






 本文介绍了如何准备YOLOv5s的数据集,包括将VOC格式转换为YOLO格式,划分训练集和验证集,并详细说明了如何执行脚本和配置训练。最后展示了蒸馏训练的结果对比。
本文介绍了如何准备YOLOv5s的数据集,包括将VOC格式转换为YOLO格式,划分训练集和验证集,并详细说明了如何执行脚本和配置训练。最后展示了蒸馏训练的结果对比。
YOLOv5s学生网络训练
准备自己的数据集
首先将你的数据集按照标准的voc数据集格式进行如下图的目录树存放
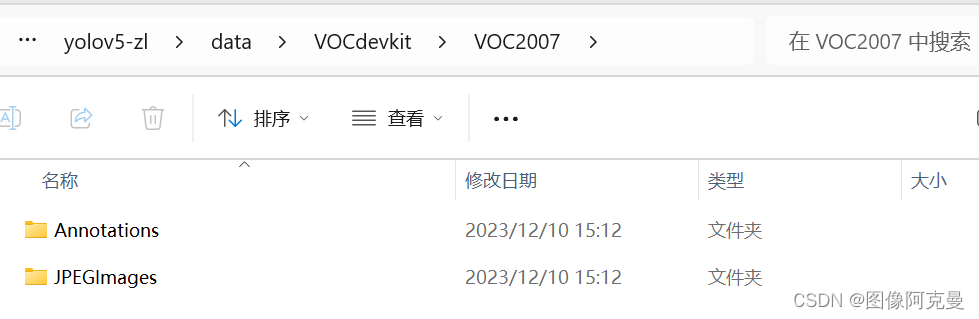 其中Annotations存放的是标注文件,文件格式是xml,JPEGImages存放的是图片。
其中Annotations存放的是标注文件,文件格式是xml,JPEGImages存放的是图片。
然后执行下面这个脚本就可以实现以下功能
- 将xml文件格式转换为标准的yolo的txt格式
- 将图片和标注文件划分训练集和验证集
注意将代码中的classes改为你的分类,顺序要对应,并且将convert_annotation函数中的文件路径改为你的对应的路径,路径中不存在中文并且尽量使用绝对路径。
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
import random
from shutil import copyfile
classes=["ball","messi"]
#classes=["ball"]
TRAIN_RATIO = 80
def clear_hidden_files(path):
dir_list = os.listdir(path)
for i in dir_list:
abspath = os.path.join(os.path.abspath(path), i)
if os.path.isfile(abspath):
if i.startswith("._"):
os.remove(abspath)
else:
clear_hidden_files(abspath)
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(image_id):
in_file = open('VOCdevkit/VOC2007/Annotations/%s.xml' %image_id)
out_file = open('VOCdevkit/VOC2007/YOLOLabels/%s.txt' %image_id, 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
wd = os.getcwd()
wd = os.getcwd()
data_base_dir = os.path.join(wd, "VOCdevkit/")
if not os.path.isdir(data_base_dir):
os.mkdir(data_base_dir)
work_sapce_dir = os.path.join(data_base_dir, "VOC2007/")
if not os.path.isdir(work_sapce_dir):
os.mkdir(work_sapce_dir)
annotation_dir = os.path.join(work_sapce_dir, "Annotations/")
if not os.path.isdir(annotation_dir):
os.mkdir(annotation_dir)
clear_hidden_files(annotation_dir)
image_dir = os.path.join(work_sapce_dir, "JPEGImages/")
if not os.path.isdir(image_dir):
os.mkdir(image_dir)
clear_hidden_files(image_dir)
yolo_labels_dir = os.path.join(work_sapce_dir, "YOLOLabels/")
if not os.path.isdir(yolo_labels_dir):
os.mkdir(yolo_labels_dir)
clear_hidden_files(yolo_labels_dir)
yolov5_images_dir = os.path.join(data_base_dir, "images/")
if not os.path.isdir(yolov5_images_dir):
os.mkdir(yolov5_images_dir)
clear_hidden_files(yolov5_images_dir)
yolov5_labels_dir = os.path.join(data_base_dir, "labels/")
if not os.path.isdir(yolov5_labels_dir):
os.mkdir(yolov5_labels_dir)
clear_hidden_files(yolov5_labels_dir)
yolov5_images_train_dir = os.path.join(yolov5_images_dir, "train/")
if not os.path.isdir(yolov5_images_train_dir):
os.mkdir(yolov5_images_train_dir)
clear_hidden_files(yolov5_images_train_dir)
yolov5_images_test_dir = os.path.join(yolov5_images_dir, "val/")
if not os.path.isdir(yolov5_images_test_dir):
os.mkdir(yolov5_images_test_dir)
clear_hidden_files(yolov5_images_test_dir)
yolov5_labels_train_dir = os.path.join(yolov5_labels_dir, "train/")
if not os.path.isdir(yolov5_labels_train_dir):
os.mkdir(yolov5_labels_train_dir)
clear_hidden_files(yolov5_labels_train_dir)
yolov5_labels_test_dir = os.path.join(yolov5_labels_dir, "val/")
if not os.path.isdir(yolov5_labels_test_dir):
os.mkdir(yolov5_labels_test_dir)
clear_hidden_files(yolov5_labels_test_dir)
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'w')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'w')
train_file.close()
test_file.close()
train_file = open(os.path.join(wd, "yolov5_train.txt"), 'a')
test_file = open(os.path.join(wd, "yolov5_val.txt"), 'a')
list_imgs = os.listdir(image_dir) # list image files
prob = random.randint(1, 100)
print("Probability: %d" % prob)
for i in range(0,len(list_imgs)):
path = os.path.join(image_dir,list_imgs[i])
if os.path.isfile(path):
image_path = image_dir + list_imgs[i]
voc_path = list_imgs[i]
(nameWithoutExtention, extention) = os.path.splitext(os.path.basename(image_path))
(voc_nameWithoutExtention, voc_extention) = os.path.splitext(os.path.basename(voc_path))
annotation_name = nameWithoutExtention + '.xml'
annotation_path = os.path.join(annotation_dir, annotation_name)
label_name = nameWithoutExtention + '.txt'
label_path = os.path.join(yolo_labels_dir, label_name)
prob = random.randint(1, 100)
print("Probability: %d" % prob)
if(prob < TRAIN_RATIO): # train dataset
if os.path.exists(annotation_path):
train_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_train_dir + voc_path)
copyfile(label_path, yolov5_labels_train_dir + label_name)
else: # test dataset
if os.path.exists(annotation_path):
test_file.write(image_path + '\n')
convert_annotation(nameWithoutExtention) # convert label
copyfile(image_path, yolov5_images_test_dir + voc_path)
copyfile(label_path, yolov5_labels_test_dir + label_name)
train_file.close()
test_file.close()
执行后如下图所示:
执行完毕以后会生成label文件夹,文件夹下已经划分好训练集和验证集。在yolov5下生成了两个文件yolov5_train.txt和yolov5_val.txt,yolov5_train.txt和yolov5_val.txt分别给出了训练图片文件和验证图片文件的列表, 含有每个图片的路径和文件名。
修改配置文件
创建data/voc_bm.yaml
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ./
train: # train images (relative to 'path') 16551 images
- VOCdevkit/images/train/
val: # val images (relative to 'path') 4952 images
- VOCdevkit/images/val/
test: # test images (optional)
# Classes
nc: 2 # number of classes
names: ['ball', 'messi'] # class names
这里的路径要写对,有三种写路径和的方法,主要推荐前面两种,配置文件中的实例就是第一种。
1) dir: path/to/imgs
2) file: path/to/imgs.txt
val: data/nwpu vhr-10/val.txt #例子
train: data/nwpu vhr-10/train.txt #例子
test: data/nwpu vhr-10/test.txt #例子
修改nc类别
然后将model文件夹下面的yolov5s和yolov5m的nc改为2,或者另外新建yolov5svoc和yolov5mvoc。
yolov5s训练自己的数据集
python train.py --data data/voc_bm.yaml --cfg models/yolov5s_bm.yaml --weights weights/yolov5s.pt --batch-size 16 --epochs 100 --workers 4 --name yolov5sbase
如果开始训练出现长期卡在这里的话
Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...
是因为项目中缺少这个东西,我直接把这个文件放这里,下载完成以后直接放在总目录下也可以识别
链接:https://pan.baidu.com/s/11AwkBdV0fsavRcRC2EXoOg?pwd=gkgk
提取码:gkgk

然后可以正常的开始训练了。

学生网络训练结果如下:

yolov5m教师网络训练
同上,仅需要将网络模型改为yolov5m就可以,训练命令如下:
python train.py --data data/voc_bm.yaml --cfg models/yolov5m_bm.yaml --weights weights/yolov5m.pt --batch-size 16 --epochs 100 --workers 4 --name yolov5m-base
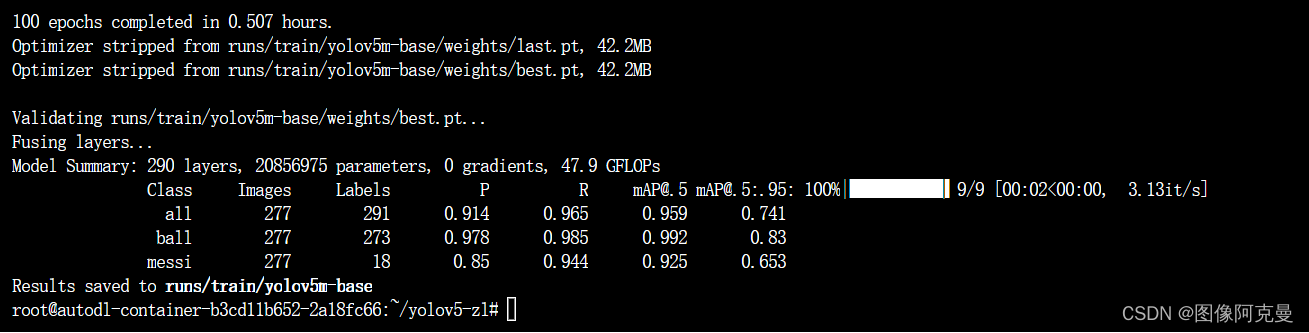
教师网络训练结果如下:
知识蒸馏训练
学生网络和教师网络训练完毕进入重点,蒸馏训练
把runs/train/yolov5s-base/weights/best.pt和runs/train/yolov5m-base/weights/best.pt拷贝到weights文件夹下并改名为yolov5szl.pt和yolov5mzl.pt
python train_distillation.py --weights weights/yolov5szl.pt --cfg models/yolov5s_bm.yaml --data data/voc_bm.yaml --batch-size 8 --epochs 100 --workers 4 --t_weights weights/yolov5mzl.pt --hyp data/hyps/hyp.scratch-low-distillation.yaml --distill --dist_loss l2 --name yolov5s-distilled
训练过程可视化:
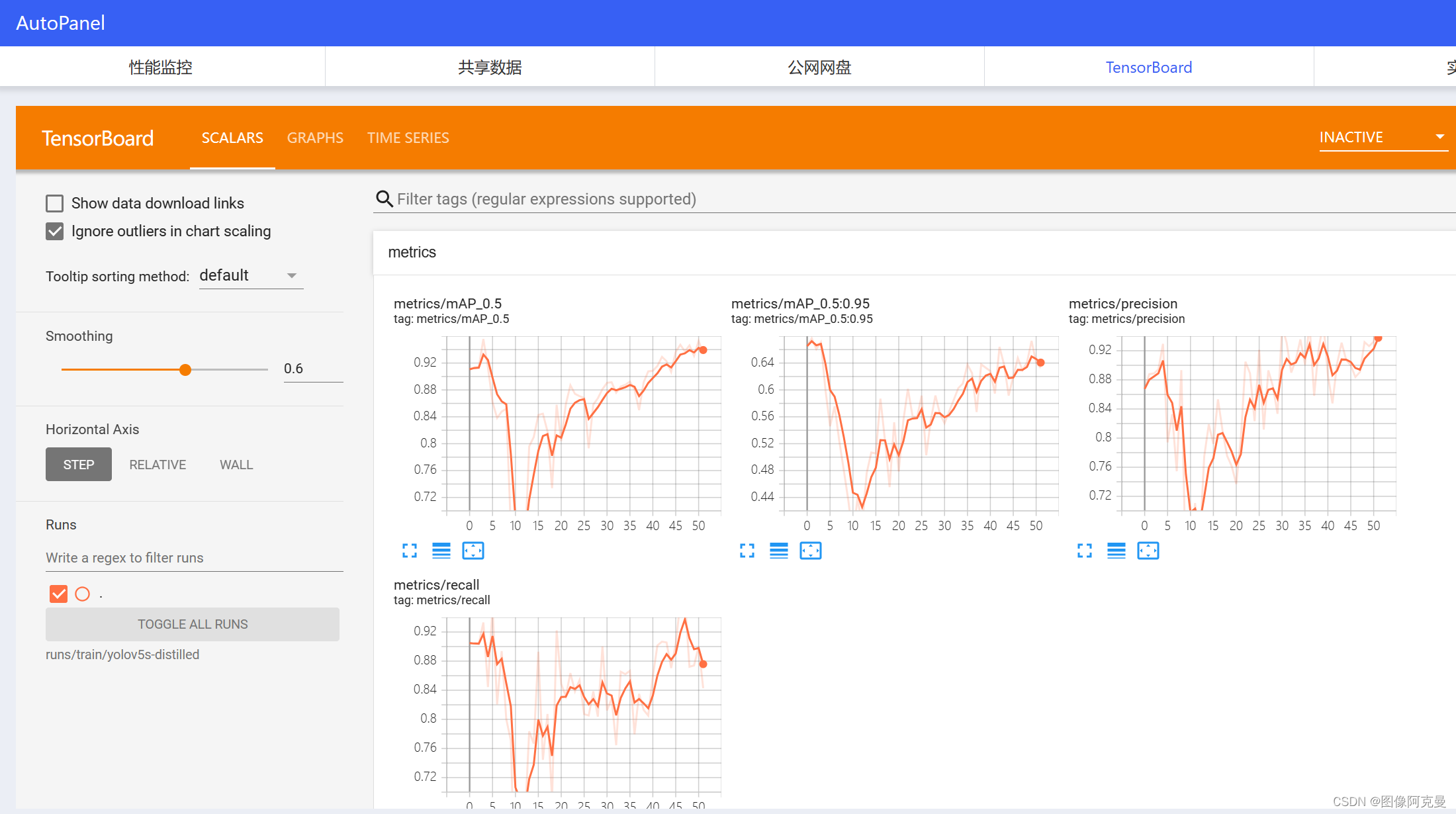
结果如下:
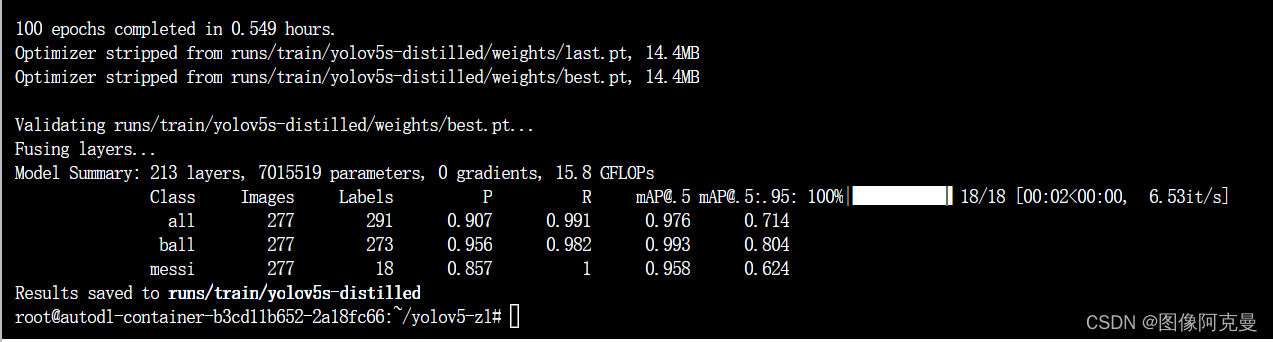
对比结果
| 参数 | yolov5s | yolov5m | 蒸馏L2 |
|---|---|---|---|
| P | 0.87 | 0.914 | 0.907 |
| R | 0.88 | 0.965 | 0.991 |
| MAP50 | 0.918 | 0.959 | 0.976 |
| MAP95 | 0.696 | 0.741 | 0.714 |
| GFLOPs | 15.8 | 47.9 | 15.8 |
对比发现这个表格显示了蒸馏L2相对于yolov5s在不同指标下的数值提升。在精度(P)、召回率(R)和平均精度(MAP)方面,蒸馏L2都取得了显著的提升。


















 4018
4018

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











