






Yanbin Wei , Qiushi Huang, Yu Zhang , James T. Kwok,2024
《KICGPT: 知识图谱补全中的上下文知识大型语言模型》
摘要
- 问题: 知识图谱补全 (KGC) 解决知识图谱 (KG) 不完整性的问题,这对于各种应用来说至关重要。
- 解决方案: KICGPT 将大型语言模型 (LLM) 与基于三元组的 KGC 检索器结合起来,以处理长尾实体而无需额外的训练。
- 方法: 使用知识提示 (Knowledge Prompt) 将结构化知识编码到示例中,以指导 LLM。
创新点: 利用 LLM 和知识提示进行 KGC,无需额外训练。
优势:能有效处理长尾实体,减少了计算资源和数据需求。
实验:在标准数据集上表现优异,验证了方法的有效性。
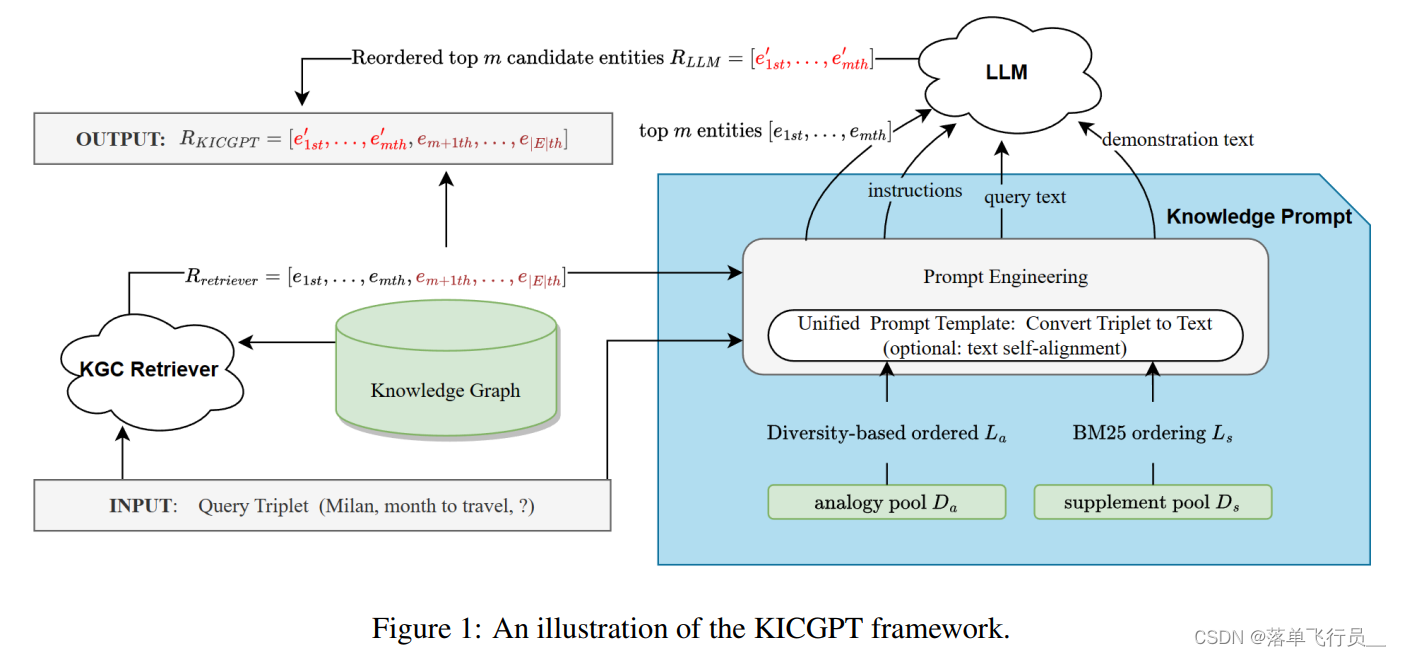
-
输入 (Input):
- 查询三元组 (Query Triplet): 例如
(Milan, month to travel, ?),表示寻找关于米兰的旅行月份的信息。
- 查询三元组 (Query Triplet): 例如
-
KGC 检索器 (KGC Retriever):
- 作用: 从知识图谱中检索与查询相关的候选实体,并对每个实体打分。
- 输出: 得到一个按分数降序排列的实体列表 Rretriever。
-
知识图谱 (Knowledge Graph):
- 作用: 提供基础知识库,包含各种实体及其关系。
-
知识提示 (Knowledge Prompt):
- 作用: 使用一个统一的提示模板将三元组转换为文本,并包含可选的文本自对齐。
- 过程:
- 示例池: 构建类比池 Da 和补充池 Ds。
- 示例排序: 对类比池使用基于多样性的排序策略,得到有序列表 La;对补充池使用BM25排序,得到有序列表Ls。
- 提示工程 (Prompt Engineering):
- 将示例和查询文本化。
- 多轮交互生成示例文本并发送给LLM进行处理。
- LLM根据这些示例重新排序前m个实体。
-
大型语言模型 (LLM):
- 作用: 基于给定的知识提示和自身的知识,对候选实体进行重新排序。
- 输出: 重新排序后的前m个实体列表 Rllm。
-
输出 (Output):
- 最终结果: 将LLM重新排序后的前m个实体替换KGC检索器列表中的前m个实体,形成最终的实体列表 Rkicgpt。















 4740
4740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









