






大家好,模特换装一般来说通过图生图方式实现的,也是可以通过ControlNet来实现,下面我们就来看看如何通过ControlNet实现模特换装。
【第一步】:ControlNet的参数设置
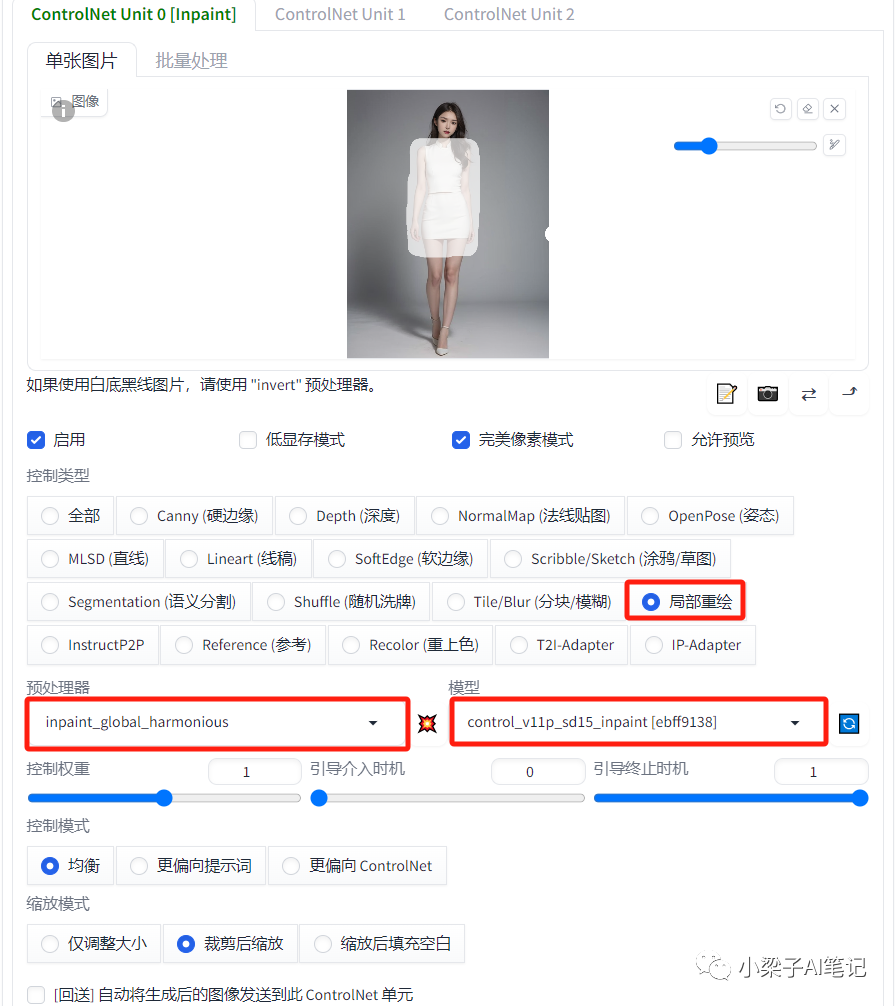
使用右边红框的画笔,将模特的服装区域涂白(这里根据需要选择服装的涂白区域,比如有些是涂白衣服,有些是涂白裤子等)。
相关参数设置如下:
-
控制类型:选择"局部重绘"
-
预处理器:inpaint_global_harmonious(重绘-全局融合算法)
-
模型:control_xxx_inpaint
-
控制权重 : 1
在ControlNet中,提供了inpaint(局部重绘)控制类型,该控制类型功能和图生图局部重绘功能类似,但是在图像的修复和调整方面功能更强大。这里预处理器选择inpaint_global_harmonious,从命名可以看出它是将原图进行重新绘制,然后只取蒙版部分填补进来。这种预处理器算法的优点就是重绘部分和整体的融合程度最高。

【第二步】提示词的编写
这里提示词可以只写图片中包含的元素以及图片质量的相关提示词即可。
原图片提示词:(masterpiece, best quality:1.4),finely detailed,1girl,solo,pale
skin,perfect body,standing,(full body photo),
变装图片提示词:(masterpiece, best quality:1.4),finely detailed,1girl,solo,(***),pale
skin,perfect body,standing,(full body photo),
其中***代表变装的衣服关键词。例如cheongsam(旗袍)
反向提示词:(worst quality:2),(low quality:2),(normal
quality:2),lowres,watermark,ng_deepnegative_v1_75t,EasyNegative,badhandv4,(multiple
girls:1.2),(nipples:1.1),(nipple protrusion:1.1),nsfw,red
eyes,(mole),(freckles),extra arms,extra limb,mutated hands,missing
fingers,fused fingers,too many fingers,(blurry
background:1.2),(2girls:1.2),(fingers that cannot be drawn well:1.2),nsfw
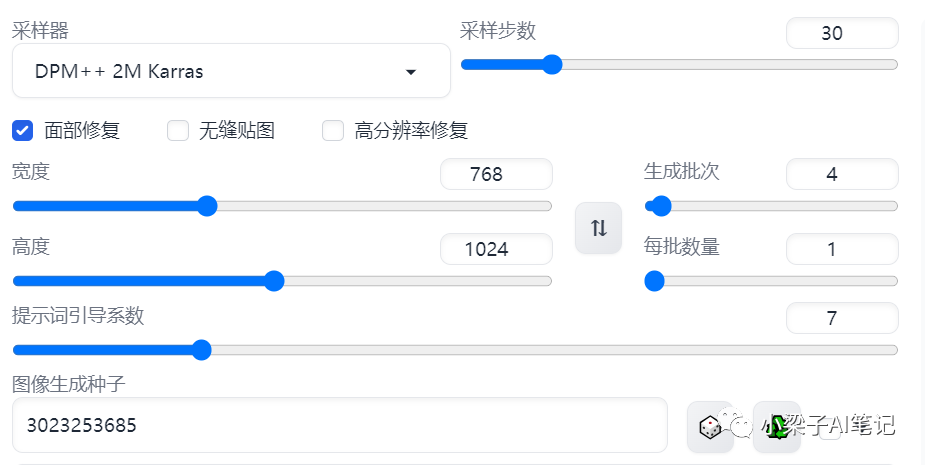
文生图相关参数设置
-
采样器:DPM++2M Karras
-
采样迭代步数:30
-
图片宽高:768*1024 保持和上传的图片宽高一致或者定比例的放大或者缩小。
-
图像生成种子:和原图片的种子保持一致。
【第三步】大模型的选择以及图片的生成
大模型我们选择一个写实的大模型,这里我们选择majicMIX realistic,其他大模型Chilloutmix、RealisticVersion都可以。
原图

正向提示词:(pink dress)(粉色裙子)


正向提示词:white slip dress(白色吊带裙)

正向提示词:cheongsam(旗袍)


正向提示词:hanfu(汉服)


相关说明:
(1)
ControlNet的inpaint模型预处理器inpaint_global_harmonious是对整张图进行绘制,重绘之后图片整体融合度比较好,但是对整张图片的绘制仍然会对原图非蒙版部分有影响,特别是图片背景元素比较多的情况,重绘可能会改变图片的色调。
本文的原美女图片是AI生成的图片,针对AI生成的图片做加工处理,因为有原图片的关键词,参数,种子作为固定,能基本保证非蒙版区域不变。
(2) ControlNet的inpaint模型预处理器inpaint_only只会重绘涂白的蒙版区域,针对今天案例中的美女图片效果还是非常不错的。




(3)ControlNet的inpaint模型预处理器到底使用inpaint_global_harmonious还是inpaint_only,还是图生图的局部重绘,一般在图像调整上建议使用inpaint_global_harmonious预处理器,因为能和原图片融合比较好。但是如果是要保持整张图片不变,只修改图片局部,最好使用inpaint_only预处理器,或者图生图的局部重绘。但是任何事情都不是绝对的,还是建议大家都尝试,多实践。
好了,今天的分享就到这里了,希望今天分享的内容对大家有所帮助。
文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,有需要的小伙伴文末扫码自行获取。
由于AIGC刚刚爆火,网上相关内容的文章博客五花八门、良莠不齐。要么杂乱、零散、碎片化,看着看着就衔接不上了,要么内容质量太浅,学不到干货。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以长按下方二维码,免费领取!

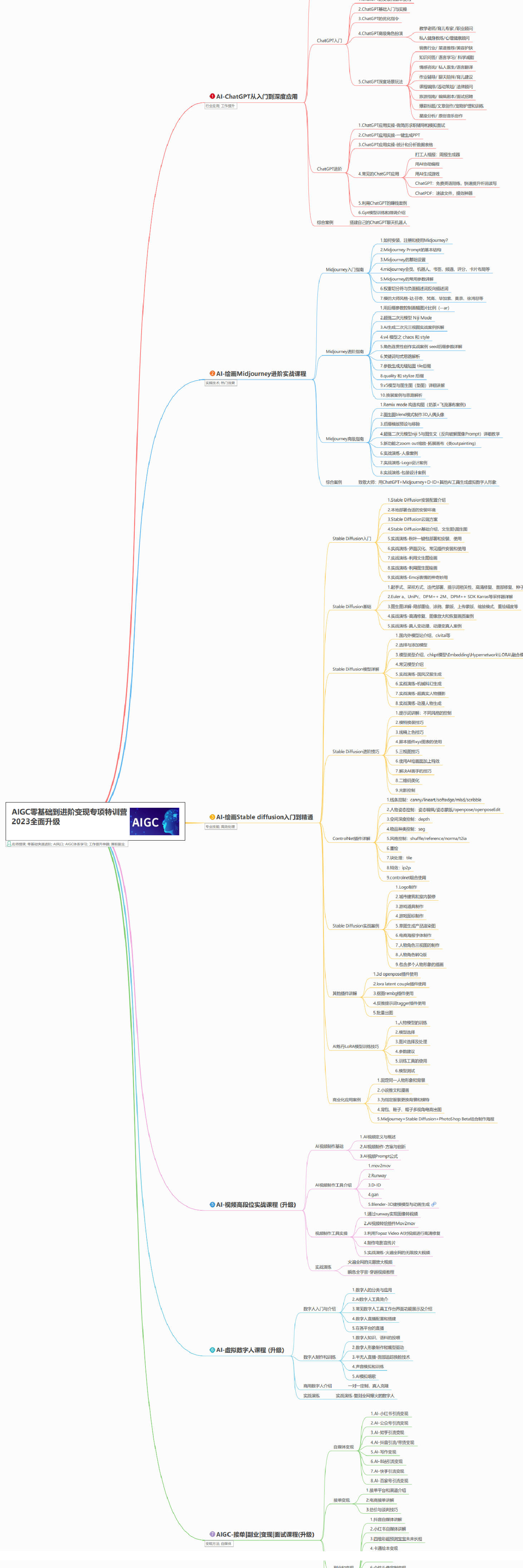
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!
精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。

有需要的朋友,可以长按下方二维码,免费领取!

















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









