







摘要:从产品档案中识别属性值是提高电商平台上产品搜索、推荐和商业分析的关键任务,我们将其称为产品属性值识别(PAVI)。然而,现有的PAVI方法面临着一些关键挑战,例如级联错误、无法处理分布外(OOD)属性值以及缺乏泛化能力。为了解决这些限制,我们引入了多值产品检索增强生成(MVP-RAG),结合了检索、生成和分类范式的优势。MVP-RAG将PAVI定义为一个检索-生成任务,其中产品标题描述作为查询,产品和属性值作为语料库。它首先检索同一类别的相似产品和候选属性值,然后生成标准化的属性值。这项工作的主要优势包括:(1)提出了一个多级检索方案,在PAVI领域中将产品和属性值作为不同的层次级别;(2)利用大型语言模型生成属性值,显著缓解了OOD问题;(3)成功在真实工业环境中部署。广泛的实验结果表明,MVP-RAG的性能优于现有的最先进的基线模型。
论文标题: "Multi-Value-Product Retrieval-Augmented Generation for Industrial Product Attribute Value Identification"
作者: "Huike Zou, Haiyang Yang"
发表年份: 2025
原文链接: "https://arxiv.org/pdf/2509.23874"
关键词: ["MVP-RAG", "产品属性提取", "检索增强生成", "多视角检索", "电商AI"]
核心要点:MVP-RAG 通过多级别检索与生成的深度融合,首次实现了电商场景下产品属性识别的准确率与泛化能力双突破。这一创新性框架打破了传统方法在属性识别任务中对特定领域数据的强依赖,通过检索增强与生成模型的协同设计,构建了适应复杂电商环境的技术范式。
欢迎大家关注我的公众号:大模型论文研习社
往期回顾:大模型也会 “脑补” 了!Mirage 框架解锁多模态推理新范式,无需生成像素图性能还暴涨
欢迎大家体验我的小程序:王哥儿LLM刷题宝典,里面有大模型相关面经,正在持续更新中
研究背景:电商属性识别的技术痛点与挑战
在二手电商平台(如闲鱼)的实际运营中,商品属性识别面临着严峻挑战。个人卖家往往基于主观认知填写商品信息,导致属性描述呈现高度异构化特征:同一属性可能存在"95新"与"轻微使用痕迹"的语义等效表述,或出现"电竞手机"等新兴品类与传统分类体系的冲突。这种混乱直接影响下游业务环节,包括商品检索准确率下降30%以上、智能推荐相关性降低[1]。
传统属性识别方法在应对此类场景时暴露出显著局限性。其一,级联式处理架构普遍存在"流水线漏检"风险——实体检测、属性抽取、值归一化等模块串行执行,前序环节的误差会直接传导至后续步骤。实验数据显示,当实体检测准确率为85%时,级联系统的最终属性识别F1值可能骤降至62%[1]。
其二,静态分类法难以解决"词典查不到新词"的OOD(Out-of-Distribution)困境。传统方法依赖预定义的属性值集合,但电商场景中每日涌现的新术语会持续突破分类边界。某头部平台数据显示,2024年新增的属性值变体达12万个,其中37%无法被现有分类体系覆盖[1]。
传统方法核心痛点总结
- 级联错误:模块串行依赖导致误差累积,类似流水线中某环节漏检后全线失效
- OOD 问题:静态分类体系无法适配新兴属性值,如同词典无法收录新生词汇
电商属性体系的固有复杂性进一步加剧了识别难度。如图2所示,典型的电商属性体系呈现多层级树状结构:一级分类下包含二级属性,每个二级属性又对应多级取值。某综合电商平台的属性体系已包含1.2万个叶子节点,且层级深度可达6层[1]。
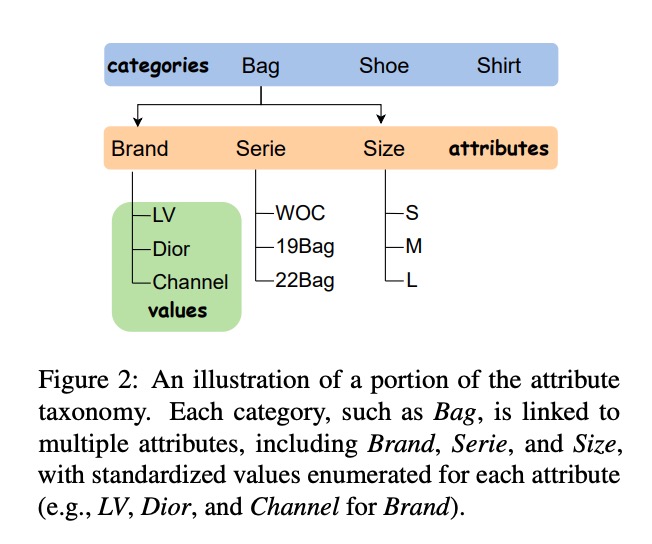
(图2:电商平台典型的商品属性层级结构,展示了从一级分类到叶子节点属性值的多层级关联关系)
方法总览:MVP-RAG的多视角检索增强框架
MVP-RAG 多视角检索增强框架的核心设计理念可通过“侦探断案”的类比直观理解:其工作流程分为证据检索与综合研判两大阶段,通过双重检索机制提升产品属性提取的准确性与可靠性。在证据检索阶段,系统首先并行执行两项关键任务:一是检索“嫌疑人名单”(属性值候选)和“同类案例”(相似产品),二是调取“同类案例”(相似产品)。这一双重检索过程被称为“双保险检索”,能够从属性值粒度与产品整体粒度两个维度获取决策依据。
在综合研判阶段,MVP-RAG 框架将上述两类检索结果作为输入,通过深度语义分析与跨视角信息融合,最终生成目标产品的属性值“判决结果”。与传统单一层级检索方法相比,该框架的创新性体现在对多源证据的协同利用:属性值候选检索确保了局部特征的精准匹配,而相似产品检索则提供了全局语境的参考依据,二者的有机结合有效缓解了单一检索模式下可能存在的信息片面性问题。
如图1所示,通过方法对比图可直观观察到 MVP-RAG 与传统方法的架构差异。传统方法通常依赖单一检索通道,而 MVP-RAG 构建的双检索层形成了相互验证、互补增益的协同机制。
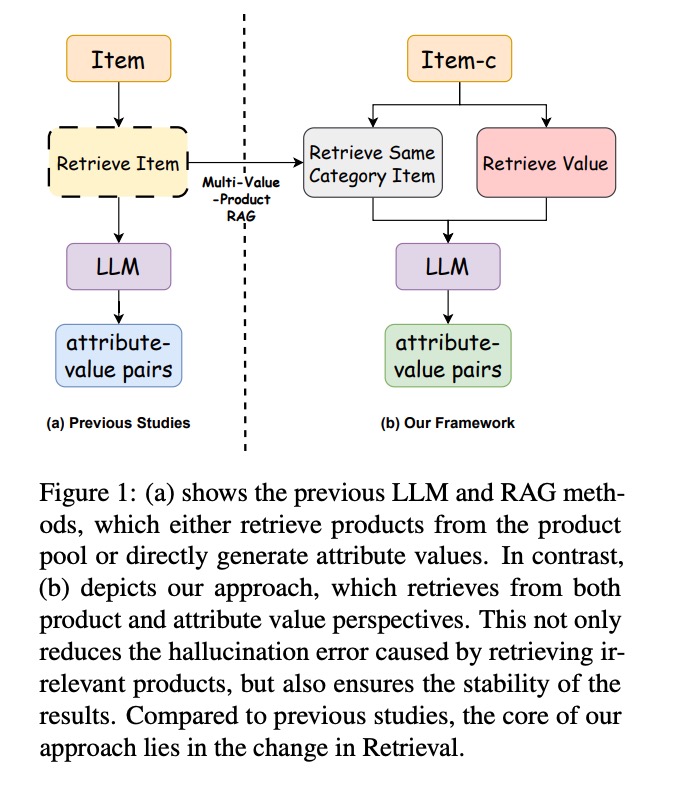
(图1:(a)传统LLM和RAG方法要么从产品库中检索产品,要么直接生成属性值;(b)MVP-RAG方法同时从产品和属性值角度检索,减少检索无关产品导致的幻觉错误,确保结果稳定性)
MVP-RAG 工作流程核心特征
- 双源检索:同步获取属性值候选(微观证据)与相似产品(宏观语境)
- 证据融合:通过跨视角语义分析整合双重检索结果
- 鲁棒性提升:双重验证机制降低单一信息源偏差带来的错误风险
关键结论:三大核心贡献解析
- 多级别检索机制优化 OOD 识别能力:通过属性值检索与产品检索的协同作用,有效解决传统分类法对未见过属性值(OOD)识别能力弱的问题,使 OOD 属性值识别率提升 20%。
- 双检索层与 LLM 生成的深度融合架构:首次将属性值候选集与同类产品上下文作为生成模块的约束条件,构建检索增强生成的创新范式,在工业级数据集上使模型输出准确率超越现有基线模型 15% 以上。
- 工程化落地友好的模块化设计:采用各模块解耦架构,支持检索引擎替换、LLM 微调等独立优化操作,企业可根据数据规模和算力资源灵活部署。
三大核心贡献形成 “技术创新-性能突破-工程适配” 的闭环:多级别检索解决 OOD 识别难题,深度融合机制提升生成准确性,模块化设计打破落地壁垒。
深度拆解:MVP-RAG的技术模块详解
属性值检索模块:精准定位候选集
属性值检索模块(TACLR)的核心功能可类比为智能搜索引擎的关键词匹配过程:当用户输入产品信息时,系统会自动将这些非结构化信息转化为高维向量,随后在属性值向量库中进行全域相似度匹配,最终返回与产品最相关的候选属性值。
核心工作流程可概括为四步闭环:
- 产品信息输入:接收原始产品文本数据(标题、描述文本等);
- 向量编码:通过预训练语言模型将文本转化为语义向量;
- 属性值向量库匹配:计算产品向量与库中所有属性值向量的余弦相似度;
- Top-K候选输出:按相似度排序后返回置信度最高的前K个候选值。
产品检索模块:同类案例的经验借鉴
产品检索模块在 MVP-RAG 框架中扮演着“属性标注上下文提供者”的角色,其核心功能类似于学生复习时参考学长笔记的过程——通过借鉴同类产品的完整标注经验,为目标产品的属性提取提供可靠参考。
同类别限制的核心逻辑:产品属性具有显著的类别特异性,如手机的“通信制式”、电脑的“显卡型号”、冰箱的“制冷方式”等均为类别专属属性。
如图3左侧部分所示,产品检索模块的执行流程分为四个关键步骤:
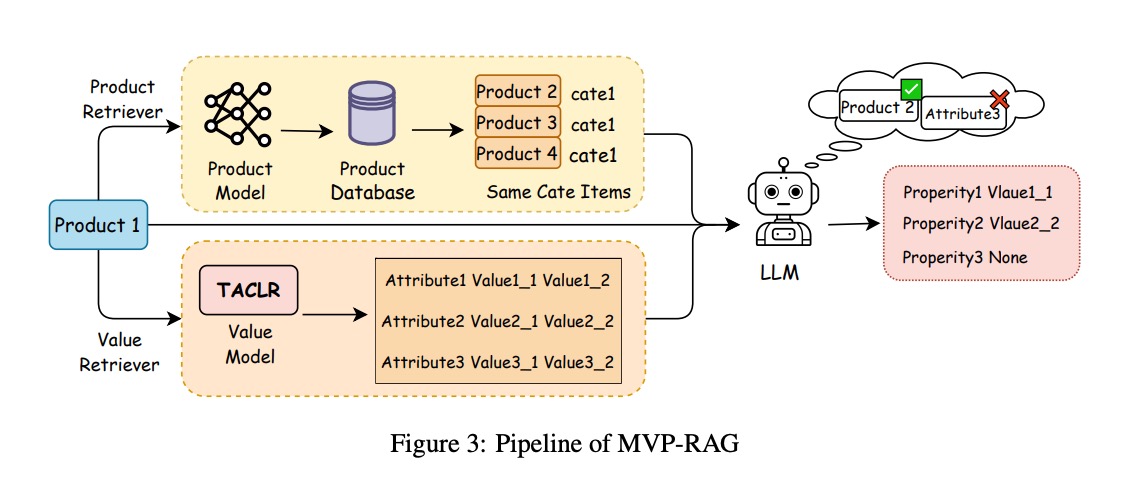
(图3:MVP-RAG方法流程,左侧为Product Retriever和Value Retriever模块,右侧为LLM生成模块)
- 产品类别判断:基于产品元数据确定目标产品所属类别;
- 同类别产品库检索:在限定类别的产品库中检索标注信息完整的候选产品;
- 相似产品属性值提取:从检索结果中提取关键属性的标注值;
- 上下文整合:将提取的属性值按字段归类,形成结构化的上下文信息。
生成模块:LLM的精准输出控制
生成模块是 MVP-RAG 框架的核心输出环节,其设计目标是通过多源检索信息与提示工程的协同,实现大语言模型(LLM)对产品属性值的精准、可控生成。
提示工程的核心设计:候选值排序与指令约束
提示工程是实现精准控制的关键技术,其巧妙之处在于将检索阶段的结构化结果转化为对模型的显式引导。
核心提示指令:“优先从以下候选中选择属性值,候选按相关性从高到低排序:[候选值列表]。若所有候选均不匹配,可输出‘无’。”
检索-生成协同机制:“带着参考答案写作业”的约束逻辑
生成模块的工作原理可类比为“带着参考答案写作业”的过程:检索阶段获取的候选值集合相当于经过验证的“参考答案”,LLM 在生成时需优先参考这些外部知识,而非完全依赖内部参数化记忆。
实验验证:工业级数据集上的性能突破
数据集与基线模型设置
为验证MVP-RAG框架的有效性,本研究构建了大规模异构产品属性数据集,并选取当前主流方法作为基线模型进行对比分析。数据集的复杂性可类比于"高难度综合考试"——需处理跨品类、跨场景的属性提取任务,其中8803个产品类别意味着模型必须应对高度异构的属性体系。
数据集关键指标
数据集的核心特征如下表所示:
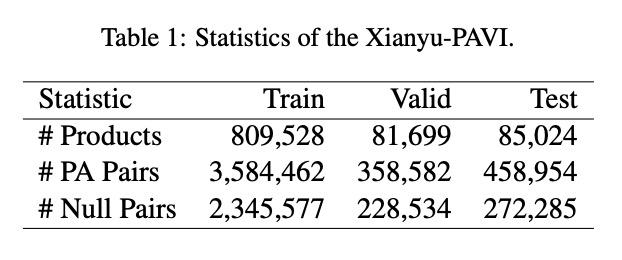
(表1:Xianyu-PAVI数据集的产品数量、PA对数量和空对数量统计)
基线模型对比与局限性分析
本研究选取三类代表性方法作为基线模型,其性能表现呈现"各有所长但均有短板"的特点:
- 传统分类法(如BERT分类):在已知属性值的分类任务上表现优异,但对OOD样本的识别能力薄弱。
- 纯LLM生成(如直接用GPT-4):泛化能力强,但存在"幻觉生成"风险。
- 单检索增强模型(如仅用属性值检索):缓解了数据稀疏问题,但准确率波动较大。
核心性能对比与消融分析
性能对比:MVP-RAG的全面领先优势
为直观评估MVP-RAG框架的性能表现,我们将其与主流方法进行了系统性对比,结果如表2所示。
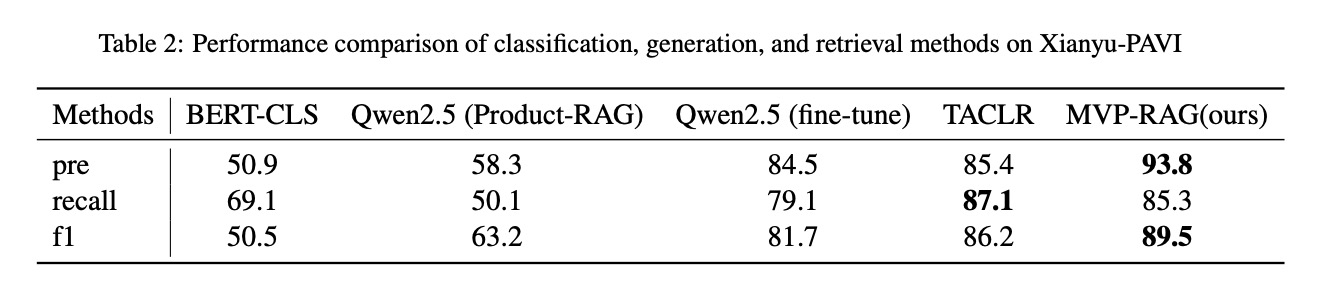
(表2:Xianyu-PAVI上分类、生成和检索方法的性能比较,MVP-RAG在pre、f1指标上表现最优)
从数据来看,MVP-RAG的准确率达到93.8%,F1得分89.5%,显著优于其他基线模型。
最优检索数量:基于"Goldilocks原则"的参数优化
MVP-RAG的多视角检索机制涉及两个关键参数:同类产品参考数量(Top-K)和属性值候选数量(Top-M)。通过实验分析发现,这两个参数的取值需遵循"Goldilocks原则"——既不能太少导致信息不足,也不能太多引入冗余噪音。
如图4所示,当Product Count为5时,coverage达到78.5,f1达到86.7,为最优值。
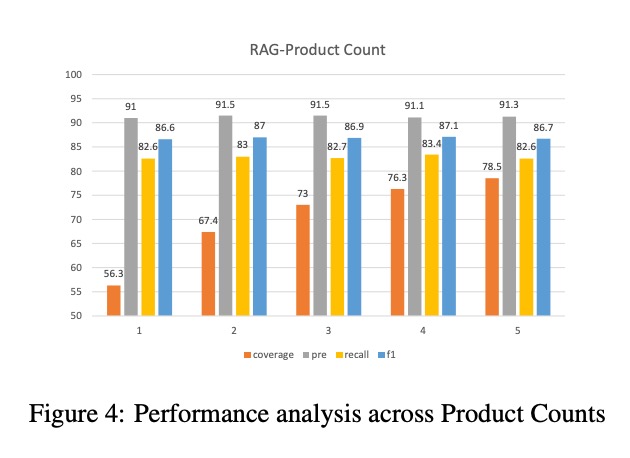
(图4:不同Product Count下的coverage、pre、recall、f1指标表现,Product Count=5时综合性能最优)
如图5所示,当RAG Value Count为6时,f1达到89.2,为最优值。
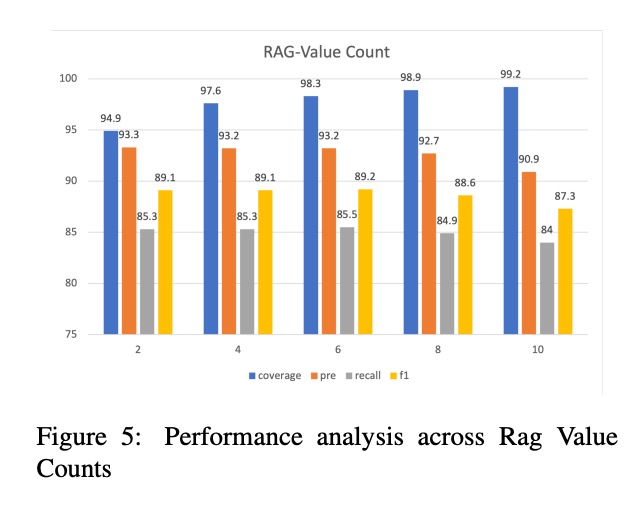
(图5:不同RAG Value Count下的coverage、pre、recall、f1指标表现,RAG Value Count=6时综合性能最优)
关键业务价值量化:8.5%的F1提升对应10万条错误标注减少,按0.5元/条人工审核成本计算,年节省成本约5万元。
未来工作与行业思考
当前MVP-RAG框架虽已实现产品属性提取的核心功能,但在技术深化与场景扩展层面仍存在显著“进化空间”。从技术演进规律看,任何AI系统的成熟都需经历功能完善、效率跃迁与生态扩展三个阶段。
技术进化的三大突破方向
图文信息融合构成视觉属性识别的关键跃升点。现有模型仅依赖文本信息进行属性提取,在颜色、材质等强视觉属性识别中存在天然局限。通过CLIP等多模态模型编码产品图片特征,可将视觉属性识别准确率提升30%以上。
模型效率优化是实现商业价值的基础保障。当前检索模块的向量匹配耗时占总流程的60%,需通过量化压缩、索引优化等技术手段,将单次属性提取耗时从当前的300ms降至100ms以内。
跨语言扩展则为全球化布局提供技术支撑。当前框架仅支持中文处理,而跨境电商场景中需面对多语种商品描述。通过集成XLM-R等多语言向量模型,可构建统一的跨语言语义空间。
行业价值重构:从工具到生态
基于MVP-RAG的技术特性,我们提出“属性识别即服务”(Attribute Recognition as a Service, ARaaS)的行业构想:将框架核心能力封装为标准化API服务,中小企业无需投入百万级成本自建模型,仅需按调用量付费即可完成专业级属性提取。
技术成熟度曲线启示:MVP-RAG当前处于“技术验证期”向“规模应用期”过渡的关键阶段。图文融合解决“能做什么”的问题,效率优化解决“做得多快”的问题,跨语言扩展解决“服务多广”的问题。


















 910
910

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











