






链接:https://arxiv.org/abs/2408.05911
原标题:A New Pipeline For Generating Instruction Dataset via RAG and Self Fine-tuning
日期:Submitted on 12 Aug 2024

Abstract
摘要
With the rapid development of large language models (LLMs) in recent years, there has been an increasing demand for domain-specific Agents that can cater to the unique needs of enterprises and organizations. Unlike general models, which strive for broad coverage, these specialized Agents rely on focused datasets tailored to their intended applications. This research proposes a pipeline that leverages the power of LLMs and the Retrieval-Augmented Generation (RAG) related framework to construct high-quality instruction datasets for finetuning on specific domains using custom document collections. By ingesting domain-specific documents, the pipeline generates relevant and contextually appropriate instructions, thus effectively creating a comprehensive dataset for fine-tuning LLMs on the target domain. This approach overcomes the limitations of traditional dataset creation methods, which often rely on manual curation or web-scraping techniques that may introduce noise and irrelevant data. Notably, our pipeline offers a dynamic solution that can quickly adapt to updates or modifications in the domainspecific document collection, eliminating the need for complete retraining. Additionally, it addresses the challenge of data scarcity by enabling the generation of instruction datasets from a limited set of initial documents, rendering it suitable for unpopular or specialized domains where comprehensive datasets are scarce. As a case study, we apply this approach to the domain of psychiatry, a field requiring specialized knowledge and sensitive handling of patient information. The resulting fine-tuned LLM demonstrates showcases the viability of the proposed approach and underscores its potential for widespread adoption across various industries and domains where tailored, accurate, and contextually relevant language models are indispensable.
近年来,随着大型语言模型(LLMs)的快速发展,对于能够满足企业和组织独特需求的领域特定代理的需求日益增加。与力求广泛覆盖的一般模型不同,这些专业代理依赖于针对其预期应用定制的专注数据集。本研究提出了一种利用LLMs的力量和检索增强生成(RAG)相关框架的管道,以构建用于特定领域微调的高质量指令数据集,使用自定义文档集合。通过吸收领域特定的文档,该管道生成相关且在上下文中适当的指令,从而有效地创建了用于在目标领域上微调LLMs的综合数据集。这种方法克服了传统数据集创建方法的局限性,后者通常依赖于可能引入噪声和无关数据的手动策划或网络抓取技术。值得注意的是,我们的管道提供了一个动态解决方案,可以快速适应领域特定文档集合中的更新或修改,无需完全重新训练。此外,它通过允许从有限的初始文档集生成指令数据集,解决了数据稀缺的挑战,使其适用于缺乏综合数据集的不受欢迎或专业领域。作为一个案例研究,我们将这种方法应用于精神病学领域,这是一个需要专业知识和对患者信息敏感处理的领域。由此微调的LLM展示了所提出方法的可行性,并强调了其在各个行业和领域广泛采用的前景,在这些领域,量身定制、准确且在上下文中相关的语言模型是不可或缺的。
Keywords—Large Language Model, Retrieval-Augmented
Generation, Psychiatry, Instruction Tuning
关键词—大型语言模型,检索增强生成,精神病学,指令调整
I. INTRODUCTION
I. 引言
Large language models (LLMs) have revolutionized natural language processing, yet face challenges when applied to highly specialized domains. For example, psychiatry requires nuanced understanding of technical terminology, diagnostic criteria, and sensitive patient interactions. However, collecting and curating datasets specific to the domain can be arduous and timeconsuming. This research proposes a pipeline that combines LLMs with the Retrieval-Augmented Generation (RAG)[1]related framework to construct domain-specific instruction datasets. By ingesting curated document collections (e.g., academic papers, clinical guidelines), the pipeline harnesses the generative capabilities of LLMs and the information retrieval strengths of RAG. This iterative process yields comprehensive datasets capturing domain intricacies while maintaining factual accuracy.
大型语言模型(LLMs)已经彻底改变了自然语言处理领域,但在应用于高度专业化的领域时仍面临挑战。例如,精神病学需要精细理解技术术语、诊断标准和敏感的患者互动。然而,收集和策划特定于该领域的数据集可能既困难又耗时。本研究提出了一种将LLMs与检索增强生成(RAG)[1]相关框架相结合的管道,用以构建领域特定的指令数据集。通过吸收策划的文档集合(例如,学术论文、临床指南),该管道利用了LLMs的生成能力和RAG的信息检索优势。这种迭代过程产生了全面的数据集,捕捉到领域的复杂性,同时保持事实的准确性。
As a case study, we apply this approach to psychiatry, utilizing the “Desk Reference to the Diagnostic Criteria from DSM-5” as our primary source document. The DSM-5 (Diagnostic and Statistical Manual of Mental Disorders, Fifth Edition)[2] is a crucial guideline book for psychiatric diagnosis, and the Desk Reference serves as a concise version of this comprehensive manual. We employ the Mistral-7B[3] model as our initial language model and leverage the Langchain framework[4] to implement the RAG technique, effectively imbuing the model with knowledge from the DSM-5.
作为一项案例研究,我们将这种方法应用于精神病学领域,使用《精神疾病诊断与统计手册第五版(DSM-5)》的“诊断标准桌面参考”作为我们的主要源文档。DSM-5(《精神疾病诊断与统计手册》第五版)[2]是精神病学诊断的重要指南书籍,而桌面参考版则是这本综合手册的浓缩版。我们使用Mistral-7B[3]模型作为我们的初始语言模型,并利用Langchain框架[4]来实现RAG技术,有效地将DSM-5的知识注入模型中。
Subsequently, through our carefully designed prompts, we facilitate the language model to generate relevant question-answer pairs in the desired format and content, which we then integrate into an instruction dataset. Finally, we fine-tune our Mistral-7B model using this dataset, transforming it into a specialized agent for the psychiatric domain, dubbed Mistral-7B-dsm5.
随后,通过我们精心设计的提示,我们促使语言模型生成所需格式和内容的相关问题-答案对,然后我们将这些对整合到一个指令数据集中。最后,我们使用这个数据集对Mistral-7B模型进行微调,将其转变为精神病学领域的专业代理,命名为Mistral-7B-dsm5。
In the following sections, we will delve into the intricacies of designing this instruction dataset and discuss our approach to evaluating the performance of Mistral-7B-dsm5 in the psychiatric domain compared to ChatGPT. By employing GPT-4 as an expert judge[5], we aim to validate the effectiveness and viability of our proposed pipeline, demonstrating its potential for creating tailored LLMs across various specialized industries.
在以下部分,我们将深入探讨设计这个指令数据集的复杂性,并讨论我们评估Mistral-7B-dsm5在精神病学领域性能的方法,与ChatGPT进行比较。通过使用GPT-4作为专家评委[5],我们旨在验证我们提出的管道的有效性和可行性,展示其在创建各种专业行业定制LLMs方面的潜力。
II. RELATED WORK
II. 相关工作
A. Self-generate instruction dataset
A. 自生成指令数据集
The success of ChatGPT has popularized the use of Instruction Tuning [6], subsequently validated by related research as the most effective fine-tuning approach for question-answering tasks [7]. However, the lack of available instruction datasets across various domains has posed a significant challenge. To address this issue, the Alpaca model from Stanford University introduced a self-instruction methodology[8, 9]. This approach involves initially curating a small seed pool of human-written instructions, which are then used as prompts to generate a larger instruction dataset via a LLM. This innovative solution has provided the academic community with a novel approach to overcome the limitations imposed by the scarcity of instruction datasets in specific domains.
ChatGPT的成功普及了指令调整(Instruction Tuning)[6]的使用,随后相关研究验证了这是一种对于问答任务最有效的微调方法[7]。然而,跨各个领域可用指令数据集的缺乏提出了一个重大挑战。为了解决这一问题,斯坦福大学的Alpaca模型引入了一种自我指令方法[8, 9]。这种方法首先涉及策划一个由人类编写的小型种子指令池,然后使用这些指令作为提示,通过大型语言模型生成更大的指令数据集。这个创新解决方案为学术界提供了一个新颖的方法,以克服特定领域指令数据集稀缺所施加的限制。
B. Downstream Tasks Application Framework
B. 下游任务应用框架
In the realm of downstream task applications, two notable frameworks have emerged: Langchain and llama-index. These frameworks aim to facilitate the integration of language models into various domain-specific tasks and workflows.
在下游任务应用领域,两个显著的框架已经出现:Langchain和llama-index。这些框架旨在促进语言模型在各种领域特定任务和工作流程中的集成。
Langchain is a comprehensive framework provides a modular and extensible approach to building applications with large language models. It offers a wide range of tools and utilities, including agents, memory components, and prompting techniques. Langchain allows developers to create custom pipelines and workflows, enabling seamless interaction between language models and external data sources, such as databases, APIs, and document repositories.
Langchain是一个全面的框架,提供了一种模块化和可扩展的方法来构建大型语言模型的应用程序。它提供了广泛的工具和实用程序,包括代理、记忆组件和提示技术。Langchain允许开发者创建自定义管道和工作流程,使得语言模型与外部数据源(如数据库、API和文档仓库)之间的交互无缝进行。
On the other hand, llama-index[10] is a specialized framework focused on building structured indices over unstructured data. It leverages language models to extract and organize information from text documents, enabling efficient retrieval and question-answering capabilities. llama-index supports various indexing strategies, including tree-based and vector-based approaches, allowing for flexible and optimized index structures tailored to specific use cases.
另一方面,llama-index[10]是一个专注于在非结构化数据上构建结构化索引的专业框架。它利用语言模型从文本文档中提取和组织信息,实现了有效的检索和问答能力。llama-index支持各种索引策略,包括基于树和基于向量的方法,允许灵活和优化的索引结构,以适应特定的用例。
While both frameworks share the common goal of integrating language models into downstream tasks, they differ in their primary focus and approach. Langchain offers a broader set of tools for building end-to-end applications, while llama-index specializes in indexing and information retrieval from unstructured data sources.
尽管这两个框架都致力于将语言模型集成到下游任务中,但它们在主要焦点和方法上有所不同。Langchain提供了更广泛的工具来构建端到端应用程序,而llama-index则专注于从非结构化数据源进行索引和信息检索。
In this research, we have adopted the Langchain framework due to its comprehensive and modular nature. Langchain’s flexibility and extensive toolset align well with our proposed pipeline, enabling seamless integration of the Retrieval-Augmented Generation (RAG) approach and the generation of domain-specific instruction datasets. By leveraging Langchain, we can effectively combine the capabilities of large language models with the retrieval and augmentation processes required for our methodology.
在这项研究中,我们采用了Langchain框架,因为它具有全面和模块化的特性。Langchain的灵活性和广泛的工具集与我们的提议管道非常契合,使得检索增强生成(RAG)方法与领域特定指令数据集的生成能够无缝集成。通过利用Langchain,我们可以有效地将大型语言模型的能力与我们的方法论所需的检索和增强过程结合起来。
C. Retrieval-Augmented Generation
C. 检索增强生成(RAG)
The Retrieval-Augmented Generation (RAG) technique represents a significant advancement in enhancing the capabilities of LLMs by incorporating external knowledge sources. Originally introduced to enable LLMs to perform web searches and incorporate relevant information from the internet, RAG has since evolved to leverage custom document collections tailored to specific domains and downstream tasks.The core principle of RAG involves two key components: a retriever and a generator. The retriever component is responsible for identifying and retrieving relevant information from a given corpus of documents or knowledge base. This can be achieved through various techniques, such as sparse retrieval using TF-IDF or dense retrieval leveraging neural encoders to embed documents and queries into a shared vector space. The retrieved information is then passed to the generator component, typically an LLM, which generates contextually relevant and coherent responses by integrating the retrieved knowledge. This augmentation process allows the LLM to produce output that is not only fluent and grammatically correct but also factually grounded in the provided document collection.
检索增强生成(RAG)技术代表了一种在大型语言模型(LLMs)中融入外部知识源以增强其能力的重大进步。RAG最初被引入是为了使LLMs能够执行网络搜索并从互联网中整合相关信息,此后它已经发展到利用针对特定领域和下游任务定制的自定义文档集合。RAG的核心原则涉及两个关键组件:检索器和生成器。检索器组件负责从给定的文档集合或知识库中识别和检索相关信息。这可以通过各种技术实现,例如使用TF-IDF的稀疏检索或利用神经编码器将文档和查询嵌入共享向量空间的密集检索。检索到的信息然后传递给生成器组件,通常是一个LLM,它通过整合检索到的知识来生成在上下文中相关且连贯的响应。这种增强过程允许LLM产生不仅流畅且语法正确,而且在提供的文档集合中具有事实依据的输出。
The application of RAG in downstream task frameworks has further extended its capabilities. By integrating RAG with frameworks like Langchain, researchers and developers can seamlessly incorporate custom document collections into the retrieval process. This enables the generation of highly specialized and context-aware responses, tailored to the unique requirements of various domains and applications.
RAG在下游任务框架中的应用进一步扩展了其能力。通过将RAG与Langchain等框架集成,研究人员和开发者可以无缝地将自定义文档集合纳入检索过程。这使得能够生成高度专业化和具有上下文感知能力的响应,满足各种领域和应用的独特需求。
In our research, we leverage the RAG approach in conjunction with custom document collections to generate domain-specific instruction datasets. By retrieving relevant information from curated sources and incorporating it into the generation process, we can create instruction samples that accurately capture the nuances and intricacies of the target domain, while ensuring factual accuracy and contextual relevance.
在我们的研究中,我们利用RAG方法并结合自定义文档集合来生成领域特定的指令数据集。通过从策划的来源检索相关信息并将其纳入生成过程,我们可以创建准确捕捉目标领域细微差别和复杂性的指令样本,同时确保事实的准确性和上下文的相关性。
D. Large Language Model on Mental Healthcare
D. 大型语言模型在心理健康保健领域的应用
Recent studies have explored the integration of LLMs with the field of mental healthcare to assist in maintaining patients’ psychological well-being. Singh et al. [11] implemented a simple chatbot on mental health topics using the Langchain framework. Additionally, the Mental-LLM proposed by Xu et al.[12] utilizes online text data for the prevention of mental disorders. Their research also evaluated the predictive performance of various LLM models in this context.
最近的研究探讨了将大型语言模型(LLMs)与心理健康保健领域相结合,以帮助维护患者的心理福祉。辛格等人[11]使用Langchain框架实现了一个关于心理健康主题的简单聊天机器人。此外,徐等人提出的Mental-LLM[12]利用在线文本数据预防精神障碍。他们的研究还评估了各种LLM模型在此背景下的预测性能。
Another noteworthy research is the Chat Doctor [13], a model based on LLaMA and trained on 100,000 dialogues between psychiatric patients and doctors. Although it does not use an instruction dataset but rather real-world dialogue, the Chat Doctor has shown promising accuracy in diagnosing mental health conditions. While not following the instruction-tuning approach, this model highlights the potential of LLMs in the mental healthcare domain when trained on substantial domain-specific data.
另一项值得注意的研究是Chat Doctor[13],这是一个基于LLaMA并训练了10万条精神病患者与医生之间对话的模型。尽管它没有使用指令数据集,而是使用了现实世界的对话,但Chat Doctor在诊断心理健康状况方面显示出令人鼓舞的准确性。尽管这个模型没有遵循指令调整方法,但它突显了当训练在大量领域特定数据上时,LLMs在心理健康保健领域的潜力。
III. METHODOLOGY
III. 方法论
Inspired by the work from Microsoft [14], we propose a pipeline that enables the generation of instruction datasets and self-fine-tuning for specialized domains. In contrast to traditional dataset construction methods, our approach leverages the power of RAG combined with LLMs, offering two advantages:
受微软工作[14]的启发,我们提出了一种管道,使得能够为专业领域生成指令数据集并进行自微调。与传统的数据集构建方法相比,我们的方法利用了RAG与LLMs相结合的力量,提供了两个优势:
• Dynamic: If updates or modifications are required for the domain-specific documents, the RAG framework can quickly assist the model in ingesting new information. This dynamic nature represents a significant improvement over traditional methods, as it eliminates the need for complete retraining and fine-tuning, thereby reducing computational costs.
• 动态性:如果需要对领域特定文档进行更新或修改,RAG框架可以快速帮助模型吸收新信息。这种动态性相对于传统方法是一个显著的改进,因为它消除了完全重新训练和微调的需要,从而减少了计算成本。
• Addressing Data Scarcity: In professionalized or specialized domains, obtaining comprehensive datasets can be challenging. Our pipeline alleviates this issue by enabling the generation of instruction datasets from a limited set of initial documents, making it suitable for domains with scarce data.
• 解决数据稀缺问题:在专业化或特殊化的领域,获取全面的数据集可能具有挑战性。我们的管道通过允许从有限的初始文档集生成指令数据集,缓解了这个问题,使得它适用于数据稀缺的领域。

Fig. 1. Methodology pipeline. First, the DSM-5 PDF is converted into DSM-5 JSON using GROBID. Then, the instruction dataset obtains information from the DSM-5 JSON through RAG and generates a QAdataset using prompts. The generated question-answer pairs are subsequently utilized for fine-tuning theMistral-7B.
图1. 方法论管道。首先,使用GROBID将DSM-5 PDF转换为DSM-5 JSON。然后,指令数据集通过RAG从DSM-5 JSON获取信息并通过提示生成一个QA数据集。随后,生成的问答对被用于微调Mistral-7B。
The flowchart in Figure 1 illustrates the process of our proposed methodology. The following sections will delineate it step-by-step:
图1中的流程图展示了我们提出的方法论的过程。以下部分将逐步阐述它:
A. Data Collecting and Preprocessing
A. 数据收集与预处理
In the field of psychiatry, the DSM-5 (Diagnostic and Statistical Manual of Mental Disorders, Fifth Edition) is a widely recognized standard guideline. For our research, we utilized the more concise version, “Desk Reference to the Diagnostic Criteria from DSM-5,” a 444-page PDF document.
在精神病学领域,DSM-5(《精神疾病诊断与统计手册》第五版)是一个广泛认可的标准指南。为了我们的研究,我们使用了更简洁的版本——“DSM-5诊断标准桌面参考”,这是一个444页的PDF文档。
However, instead of directly loading the PDF using a unstructured loader, we aimed to enhance the model’s question-answering accuracy by transforming the unstructured text into a structured JSON format. To achieve this, we employed GROBID[15], a machine learning model designed for text extraction and structuring from PDF documents. GROBID extracts the raw text in TEI format, and then we convert it from XML to JSON file. By preprocessing the PDF using GROBID, we obtained a structured representation of the diagnostic criteria, disorder descriptions, and other relevant information from the DSM-5 desk reference. This structured data format facilitated more efficient information retrieval and improved the model’s ability to provide accurate and contextually relevant responses within the psychiatric domain.
然而,我们不是直接使用非结构化加载器加载PDF,而是希望通过将非结构化文本转换为结构化的JSON格式来提高模型问答的准确性。为了实现这一点,我们使用了GROBID[15],这是一个用于从PDF文档中提取和结构化文本的机器学习模型。GROBID提取TEI格式的原始文本,然后我们将它从XML转换为JSON文件。通过使用GROBID预处理PDF,我们获得了DSM-5桌面参考中的诊断标准、疾病描述和其他相关信息的结构化表示。这种结构化数据格式使得信息检索更加高效,并提高了模型在精神病学领域提供准确且上下文相关响应的能力。
B. Language Model and RAG setup
B. 语言模型与RAG设置
We selected the Mistral 7B-instruct v0.2 language model for our research, as it outperforms other models of similar parameter size. We then leveraged the Langchain framework to ingest and process the structured JSON file obtained from the preprocessing step.
我们为我们的研究选择了Mistral 7B-instruct v0.2语言模型,因为它在相似参数大小的模型中表现更佳。然后我们利用Langchain框架来摄取和处理预处理步骤中获得的结构化JSON文件。
Within the Langchain framework, we employed the Conversational Retrieval Chain function, which is tailored for conversational and contextual retrieval tasks. For the vector database, we opted for FAISS (Facebook AI Similarity Search)[16], a highly efficient and scalable library for similarity search and dense vector indexing.
在Langchain框架内,我们使用了Conversational Retrieval Chain函数,这是为对话和上下文检索任务量身定制的。对于向量数据库,我们选择了FAISS(Facebook AI相似性搜索)[16],这是一个高效且可扩展的库,用于相似性搜索和密集向量索引。
Regarding the choice of embedding model, we extensively evaluated various options, Ultimately, we selected the Nomic AI’s embedding model which called “nomic-embed-text” [17],as it demonstrated superior performance compared to the other alternatives in our experiments.
关于嵌入模型的选择,我们广泛评估了各种选项,最终我们选择了Nomic AI的嵌入模型,名为“nomic-embed-text”[17],因为在我们实验中,它相比其他替代方案表现出了更优越的性能。
C. Generate QA Prompt Design
C. 生成QA提示设计
Prompt design is a crucial part of our methodology, as it directly impacts the language model’s ability to comprehend and generate relevant dataset entries accurately. To ensure high-quality datasets that encompass all essential information from the document corpus, we adopted a structured approach based on the table of contents.
提示设计是我们方法论的关键部分,因为它直接影响语言模型理解和准确生成相关数据集条目的能力。为了确保涵盖文档语料库中所有必要信息的高质量数据集,我们采用了一种基于目录的结构化方法。
We divided the prompts into sections according to the organization of the source material and generated 60~100 entries for each category of mental disorders, After deduplication and removal of low-quality entries, we targeted approximately 80 entries per category of mental disorders for dataset construction.This systematic approach aimed to capture the nuances and specific details associated with different psychiatric conditions.An example of our prompt design was shown in Figure 2.
我们根据源材料的组织将提示分为几个部分,并为每种精神障碍类别生成了60~100个条目。在去重和移除低质量条目后,我们目标是为每种精神障碍类别构建大约80个条目的数据集。这种系统化的方法旨在捕捉与不同精神疾病状况相关的细微差别和具体细节。我们的提示设计的一个例子如图2所示。

Fig. 2. QA generation prompt example. When prompting the model, we replace the {Disorder category} tag with the title of each chapter in the DSM-5.
图2. QA生成提示示例。在提示模型时,我们将{疾病类别}标签替换为DSM-5中每个章节的标题。
D. Training
D. 训练
After the aforementioned processes, we generated approximately 2,000 entries for our instruction fine-tuning dataset. The details of this dataset will be elaborated in Chapter 4. Subsequently, we utilized this dataset to fine-tune the Mistral-7B model.
在上述过程之后,我们为我们指令微调数据集生成了大约2,000个条目。这个数据集的详细信息将在第4章中详细阐述。随后,我们利用这个数据集来微调Mistral-7B模型。
For the fine-tuning process, we employed the LoRA (LowRank Adaptation) technique [18], which is a popular and efficient method for adapting large language models. The hardware used for training was a single RTX A6000 GPU with 48GB of VRAM. The total training time was 2 hours. The remaining hyperparameters and settings are summarized in Table I. Through this training process, we obtained the Mistral-7B-DSM-5 model, a language model tailored for the psychiatric domain, capable of performing simple diagnoses and psychological assessments.
对于微调过程,我们采用了LoRA(低秩适应)技术[18],这是一种流行且高效的大型语言模型适应方法。训练所使用的硬件是一块拥有48GB VRAM的RTX A6000 GPU。总训练时间为2小时。其余的超参数和设置总结在表I中。通过这个训练过程,我们获得了Mistral-7B-DSM-5模型,这是一个针对精神病学领域量身定制的语言模型,能够进行简单的诊断和心理评估。
TABLE I. HYPERPARAMETER CONFIGURATION
表I. 超参数配置

IV. EXPERIMENT RESULTS
IV. 实验结果
After completing the pipeline described in the previous chapter, we obtained a DSM-5 instruction dataset. This dataset comprises approximately 80 entries for each category of mental disorders, covering a range of relevant questions and answers. However, for the sections on “Medication-induced Movement” and “Other Adverse Effects of Medication”, due to their relatively limited content, we generated 40 entries for each. To further enhance the diversity of the dataset, we additionally generated over 300 entries based on the entire DSM-5 guideline. The final dataset consists of approximately 2,000 instruction entries in total. The distribution of entries across different categories of mental disorders is presented in Table II.
在完成了前一章描述的管道后,我们获得了DSM-5指令数据集。这个数据集包含了每种精神障碍类别大约80个条目,涵盖了相关的问题和答案。然而,对于“药物引起的运动障碍”和“药物的其他不良反应”部分,由于它们的内容相对有限,我们为每个部分生成了40个条目。为了进一步增加数据集的多样性,我们还根据整个DSM-5指南额外生成了超过300个条目。最终的数据集总共包含了大约2,000个指令条目。不同精神障碍类别条目的分布情况呈现在表II中。
This comprehensive instruction dataset serves as the foundation for fine-tuning our language model, aiming to enhance its performance in addressing psychiatric domain-specific tasks and queries accurately. The diversity of the dataset, encompassing various mental disorders and their associated diagnostic criteria, treatment recommendations, and other relevant information, is crucial for developing a versatile model capable of handling a wide range of scenarios within the psychiatric field.
这个全面的指令数据集作为我们微调语言模型的基础,旨在提高其在准确处理精神病学领域特定任务和查询方面的性能。数据集的多样性,包括各种精神障碍及其相关的诊断标准、治疗建议和其他相关信息,对于开发一个能够处理精神病学领域内广泛场景的多功能模型至关重要。
TABLE II. DSM-5 INSTRUCTION DATASET CATEGORY PERCENTAGE
表II. DSM-5指令数据集类别百分比

On the other hand, our model achieved an average final Loss of around 0.07 after training, as shown in Figure 3. While it is possible that increasing the number of epochs or adjusting the learning rate could further reduce the Loss, the current model performance is already outstanding.
另一方面,我们的模型在训练后实现了大约0.07的平均最终损失,如图3所示。尽管增加迭代次数或调整学习率可能会进一步降低损失,但当前模型的性能已经非常出色。

Fig. 3. Training loss. The stable decrease in training loss indicates that our model has effectively learned from the dataset.
图3. 训练损失。训练损失的稳定下降表明我们的模型已经有效地从数据集中学习。
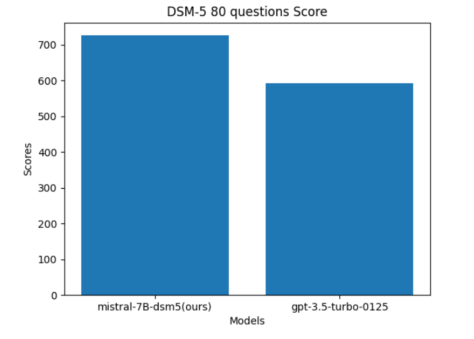
Fig. 4. Model evaluation scores judged by GPT-4.
图4. GPT-4评估的模型评分。
At last, we employed GPT-4 as an expert judge to evaluate the capabilities of our fine-tuned model. We randomly generated 80 questions based on the “Desk Reference to the Diagnostic Criteria From DSM-5” guideline book, and tasked both our mistral-7B-dsm5 model and the GPT-3.5-turbo-0125 model to generate answers. These responses were then submitted to GPT-4 for scoring on a scale of 1 to 10 for each question. The results was shown in Figure 4, our mistral-7Bdsm5 model achieved a superior score of 726, while the GPT-3.5-turbo-0125 model scored 592.
最后,我们使用GPT-4作为专家评委来评估我们微调模型的能力。我们随机基于“DSM-5诊断标准桌面参考”指南书生成了80个问题,并让我们的mistral-7B-dsm5模型和GPT-3.5-turbo-0125模型生成答案。这些响应随后提交给GPT-4,为每个问题打分,评分范围为1到10。结果如图4所示,我们的mistral-7B-dsm5模型获得了726分的高分,而GPT-3.5-turbo-0125模型获得了592分。
V. CONCLUSION
V. 结论
In this research, we have presented a novel pipeline that leverages the power of LLMs and the Retrieval-Augmented Generation related framework to generate domain-specific instruction datasets for fine-tuning. By conducting a case study in the field of psychiatry, we have demonstrated the feasibility and effectiveness of our approach. Remarkably, using only the electronic version of the DSM-5 guideline as the source document, our pipeline generated an instruction fine-tuning dataset comprising approximately 2,000 entries and 200,000 words. This achievement underscores the potential of our methodology to create high-quality, domain-specific datasets efficiently, even when working with limited source materials.
在这项研究中,我们提出了一种新型的管道,利用LLMs和检索增强生成(RAG)相关框架生成领域特定的指令数据集以进行微调。通过在精神病学领域进行案例研究,我们证明了我们的方法的可行性和有效性。值得注意的是,仅使用DSM-5指南的电子版本作为源文档,我们的管道生成了一个包含大约2,000条目和200,000个单词的指令微调数据集。这一成就凸显了我们方法论的潜力,即使在工作材料有限的情况下,也能高效地创建高质量、领域特定的数据集。
The success of our pipeline in the psychiatric domain serves as a compelling proof-of-concept, highlighting its applicability across various domains. This research provides enterprises and organizations with a viable solution for developing customized, domain-specific language models without incurring excessive costs. Notably, our experiments were conducted on consumer-grade hardware, further emphasizing the accessibility and scalability of our approach.
我们在精神病学领域的管道成功为各种领域提供了有说服力的概念证明,突显了其适用性。这项研究为企业和组织提供了一个可行的解决方案,以开发定制的、领域特定的语言模型,而无需承担过高的成本。值得注意的是,我们的实验是在消费级硬件上进行的,进一步强调了我们的方法的可达性和可扩展性。
While our results are promising, we acknowledge that there is room for further improvement and refinement. In the future, we plan to extend our pipeline to different domains, continuously enhancing its usability and streamlining the process. By doing so, we aim to empower a broader range of stakeholders to leverage the power of LLMs for their specific needs, fostering innovation and unlocking new possibilities in natural language processing applications.
虽然我们的结果很有希望,但我们承认还有改进和精炼的空间。未来,我们计划将我们的管道扩展到不同的领域,不断改进其可用性和简化流程。通过这样做,我们旨在使更广泛的利益相关者能够利用LLMs的力量满足他们的特定需求,推动创新并解锁自然语言处理应用中的新可能性。
Moreover, our research underscores the importance of responsible and ethical practices in the development and deployment of AI systems, particularly in sensitive domains like mental healthcare. As language models become increasingly sophisticated, it is crucial to ensure their outputs are accurate, unbiased, and aligned with professional guidelines and ethical principles.
此外,我们的研究凸显了在敏感领域如心理健康保健的开发和部署AI系统时,负责任和道德实践的重要性。随着语言模型变得越来越复杂,确保它们的输出准确、无偏见,并符合专业指南和伦理原则至关重要。
In conclusion, this study represents a significant step towards democratizing the creation of customized language models tailored to specific domains. By combining the strengths of LLMs, the RAG framework, and domain-specific knowledge sources, our pipeline offers a promising solution for organizations seeking to harness the potential of AI while addressing the challenges of data scarcity and domain specificity.
总之,这项研究代表了一个重要的步骤,朝着使特定领域的定制语言模型的创建民主化迈出了一步。通过结合LLMs、RAG框架和领域特定知识源的优势,我们的管道为寻求利用AI潜力的同时解决数据稀缺性和领域特定性的挑战的组织提供了一个有希望的解决方案。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









