






如果说对比目前的Midjourney和Stable Diffusion,能否让AI能根据我们的意愿进行调整就是一个很大的区别。就这一点来看,StableDiffusion拥有了更大的自由度和更稳定的可控性。
我这里整理好了需要用到的大模型以及插件,需要的小伙伴直接扫码获取
今天,我们再更深入地了解一下图生图中的“局部重绘”。首先,使用大模型“lofi”绘制一个人物形象。前几期我们都是使用的卡通模型,这一次使用的这款是一个写实类模型,可以看到人物非常逼真,丝毫不亚于相机所拍的照片。在提示词中加入了关于相机的一些标准化提示词——佳能EOSR6拍摄,135mm, 1/1250, f/2.8, ISO400。然后还使用了一个负面Embedding——NG_DeepNegative_V1_75T,这个Embedding是专门用来修复写实人物的手部、姿态等细节问题的。

接下来,我们把这张图发送到图生图,点击“局部重绘”。
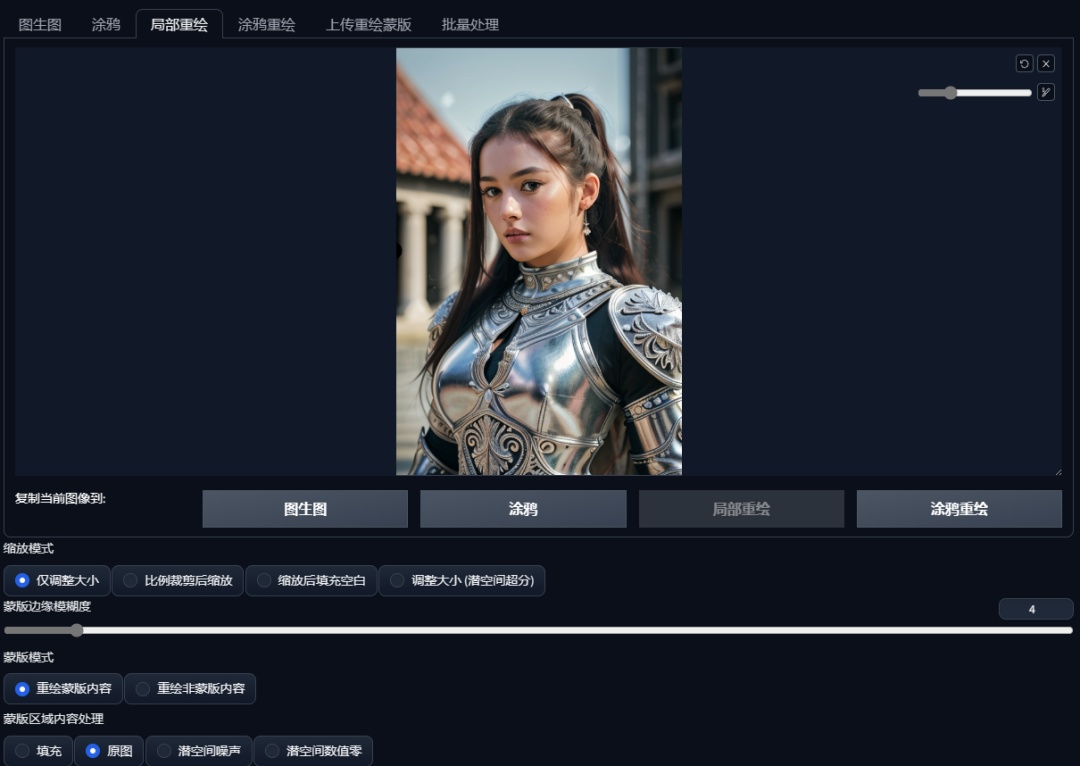
比如,我们可以试着让人物闭上眼睛。可以先用画笔将人物需要调整的部分涂上,这个区域又可以称为蒙版。

接下来,在正向提示词里面添加(closed eyes:1.2),括号和数字都是增加权重用的,告诉AI我们需要一双闭上的眼睛。

可以适当增加一些重绘幅度,点击生成,闭上眼睛的样子就改好了。

它的原理就是将蒙住的部分重新画,你也可以将没有蒙住的部分重新画,比如你可以把人物蒙住之后,重画她的背景。
更进阶的用法,我们可以进入涂鸦重绘,用颜色画笔画任意你想添加的东西,比如在她的头顶加上一朵小黄花。

添加关键词(Yellow flowers:1.2),点击生成,图片就像神笔马良一样生出了一朵花。

如果我们想让这张照片变成横的,就需要扩展它的背景,可以在图生图中选择“缩放后填充空白”,重绘幅度0.5,并将宽度从512增加到1200。
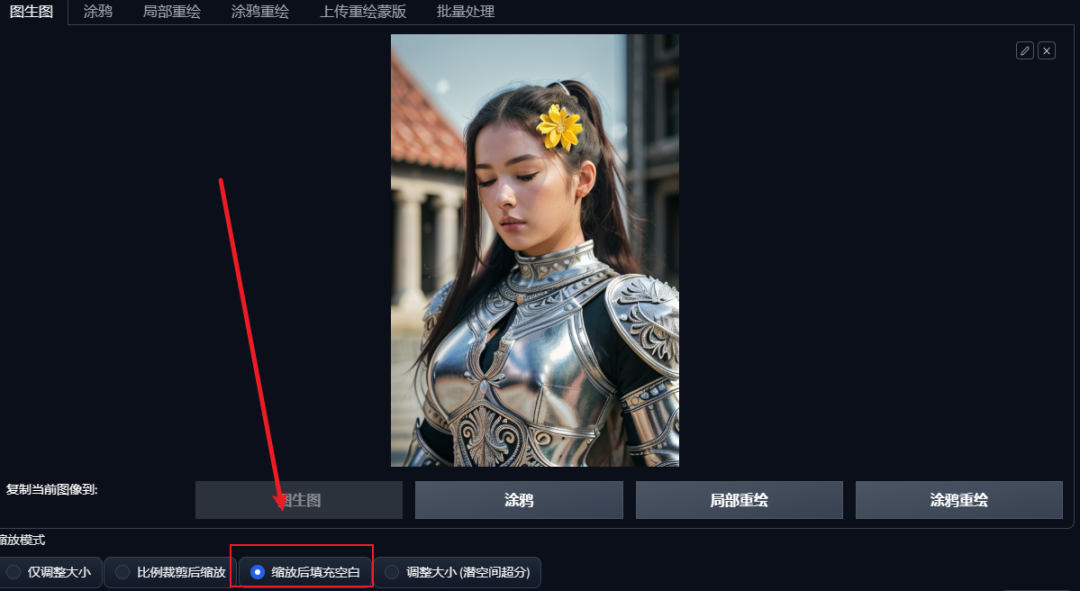

生成后不仅对背景做了补充,甚至还将人物进行了补全,但是背景拉伸的重复度太高,这时可以适当增加重绘幅度。

当重绘幅度为0.58的时候,背景已经比较正常了。但是随着重绘幅度的增大,可以看见人物的细节也产生了一定的改变。有什么办法可以既不改变人物,又能修改背景呢?

这里就需要用到一点PS的帮助了,我们保存这张图进入PS,对主体人物抠像。点击选择-主体,可以得到这个人物的选区。
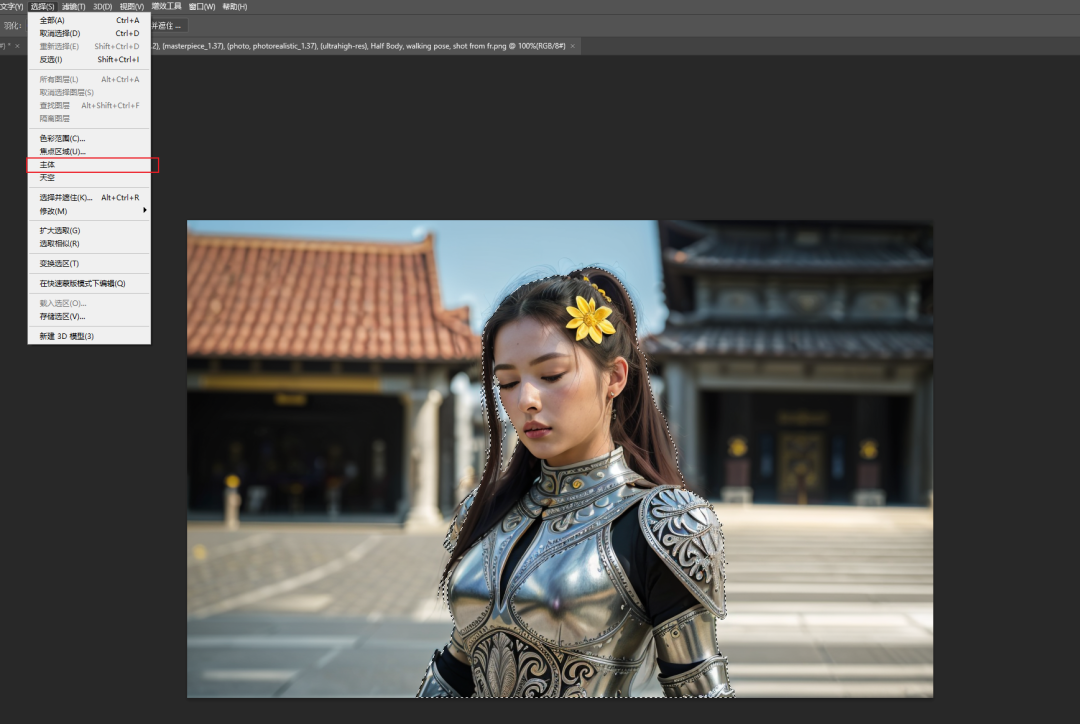
对选区填充白色,对背景填充黑色,就可以得到这个人物形象的精确蒙版。

我们进入“上传重绘蒙版”的界面,上面放置需要重绘的图像,下面放置PS中制作好的蒙版。
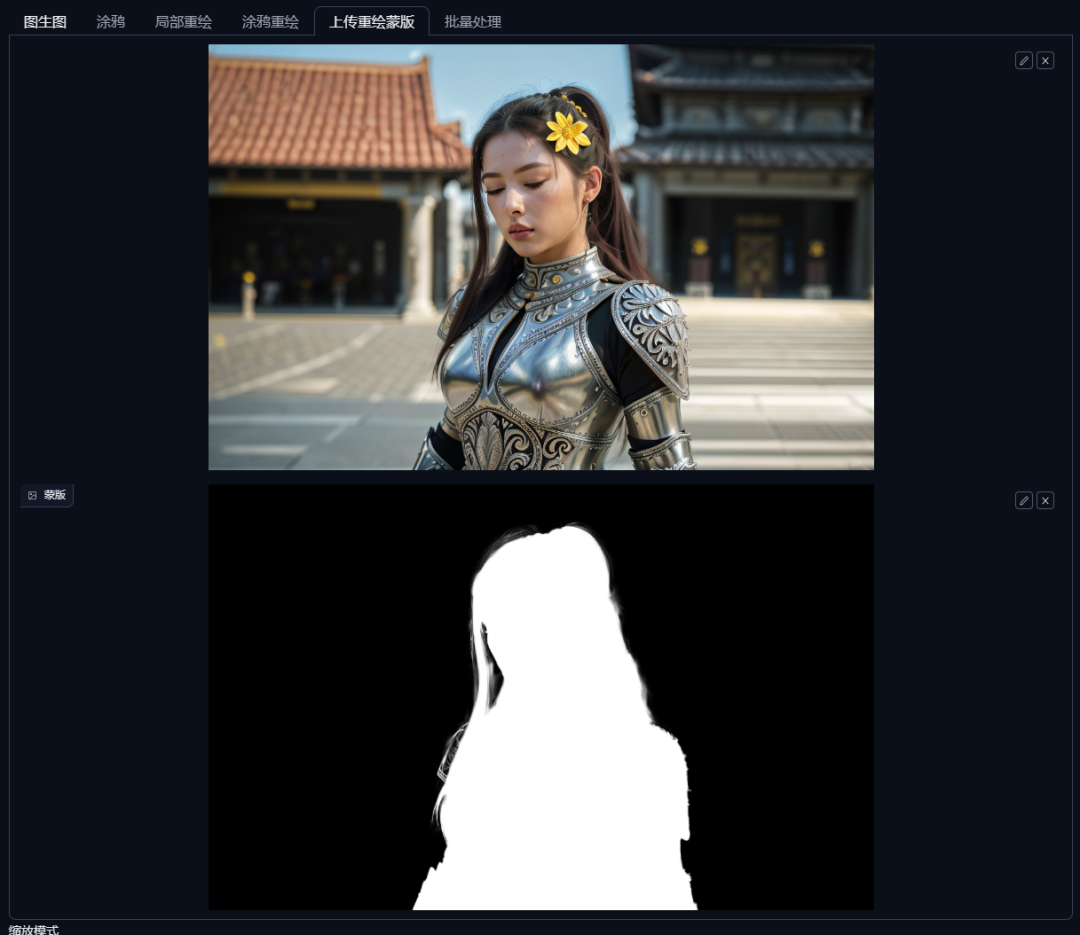
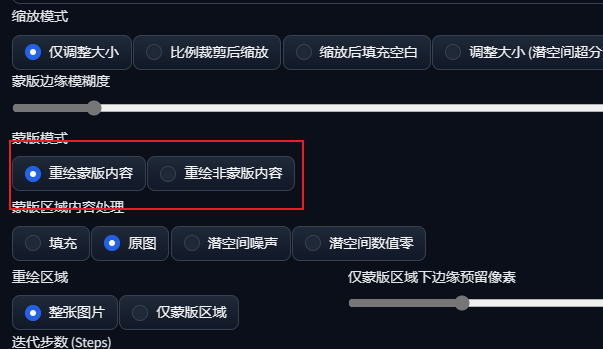
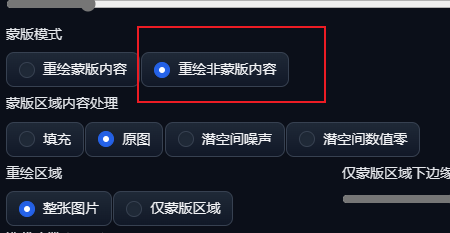
在Stable Diffusion中,蒙版的白色区域是默认重绘的区域,如果只想改变背景的话,可以切换到“重绘非蒙版区域”。
将提示词调整为铺满了鲜花的场景:detailed background filled with (many:1.1) (colorful:1.1)
(flowers):1.1, (quality:1.1), (photorealistic:1.1), (resolution:1.1),
(sharpness:1.1), (cinematic lighting), depth of field, Canan EOS R6, 135mm,
1/1250s, f/2.8, ISO 400。
重绘幅度拉高到0.9,点击生成。可以看到,人物原封不动,而场景产生了大变化,成为了一片花海。

最后,再使用之前讲过的SD放大功能,可以翻看我之前的文章。

从这个例子中,我们可以看到StableDiffusion对绘图的控制能力,绝不仅仅是人们印象中的看天吃饭,随机抽卡。再加上它还有lora,contronet等一众神器的加持,可以说,StableDiffusion就是目前市面上最听话的AI绘图软件。
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!


















 1692
1692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









