









 该文详细介绍了如何使用PyTorch和numpy对MNIST数据集进行预处理,包括数据加载、转换、拆分训练集和测试集。文中还涉及逻辑回归模型的构建,包括Sigmoid激活函数、交叉熵损失函数的计算以及梯度下降法的实现。此外,还涵盖了数据的独热编码和模型的预测功能。
该文详细介绍了如何使用PyTorch和numpy对MNIST数据集进行预处理,包括数据加载、转换、拆分训练集和测试集。文中还涉及逻辑回归模型的构建,包括Sigmoid激活函数、交叉熵损失函数的计算以及梯度下降法的实现。此外,还涵盖了数据的独热编码和模型的预测功能。
文章目录
完整代码
import os.path
import numpy as np
from torchvision.datasets import ImageFolder
from torch.utils.data import DataLoader
from torchvision import transforms
from sklearn.model_selection import train_test_split
def LoadMyData(dataroot):
transform = transforms.Compose([transforms.Resize(16),transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
dataset = ImageFolder(dataroot,transform)
datafolder = DataLoader(dataset)
classes = []
labels = []
for myclass,mylabel in datafolder:
classes.append(myclass.view(-1).numpy())
labels.append(mylabel.item())
return classes,labels
def SplitData(data,labels):
x_train,x_test,y_train,y_test = train_test_split(data,labels,test_size=0.3,random_state=0)
x_train = np.insert(x_train,0,1,axis=1)
x_test = np.insert(x_test,0,1,axis=1)
return x_train,x_test,y_train,y_test
def PrepareData(dataroot):
classes,labels = LoadMyData(dataroot)
x_train,x_test,y_train,y_test = SplitData(classes,labels)
return x_train,x_test,y_train,y_test
def sigmoid(z):
return 1/(1+np.exp(-z))
def predict(z):
return np.argmax(sigmoid(z),axis=1)
def cost_function(theta,x,y):
m = len(y)
y_pred = sigmoid(np.dot(x,theta))
J = (-1/m)*(y*np.log(y_pred)+(1-y)*(np.log(1-y_pred)))
grad = (1/m)*np.dot(x.T,(y_pred-y))
return J,grad
def count_subdirectories(dataroot):
if not os.path.isdir(dataroot):
print("Invalid Folder Path")
return
names = os.listdir(dataroot)
return len(names)
def main(mydataroot,my_lr,my_iterations,my_gap):
dataroot = mydataroot
num_classes = count_subdirectories(dataroot)
x_train,x_test,y_train,y_test = PrepareData(dataroot)
theta = np.zeros((x_train.shape[1],num_classes))
y_one_hot = np.eye(num_classes)[y_train]
lr = my_lr
for iterations in range(0,my_iterations,my_gap):
for iteration in range(iterations):
J,grad = cost_function(theta,x_train,y_one_hot)
theta = theta - lr*grad
y_pred = predict(np.dot(x_test,theta))
acc = np.mean(y_pred == y_test)*100
print(f"accuracy after {iterations} iterations is {acc}%")
if __name__ == "__main__":
print("begin")
dataroot = "./data"
learning_rate = 0.01
iterations = 300
gap = 5
main(dataroot,learning_rate,iterations,gap)
print("end")
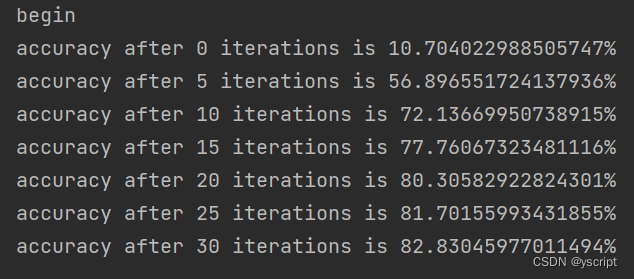
对mnist的测试输出结果
主函数各参数解释
存放数据的文件夹:dataroot = "./data"
学习率:learning_rate = 0.01
迭代次数:iterations = 300
每多少次迭代后,打印输出值,这里设置为5:gap = 5

这5个子文件夹放在名为data的主文件夹中。(文件夹名可以任意,不一定非要是0,1,2,3,4;因为ImageFolder和Dataloader会自动处理标签)
预备知识
数学推导
逻辑回归是一种广泛应用于分类问题的机器学习算法,它可以用于二元分类和多元分类。在多元分类问题中,逻辑回归通过扩展二元逻辑回归模型来进行预测。
具体的数学证明请查阅别的资料,这里只给出最终结果。
代价函数:
J
(
θ
)
=
1
m
∑
i
=
1
m
Cost
(
h
θ
(
x
(
i
)
)
,
y
(
i
)
)
=
−
1
m
[
∑
i
=
1
m
y
(
i
)
log
(
h
θ
(
x
(
i
)
)
)
+
(
1
−
y
(
i
)
)
log
(
1
−
h
θ
(
x
(
i
)
)
)
]
\begin{aligned} J(\theta) & =\frac{1}{m} \sum_{i=1}^{m} \operatorname{Cost}\left(h_{\theta}\left(x^{(i)}\right), y^{(i)}\right) \\ & =-\frac{1}{m}\left[\sum_{i=1}^{m} y^{(i)} \log \left(h_{\theta}\left(x^{(i)}\right)\right)+\left(1-y^{(i)}\right) \log \left(1-h_{\theta}\left(x^{(i)}\right)\right)\right] \end{aligned}
J(θ)=m1i=1∑mCost(hθ(x(i)),y(i))=−m1[i=1∑my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
梯度:
∂
∂
θ
j
J
(
θ
)
=
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\frac{\partial}{\partial \theta_{j}} J(\theta)=\frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)}
∂θj∂J(θ)=m1i=1∑m(hθ(x(i))−y(i))xj(i)
theta的更新策略:
θ
j
:
=
θ
j
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\theta_{j}:=\theta_{j}-\alpha \frac{1}{m} \sum_{i=1}^{m}\left(h_{\theta}\left(x^{(i)}\right)-y^{(i)}\right) x_{j}^{(i)}
θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i)
其中, α \alpha α为学习率, h θ ( x ) h_{\theta}(x) hθ(x)为x和对应维度的theta做乘法后在放入sigmoid求出的y_pred
sigmoid函数
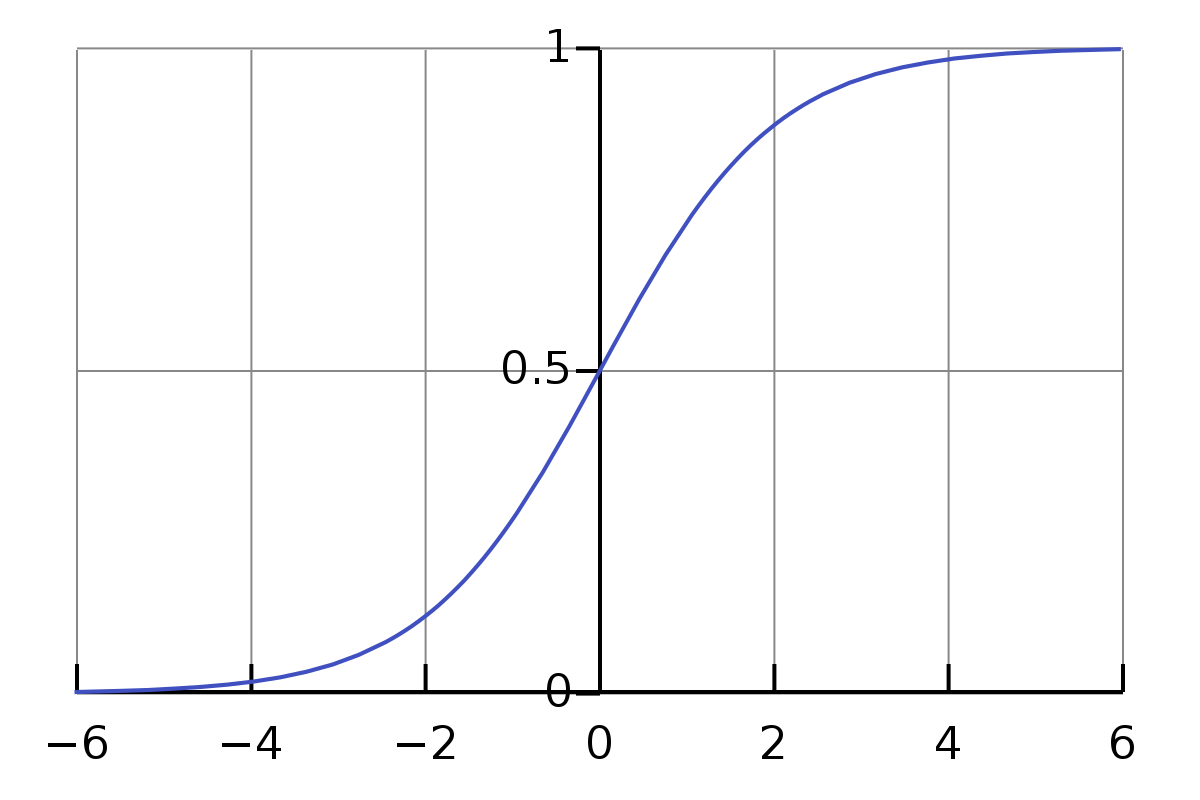
f
(
x
)
=
1
1
+
e
−
x
f(x) = \frac{1}{1+e^{-x}}
f(x)=1+e−x1
理解为非线性映射即可。把一个输入映射为0-1上的值。
np的矩阵维度读取
对于二维数组,可以使用shape[0]获取行数,shape[1]获取列数。
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
shape = np.shape(arr)
rows = shape[0]
cols = shape[1]
print("行数:", rows)
print("列数:", cols)
# 输出:
# 行数: 2
# 列数: 3
在代码中,我们需要用到这个函数获取输入向量的某些信息。
np.argmax函数
np.argmax是NumPy库中的一个函数,用于返回数组中最大元素的索引或指定轴上最大元素的索引。
函数的语法如下:
numpy.argmax(arr, axis=None)
参数说明:
arr:输入的数组。
axis:指定要沿着哪个轴寻找最大值的索引。默认值为None,表示在整个数组中寻找最大值的索引。
函数返回一个表示最大值索引的整数或整数数组。如果axis=None,则返回整个数组中最大值的索引。如果axis被指定,则返回沿着指定轴的最大值的索引数组。
1.在一维数组中寻找最大值的索引:
import numpy as np
arr = np.array([3, 1, 5, 2, 4])
max_index = np.argmax(arr)
print(max_index)
# 输出:2
2.在二维数组中寻找整个数组最大值的索引:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
max_index = np.argmax(arr)
print(max_index)
# 输出:5
3.在二维数组中沿着指定轴(行轴)寻找最大值的索引数组:
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
max_indices = np.argmax(arr, axis=1)
print(max_indices)
# 输出:[2 2]
在示例3中,axis=1表示沿着行轴寻找最大值的索引。结果是一个包含每行最大值索引的一维数组。
需要注意的是,np.argmax只返回最大值的索引。如果需要获取最大值本身,可以使用np.max函数。
np.insert函数
用法:
numpy.insert(arr, obj, values, axis=None)
arr:需要插入值或数组的目标数组。
obj:插入位置的索引或索引数组。可以是一个整数,表示要插入值的位置,也可以是一个整数数组,表示要插入值的多个位置。如果是一个整数数组,它的长度必须与要插入的值或数组的长度相同。
values:要插入的值或数组。可以是一个标量值或一个数组。如果是一个数组,它的形状必须与要插入的位置匹配。
axis:指定在哪个轴上进行插入操作。默认值为None,表示将输入数组展平后进行插入。
示例:
1.在一维数组中插入一个值:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
new_arr = np.insert(arr, 2, 10)
print(new_arr)
# 输出:[ 1 2 10 3 4 5]
2.在一维数组中插入一个数组:
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
values = np.array([10, 11, 12])
new_arr = np.insert(arr, 2, values)
print(new_arr)
# 输出:[ 1 2 10 11 12 3 4 5]
3.在二维数组的指定轴上插入一个值或数组:
import numpy as np
arr = np.array([[1, 2], [3, 4]])
new_arr = np.insert(arr, 1, 10, axis=1)
print(new_arr)
# 输出:
# [[ 1 10 2]
# [ 3 10 4]]
values = np.array([[11, 12], [13, 14]])
new_arr = np.insert(arr, 1, values, axis=0)
print(new_arr)
# 输出:
# [[ 1 2]
# [11 12]
# [13 14]
# [ 3 4]]
独热编码(One-Hot Encoding)
独热编码(One-Hot Encoding)是一种常用的分类数据编码方法,用于将离散特征表示为二进制向量的形式。它主要用于解决分类算法中特征值之间的无序关系。
独热编码的原理是为每个离散特征创建一个新的二进制特征列,其中每个特征值都表示为一个唯一的二进制编码。对于一个有N个不同特征值的离散特征,独热编码将生成一个N维的二进制向量,其中只有一个元素为1,其余元素均为0。
例如,假设有一个表示颜色的特征,包含三个不同的取值:红、绿和蓝。使用独热编码,可以将每个颜色值编码为一个二进制向量,如下所示:
红色:[1, 0, 0]
绿色:[0, 1, 0]
蓝色:[0, 0, 1]
这样做的好处是,将离散特征转换为二进制向量后,可以在机器学习算法中更好地处理这些特征,避免了特征值之间的无序关系对算法产生的影响。
这里使用np.eye等生成独热编码。
举例:
import numpy as np
arr = np.array([4, 1, 2, 5, 3])
num_classes = np.max(arr) + 1
one_hot = np.eye(num_classes)[arr]
print("原始数组:", arr)
print("独热编码:")
print(one_hot)
输出:
原始数组: [4 1 2 5 3]
独热编码:
原始数组: [4 1 2 5 3]
独热编码:
[[0. 0. 0. 0. 1. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 0. 0. 0. 1.]
[0. 0. 0. 1. 0. 0.]]
数据预处理
参考之前的文章:
图片数据导入和预处理
各模块代码详解
def LoadMyData(dataroot):
transform = transforms.Compose([transforms.Resize(16),transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
dataset = ImageFolder(dataroot,transform)
datafolder = DataLoader(dataset)
classes = []
labels = []
for myclass,mylabel in datafolder:
classes.append(myclass.view(-1).numpy())
labels.append(mylabel.item())
return classes,labels
数据预处理,图片大小转换为16*16的numpy,返回包含所有图片和对应标签的列表
def SplitData(data,labels):
x_train,x_test,y_train,y_test = train_test_split(data,labels,test_size=0.3,random_state=0)
x_train = np.insert(x_train,0,1,axis=1)
x_test = np.insert(x_test,0,1,axis=1)
return x_train,x_test,y_train,y_test
def PrepareData(dataroot):
classes,labels = LoadMyData(dataroot)
x_train,x_test,y_train,y_test = SplitData(classes,labels)
return x_train,x_test,y_train,y_test
分割数据,并最后返回训练集和测试集(测试集比例为0.3)
def sigmoid(z):
return 1/(1+np.exp(-z))
定义sigmoid函数
def predict(z):
return np.argmax(sigmoid(z),axis=1)
预测函数,返回的是预测标签
def cost_function(theta,x,y):
m = len(y)
y_pred = sigmoid(np.dot(x,theta))
J = (-1/m)*(y*np.log(y_pred)+(1-y)*(np.log(1-y_pred)))
grad = (1/m)*np.dot(x.T,(y_pred-y))
return J,grad
核心函数,求解损失函数和梯度,具体的数学推导见之前的预备知识。
注意交叉熵函数pred和y的位置,grad里数组维度的对应。
def count_subdirectories(dataroot):
if not os.path.isdir(dataroot):
print("Invalid Folder Path")
return
names = os.listdir(dataroot)
return len(names)
求解主文件下子文件夹的数量,即一共有多少个类别。
def main(mydataroot,my_lr,my_iterations,my_gap):
dataroot = mydataroot
num_classes = count_subdirectories(dataroot)
x_train,x_test,y_train,y_test = PrepareData(dataroot)
theta = np.zeros((x_train.shape[1],num_classes))
y_one_hot = np.eye(num_classes)[y_train]
lr = my_lr
for iterations in range(0,my_iterations,my_gap):
for iteration in range(iterations):
J,grad = cost_function(theta,x_train,y_one_hot)
theta = theta - lr*grad
y_pred = predict(np.dot(x_test,theta))
acc = np.mean(y_pred == y_test)*100
print(f"accuracy after {iterations} iterations is {acc}%")
main函数,注意初始化theta的维度。
双层循环的含义是一共迭代my_iterations,没my_gap次打印一次当前的预测准确率。
if __name__ == "__main__":
print("begin")
dataroot = "./data"
learning_rate = 0.01
iterations = 300
gap = 5
main(dataroot,learning_rate,iterations,gap)
print("end")
设置各参数。

















 1527
1527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









