






刚接触强化学习,在b站上看到一个up主实现的简单的Q-learning小车爬山,代码学习笔记如下,资料来源在文末。
up讲解更为详细,笔记更多留作自用^^
import gym
import numpy as np
env = gym.make("MountainCar-v0")
# Q-Learning settings
LEARNING_RATE = 0.1
DISCOUNT = 0.95
EPISODES = 25000
SHOW_EVERY = 1000^使用gym中的MountainCar-v0环境
设置学习率,折扣因子,迭代轮次(一个轮次指一次爬山的尝试,结束的标志是到达目标或者次数到达上限),展示频率(每1000轮次展示一次)
# Exploration settings
epsilon = 1 # not a constant, qoing to be decayed
START_EPSILON_DECAYING = 1
END_EPSILON_DECAYING = EPISODES//2
epsilon_decay_value = epsilon/(END_EPSILON_DECAYING - START_EPSILON_DECAYING)^epsilon是随机程度的指标(后文会用到)
epsilon_decay_value是每个大循环epsilon衰减的值(常值,可自己修改)
DISCRETE_OS_SIZE = [20, 20]
discrete_os_win_size = (env.observation_space.high - env.observation_space.low)/DISCRETE_OS_SIZE
def get_discrete_state(state):
discrete_state = (state - env.observation_space.low)/discrete_os_win_size
return tuple(discrete_state.astype(np.int64)) # we use this tuple to look up the 3 Q values for the available actions in the q-table^将连续状态离散化,将横向纵向分别分成20块
q_table = np.random.uniform(low=-2, high=0, size=(DISCRETE_OS_SIZE + [env.action_space.n]))
for episode in range(EPISODES):
state = env.reset()
discrete_state = get_discrete_state(state)
if episode % SHOW_EVERY == 0:
render = True
print(episode)
else:
render = False
done = False^初始化Q值表
每个轮次中,重置状态
每SHOW_EVERY个轮次展示一次
while not done:
if np.random.random() > epsilon:
# Get action from Q table
action = np.argmax(q_table[discrete_state])
else:
# Get random action
action = np.random.randint(0, env.action_space.n)
new_state, reward, done, _ = env.step(action)
new_discrete_state = get_discrete_state(new_state)
# If simulation did not end yet after last step - update Q table ^在一个轮次中:
随机生成数,和epsilon比较以达到随机程度的设置,开始时epsilon=1,动作完全随机生成,后续epsilon逐渐变小,agent的action选择逐渐依靠Q值表。
if not done:
# Maximum possible Q value in next step (for new state)
max_future_q = np.max(q_table[new_discrete_state])
# Current Q value (for current state and performed action)
current_q = q_table[discrete_state + (action,)]
# And here's our equation for a new Q value for current state and action
new_q = (1 - LEARNING_RATE) * current_q + LEARNING_RATE * (reward + DISCOUNT * max_future_q)
# Update Q table with new Q value
q_table[discrete_state + (action,)] = new_q
# Simulation ended (for any reson) - if goal position is achived - update Q value with reward directly
elif new_state[0] >= env.goal_position:
q_table[discrete_state + (action,)] = 0
print("we made it on episode {}".format(episode))^如果未到达目标,则更新Q值表:
依照公式:
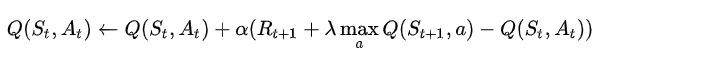
含义为:
现在的Q值=原来的Q值+学习率*(立即回报+Lambda*后继状态的最大Q值-原来的Q值)
如果车到达目标,则将当前状态、当前动作的Q值更新为0???
discrete_state = new_discrete_state
if render:
env.render()
# Decaying is being done every episode if episode number is within decaying range
if END_EPSILON_DECAYING >= episode >= START_EPSILON_DECAYING:
epsilon -= epsilon_decay_value
env.close()^将新状态赋予当前状态
如果到了相应轮次,则展示本次尝试
更新epsilon值
关闭环境
完整代码:
import gym
import numpy as np
env = gym.make("MountainCar-v0")
# Q-Learning settings
LEARNING_RATE = 0.1
DISCOUNT = 0.95
EPISODES = 25000
SHOW_EVERY = 1000
# Exploration settings
epsilon = 1 # not a constant, qoing to be decayed
START_EPSILON_DECAYING = 1
END_EPSILON_DECAYING = EPISODES//2
epsilon_decay_value = epsilon/(END_EPSILON_DECAYING - START_EPSILON_DECAYING)
DISCRETE_OS_SIZE = [20, 20]
discrete_os_win_size = (env.observation_space.high - env.observation_space.low)/DISCRETE_OS_SIZE
def get_discrete_state(state):
discrete_state = (state - env.observation_space.low)/discrete_os_win_size
return tuple(discrete_state.astype(np.int64)) # we use this tuple to look up the 3 Q values for the available actions in the q-table
q_table = np.random.uniform(low=-2, high=0, size=(DISCRETE_OS_SIZE + [env.action_space.n]))
for episode in range(EPISODES):
state = env.reset()
discrete_state = get_discrete_state(state)
if episode % SHOW_EVERY == 0:
render = True
print(episode)
else:
render = False
done = False
while not done:
if np.random.random() > epsilon:
# Get action from Q table
action = np.argmax(q_table[discrete_state])
else:
# Get random action
action = np.random.randint(0, env.action_space.n)
new_state, reward, done, _ = env.step(action)
new_discrete_state = get_discrete_state(new_state)
# If simulation did not end yet after last step - update Q table
if not done:
# Maximum possible Q value in next step (for new state)
max_future_q = np.max(q_table[new_discrete_state])
# Current Q value (for current state and performed action)
current_q = q_table[discrete_state + (action,)]
# And here's our equation for a new Q value for current state and action
new_q = (1 - LEARNING_RATE) * current_q + LEARNING_RATE * (reward + DISCOUNT * max_future_q)
# Update Q table with new Q value
q_table[discrete_state + (action,)] = new_q
# Simulation ended (for any reson) - if goal position is achived - update Q value with reward directly
elif new_state[0] >= env.goal_position:
q_table[discrete_state + (action,)] = 0
print("we made it on episode {}".format(episode))
discrete_state = new_discrete_state
if render:
env.render()
# Decaying is being done every episode if episode number is within decaying range
if END_EPSILON_DECAYING >= episode >= START_EPSILON_DECAYING:
epsilon -= epsilon_decay_value
env.close()
# np.save(path, q_table) # path自己指定 作者:Leon小草办 https://www.bilibili.com/read/cv17082506/ 出处:bilibili代码作者:Leon小草办 https://www.bilibili.com/read/cv17082506/ 出处:bilibili
作者实践视频(b站):BV1TZ4y1q728

















 346
346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









