






使用Pytorch通过卷积神经网络实现CIFAR10数据集的分类器
最下面自己写的通过csv保存数据的部分太捞了,参考其他方法:tensorboard、wandb、np.save等
引言
在本次实验中,会使用Pytorch来实现一个卷积神经网络,之后对CIFAR-10数据集进行训练,保存训练模型参数,绘制loss图并保存,使用训练得到的模型对训练集与测试集的数据进行准确率测试,并将多次训练后得到的测试结果记录到对应的csv文件中。
CIFAR-10数据集
CIFAR10数据集一共有60000张32*32的彩色图,共有十类,每类6000张,其中5000张训练图,1000张测试图;也就是一共有50000张图用来训练,10000张图用来测试。
十类分别是:plane, car, bird, cat, deer, dog, frog, horse, ship, truck.
更多关于CIFAR-10和CIFAR-100的信息可以看这里
事前准备
-
声明:文档中的代码在拷贝与修改的过程中可能会有错误,具体以实际的代码为准
-
在data文件夹的声明CIFAR10数据文件夹中创建一个文件夹叫save_model,用来存储训练得到的模型参数
-
使用createcsv.py创建两个csv文件,用来存储每次训练之后测试得到的训练集与测试集的准确度,因为想是csv文件中第一行写上10个类别与总的准确度,以后每次测试完都在下面追加,就把第一行单独先写好,以后测试完直接打开追加即可,代码如下:
import csv classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck','Total'] with open('TrainAccHistory.csv', 'w', newline='', encoding='utf-8') as f: writer = csv.writer(f) writer.writerow(classes) with open('TestAccHistory.csv', 'w', newline='', encoding='utf-8') as f: writer = csv.writer(f) writer.writerow(classes) -
下载数据集,可以通过链接直接下载,下载完记得在对应的data文件夹里解压,不然会报错,当然也可以在代码中通过设置download属性进行下载,后面放出来。
开始实验
导入需要的模块
我们需要torch模块来创建网络,优化器,损失函数等;需要torchvision模块将下载的数据集做成dataset与loader,以便后续操作;需要matplotlib下的pyplot子库来显示一些图片,绘制并保存loss图;需要os库对文件夹内容进行判断以确定不同的行动分支;使用numpy显示一些数据集中的图片;需要time库查看训练时间等(可以不要);需要csv库将测试结果存到对应的csv文件中。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data as Data # to make Loader
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import os
import numpy as np
import time
import csv
初始化一些参数
包括训练迭代的次数EPOCH;每次训练的批数目BATCH_SIZE;学习率LR;是否下载数据集DOWNLOAD_CIFAR10;
device用来表示使用cpu还是gpu;transform用来将数据进行能够训练的转化;还有10类数据的名字
EPOCH = 2
BATCH_SIZE = 4
LR = 0.001
DOWNLOAD_CIFAR10 = False
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
train_data = torchvision.datasets.CIFAR10(
root='./data',
train=True,
download=DOWNLOAD_CIFAR10,
transform=transform
)
train_loader = Data.DataLoader(
train_data,
batch_size=BATCH_SIZE,
shuffle=True,
# num_workers=2 # ready to be commented(windows)
)
test_data = torchvision.datasets.CIFAR10(
root='./data',
train=False,
download=DOWNLOAD_CIFAR10,
transform=transform,
)
test_loader = Data.DataLoader(
test_data,
batch_size=BATCH_SIZE,
shuffle=False,
# num_workers=2
)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
其中的一些参数说明:root表示数据集所在的目录;train=True表示将是训练集的数据提出来,False就是将测试的那部分提出来;download表示是否进行下载,因为前面用链接下载解压过了,所以设置的DOWNLOAD_CIFAR10为False;transform表示进行相应转化(转成灰度以及其他格式)。DataLoader中的第一个参数表示用来做成迭代器Loader的数据集;第二个参数batch_size即为每次load出来的图片数;shuffle参数表示是否在每个epoch开始的时候将数据集重新打乱;num_workers表示用来处理data的进程数,在windows下抱错,直接注释掉即可。(参考文档)
显示一些图片
下面试着显示一下几张图,看看有没有load成功:
def imshow(img):
img = img /2 +0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1,2,0)))
plt.show()
dataiter = iter(train_loader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))
因为上面设置的batch_size为4,所以这里就打印4个labels,得到的结果是:

关闭窗口之后即可在终端看到对应的labels,分别为: cat frog frog car
将这段显示图片的注释掉,进行后续实验,不然每次运行都显示就有点烦(强迫症哈哈哈)
定义卷积神经网络
采用LeNet5模型,即两层卷积核为5*5的卷积层,两层最大池化层,三层全连接层:
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10) # result is ten kinds of item
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16*5*5) # reshape to 16*5*5 to fc
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
output = self.fc3(x)
return output
cnn = CNN()
注意每次卷积之后都要经过一层激活层再进行最大池化层,激活函数用的是relu().
定义损失函数与优化器
optimizer = optim.Adam(cnn.parameters())
loss_func = nn.CrossEntropyLoss()
损失函数使用的CrocsEntropyLoss(), 优化器使用的是据说是优化器中的集大成者: Adam,不需要传入学习率,但是在保存模型参数的时候需要将Adam优化器的参数也要保存,以便下次在这个模型参数基础上训练时使用该参数,如果不保存可能会影响结果,于是将状态信息定义成下面这样:
state = {'cnn': cnn.state_dict(), 'optimizer': optimizer.state_dict()}
包括卷积神经网络的状态以及优化器的状态,将来训练完之后保存。
绘制并保存loss图可以用如下方式实现:
losses = [] # record losses
def save_losses(losses):
t = np.arange(len(losses))
plt.plot(t, losses)
plt.savefig('loss.png')
# plt.show()
定义训练函数
下面定义训练函数,对train_loader load的数据进行训练:
def train():
global losses
for epoch in range(EPOCH):
running_loss = 0.0
for step, (inputs, labels) in enumerate(train_loader, 0):
# inputs, labels = data[0].to(device), data[1].to(device)
inputs = inputs.to(device) # 2
labels = labels.to(device)
optimizer.zero_grad()
output = cnn(inputs)
loss = loss_func(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if step % 100 == 99:
loss_num = running_loss / 100
losses.append(loss_num)
print('|epoch: %d, step: %5d| -> loss: %.3f|' %(epoch+1, step+1, loss_num))
running_loss = 0.0
# save losses
save_losses(losses)
训练完之后调用上面定义的save_losses函数,保存此次训练的loss图像
开始训练
训练需要判断模型参数保存的状态,因此加入分支:
start = time.time()
model_save_path = './data/cifar-10-batches-py/saved_model/'
model_path = model_save_path + 'saved_model.pth'
if not os.path.exists(model_save_path):
os.makedirs(model_save_path)
if os.path.isfile(model_path): # if there has been the file, train on it
cnn.load_state_dict(torch.load(model_path)['cnn'])
optimizer.load_state_dict(torch.load(model_path)['optimizer'])
print("Loaded model parameters from disk successfully!")
train()
print("Training Finished!")
torch.save(state, model_path)
print("Model Saved Complete!")
else:
train()
print("Training Finished!")
torch.save(state, model_path)
print("Model Saved Complete!")
end = time.time()
print('takes:', end-start,'s')
第一个if:当不存在模型参数保存目录时,创建该目录。之后开始判断是否已经有参数:①如果已经有了,则使用torch.load函数读取参数,并使用正确的键值分别赋给cnn和optimizer,之后在此网络与优化器参数的基础上继续进行训练,最后打印一下训练大致用时。每次训练之后都要记得保存cnn与optimizer的状态。
测试训练集与测试集的准确度
下面只放出对训练集的测试,对于测试集的测试,只需要将相应的train改成test即可:比如train_loader改成test_loader,train_total改成test_total,trainAccHistory.csv改成testAccHistory.csv等等即可:
# test and get accuracy
correct_time = time.time()
classes_correct = [0 for i in range(10)]
classes_total = [0 for i in range(10)]
pass_total = 0
train_total = 50000
test_total = 10000
# test train_data
print("-----Test Train results-----")
with torch.no_grad():
for (images, labels) in train_loader:
output = cnn(images)
_, prediction = torch.max(output, 1)
c = (prediction == labels).squeeze()
for i in range(BATCH_SIZE):
label = labels[i]
classes_correct[label] += c[i].item()
classes_total[label] += 1
accNow = []
for i in range(len(classes)):
print("%3d of %4d passed | accuracy of %5s -> %2d %%" % (classes_correct[i], classes_total[i], classes[i],round(100*classes_correct[i]/classes_total[i])))
pass_total += classes_correct[i]
accNow.append(str(round(100*classes_correct[i]/classes_total[i])) + '%')
accNow.append(str(round(100*pass_total/train_total)) + '%')
print("%3d of %4d passed | total accuracy is -> %2d %%" % (pass_total, train_total, round(100*pass_total/train_total)))
print()
with open('TrainAccHistory.csv', 'a+', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(accNow)
now = time.time()
print('test takes:', now-correct_time,'s')
classes_correct表示测试匹配正确的对应类的个数, class_total对应的是每个类的总个数;pass_total是匹配正确的总个数(训练集的总个数/测试集的总个数);train_total=50000, test_total=10000的意义就很明显了
第一次尝试运行
发现可以正常顺利运行:运行最后的结果大致如下:
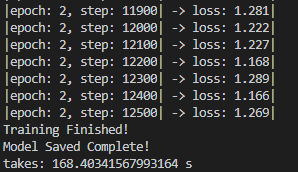
测试结果大致为:

绘制的loss图像大体如下:

此时检查两个csv文件,可以发现,都新增了一行,并且对应的准确率与终端中显示的一致。


使用GPU来训练
刚好之前辛辛苦苦装的GPU版的Pytorch,这次可以拿来试试,于是就查阅资料看看怎么用GPU来训练,找到两个版本:①初始化cnn之后使用cnn.cuda()语句,同时让从DataLoader中拿到的data也使用.cuda()方法;②初始化cnn之后使用cnn.to(device),device即是之前最开始定义的那句 device = torch.device(“cuda:0” if torch.cuda.is_available() else “cpu”),然后让相应的data使用to(device)方法,我这里使用的是第二种方法,大致位置:
...
cnn = CNN()
cnn.to(device)
# train函数中的一部分
for step, (inputs, labels) in enumerate(train_loader, 0):
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
...
# test中的一部分
for (images, labels) in train_loader:
images = images.to(device)
labels = labels.to(device)
output = cnn(images)
...
上面只贴出了测试训练集的一部分,因为测试测试集的部分与这几乎一样,对着改一下就行了,于是删掉保存的模型参数(从头训练),以及两个csv文件中新增的那一行(强迫症),开始训练:
发现训练过程中GPU有在计算,但是最后的结果却不那么如意:

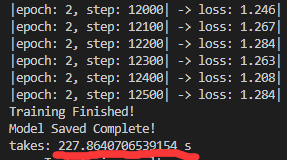
发现最后训练运行的时间不仅没有缩短,竟然还多了1分钟,于是又搜了原因,发现是因为上面吧batch_size设置为4,太小了,不能体现GPU的能力,于是就将BATCH_SIZE直接提高到100,再次复原到初始状态重新训练:
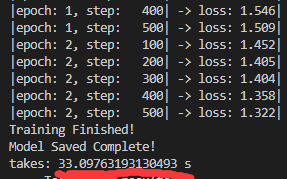
发现训练2次仅用了33秒,速度相当于用CPU运行的5倍,于是成功的使用GPU进行训练,并且节省了时间。
最后开始集体训练
最后将EPOCH设为10,BATCH_SIZE设为100,一切恢复到初始状态开始从头训练,之后每次都在上一次训练得到的模型参数的基础上进行训练,经过7次的训练发现如下结果:
①从保存的loss1-7七张loss图中可以发现loss在不断减少,从2一直减少到0.3左右。
②但是,观察保存的TrainAccHistory.csv与TestAccHistory.csv:


发现:训练集的测试结果的准确率在不断上升,而测试集测试的准确率却呈现出下降的趋势。
推测原因
应该是出现了过拟合,导致不断训练时,训练集的准确率不断增大,而测试集的准确率不断减小。个人觉得可能因为定义的CNN网络结构不够好;或是训练集与测试集的样本太少了,每一类才5000张用来训练,1000张用来测试。
试图优化
于是便想着是否可以更改网络结构来提高准确率,于是google了一下“cifar10 准确率”,搜到一篇博客,使用的是VGG-16的删减版,在原本VGG-16的基础上减少了卷积的层数(原来的爆内存),于是弄来试试,网络的定义如下:
class CNN(nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.conv1 = nn.Conv2d(3,64,3,padding=1)
self.conv2 = nn.Conv2d(64,64,3,padding=1)
self.pool1 = nn.MaxPool2d(2, 2)
self.bn1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU()
self.conv3 = nn.Conv2d(64,128,3,padding=1)
self.conv4 = nn.Conv2d(128, 128, 3,padding=1)
self.pool2 = nn.MaxPool2d(2, 2, padding=1)
self.bn2 = nn.BatchNorm2d(128)
self.relu2 = nn.ReLU()
self.conv5 = nn.Conv2d(128,128, 3,padding=1)
self.conv6 = nn.Conv2d(128, 128, 3,padding=1)
self.conv7 = nn.Conv2d(128, 128, 1,padding=1)
self.pool3 = nn.MaxPool2d(2, 2, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.relu3 = nn.ReLU()
self.conv8 = nn.Conv2d(128, 256, 3,padding=1)
self.conv9 = nn.Conv2d(256, 256, 3, padding=1)
self.conv10 = nn.Conv2d(256, 256, 1, padding=1)
self.pool4 = nn.MaxPool2d(2, 2, padding=1)
self.bn4 = nn.BatchNorm2d(256)
self.relu4 = nn.ReLU()
self.conv11 = nn.Conv2d(256, 512, 3, padding=1)
self.conv12 = nn.Conv2d(512, 512, 3, padding=1)
self.conv13 = nn.Conv2d(512, 512, 1, padding=1)
self.pool5 = nn.MaxPool2d(2, 2, padding=1)
self.bn5 = nn.BatchNorm2d(512)
self.relu5 = nn.ReLU()
self.fc14 = nn.Linear(512*4*4,1024)
self.drop1 = nn.Dropout2d()
self.fc15 = nn.Linear(1024,1024)
self.drop2 = nn.Dropout2d()
self.fc16 = nn.Linear(1024,10)
def forward(self,x):
x = self.conv1(x)
x = self.conv2(x)
x = self.pool1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.pool2(x)
x = self.bn2(x)
x = self.relu2(x)
x = self.conv5(x)
x = self.conv6(x)
x = self.conv7(x)
x = self.pool3(x)
x = self.bn3(x)
x = self.relu3(x)
x = self.conv8(x)
x = self.conv9(x)
x = self.conv10(x)
x = self.pool4(x)
x = self.bn4(x)
x = self.relu4(x)
x = self.conv11(x)
x = self.conv12(x)
x = self.conv13(x)
x = self.pool5(x)
x = self.bn5(x)
x = self.relu5(x)
# print(" x shape ",x.size())
x = x.view(-1,512*4*4)
x = F.relu(self.fc14(x))
x = self.drop1(x)
x = F.relu(self.fc15(x))
x = self.drop2(x)
x = self.fc16(x)
return x
将之前用LeNet5网络训练得到的参数改下名字,防止覆盖,之后开始训练10个epoch,经过漫长的等待,得到了结果:
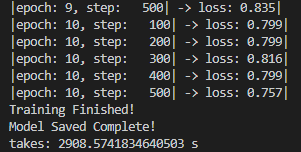
同时得到的训练集与测试集的准确率分别是74%跟71%,好像有点用,之后在模型参数的基础上又训练了4次,从lossvgg1-5可以看到loss从2降到0.1左右,训练集与测试集的准确率分别为:


发现测试集的准确率到达最高点81%之后又有下降的趋势,可能又出现过拟合了,不过81%的准确率比一开始的64%的准确率高很多了。
也算是成功优化了,也证实了确实是因为网络结构的原因,准确率才这样低。
继续修改优化
可是网上看到的理论上这些网络结构准确率能上90%啊,这还差得远呢,于是继续搜索网络结构,先是找了ResNet的网络,选择的是ResNet18,结果准确率也只能到84%,后来发现在最开始对数据的预处理也很重要,也就是transform的设置,文档中提供的是这样的:
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
后来找到的准确率比较高的transform是这样的:
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
并分别将train_data中的transform改成transform_train,test_data中的transform改成transform_test,重新对ResNet18进行训练。
ResNet的定义如下:
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, num_classes=10):
super(ResNet, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
self.linear = nn.Linear(512*block.expansion, num_classes)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def ResNet18():
return ResNet(BasicBlock, [2,2,2,2])
def ResNet34():
return ResNet(BasicBlock, [3,4,6,3])
def ResNet50():
return ResNet(Bottleneck, [3,4,6,3])
def ResNet101():
return ResNet(Bottleneck, [3,4,23,3])
def ResNet152():
return ResNet(Bottleneck, [3,8,36,3])
先是定义两个辅助类BasicBlock和Bottleneck,之后定义ResNet类。根据参数不同,有ResNet18,ResNet34,ResNet50,ResNet101和ResNet152。
因为用的是老师提供的GPU,训练完之后修改文件名什么的很麻烦,就没有保存对应的多次训练的loss图,不过大致跟前面记录的LeNet5和伪VGG的差不多,就直接看结果:
训练集的准确度:

发现第五次就已经接近100%了
测试集的准确度:

发现训练50个epoch(每次是10个epoch)之后测试集就达到了90%的准确度,后面试图看看能不能上到91%,发现又训练了20个epoch,发现并没有变化(可能小数点后面的数值增大了,不过90%已经足够了)
后来又选用DPN的网络结构进行训练,同样是用上面的两个transform,网络定义如下:
class Bottleneck2(nn.Module):
def __init__(self, last_planes, in_planes, out_planes, dense_depth, stride, first_layer):
super(Bottleneck2, self).__init__()
self.out_planes = out_planes
self.dense_depth = dense_depth
self.conv1 = nn.Conv2d(last_planes, in_planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(in_planes)
self.conv2 = nn.Conv2d(in_planes, in_planes, kernel_size=3, stride=stride, padding=1, groups=32, bias=False)
self.bn2 = nn.BatchNorm2d(in_planes)
self.conv3 = nn.Conv2d(in_planes, out_planes+dense_depth, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_planes+dense_depth)
self.shortcut = nn.Sequential()
if first_layer:
self.shortcut = nn.Sequential(
nn.Conv2d(last_planes, out_planes+dense_depth, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_planes+dense_depth)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
x = self.shortcut(x)
d = self.out_planes
out = torch.cat([x[:,:d,:,:]+out[:,:d,:,:], x[:,d:,:,:], out[:,d:,:,:]], 1)
out = F.relu(out)
return out
class DPN(nn.Module):
def __init__(self, cfg):
super(DPN, self).__init__()
in_planes, out_planes = cfg['in_planes'], cfg['out_planes']
num_blocks, dense_depth = cfg['num_blocks'], cfg['dense_depth']
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.last_planes = 64
self.layer1 = self._make_layer(in_planes[0], out_planes[0], num_blocks[0], dense_depth[0], stride=1)
self.layer2 = self._make_layer(in_planes[1], out_planes[1], num_blocks[1], dense_depth[1], stride=2)
self.layer3 = self._make_layer(in_planes[2], out_planes[2], num_blocks[2], dense_depth[2], stride=2)
self.layer4 = self._make_layer(in_planes[3], out_planes[3], num_blocks[3], dense_depth[3], stride=2)
self.linear = nn.Linear(out_planes[3]+(num_blocks[3]+1)*dense_depth[3], 10)
def _make_layer(self, in_planes, out_planes, num_blocks, dense_depth, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for i,stride in enumerate(strides):
layers.append(Bottleneck2(self.last_planes, in_planes, out_planes, dense_depth, stride, i==0))
self.last_planes = out_planes + (i+2) * dense_depth
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.linear(out)
return out
def DPN26():
cfg = {
'in_planes': (96,192,384,768),
'out_planes': (256,512,1024,2048),
'num_blocks': (2,2,2,2),
'dense_depth': (16,32,24,128)
}
return DPN(cfg)
def DPN92():
cfg = {
'in_planes': (96,192,384,768),
'out_planes': (256,512,1024,2048),
'num_blocks': (3,4,20,3),
'dense_depth': (16,32,24,128)
}
return DPN(cfg)
同样是需要一个辅助类Bottleneck2(因为上面已经用到Bottleneck了,所以取名加个2),之后定义DPN类以及根据参数的不同有DPN26与DPN92。
选用DPN92进行训练,同样没有一次记录loss图,直接看结果:
训练集的准确率结果:
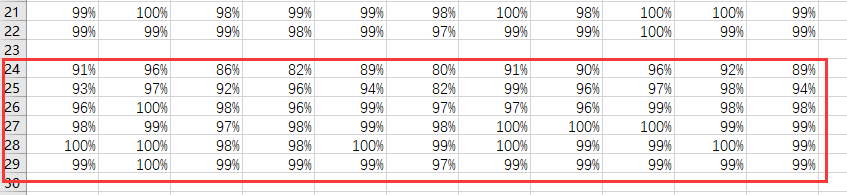
测试集的准确率结果:
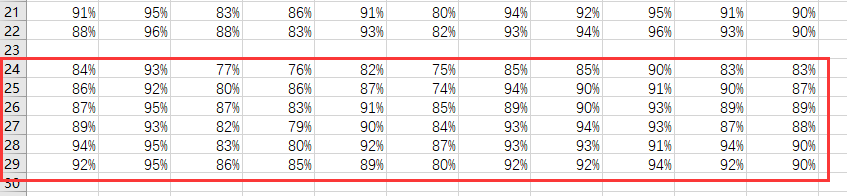
最后也成功上升到了90%,不过第四次训练有点神奇:

前面几个epoch的loss都在0.07左右,这里突然跳到0.3,才导致上面的准确率变到了88%,不过整体的loss是下降的。
可能其他方面还能继续优化,比如对图像预处理的时候可以让每个epoch训练的时候讲训练集的数据进行打乱,可以避免每个epoch都是同样的顺序进行训练而容易出现过拟合等。这里就先记录这么多。
以上训练过的模型参数记录都存在./data/cifar-10-batches-py/saved_model目录中。
可能其他方面还能继续优化,比如对图像预处理的时候可以让每个epoch训练的时候讲训练集的数据进行打乱,可以避免每个epoch都是同样的顺序进行训练而容易出现过拟合等。这里就先记录这么多。
以上训练过的模型参数记录都存在./data/cifar-10-batches-py/saved_model目录中。















 872
872











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









