







本篇文章内容非100%原创,主要是学习博客,用以总结,如侵就删,本人是个菜鸡,如有不对,欢迎指正
文章目录
这部分主要讲述yolo系列各个版本的的原理,这部分会把yolov1到yolov5的原理进行详细的阐述。首先我们先来看深度学习的两种经典的检测方法:
Two-stage(两阶段):代表-- Fsater-rcnn Mask-rcnn系列
One-stage(单阶段):代表-- Yolo系列
两阶段和单阶段有什么样的区别呢,我们从整体上理解:单阶段的就是一步到位,我们输入一个图像,经过一系列传化,最终会得到一个输出结果;双阶段相较于单节段多了一些中间步骤,输入一个原始图像,我们会先得到一些中间值,最后才输出结果。更形象的表述为,我们要选择一个人当代表,代表安徽省踢球,那么双阶段就类似与我先在安徽各个市找一些好苗子,最后再从这些好苗子中选择一个最优秀的。具体可以参照下图:

既然两种检测方式有所区别,那自然会讨论他们的优缺点:
One-stage
优势:速度非常快,适合做实时检测任务
劣势:效果通常不会太好
Two-stage
优势:效果通常比较好
劣势:速度较慢,不适合做实时检测任务
其实他们的优缺点我们也很好理解,单阶段检测的没有中间过程,那速度肯定是相当哇塞了,但从效果来说,就相对差一点。我们可以看一下他们的对比(以单阶段的yolo和双阶段的Faster-rcnn为代表)

从上图可以看出,YOLO的mAP要低于Fast-rcnn,但是FPS却远高于Fast-rcnn。【FPS表示一个网络的检测速度,越大速度越快,mAP表示模型综合检测的效果,越大效果越好】
上面提到了一个术语:mAP。它表示的是一个综合检测的效果,因为表示模型效果的评价指标有很多,像IOU、precision、recall等,下面先来介绍这三个参数:
IOU:
真实框和预测框之间的交并比,可以反映两个框之间的距离
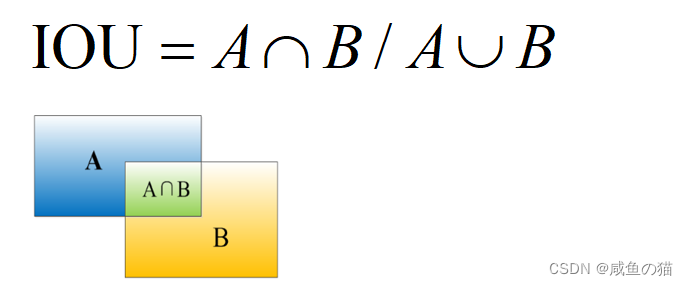
Precision(精度)和Recall(召回率)
精度表示分类的准确性,它等于将(正类分类正确)与(正类分类正确和错误)的比例
召回率的含义是表示(正类分类正确)与(正类分类正确和把正类判断成负类)的比值。简单来说,recall表示的就是一些没有检测到的物体的比例,比如一张图片有10个目标需要检测,一种方法你检测到了10种目标,那你的召回率就好;而另一种方法只检测到了8个图片,那么你的召回率就不好。

TP(真阳)——Ture Positives(表示判断正确,把正类判断成正类)
FP(假阳)——False Positives(表示判断错误,把负类判断成正类)
FN(假阴)——False Negatives(表示判断错误,把正类判断成负类)
TN(真阴)——True Negatives(表示判断正确,把负类判断成负类)
举例说明
已知:班级共100人,其中男生80人,女生20人
目标:找出所有女生
结果:从班级中选择了50人才找出20个女生,也即错误的把30名男生也挑选出来了
则
- TP=20 【把正类判断成正类,即找到的20个女生】
- FP=30 【把负类判断成正类,即将30个男生看做女生】
- FN=0 【把正类判断成负类,这里为0,所以女生都被选出来了】
- TN=50 【把负类判断成负类,即剩下的没有选出来的50个男生】
precision=20/(20+30)=2/5
recall=20/(20+0)=1
知道了precision和recall,这两个指标都可以表示检测的效果,为了综合表示检测效果,产生了mAP。首先先介绍什么是AP?AP事实上指的是,我们取不同的置信度,可以获得不同的Precision和不同的Recall,当我们取置信度足够密集的时候,就可以获得非常多的Precision和Recall。利用不同的Precision和Recall的点的组合,画出来的曲线下面的面积即为AP的大小。如下图所示:

AP衡量的是对一个类检测好坏,mAP就是对多个类的检测好坏。计算方法就是把所有类的AP值取平均。比如有两类,类A的AP值是0.6,类B的AP值是0.4,那么mAP=(0.6+0.4)/2=0.5
算法思想:
YOLOv1 和后续的 YOLO 算法最大的不同是 YOLOv1 并没有使用先验框(anchor box)
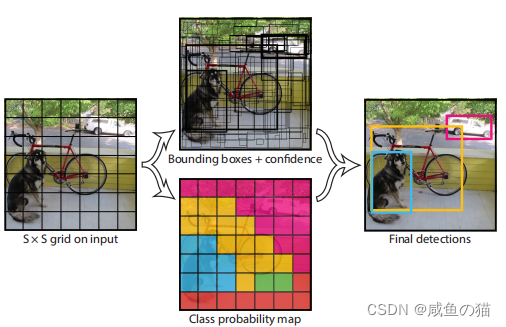
1. 将图像划分为 S x S 的网格,论文中的设置是 7 x 7 的网格。如果某个物体的中心落在这个网格中,那么这个网格就负责预测这个物体。
2. 然后每个网格预测 B 个边框,论文中的设置是2个边框,即预测出 7 x 7 x 2 个边框,这个边框负责预测物体的位置。
3. 每个边框除了要预测物体的位置之外,还要附带预测一个置信度。这里的置信度不仅指边框包含目标的概率,还指边框定位目标的准确程度。
4. 每个网格还要预测C个类别的分数。比如说在 VOC 数据集上则会预测出20个类别。
5. 因此,对于 VOC 数据集来说,YOLOv1 的网络最后是输出预测位置(xywh)+置信度以及类别分数,所以输出为 7 x 7 x (5 + 5 + 20)。
6. 最后一层全连接层用线性激活函数,其余层采用 Leaky ReLU
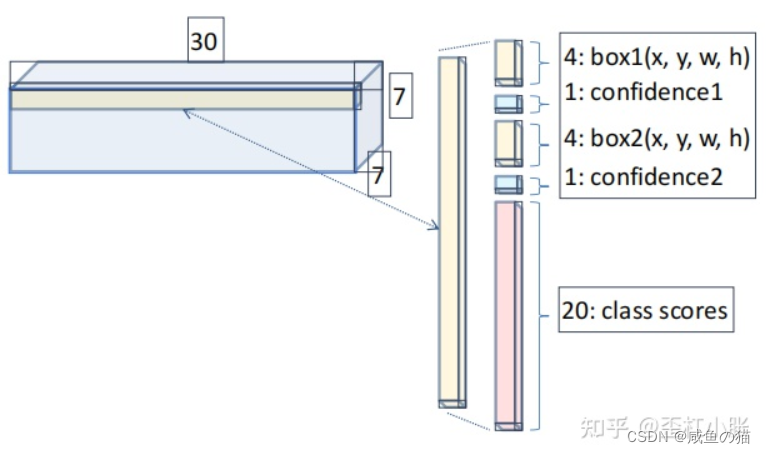
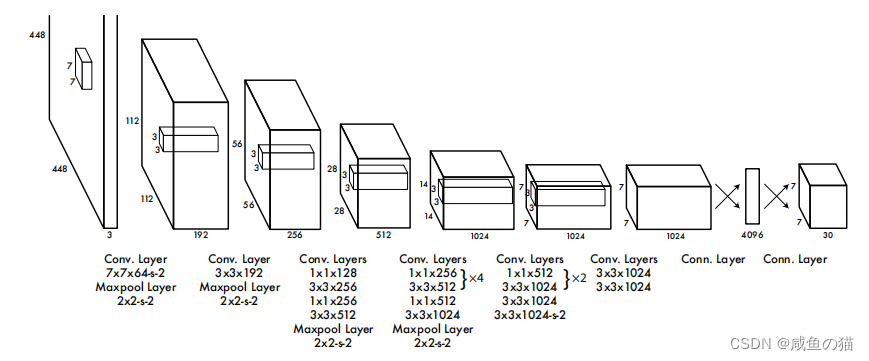
模型结构
损失函数
损失函数=定位损失+置信度损失+分类损失
三者都用均方差损失(MSE)计算

Yolov1优点及不足
优点:
检测速度快
迁移能力强
不足:
1. 因为每个网格单元只预测两个框,并且只有一个类别。即每个网格只会选择出 IOU 最高的那个目标,所以如果每个网格包含多个物体,就只能检测出其中一个,所以对于拥有群体小目标的图片来说,比如鸟群,检测效果会很差。
2. 当出现新尺寸的目标时,效果也会变差,原因是 YOLOv1 使用简单的特征来预测边界框,并没有使用 anchor,导致定位的不准确。
3. 最后的输出层为全连接层。因为全连接层输出大小是固定的,所以导致图像的输入大小也必须固定,这在一定程度上来说有局限性。
4、MSE 在处理大边框和小边框时,赋予的权重是一样的。假设同样是预测与实际相差25个像素点,但是对于大边界框来说,小错误通常是无足轻重的,甚至可以忽略不计,但对于小边界框来说,这个数值对于它的影响就很大了
参考文章
CSDN博主「秃头小苏」
原文链接:https://blog.csdn.net/qq_47233366/article/details/122550734
知乎 cv技术指南

















 2462
2462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









