






# -------------------------处理、读取数据----------------------------------------------#
# -----------------------readcifar10.py---------------------------------------------#
import pickle
import glob
import numpy as np
import cv2
import os
# -----------------------------------------------------------------------#
# train_list: 用于存储测试集数据文件的路径列表。
# lable_name: CIFAR-10数据集的标签名称列表,对应着图片的类别。
# save_path: 保存解析后的图片的文件夹路径。
# train_list 是一个存储训练集图像文件路径的列表。
# unpickle() 是一个自定义函数,用于解析 CIFAR-10 数据集文件。它接受一个文件路径作为输入,并返回一个包含图像数据、标签和文件名等信息的字典。
# im_dix, im_data 在循环中分别表示当前图像在文件中的索引和对应的图像数据。
# im_label 表示当前图像的标签(类别)。
# im_name 表示当前图像的文件名。
# im_label_name 是一个根据标签获取到的对应类别的名称。
# im_data = np.reshape(im_data,[3,32,32]) 将原始的图像数据转换为形状为 (3, 32, 32) 的数组。
# im_data = np.transpose(im_data,(1,2,0)) 对图像数据进行转置操作,使得通道维度在最后。
# 使用 cv2.imwrite() 函数将图像数据保存为图像文件。
# 第一个参数:保存文件的路径,其中包括保存目录、类别名称和文件名。
# 第二个参数:待保存的图像数据。
# -----------------------------------------------------------------------#
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
lable_name = ["airplane",
"automobile",
"bird",
"cat",
"deer",
"dog",
"frog",
"horse",
"ship",
"truck"]
train_list = glob.glob(r"Cifar10\cifar-10-python\cifar-10-batches-py\test_batch*")
print(train_list)
save_path = "Cifar10/cifar-10-python/cifar-10-batches-py/test"
for l in train_list:
# print(l)
# print("-"*100)
l_dict = unpickle(l)
# print(l_dict)
# print(l_dict.keys())
# print("-" * 100)
for im_dix,im_data in enumerate(l_dict[b"data"]):
# print(im_dix)
# print("-" * 100)
# print(im_data)
# print("-" * 100)
im_label = l_dict[b"labels"][im_dix]
im_name = l_dict[b"filenames"][im_dix]
# print(im_label,im_name,im_data)
# print("-" * 100)
im_label_name = lable_name[im_label]
im_data = np.reshape(im_data,[3,32,32])
im_data = np.transpose(im_data,(1,2,0))
# print(im_data)
# cv2.imshow("im_data",cv2.resize(im_data,(200,200)))
# cv2.waitKey(0)
if not os.path.exists("{}/{}".format(save_path,im_label_name)):
os.mkdir("{}/{}".format(save_path,im_label_name))
# print("-" * 100)
cv2.imwrite("{}/{}/{}".format(save_path,
im_label_name,
im_name.decode("utf-8")
),
im_data)
print("-" * 100)
以下是代码的主要实现逻辑:
使用glob.glob()函数获取测试集数据文件的路径列表。
定义一个辅助函数unpickle()来反序列化数据文件。
遍历每个测试集数据文件:
使用unpickle()函数读取文件内容,返回一个字典。
遍历每张图片的索引和数据:
获取图片的标签和文件名。
根据标签获取对应的类别名称。
将数据重新reshape为3通道的图像形式。
创建保存图片的类别文件夹(如果不存在)。
使用OpenCV的imwrite()函数将图像保存到对应文件夹中。
可以根据具体需求修改代码,例如修改train_list来处理训练集数据,修改save_path来调整保存路径等。
运行结果:
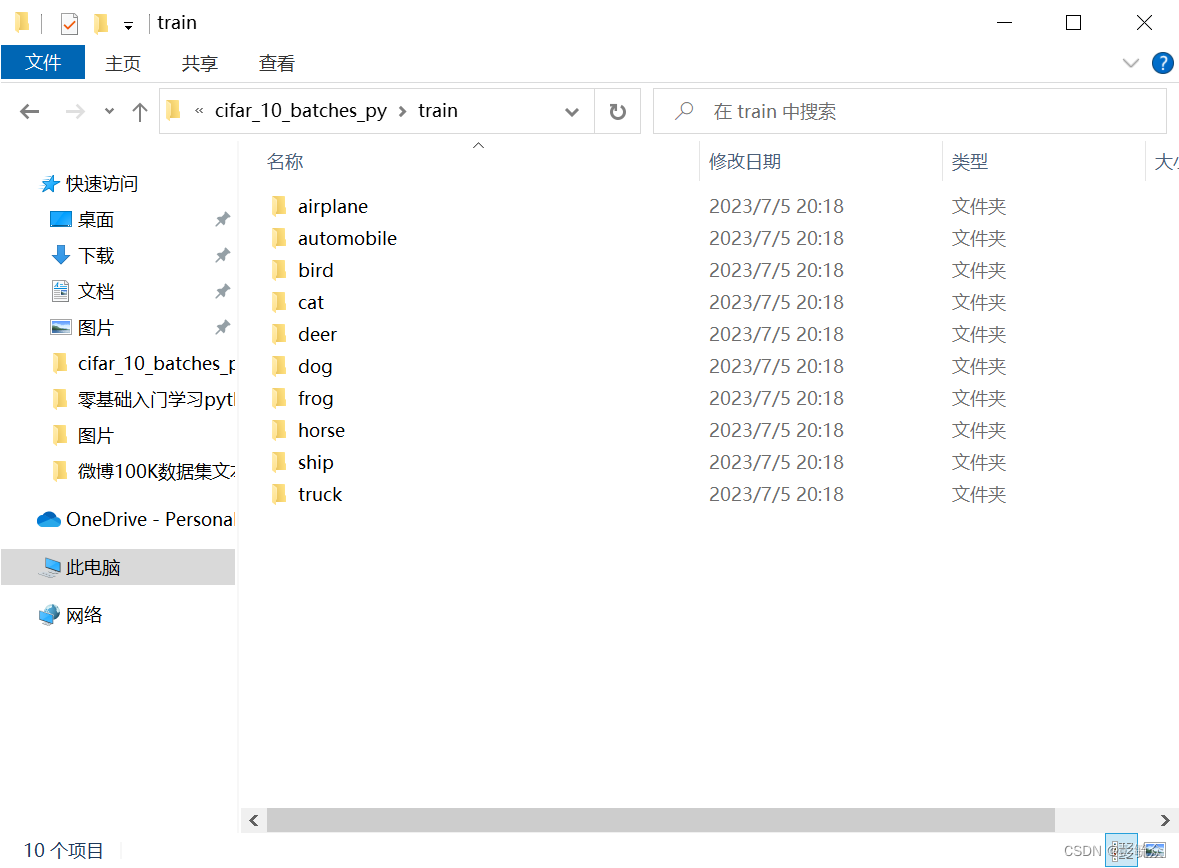
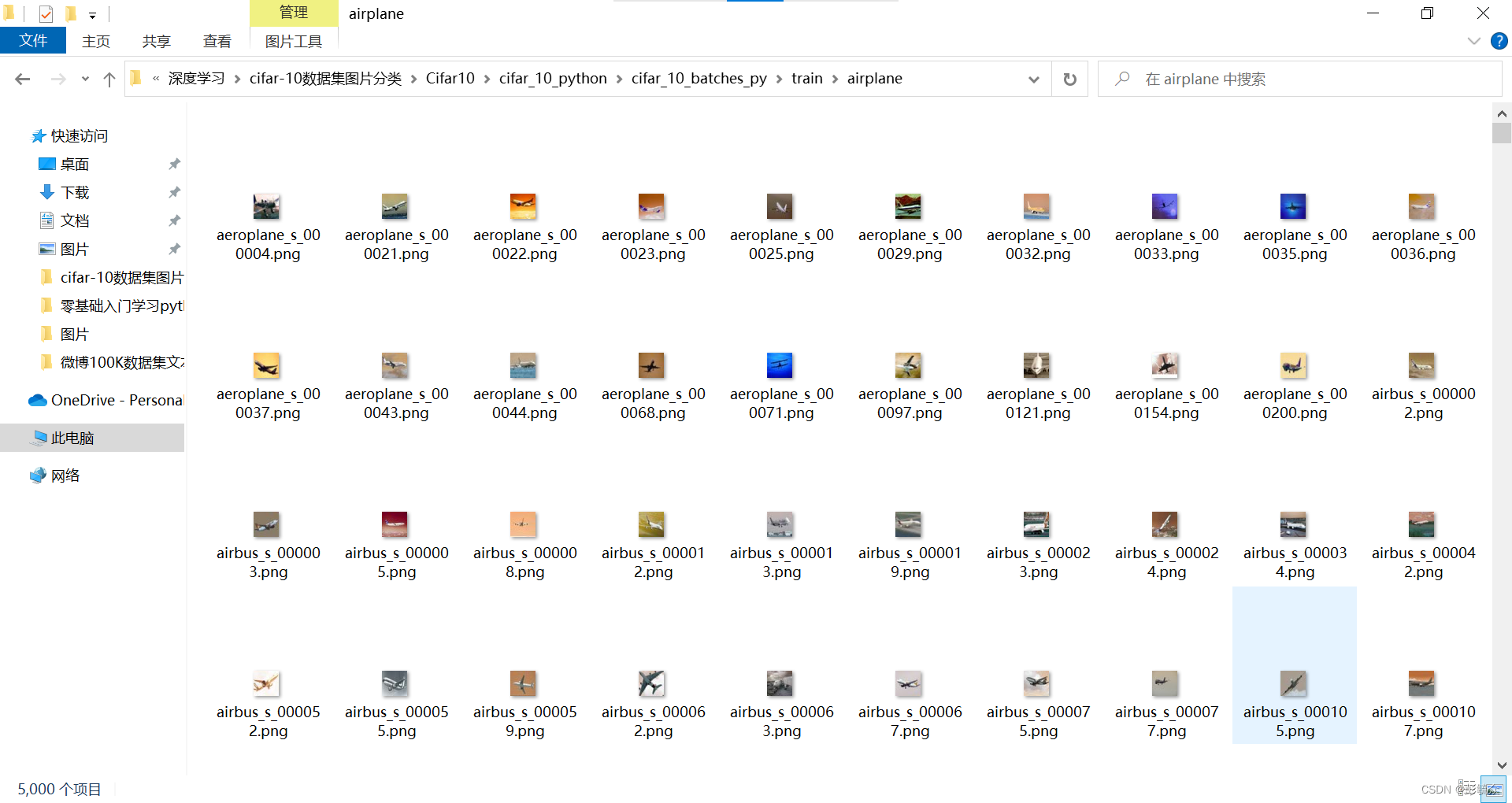
# -------------------------------加载数据----------------------------------------------#
# ---------------------------load_cifar10.py-----------------------------------------#
from torchvision import transforms
from torch.utils.data import DataLoader,Dataset
import os
from PIL import Image
import numpy as np
import glob
label_name = ["airplane","automobile", "bird",
"cat", "deer","dog","frog",
"horse","ship","truck"]
label_dict = {}
for idx,name in enumerate(label_name):
label_dict[name] = idx
# print(label_dict[name])
def default_loader(path):
return Image.open(path).convert("RGB")
train_transform = transforms.Compose([
transforms.RandomResizedCrop((28,28)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
])
test_transform = transforms.Compose([
transforms.RandomResizedCrop((28,28)),
transforms.ToTensor()
])
# train_transform = transforms.Compose([
# transforms.RandomResizedCrop((28,28)),
# transforms.RandomHorizontalFlip(),
# transforms.RandomVerticalFlip(),
# transforms.RandomRotation(90),
# transforms.RandomGrayscale(0.1),
# transforms.ColorJitter(0.3,0.3,0.3,0.3),
# transforms.ToTensor()
# ])
# --------------------------------------------------------------------#
# im_list 是一个包含图像文件路径的列表,即待加载的图像数据集。
# transform 是一个可选的数据转换操作,用于在加载图像数据后对其进行预处理。
# loader 是一个函数指针,默认为 default_loader,用于加载图像文件。
# im_label_name = im_item.split("\\")[-2] 从图像文件路径中提取出标签对应的类别名称。
# imgs.append([im_item,label_dict[im_label_name]]) 将图像文件路径和对应的类别标签添加到 imgs 列表中。
# im_path, im_label = self.imgs[index] 从 self.imgs 列表中获取指定索引位置的图像路径和标签。
# im_data = self.loader(im_path) 使用 self.loader 函数加载对应路径的图像数据。
# __len__(self) 方法返回数据集的长度,即图像数量,通过 return len(self.imgs) 实现。
# --------------------------------------------------------------------#
class MyDataset(Dataset):
def __init__(self,im_list,
transform=None,
loader = default_loader):
super(MyDataset,self).__init__()
imgs = []
for im_item in im_list:
im_label_name = im_item.split("\\")[-2]
imgs.append([im_item,label_dict[im_label_name]])
# print(imgs)
self.imgs = imgs
self.transform = transform
self.loader = loader
def __getitem__(self, index):
im_path, im_label = self.imgs[index]
im_data = self.loader(im_path)
if self.transform is not None:
im_data = self.transform(im_data)
return im_data, im_label
def __len__(self):
return len(self.imgs)
im_train_list = glob.glob(r"D:\PythonProject\深度学习\cifar-10数据集图片分类\Cifar10\cifar_10_python\cifar_10_batches_py\train\*\*.png")
im_test_list = glob.glob(r"D:\PythonProject\深度学习\cifar-10数据集图片分类\Cifar10\cifar_10_python\cifar_10_batches_py\test\*\*.png")
# print(im_test_list)
train_dataset = MyDataset(im_train_list,
transform = train_transform)
test_dataset = MyDataset(im_test_list,
transform = transforms.ToTensor())
# train_data_loader = DataLoader(dataset=train_dataset,
# batch_size=6,
# shuffle=True,
# num_workers=4)
train_data_loader = DataLoader(dataset=train_dataset,
batch_size=128,
shuffle=True,
num_workers=0)
test_data_loader = DataLoader(dataset=test_dataset,
batch_size=128,
shuffle=False,
num_workers=0)
print("num_of_train",len(train_dataset))
print("num_of_test",len(test_dataset))
# -------------------------------定义模型----------------------------------------------#
# ------------------------------vggnet.py--------------------------------------------#
import torch
import torch.nn as nn
import torch.nn.functional as F
# ---------------------------------------------------------------------------------#
# in_channels:输入特征图的通道数。表示卷积层接收的输入数据有多少个通道。
# out_channels:输出特征图的通道数。表示卷积层将生成多少个特征图作为输出。
# kernel_size:卷积核的尺寸。可以是整数或元组。如果是整数,则表示卷积核的高度和宽度相等;如果是元组,则表示卷积核的高度和宽度分别是元组中的两个值。
# stride:卷积操作的步长。可以是整数或元组。如果是整数,则表示卷积核在水平和垂直方向上的步长相等;如果是元组,则表示卷积核在水平和垂直方向上的步长分别是元组中的两个值。默认值为 1。
# padding:输入边缘的填充数量。可以是整数或元组。如果是整数,则表示在输入图像的四个边缘上填充相同数量的像素;如果是元组,则表示在水平和垂直方向上分别填充元组中的两个值。默认值为 0。
# dilation:卷积核中元素之间的间距。可以是整数或元组。如果是整数,则表示卷积核中元素的间距相等;如果是元组,则表示卷积核中元素在水平和垂直方向上的间距分别是元组中的两个值。默认值为 1。
# groups:输入和输出通道之间的连接方式。默认值为 1,表示普通的连接方式。如果设置为输入通道数,将会进行卷积分组操作。
# bias:是否使用偏置项。默认值为 True,表示使用偏置项。
# ---------------------------------------------------------------------------------#
class VGGbase(nn.Module):
def __init__(self):
super(VGGbase, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3,64,kernel_size=3,stride=1,padding=1),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.max_pooling1 = nn.MaxPool2d(kernel_size=2,stride=2)
self.conv2_1 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.max_pooling2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2_2 = nn.Sequential(
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.max_pooling2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3_1 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.max_pooling3 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv3_2 = nn.Sequential(
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.max_pooling3 = nn.MaxPool2d(kernel_size=2, stride=2,padding=1)
self.conv4_1 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.max_pooling4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv4_2 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU()
)
self.max_pooling4 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc = nn.Linear(512*4,10)
def forward(self,x):
batchsize = x.size(0)
out = self.conv1(x)
out = self.max_pooling1(out)
out = self.conv2_1(out)
out = self.conv2_2(out)
out = self.max_pooling2(out)
out = self.conv3_1(out)
out = self.conv3_2(out)
out = self.max_pooling3(out)
out = self.conv4_1(out)
out = self.conv4_2(out)
out = self.max_pooling4(out)
out = out.view(batchsize,-1)
out = self.fc(out)
out = F.log_softmax(out,dim=1)
return out
def VGGNet():
return VGGbase()
# -------------------------------训练函数----------------------------------------------#
# -------------------------------train.py--------------------------------------------#
import torch
import torch.nn as nn
import torchvision
from vggnet import VGGNet
from load_cifar10 import train_data_loader,test_data_loader
import os
import tensorboardX
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
epoch_num = 200
lr = 0.01
net = VGGNet().to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=lr)
# optimizer = torch.optim.SGD(net.parameters(),lr=lr,momentum=0.9,weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.9)
for epoch in range(epoch_num):
# print("Epoch is:",epoch)
net.train()
for i,data in enumerate(train_data_loader):
# print("step:",i)
inputs,labels = data
inputs,labels = inputs.to(device),labels.to(device)
outputs = net(inputs)
loss = loss_func(outputs,labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print("step:",i,"loss is:",loss.item())
_,pred = torch.max(outputs.data,dim=1)
correct = pred.eq(labels.data).cpu().sum()
batch_size = 128
print("Epoch is:", epoch)
print("lr is", optimizer.state_dict()["param_groups"][0]["lr"])
print("step:", i, "loss is:", loss.item(),
"mini-batch correct is:",100.0 * correct / batch_size)
if not os.path.exists("models"):
os.mkdir("models")
torch.save(net.state_dict(),"models/{}.pth".format(epoch + 1))
scheduler.step()
# print("lr is",optimizer.state_dict()["param_groups"][0]["lr"])
运行结果:


# -------------------------------测试函数----------------------------------------------#
# -------------------------------test.py--------------------------------------------#
import torch
import torch.nn as nn
import torchvision
from vggnet import VGGNet
from load_cifar10 import train_data_loader,test_data_loader
import os
import tensorboardX
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
epoch_num = 200
lr = 0.01
net = VGGNet().to(device)
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(),lr=lr)
# optimizer = torch.optim.SGD(net.parameters(),lr=lr,momentum=0.9,weight_decay=5e-4)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer,step_size=5,gamma=0.9)
for epoch in range(epoch_num):
# print("Epoch is:",epoch)
# net.train()
sum_loss = 0
sum_correct = 0
for i,data in enumerate(test_data_loader):
net.eval()
# print("step:",i)
inputs,labels = data
inputs,labels = inputs.to(device),labels.to(device)
outputs = net(inputs)
loss = loss_func(outputs,labels)
# print("step:",i,"loss is:",loss.item())
_,pred = torch.max(outputs.data,dim=1)
correct = pred.eq(labels.data).cpu().sum()
batch_size = 128
sum_loss = sum_loss + loss.item()
sum_correct = sum_correct + correct.item()
# print("Epoch is:", epoch)
# print("lr is", optimizer.state_dict()["param_groups"][0]["lr"])
# print("test step:", i, "loss is:", loss.item(),
# "mini-batch correct is:",100.0 * correct / batch_size)
test_loss = sum_loss * 1.0 / len(test_data_loader)
test_correct = sum_correct * 100.0 / len(test_data_loader) / batch_size
print("Epoch is:", epoch + 1)
print("test step:", i, "loss is:", test_loss,
"test correct is:", test_correct)
# if not os.path.exists("models"):
# os.mkdir("models")
#
# torch.save(net.state_dict(),"models/{}.pth".format(epoch + 1))
# scheduler.step()
# print("lr is",optimizer.state_dict()["param_groups"][0]["lr"])















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











