



1 谷歌发布 Gemini 3.0,多项基准测试碾压一众模型
刚刚,谷歌发布了其划时代的 AI 模型——Gemini 3.0,与过去以往发布模式不同的是,这次谷歌甚至连一场发布会都没有召开。
过去几个月,谷歌的 Gemini AI 一直深陷争议之中。隐私诉讼、图像生成失败、API 变更破坏性升级激怒了开发者,各种负面新闻层出不穷。人们纷纷指责谷歌急于将产品推向市场,偷工减料,最终在人工智能竞赛中败给了 OpenAI。
在一片骂声中,谷歌只通过一篇博客就放出重磅模型的行为也就不难理解了。
代表 Gemini 团队的谷歌 DeepMind CEO Demis Hassabis 和谷歌 DeepMind CTO 兼谷歌首席人工智能架构师 Koray Kavukcuoglu 共同在官网上发布了这款最强模型的详细介绍。
据介绍,Gemini 3 是谷歌迄今为止 最智能、适应性最 强的模型,能够帮助应对现实世界的复杂性,解决需要增强推理和智能、创造力、战略规划以及逐步改进的问题。它特别适用于需要:智能体性能、高级编码、长上下文和 / 或多模态理解,以及 / 或算法开发的应用。
Gemini 从一开始就旨在无缝整合任何主题的多模态信息,包括文本、图像、视频、音频和代码。Gemini 3 结合了其先进的推理、视觉和空间理解能力、领先的多语言性能以及百万级上下文窗口,相比之下,Claude Sonnet 4.5 和 GPT 5.1 的最大输出量停留在数万或者数十万级别。
Gemini 3.0 已第一时间登陆 AI Studio、Gemini CLI,以及 Cursor、GitHub、JetBrains、Cline 等最重要的开发者入口。
谷歌还表示,今天起,将发布 Gemini 3 Pro 预览版,并将其集成到一系列 Google 产品中。此外,谷歌还将推出 Gemini 3 Deep Think——这是其增强的推理模式,可进一步提升 Gemini 3 的性能——并在向 Google AI Ultra 订阅用户开放之前,先向安全测试人员开放试用。
Gemini 3 Pro 虽然也采用的是稀疏混合专家(MoE)架构,但并不是先前模型的修改或微调版本。这种基于 MoE 设计的核心优势在于实现了总模型容量与单 token 计算成本的解耦——模型可通过大规模参数储备提升能力上限,同时仅激活部分参数完成计算,在保证性能的同时显著降低资源消耗。
例如,如果想学习如何烹饪家族传统菜肴,Gemini 3 可以解读并翻译不同语言的手写食谱,生成可与家人分享的食谱。
或者,如果想学习某个新主题,用户可以提供学术论文、长篇视频讲座或教程,它可以生成交互式记忆卡片、可视化或其他格式的代码,帮助您掌握相关知识。
它甚至可以分析匹克球比赛视频,找出可以改进的地方,并制定训练计划,帮助全面提升球技。
在 2.5 Pro 成功的基础上,Gemini 3 兑现了将开发者的任何想法变为现实的承诺。它在零样本生成方面表现出色,能够处理复杂的提示和指令,从而渲染出更丰富、更具交互性的 Web 用户界面。
据谷歌称,Gemini 3 还是谷歌迄今为止构建的最佳 Vibe Coding 和代理编码模型,它使得谷歌的产品更加自主,并显著提升了开发者的效率。
而在代码能力之外,Google 这次更大的动作,是试图借 Gemini 3 彻底重塑开发体验,让其从“代码自动补全”迈向“agent-first”。
伴随 Gemini 3 发布,他们推出了全新的智能体开发平台 Google Antigravity,目标是让开发者从具体指令、单次调用,跃迁到更高层次的“任务导向型开发”。据说,这是谷歌自己的 VS Code 分支。

除了 Gemini 3 Pro,Antigravity 还深度集成了最新的 Gemini 2.5 Computer Use 模型(用于浏览器自动化操作)以及 Nano Banana。
Gemini 3 系列模型的成功离不开谷歌全栈技术生态的支撑。硬件层面,模型完全基于谷歌张量处理单元(TPU)集群训练,这种专为大语言模型设计的芯片凭借高带宽内存和并行计算能力,较传统 CPU 实现了训练速度的数量级提升。通过 TPU Pods 集群的分布式部署,谷歌将庞大的训练任务拆分至多个设备并行处理,既保证了模型训练的效率,又通过硬件优化践行了可持续运营承诺。
在数据层面,Gemini 3 Pro 的训练数据体系呈现出多元化与高合规性的双重特征。其数据集不仅包括公开网页数据、可下载数据集及商业许可数据,还纳入了符合谷歌服务条款的用户互动数据、员工生成数据及 AI 合成数据。
为平衡数据丰富性与安全性,谷歌建立了多维度数据处理机制:通过遵守 robots 协议规范爬虫行为,利用安全过滤技术践行 AI 安全承诺,同时针对儿童性虐待材料(CSAM)等违法内容实施专项过滤。
特别值得注意的是,模型在训练过程中融入了强化学习技术,通过多步推理、定理证明等专业数据优化问题解决能力。
具体而言,Gemini 3 Pro 在各项基准测试中表现如何?
2 能力到底有多强?
我们在这里专门从 代码能力、数学推理能力,以及 Agent(工具使用与长期任务)能力 三个维度,对 Gemini 3 Pro 的能力进行解读。
在代码生成和工程落地上,Gemini 3 Pro 的跃升非常明显。
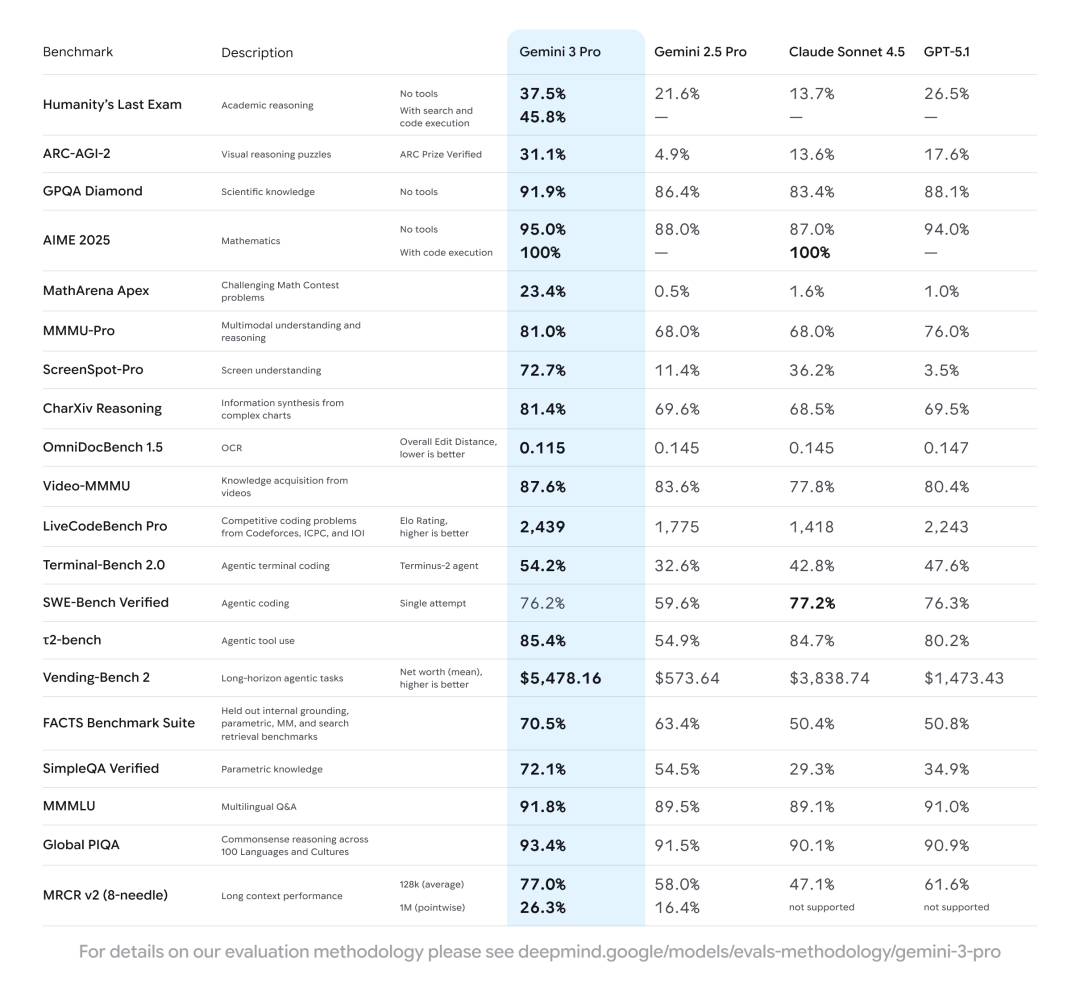
在 LiveCodeBench Pro(接近 ICPC / Codeforces 难度的竞技编程)上,Gemini 3 Pro 得分 2439(Elo,数值越高越好),不仅高于 GPT-5.1 的 2243,也远超 Claude 4.5 的 1418。这个分数段基本已经逼近“专业竞赛级程序员”的水平,而且在同类模型中优势最为明显——在高难度算法与数据结构题上,G3 Pro 已经是第一梯队。
在 SWE-bench Verified(真实 GitHub issue 自动修复,Agentic coding)上,Gemini 3 Pro 得分 76.2%,与 GPT-5.1 的 76.3% 几乎持平,略低于 Claude 4.5 的 77.2%。SWE-bench Verified 更接近真实工程环境:多文件仓库、测试驱动、一次性打补丁。G3 Pro 在这一指标上已经稳居顶级模型阵营,与 GPT-5.1 和 Claude 4.5 基本等价,而相较 2.5 Pro 则是一次“代际级”跨越。
在数学方面*AIME 2025 这一项,Gemini 3 Pro 裸分为 95%,开启 code execution 后可以做到 100%。这里的 “100% with code execution” 意味着模型能够主动调用 Python 等工具链完成严格推导——这其实是 Agent 能力与推理能力深度融合 的一个关键信号。这个成绩不仅高于 GPT-5.1 的 94%,也领先于 Claude 4.5 的 87%(Claude 同样在开启 code execution 时可达 100%)。
AIME 2025 被认为是全球最难的高中奥数试题集合,MathArena Apex 的难度则接近大学高等数学 / 奥数级别。在 MathArena Apex 上,Gemini 3 Pro 远超其他模型(Gemini 2.5 Pro 仅 0.5%)。因此,Gemini 3 Pro 的核心升级并不仅仅是模型变大,而是 “推理能力 + 工具链整合” 的双重跃迁。
在 Agent 能力方面,Gemini 3 Pro 的提升可以说是“断层式”的。无论是工具调用、操作系统级任务,还是跨阶段的长期规划,它都展现出了超越前代、并跻身行业顶尖的综合能力。
t2-bench(工具调用 & 操作系统任务,Agentic tool use),Gemini 3 Pro 得分 85.4%,与 Claude 4.5 的 84.7% 基本持平,明显高于 GPT-5.1 的 80.2%,远超 2.5 Pro 的 54.9%。t2-bench 主要考察模型在真实软件环境中“使用工具执行任务”的能力,包括 API 调用、函数调用、文件操作、系统指令执行等典型 Agent 行为。
这一项是“Agent 的真正核心竞争力”。Gemini 3 Pro 在此不仅与 GPT-5.1、Claude 4.5 并列顶尖阵营,还明显比上一代 2.5 Pro 高出一个量级。
Vending-Bench 2(长期任务规划,越高越好),Gemini 3 Pro 得分 $5,478,显著高于 Claude 4.5 的 $3,838,大幅领先 GPT-5.1 的 $1,473,也远超 2.5 Pro 的 $573。Gemini 3 Pro 的表现可以说是“代际级领先”。在长任务执行、自动化工作流、任务可靠性上,它不仅进入第一梯队,甚至与竞品拉开了非常明显的差距。
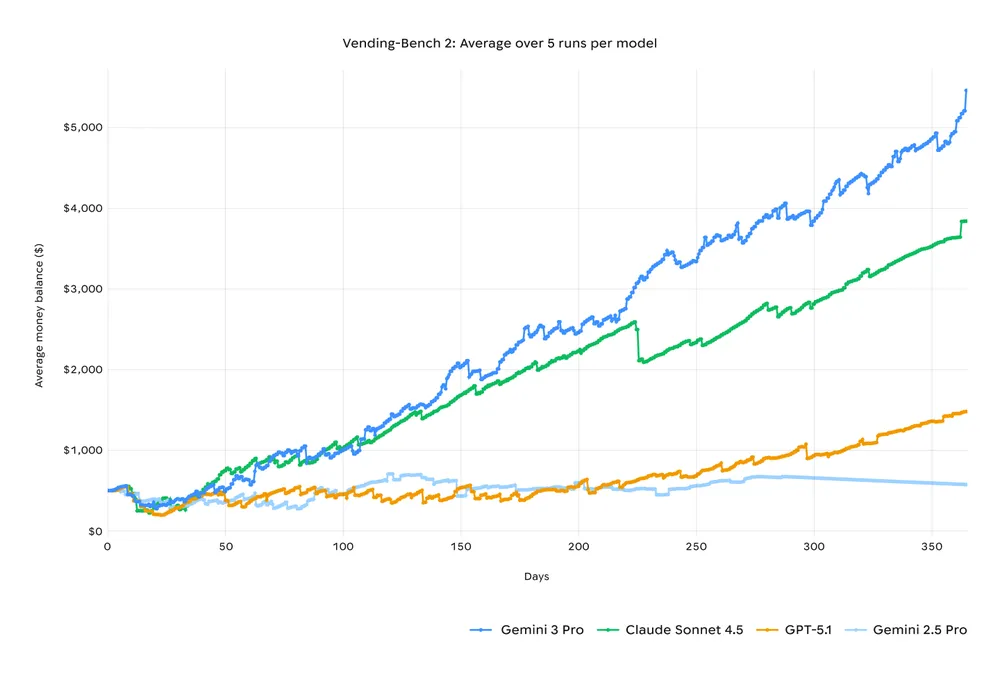
Terminal-Bench 2.0(Unix 环境指令执行 & 自动修复)中,Gemini 3 Pro 得分为 54.2%,明显高于 GPT-5.1 的 47.6%、Claude 4.5 的 42.8%,以及 Gemini 2.5 Pro 的 32.6%。
Terminal-Bench 测试的是一个 Agent 在真实 Unix 环境中能否读日志、定位问题,执行文件系统操作,修改配置并验证结果,完成类似 CI 的自动修复流程——本质上是在回答一个问题:“这个东西能不能真的上生产系统?” 在这一项上,Gemini 3 Pro 的表现同样处于显著领先的位置。
从代码助手到 Agent 开发新基建
这种能力跃升背后,是谷歌对“AI + 软件开发”路线的集中押注。
在今年 2 月推出 Gemini 2 后,谷歌在 4 月迅速调整了 Gemini 的管理层,将领导权交给了 Google Labs 负责人 Josh Woodward——这位同时负责 otebook LM 与 Project Mariner(Chrome 控制 Agent)的产品负责人,长期深耕“AI + 软件开发”,对编码工作流与 Agent 思维方式有深刻理解。
Woodward 在多次公开讨论中也强调了同一件事:代码,是 Google 内部规模最大、持续增长最快的 AI 应用场景。“Google 有上万名工程师,而 AI 正在重塑整个软件生产流程,所以我们会从‘软件开发的未来是什么样?’开始思考,既对 Google 内部构建,也对外部用户负责。”
Jeff Dean 也曾公开表示,Google 内部已有 25% 的代码由 AI 自动生成,而且这个比例还在快速增长。换句话说,Gemini 每一次的迭代,都直接影响着谷歌数万工程师的生产方式。
按 Woodward 此前的说法,编程是一个被低估的方向:“如果你能让代码模型自己写代码、自己纠错、自己修复、自己迁移旧系统,那你会发现:原本已经很快的技术进步曲线,会被彻底改写。 所以我觉得这块虽然已经炒得很热了,但远远不够热,它应该被炒得更热。”
在他看来,未来系统将依赖更长上下文、更深的工具链整合以及更强的自动化能力去完成复杂工作流,而编码能力正是这一切的地基。换句话说,Gemini 的代码能力不只是产品特性,而是 Google 推动下一代 Agent、自动化系统和 AI 原生软件工程的战略支点。
从这组信号来看,Gemini 3 Pro 在代码生成、工程修复与 Agent 能力上的大幅跃升,并不是偶然,而是谷歌从领导层到产品方向的刻意押注。
3 网友评价如何?
Gemini 3 才发布不到一小时的时间,网上的讨论早已铺天盖地,甚至比产品本身更“热闹”。在 Hacker News、Reddit 等平台上,从专业开发者到普通用户,评论区呈现出罕见的两极分化:有人直呼“终于追上了”、有人冷嘲“你这不叫卷,这是自救”,也有人担心谷歌是否还能回到巅峰时代。
在 Reddit 上,有用户表示:“至少这次没摆烂,性能上终于能正面跟上 GPT 系列。”
还有用户称: “多模态响应速度快了很多,尤其是视频理解像那么回事了。代码能力回来了,谷歌终于不像去年那么迷茫。”
但也有用户对 Gemini 3 表示失望。该网友认为谷歌这次并没有交出很好的答卷。
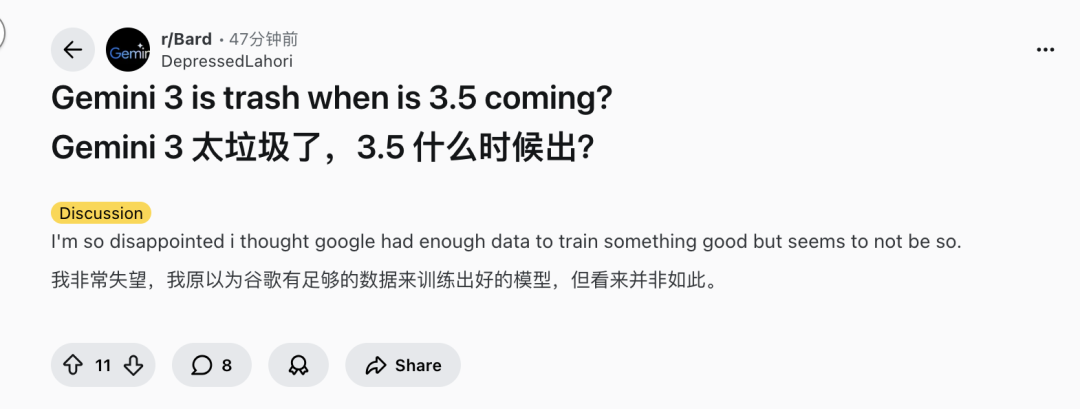
在 X 上,有网友吐槽了谷歌这次模型发布的形式过于枯燥。他认为需要改进的可能并不是模型本身,而是谷歌的发布方式。他评论称:“只有博客文章的发布形式太无聊了。”
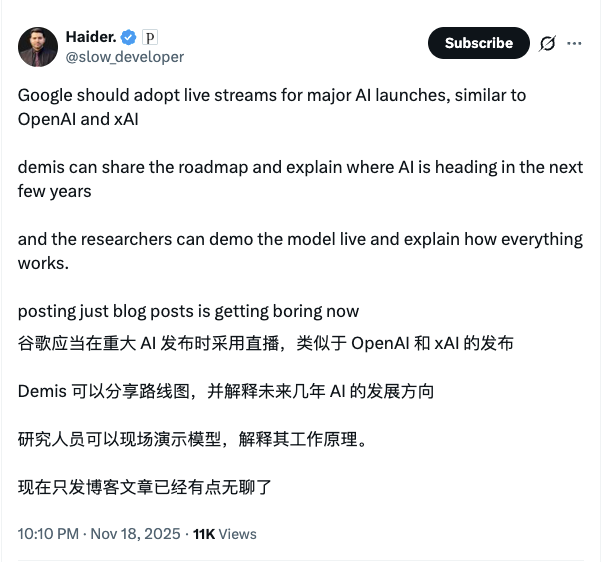
还有网友表示,大模型进入到现在这个阶段后,对用户来说更具性价比的产品更能吸引和留住用户。
“实际上,采取一种更为务实的策略或许是可取的:推出一些在技术上未必最前沿,但在经济上极具吸引力的产品。当前,模型在某些高度专业化或小众领域(例如深度推理、金融、哲学等)的性能提升,对大多数用户而言已不易感知,甚至难以察觉。
如果能推出一款产品,在内存容量、上下文窗口大小上超越 GPT-5.1将极具竞争力。
一旦技术性能的增长进入平台期,企业就必须通过功能创新实现差异化,或是通过降低成本来维持竞争力。如果他们选择后者,并借此削弱 OpenAI 的用户获取与留存能力,这或许将改变市场竞争格局——OpenAI 可能难以承受用户增长放缓甚至流失的压力,而谷歌这类公司则更有能力应对这样的局面。”
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


















 235
235

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









