







 本文介绍了SRN-DeblurNet,一种基于深度学习的盲去模糊方法,它是首个将RNN应用于去模糊领域的模型,相比其他深度学习方法,其网络结构简洁,训练高效。文章详细描述了网络结构和模型代码实现,展示了SRN-DeblurNet在去模糊任务中的开创性作用。
本文介绍了SRN-DeblurNet,一种基于深度学习的盲去模糊方法,它是首个将RNN应用于去模糊领域的模型,相比其他深度学习方法,其网络结构简洁,训练高效。文章详细描述了网络结构和模型代码实现,展示了SRN-DeblurNet在去模糊任务中的开创性作用。
第一步:SRN-DeblurNet介绍
本文介绍的 SRN-DeblurNet(CVPR2018)方法便是一种基于深度学习的盲去模糊方法,它沿用了去模糊领域广泛应用的从粗到细(coarse-to-fine)的方案,提出了一个新的用于去模糊任务的尺度循环网络(Scale-recurrent Network),采用尺度训练方法,使用了编码器-解码器,ResBlock 网络等,该方法有两大突出特点:
SRN-DeblurNet 是第一篇将循环神经网络 RNN(Recurrent Neural Network)引入去模糊任务,而此前基于深度学习的去模糊领域通常使用 CNN(卷积神经网络),该文章的引用已达 1090 次(Google scholar),在基于深度学习的去模糊领域中具有开创性的意义。
SRN-DeblurNet 相比于同期其它的基于深度学习的方法,它的网络结构更简单,参数数量更少,训练更高效、容易;而且该网络的去模糊效果在相关邻域其它论文中得到了一致的认可。
第二步:SRN-DeblurNet网络结构

第三步:模型代码展示
from __future__ import print_function
import os
import time
import random
import datetime
import scipy.misc
import imageio
import numpy as np
import skimage.transform
import cv2
import tensorflow as tf
import tensorflow.contrib.slim as slim
from datetime import datetime
from util.util import *
from util.BasicConvLSTMCell import *
class DEBLUR(object):
def __init__(self, args):
self.args = args
self.n_levels = 3
self.scale = 0.5
self.chns = 3 if self.args.model == 'color' else 1 # input / output channels
# if args.phase == 'train':
self.crop_size = 256
self.data_list = open(args.datalist, 'rt').read().splitlines()
self.data_list = list(map(lambda x: x.split(' '), self.data_list))
random.shuffle(self.data_list)
self.train_dir = os.path.join('./checkpoints', args.model)
if not os.path.exists(self.train_dir):
os.makedirs(self.train_dir)
self.batch_size = args.batch_size
self.epoch = args.epoch
self.data_size = (len(self.data_list)) // self.batch_size
self.max_steps = int(self.epoch * self.data_size)
self.learning_rate = args.learning_rate
def input_producer(self, batch_size=10):
def read_data():
img_a = tf.image.decode_image(tf.read_file(tf.string_join(['./training_set/', self.data_queue[0]])),
channels=3)
img_b = tf.image.decode_image(tf.read_file(tf.string_join(['./training_set/', self.data_queue[1]])),
channels=3)
img_a, img_b = preprocessing([img_a, img_b])
return img_a, img_b
def preprocessing(imgs):
imgs = [tf.cast(img, tf.float32) / 255.0 for img in imgs]
if self.args.model != 'color':
imgs = [tf.image.rgb_to_grayscale(img) for img in imgs]
img_crop = tf.unstack(tf.random_crop(tf.stack(imgs, axis=0), [2, self.crop_size, self.crop_size, self.chns]),
axis=0)
return img_crop
with tf.variable_scope('input'):
List_all = tf.convert_to_tensor(self.data_list, dtype=tf.string)
gt_list = List_all[:, 0]
in_list = List_all[:, 1]
self.data_queue = tf.train.slice_input_producer([in_list, gt_list], capacity=20)
image_in, image_gt = read_data()
batch_in, batch_gt = tf.train.batch([image_in, image_gt], batch_size=batch_size, num_threads=8, capacity=20)
return batch_in, batch_gt
def generator(self, inputs, reuse=False, scope='g_net'):
n, h, w, c = inputs.get_shape().as_list()
if self.args.model == 'lstm':
with tf.variable_scope('LSTM'):
cell = BasicConvLSTMCell([h / 4, w / 4], [3, 3], 128)
rnn_state = cell.zero_state(batch_size=self.batch_size, dtype=tf.float32)
x_unwrap = []
with tf.variable_scope(scope, reuse=reuse):
with slim.arg_scope([slim.conv2d, slim.conv2d_transpose],
activation_fn=tf.nn.relu, padding='SAME', normalizer_fn=None,
weights_initializer=tf.contrib.layers.xavier_initializer(uniform=True),
biases_initializer=tf.constant_initializer(0.0)):
inp_pred = inputs
for i in xrange(self.n_levels):
scale = self.scale ** (self.n_levels - i - 1)
hi = int(round(h * scale))
wi = int(round(w * scale))
inp_blur = tf.image.resize_images(inputs, [hi, wi], method=0)
inp_pred = tf.stop_gradient(tf.image.resize_images(inp_pred, [hi, wi], method=0))
inp_all = tf.concat([inp_blur, inp_pred], axis=3, name='inp')
if self.args.model == 'lstm':
rnn_state = tf.image.resize_images(rnn_state, [hi // 4, wi // 4], method=0)
# encoder
conv1_1 = slim.conv2d(inp_all, 32, [5, 5], scope='enc1_1')
conv1_2 = ResnetBlock(conv1_1, 32, 5, scope='enc1_2')
conv1_3 = ResnetBlock(conv1_2, 32, 5, scope='enc1_3')
conv1_4 = ResnetBlock(conv1_3, 32, 5, scope='enc1_4')
conv2_1 = slim.conv2d(conv1_4, 64, [5, 5], stride=2, scope='enc2_1')
conv2_2 = ResnetBlock(conv2_1, 64, 5, scope='enc2_2')
conv2_3 = ResnetBlock(conv2_2, 64, 5, scope='enc2_3')
conv2_4 = ResnetBlock(conv2_3, 64, 5, scope='enc2_4')
conv3_1 = slim.conv2d(conv2_4, 128, [5, 5], stride=2, scope='enc3_1')
conv3_2 = ResnetBlock(conv3_1, 128, 5, scope='enc3_2')
conv3_3 = ResnetBlock(conv3_2, 128, 5, scope='enc3_3')
conv3_4 = ResnetBlock(conv3_3, 128, 5, scope='enc3_4')
if self.args.model == 'lstm':
deconv3_4, rnn_state = cell(conv3_4, rnn_state)
else:
deconv3_4 = conv3_4
# decoder
deconv3_3 = ResnetBlock(deconv3_4, 128, 5, scope='dec3_3')
deconv3_2 = ResnetBlock(deconv3_3, 128, 5, scope='dec3_2')
deconv3_1 = ResnetBlock(deconv3_2, 128, 5, scope='dec3_1')
deconv2_4 = slim.conv2d_transpose(deconv3_1, 64, [4, 4], stride=2, scope='dec2_4')
cat2 = deconv2_4 + conv2_4
deconv2_3 = ResnetBlock(cat2, 64, 5, scope='dec2_3')
deconv2_2 = ResnetBlock(deconv2_3, 64, 5, scope='dec2_2')
deconv2_1 = ResnetBlock(deconv2_2, 64, 5, scope='dec2_1')
deconv1_4 = slim.conv2d_transpose(deconv2_1, 32, [4, 4], stride=2, scope='dec1_4')
cat1 = deconv1_4 + conv1_4
deconv1_3 = ResnetBlock(cat1, 32, 5, scope='dec1_3')
deconv1_2 = ResnetBlock(deconv1_3, 32, 5, scope='dec1_2')
deconv1_1 = ResnetBlock(deconv1_2, 32, 5, scope='dec1_1')
inp_pred = slim.conv2d(deconv1_1, self.chns, [5, 5], activation_fn=None, scope='dec1_0')
if i >= 0:
x_unwrap.append(inp_pred)
if i == 0:
tf.get_variable_scope().reuse_variables()
return x_unwrap
def build_model(self):
img_in, img_gt = self.input_producer(self.batch_size)
tf.summary.image('img_in', im2uint8(img_in))
tf.summary.image('img_gt', im2uint8(img_gt))
print('img_in, img_gt', img_in.get_shape(), img_gt.get_shape())
# generator
x_unwrap = self.generator(img_in, reuse=False, scope='g_net')
# calculate multi-scale loss
self.loss_total = 0
for i in xrange(self.n_levels):
_, hi, wi, _ = x_unwrap[i].get_shape().as_list()
gt_i = tf.image.resize_images(img_gt, [hi, wi], method=0)
loss = tf.reduce_mean((gt_i - x_unwrap[i]) ** 2)
self.loss_total += loss
tf.summary.image('out_' + str(i), im2uint8(x_unwrap[i]))
tf.summary.scalar('loss_' + str(i), loss)
# losses
tf.summary.scalar('loss_total', self.loss_total)
# training vars
all_vars = tf.trainable_variables()
self.all_vars = all_vars
self.g_vars = [var for var in all_vars if 'g_net' in var.name]
self.lstm_vars = [var for var in all_vars if 'LSTM' in var.name]
for var in all_vars:
print(var.name)
第四步:运行

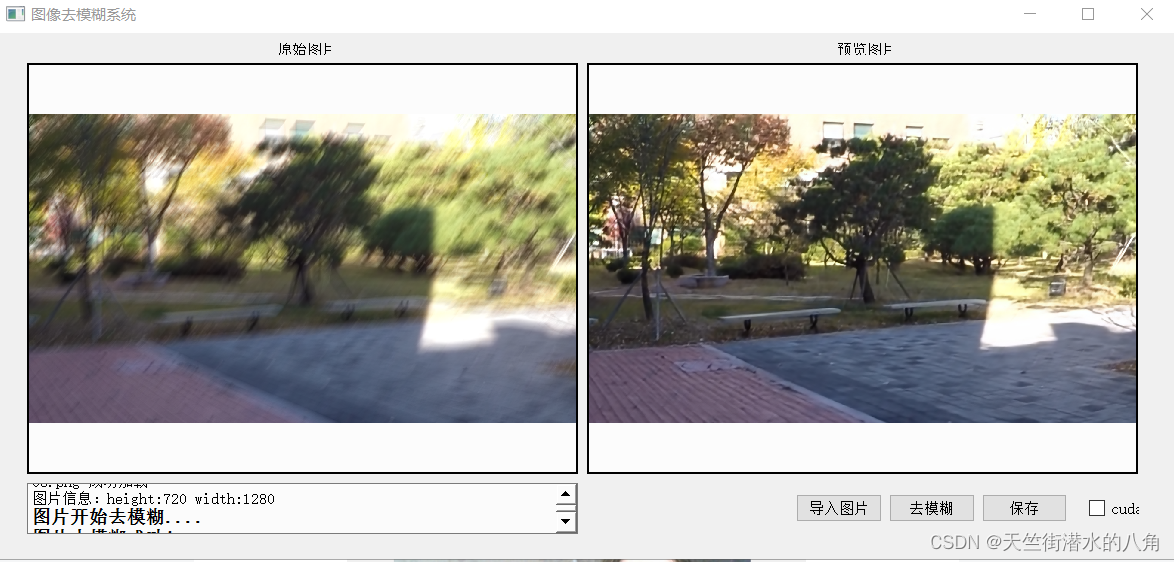
第五步:整个工程的内容
代码的下载路径(新窗口打开链接):基于深度学习SRN图像去模糊系统

有问题可以私信或者留言,有问必答















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









