







作业目的:
实现分类预测的L层深度神经网络的所有函数。
搭建步骤:
一、初始化神经网络的所有参数,包括从1到L-1层的W和b(第0层为输入特征)
(一)要点:
- 初始化权重矩阵W[l],使用np.random.randn(shape) * 0.01,其中,shape为(第l层的神经元个数,第l-1层的神经元个数),np.random.randn()生成一组服从“0~1”均匀分布的随机样本值。随机样本取值范围是[0,1),不包括1。乘以0.01是为了确保W的值很小,从而使Z[l]=W[l]X+b[l]得到的Z[l]比较小,那么sigmoid(Z)的斜率较大,可以加快学习速度。
- 初始化偏置矩阵b[l],使用np.zeros(shap),即b为全0矩阵。shape为(第l层的神经元个数, 1).
(二)核心代码:
def initialize_parameters_deep(layer_dims):
parameters = {}
L = len(layer_dims) # number of layers in the network
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1]) * 0.01
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))
assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))
return parameters参数说明:
- layer_dims:函数输入,是一个数组,包含了每一层的维度;比如:layer_dims = [5, 4, 3],表示该神经网络含输入层一共有3层,输入特征个数为5,另外两层的神经元个数分别为4,3.
- W[1],..., W[L-1]和b[1],..., b[L-1]:分别为从第1层到L-1层的权重矩阵和偏置向量;在layer_dims = [5, 4, 3]的例子中,W[1] 和 W[2] 的形状分别为 (4, 5) 和 (3, 4),b[1] 和 b[2] 的形状分别为 (4, 1) 和 (3, 1).
- parameters:函数输出,是一个字典,包含关键字为"W[1]", "W[2]", ..., "b[1]", "b[2]"... 的所有键值对。
二、前向传播模块
(一)要点:前向传播流程概括为:[LINEAR -> RELU] × (L-1) -> LINEAR -> SIGMOID,如下图:

前向传播模块的实现分三步走:
- 线性计算 - LINEAR:Z[l] = W[l]A[l-1] + b[l];
- 激活函数 - LINEAR -> ACTIVATION:A[l] = g(Z[l]),其中,1到L-1层ACTIVATION是ReLU函数,最后一层的ACTIVATION是Sigmoid函数;
- 完整模型 - [LINEAR -> RELU] × (L-1) -> LINEAR -> SIGMOID。
(二)功能模块的实现:
线性计算
1、LINEAR模块实现:Z[l] = W[l] A[l-1] + b[l],其中,A[0] = X,核心代码如下:
def linear_forward(A, W, b):
Z = np.dot(W, A) + b
assert(Z.shape == (W.shape[0], A.shape[1]))
cache = (A, W, b)
return Z, cachelinear_forward()输入参数说明:
- A:来自前一层的激活函数值,形状为 (前一层的神经元个数,当前层的神经元个数);
- W:当前层的权重矩阵,形状为 (当前层的神经元个数,前一层的神经元个数);
- b:当前层的偏置向量,形状为 (当前层的神经元个数,1);
linear_forward()返回值说明:
- Z:激活函数的输入,即欲激活参数;Z的形状为:(当前层的神经元个数,样本数);
- cache:一个长度为3的元组,包含A[l-1], W[l]和b[l],用于反向传播计算。这里因为LINEAR模块的计算使用了参数A[l-1], W[l], b[l]的函数,因此保存的就是A[l-1], W[l], b[l],后面还有activation_cache,存的是Z,因为激活函数是关于Z的函数。
激活函数
2、RELU模块实现:RELU是从1到L-1层的激活函数,A=relu(Z)
RELU实现:A = np.maximum(0,Z);代码如下:
def relu(Z):
A = np.maximum(0,Z) # Element-wise maximum of array elements
assert(A.shape == Z.shape)
cache = Z
return A, cache
3、SIGMOID模块实现:SIGMOID是第L层的激活函数:A=sigmoid(Z),实现激活函数时要缓存Z值到变量cache,方便反向传播的计算。
SIGMOID实现:A = 1/(1+np.exp(-Z));代码如下:
def sigmoid(Z):
A = 1/(1+np.exp(-Z))
cache = Z
return A, cache因为激活函数是关于Z的函数:A=g(Z),其中g()为sigmoid或者relu,为了方便反向传播的计算,需要将Z值缓存到cache.
4、整合LINEAR -> ACTIVATION(即LINEAR -> RELU 和 LINEAR -> SIGMOID) 模块
def linear_activation_forward(A_prev, W, b, activation):
if activation == "sigmoid":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = sigmoid(Z)
elif activation == "relu":
Z, linear_cache = linear_forward(A_prev, W, b)
A, activation_cache = relu(Z)
assert (A.shape == (W.shape[0], A_prev.shape[1]))
cache = (linear_cache, activation_cache)
return A, cachelinear_activation_forward()输入参数说明(输入参数 A_prev, W, b 和 linear_forward()函数定义中的输入参数A, W, b含义完全相同)
- A_prev:来自前一层的激活函数值,形状为 (前一层的神经元个数,当前层的神经元个数);
- W:当前层的权重矩阵,形状为 (当前层的神经元个数,前一层的神经元个数);
- b:当前层的偏置向量,形状为 (当前层的神经元个数,1)。
- activation:字符串,表示激活函数的类型,只允许为"sigmoid"或"relu"。
linear_activation_forward()返回值说明:
- A:当前层经过LINEAR->ACTIVATION之后得到的激活函数值,形状为 (当前层的神经元个数,样本数)
- cache:一个长度为2的元组,由长度为3的元组linear_cache和数组activation_cache组成,其中,linear_cache表示LINEAR模块缓存的值,包括(A[l-1], W[l], b[l]),activation_cache表示ACTIVATION模块缓存的Z[l],其中,l表示当前层。
完整模型
5、整合前向传播的所有功能模块,实现[LINEAR -> RELU] × (L-1) -> LINEAR -> SIGMOID:
def L_model_forward(X, parameters):
caches = []
A = X
L = len(parameters) // 2 # number of layers in the neural network
# Implement [LINEAR -> RELU]*(L-1). Add "cache" to the "caches" list.
# 将LINEAR -> RELU的步骤重复了L-1次
for l in range(1, L):
A_prev = A
A, cache = linear_activation_forward(A_prev, parameters["W" + str(l)], parameters["b" + str(l)], "relu")
caches.append(cache)
# Implement LINEAR -> SIGMOID. Add "cache" to the "caches" list.
# LINEAR -> SIGMOID 功能模块
AL, cache = linear_activation_forward(A, parameters["W" + str(L)], parameters["b" + str(L)], "sigmoid")
caches.append(cache)
assert(AL.shape == (1,X.shape[1]))
return AL, cachesL_model_forward()输入参数说明:
- X:数据训练集,形状为 (特征数目, 样本数目);
- paramters:一个字典,包含关键字为"W[1]", "W[2]", ..., "b[1]", "b[2]"... 的所有键值对。第l层对应的W和b表示为W[l]和b[l],因此,len(parameters) // 2 表示层数;
L_model_forward()主体功能说明:
- for循环语句块:将LINEAR -> RELU的步骤重复了L-1次(从l=0到l=L-1);
- for循环语句块执行完毕后,再执行LINEAR -> SIGMOID功能模块。
L_model_forward()返回值说明:
- AL:最后一层激活函数得到的值,即概率向量,形状为(样本数,1);
- caches:是一个列表,包括了每一层的cache,每一层的cache的含义与linear_activation_forward()返回值的cache相同:
cache:一个长度为2的元组,由长度为3的元组linear_cache和数组activation_cache组成,其中,linear_cache表示LINEAR模块缓存的值,包括(A[l-1], W[l], b[l]),activation_cache表示ACTIVATION模块缓存的Z[l],其中,l表示当前层。
例如:第l层的cache是一个长度为2的元组,由长度为3的元组linear_cache和数组activation_cache组成,其中,linear_cache表示LINEAR模块缓存的值,包括(A[l-1], W[l], b[l]),activation_cache表示ACTIVATION模块缓存的Z[l]。
三、损失函数
损失函数计算公式:
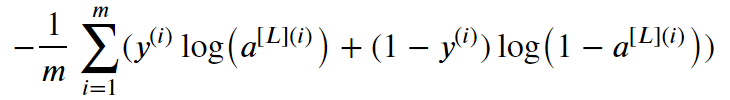
核心代码:
def compute_cost(AL, Y):
m = Y.shape[1]
# Compute loss from aL and y.
cost = -1/m * np.sum(Y * np.log(AL) + (1 - Y) * np.log(1 - AL))
# To make sure your cost's shape is what we expect (e.g. this turns [[17]] into 17).
cost = np.squeeze(cost)
assert(cost.shape == ())
return cost四、反向传播模块
(一)要点:
作用:计算损失函数在W和b上的梯度值(即分别求L对W和b的导数)
LINEAR->RELU->LINEAR->SIGMOID的前向和反向传播示意图:

同前向传播类似,反向传播模块的实现也分三步走:
- 线性函数 - LINEAR backward:求损失函数分别在W[l], b[l], A[l-1]上的导数,表示为dW[l], db[l]. dA[l-1];
- 激活函数 - LINEAR -> ACTIVATION backward,求激活函数对Z的导数dZ[l],具体地,从第1到L-1层计算ReLU函数的导数,第L层计算SIGMOID函数的导数
- 完整模型 - [LINEAR -> RELU] × (L-1) -> LINEAR -> SIGMOID backward:反向传播的启动从求dAL开始,即损失函数对最后一层的激活函数值A[L]的导数。
(二)功能模块的实现:
线性函数反向模块
1、线性函数为Z[l] = W[l]A[l-1] + b[l],求损失函数在dW[l], db[l], dA[l-1]上的导数
输入dZ[l] 和 cache,得到dW[l], db[l], dA[l-1]. 已知Z[l] = W[l]A[l-1] + b[l]和dZ[l](实现该部分需要假设已知dZ[l],dZ[l]由损失函数对激活函数求导所得,dZ[l]的计算参考下面的激活函数反向模块),

dW[l], db[l], dA[l]的计算公式如下:

代码如下:
def linear_backward(dZ, cache):
A_prev, W, b = cache
m = A_prev.shape[1]
dW = 1 / m * np.dot(dZ, cache[0].T)
db = 1 / m * np.sum(dZ, axis = 1, keepdims = True)
dA_prev = np.dot(cache[1].T, dZ)
assert (dA_prev.shape == A_prev.shape)
assert (dW.shape == W.shape)
assert (db.shape == b.shape)
return dA_prev, dW, dblinear_backward()输入参数说明:
- dZ:损失函数对当前层产生的Z求导,Z是当前层的线性函数的输出;
- cache:是一个长度为3的元组 (A_prev, W, b),为当前层的前向传播函数linear_forward()的返回值;A_prev, W, b分别为A[l-1], W[l], b[l],其中,l为当前层;
linear_backward()返回值说明:
- dA_prev,dW,db分别是损失函数对A[l-1], W[l], b[l]的导数,其形状分别与A[l-1], W[l], b[l]相同。
激活函数反向模块
用g(Z)表示激活函数,则A = g(Z),那么损失函数L(A,y)在Z上的导数计算方法为:
![]()
其中,dA[l] 是损失函数对A[l]求导,g'(Z[l])是g(Z[l])对Z[l]求导,这是求导的链式法则。
2、g(.)为RELU函数时的反向模块:RELU是从1到L-1层的激活函数,A=relu(Z)
def relu_backward(dA, cache):
Z = cache
dZ = np.array(dA, copy=True) # just converting dz to a correct object.
# When z <= 0, you should set dz to 0 as well.
dZ[Z <= 0] = 0
assert (dZ.shape == Z.shape)
return dZ3、g(.)为SIGMOID函数时的反向模块:SIGMOID是第L层的激活函数,A=sigmoid(Z)
def sigmoid_backward(dA, cache):
Z = cache
s = 1/(1+np.exp(-Z))
dZ = dA * s * (1-s)
assert (dZ.shape == Z.shape)
return dZ以上两个激活函数反向模块的输入参数和返回值一样,说明如下:
反向激活函数输入参数说明:
- dA:损失函数对A的导数;
- cache:当前层正向传播计算的Z值。
反向激活函数返回值说明:
- dZ:损失函数对Z的导数,与Z形状相同。
4、将 linear_backward(), relu_backward(), sigmoid_backward() 进行整合,实现 LINEAR->ACTIVATION的反向模块:
def linear_activation_backward(dA, cache, activation):
linear_cache, activation_cache = cache
if activation == "relu":
dZ = relu_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
elif activation == "sigmoid":
dZ = sigmoid_backward(dA, activation_cache)
dA_prev, dW, db = linear_backward(dZ, linear_cache)
return dA_prev, dW, dblinear_activation_backward()输入参数说明:
- dA:损失函数对当前层的A求导所得的值,形状和A相同;
- activation:字符串,标明是 "relu" 还是 "sigmoid";
- cache:由当前层正向传播计算所得,与linear_activation_forward()返回值中的cache一样:
- cache:一个长度为2的元组,由长度为3的元组linear_cache和数组activation_cache组成,其中,linear_cache表示LINEAR模块缓存的值,包括(A[l-1], W[l], b[l]),activation_cache表示ACTIVATION模块缓存的Z[l],其中,l表示当前层。
linear_activation_backward()返回值说明:
- dA_prev, dW, db:分别为损失函数对A[l-1], W[l], b[l]的导数,其中,l为当前层。
完整模型:

要启动反向传播,先要算出损失函数对最后一层(第L层) 的激活函数输出值AL的导数:
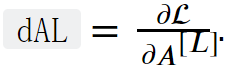
计算代码:
# derivative of cost with respect to AL
dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL))计算dAL是反向传播的起点,有了dAL才能从第L层往前层计算。
5、整合反向传播的所有功能模块,反向计算[LINEAR->RELU] × (L-1) -> LINEAR -> SIGMOID
def L_model_backward(AL, Y, caches):
grads = {}
L = len(caches) # the number of layers
m = AL.shape[1]
Y = Y.reshape(AL.shape) # after this line, Y is the same shape as AL
# Initializing the backpropagation
### START CODE HERE ### (1 line of code)
dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL))
### END CODE HERE ###
# Lth layer (SIGMOID -> LINEAR) gradients. Inputs: "dAL, current_cache". Outputs: "grads["dAL-1"], grads["dWL"], grads["dbL"]
current_cache = caches[L-1]
grads["dA" + str(L-1)], grads["dW" + str(L)], grads["db" + str(L)] = linear_activation_backward(dAL, current_cache, activation = "sigmoid")
# Loop from l=L-2 to l=0
for l in reversed(range(L-1)):
# lth layer: (RELU -> LINEAR) gradients.
# Inputs: "grads["dA" + str(l + 1)], current_cache". Outputs: "grads["dA" + str(l)] , grads["dW" + str(l + 1)] , grads["db" + str(l + 1)]
current_cache = caches[l]
dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads["dA" + str(l+1)], current_cache, activation = "relu")
grads["dA" + str(l)] = dA_prev_temp
grads["dW" + str(l + 1)] = dW_temp
grads["db" + str(l + 1)] = db_temp
return gradsL_model_backward()输入参数说明:
- AL:第L层的激活函数输出,为概率向量,形状为(样本数,1),与L_model_forward()的返回值AL含义相同;
- Y:真实的标签向量,元素为0或1,形状为(样本数,1),损失函数的计算需要AL和Y,即L(AL, Y);
- caches:与L_model_forward()的返回值caches含义相同,如下:
- caches:是一个列表,包括了每一层的cache,每一层的cache的含义与linear_activation_forward()返回值的cache相同。例如:第l层的cache是一个长度为2的元组,由长度为3的元组linear_cache和数组activation_cache组成,其中,linear_cache表示LINEAR模块缓存的值,包括(A[l-1], W[l], b[l]),activation_cache表示ACTIVATION模块缓存的Z[l]。
L_model_backward()返回值说明:
grads:是一个字典,包含所有层的dA[0], dA[1], ..., dA[L-1], dW[1], dW[2], ..., dW[L], db[1], db[2], ...db[L]的键值对。
注意:返回值不包括dA[L],因为dA[L]就是dAL,前面计算过了,是反向传播的起点。
五、更新参数:更新每一层的参数W和b
更新公式为:
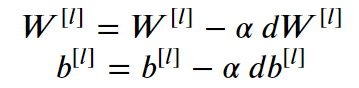
其中,alpha为学习率,控制每一次参数的改变步距,l从1到L,代码如下:
def update_parameters(parameters, grads, learning_rate):
L = len(parameters) // 2 # number of layers in the neural network
# Update rule for each parameter. Use a for loop.
for l in range(L):
parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate * grads["dW" + str(l+1)]
parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate * grads["db" + str(l+1)]
return parametersupdate_parameters()输入参数说明:
- parameters:和initialize_parameters_deep()中的返回值含义一致:
- parameters:是一个字典,包含关键字为"W[1]", "W[2]", ..., "b[1]", "b[2]"... 的所有键值对。
- grads:包含所有梯度值(导数),由L_model_backward()函数输出:
- grads:是一个字典,包含所有层的dA[0], dA[1], ..., dA[L-1], dW[1], dW[2], ..., dW[L], db[1], db[2], ...db[L]的键值对。
update_parameters()返回值数说明:
- parameters: 是一个字典,字典的所有键与输入相同,值为更新后的值。
至此,实现分类预测的L层深度网络的正向和反向传播的所有功能模块全部实现。















 661
661











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









