






Opencv4和深度神经网络
Opencv4中提供了专门的模块 用于实现各种深度学习算法
加载深度学习模型
Opencv不能训练模型 但是 可以加载使用模型
retval = cv.dnn.readNet(model,[config,framework])
model 模型名称
config 配置文件名称
framework 框架种类
retval 一个Net类型的变量
不同的框架有不同的模型扩展名
Caffe 模型 .caffemodel 配置文件.prototxt
Tensorflow 模型 .pb 配置文件.pbtxt
Torch 模型 .t7 | .net 配置文件 --
Darknet 模型 .weights 配置文件.cfg
DLDT 模型 .bin 配置文件 .xml
Net类
empty() 判断是否为空
getLayerNames() 得到每层名称
getLayerId(name) 得到某层ID
getLayer(ID) 得到具体的ID或名称的指针
forward() 执行向前传输 输入为要输出的网络层
setInput() 设置网络中新的输入数据
None = cv.dnn_Net.setInput(blob)
blob: 新的输入数据import cv2 as cv
if __name__ == '__main__':
net = cv.dnn.readNet('dnn_model/bvlc_googlenet.caffemodel',
'dnn_model/bvlc_googlenet.prototxt')
is_empty = net.empty()
name_list = net.getLayerNames()
for name in name_list:
# 拿到ID
i = net.getLayerId(name)
# 拿到指针
layer = net.getLayer(i)
print('当前网络层数:{},网络类型:{},网络名称{}'.format(i,layer.type,layer.name))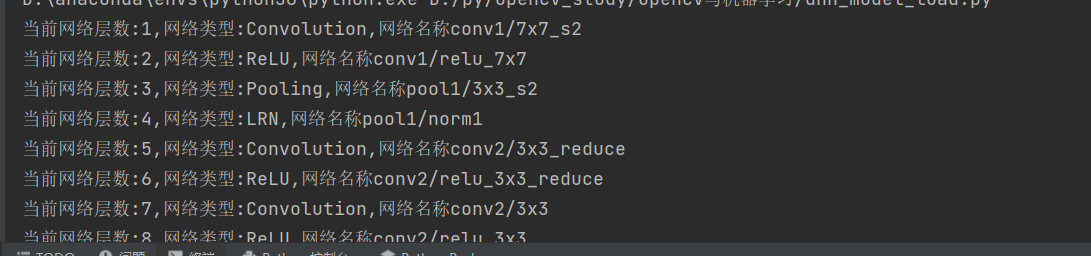
图像识别
主要讲如何使用模型进行图像识别 本例使用谷歌训练的由Tensorflow搭建的模型
会输出一个系列来表示结果和概率 结果是在分类表中寻找到的索引
在使用任何一个深度学习模型时 都需要了解该模型中输入的数据大小 一般来说
所有数据都需要相同的大小 本例尺寸为244*244
Opencv提供了转为 深度学习 尺寸转化的的 函数
retval = cv.dnn.blobFromImages(imgs,[scalefactor,size,mean,swapRGB,crop,ddepth])
scalefactor : 缩放系数 float32 默认为1.0
size : 输出图像尺寸 必须答大于40
mean : 去均值化 默认为空 去均值化为了减少光照影响
swapRGB : 是否交换RB
crop: 调整尺寸时 是否剪切 为True时 通过围绕中心剪切来实现尺寸 为False通过变换行列 会变形
ddepth: 输出的数据类型 默认为cv.CV_32F
retval: 返回一个4通道的blob(blob可以简单理解为一个N维的数组,用于神经网络的输入)import cv2 as cv
import numpy as np
if __name__ == '__main__':
cap = cv.VideoCapture(0)
model = 'dnn_model/tensorflow_inception_graph.pb'
label = 'dnn_model/imagenet_comp_graph_label_strings.txt'
net = cv.dnn.readNet(model)
with open(label,'r',encoding='utf-8') as f:
label = f.readlines()
while cap.isOpened():
_,img = cap.read()
# print(img.shape)
blob = cv.dnn.blobFromImage(img,size=(224,224),swapRB=True,crop=False)
net.setInput(blob)
# 返还一个1 * label数的矩阵 里面存储了对应位置的标签概率 one-hot编码
prob = net.forward()
# print(blob.shape)
# cv.imshow('img',img)
#round()方法返回浮点数x的四舍五入值
score = round(max(prob[0]) * 100)
# np.argmax() 返还该维度的最大值的索引
class_name = label[np.argmax(prob[0])].split('\n')[0]
string = 'label:{} score:{}'.format(class_name,score)
cv.putText(img,string,(50,50),cv.FONT_HERSHEY_SIMPLEX,1.0,(0,0,255),2,8)
cv.imshow('pre',img)
# print(prob.shape)
# print(len(label))
if cv.waitKey(1000//60) == ord('q'):
break
cap.release()
cv.destroyAllWindows()来自人工智能的肯定。。。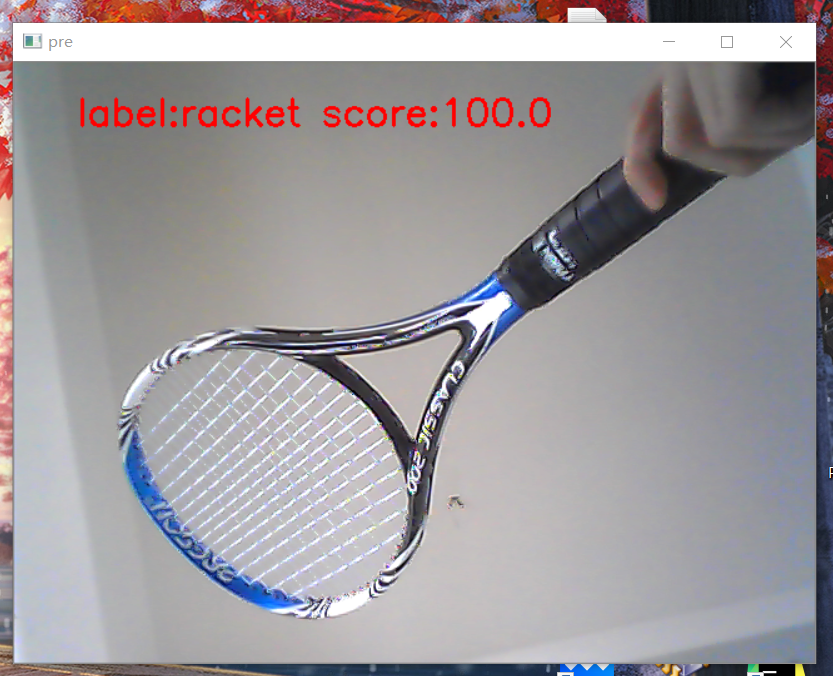
性别检测
一般情况下 每个模型都主要完成一件事情 例如识别动作 行人检测等
如果需要识别行人的动作 则要将两个模型联合在一起
下面内容将介绍如何通过多个模型来检测人物的性别
我们将使用人脸检测模型 和 性别检测模型
我们先使用人脸检测模型提取出人脸 之后输入性别检测模型来得到结果
import cv2 as cv
import numpy as np
if __name__ == '__main__':
gender_model = 'dnn_model/gender_net.caffemodel'
gender_config = 'dnn_model/gender_deploy.prototxt'
genderNet = cv.dnn.readNet(gender_model, gender_config)
face_model = 'dnn_model/opencv_face_detector_uint8.pb'
face_config = 'dnn_model/opencv_face_detector.pbtxt'
faceNet = cv.dnn.readNet(face_model, face_config)
cap = cv.VideoCapture(0)
while cap.isOpened():
_, img = cap.read()
blob = cv.dnn.blobFromImage(img, size=(300, 300), mean=None, swapRB=False, crop=False)
faceNet.setInput(blob)
# 返还一个长度为1的列表 内部有一个高维度矩阵
detects = faceNet.forward(blob)[0]
bbox = []
h, w = img.shape[:2]
# 拿到i i是二维的 第三列是概率 4,5,6,7 是 范围的左上角和右下角的 按比例给出
for i in detects[0][0]:
if i[2] > 0.5:
x1 = int(w*i[3])
y1 = int(h*i[4])
x2 = int(w*i[5])
y2 = int(h*i[6])
bbox.append([x1,y1,x2,y2])
cv.rectangle(img,(x1,y1),(x2,y2),(255,0,0),2,8,0)
genderlist = ['boy','girl']
for face in bbox:
face_img = img[face[1]:face[3],face[0]:face[2]]
blob = cv.dnn.blobFromImage(face_img,1.0,(227,227),swapRB=False,crop=False)
genderNet.setInput(blob)
res = genderNet.forward()
print(res)
gender = genderlist[res[0].argmax()]
string = 'gender:{} score:{:.2f}'.format(gender,max(res[0]))
cv.putText(img,string,(face[0],face[1]),cv.FONT_HERSHEY_SIMPLEX,0.8,(0,0,255),2,8)
cv.imshow('img',img)
if cv.waitKey(1000 // 60) == ord('q'):
break
cap.release()
cv.destroyAllWindows()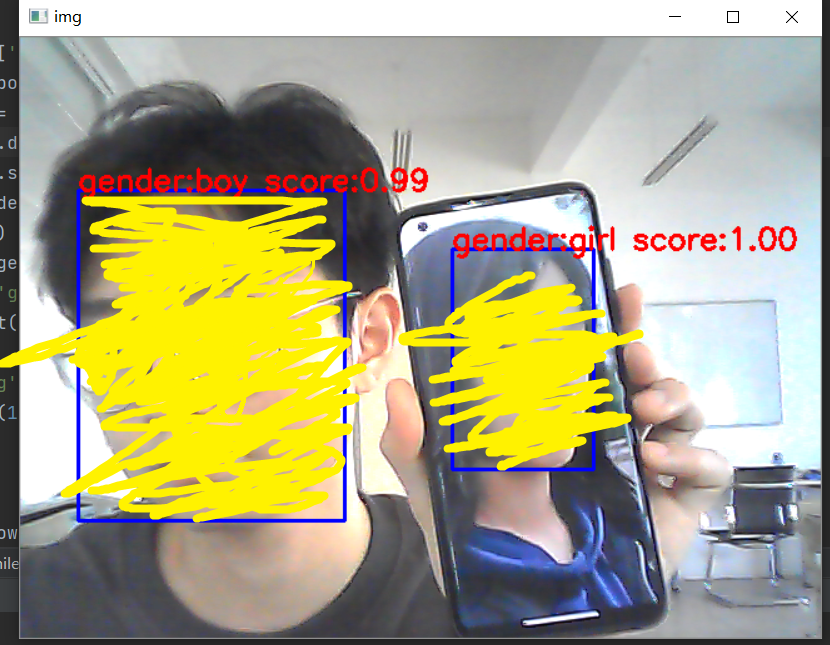















 21万+
21万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









