







摘要:大多数现有的无监督人员重新识别(ReID)方法使用聚类来生成用于模型训练的伪标签。遗憾的是,聚类有时会将不同的真实身份混合在一起,或者将同一身份拆分为两个或多个子聚类。在这些嘈杂的集群上进行训练会严重阻碍 Re-ID 的准确性。由于每个恒等式中的样本有限,我们假设可能缺少一些基础信息来很好地揭示准确的聚类。为了发现这些信息,我们提出了一种隐式样本扩展(ISE)方法来生成我们称之为集群边界的支持样本。具体来说,我们通过渐进线性插值(PLI)策略从嵌入空间中的实际样本及其相邻簇生成支持样本。PLI通过两个关键因素控制生成,即1)从实际样本到其K最近集群的方向和2)混合来自K最近集群的背景信息的程度。同时,给定支持样本,ISE进一步使用标签保留损失将它们拉向相应的实际样本,从而压缩每个簇。因此,ISE减少了“子和混合”聚类错误,从而提高了重新识别性能。大量实验表明,所提方法在无监督人员重新识别方面是有效的,并且实现了最先进的性能。
总体模型:
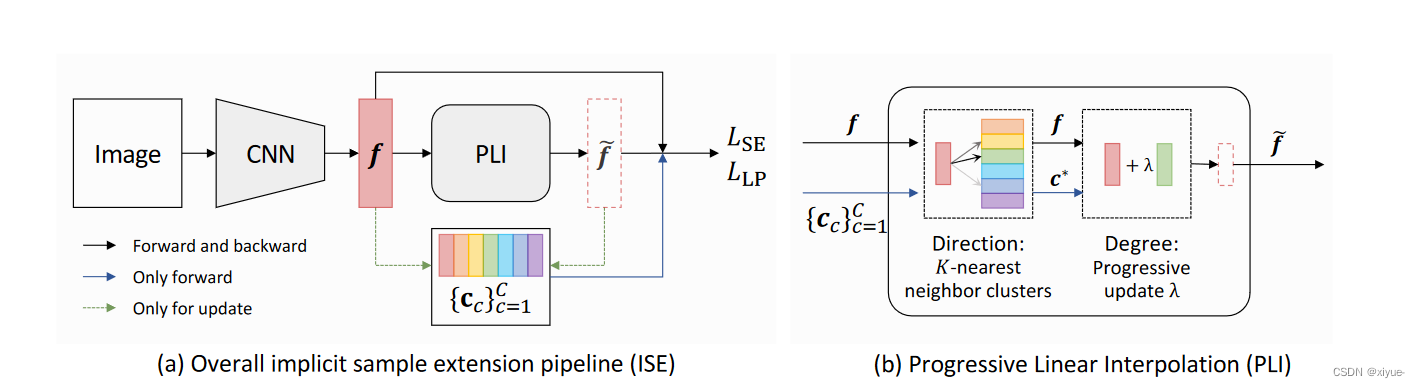
概述(a)整体隐式样本扩展管道(ISE)和(b)渐进式线性插值(PLI)策略的详细信息。对于特定的样本特征f,我们应用PLI生成支持样本![]() ,用于优化样本扩展损失LSE和标签保留损失LLP的模型。在生成过程中,PLI以K-最近团簇质心c∗为生成方向,并采用渐进更新的λ来控制生成度。
,用于优化样本扩展损失LSE和标签保留损失LLP的模型。在生成过程中,PLI以K-最近团簇质心c∗为生成方向,并采用渐进更新的λ来控制生成度。
PLI模型:
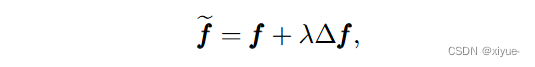
给定一个样本特征f,通过线性插值运算生成其对应的支持样本![]() ,其中∆f控制方向,λ控制度数,这是样品扩展过程中的两个重要因素
,其中∆f控制方向,λ控制度数,这是样品扩展过程中的两个重要因素
ISE模型:

优点:
- 我们提出了一种新的USL人员Re-ID隐式样本扩展(ISE)方法。从ISE生成的支持样本提供了补充信息,可以很好地处理子集群和混合聚类错误的问题
- 我们提出了一种新颖的渐进线性插值(PLI)策略和用于支持样品生成的标签保留对比度损失(LP)
- 我们进行了全面的实验和分析,以证明ISE的有效性,ISE的表现大大优于当前最先进的技术
不足:
我们的ISE从实际样本生成支持样本到嵌入空间中的相邻簇质心。对于每个样本,所选最近的聚类质心的数量固定为 K。这可能不是最佳解决方案。如果某些聚类已很好地分类,则无需添加补充样本。相反,当特定聚类由多个标识混合时,最好在多个 K 最近方向上生成支持样本。
参考文献:Implicit Sample Extension for Unsupervised Person Re-Identification















 2266
2266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









