将有权重的层(卷积层或者全连接层)叠加至16层(或者19层), 具备了深度(根据层的深度,有时也称为“VGG16”或“VGG19”)。
• GoogLeNet的特征是,网络不仅 在纵向上有深度,在横向上也有深度(广度)
• ResNet它的特征在于具有比以前的网络更深的结构。
• 迁移学习在手头数据集较少时非常有效。把学习完的权重作为初始值,以新数据集为对象,进 行再学习。
• 全连接层可以替换成进行相同处理的卷积层。
• 对于大多数的问题,都可以期待通过加深网络来提高性能。
• 在最近的图像识别大赛ILSVRC中,基于深度学习的方法独占鳌头,使用的网络也在深化。
• VGG、GoogLeNet、ResNet等是几个著名的网络。
• 基于GPU、分布式学习、位数精度的缩减,可以实现深度学习的高速化。
• 深度学习(神经网络)不仅可以用于物体识别,还可以用于物体检测、 图像分割。
• 深度学习的应用包括图像标题的生成、图像的生成、强化学习等。最近, 深度学习在自动驾驶上的应用也备受期待。
总结
以上就是这本鱼书的一些主要内容啦,大部分内容都是搬运过来的,为了方便自己后期回顾复习,如果对你有所帮助那么我觉得这件事情“泰裤辣”。最后,送大家一句话,不闻不若闻之,闻之不若见之,见之不若知之,知之不若行之。















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









