







以下内容总结自B站:深度强化学习(Deep Reinforcement Learning)_哔哩哔哩_bilibili
一、概述:
Value-based learning(价值学习):使用神经网络Deep Q network(DQN)来近似学习;使用时间差分(TD:temporal different)算法来训练DQN,即学习神经网络的参数。
二、概念回顾:
1、基于策略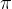 的动作价值函数(Action-value function):
的动作价值函数(Action-value function):
,表示
时刻状态
下做动作之后能获得的回报的期望。
是回报 (Return):表示t时刻开始未来执行一组动作后能够获得的奖励之和。
是即时奖励,与状态
和动作
相关;
是折扣因子,取[0,1]之间。未来的奖励不确定,所以需要在未来奖励上打个折扣。
- 动作价值函数
的现实意义:如果用策略
下做动作
是否明智,即
- 用不同的策略
- 下面尝试把
2、Optimal action-value function(最优动作价值函数
 ):
):
,表示在状态
下,做
能得到最好的回报的期望。
- 最优动作价值函数的现实意义: 在状态
能指导Agent做决策。有了
.
- Value-based learning(价值学习)就是使用神经网络Deep Q network(DQN)来学习一个函数
,该函数能够近似
三、Deep Q network(DQN)
(一)全貌概览:

假设我们已经训练好了一个DQN,即DQN的参数w已经有了,那么:
- 将屏幕的一帧作为输入,通过卷积层(Conv)进行特征提取,得到特征向量(feature),然后通过全连接层(Dense)将特征映射到输出向量(图中紫色方块)。
- 输出向量就是对动作的打分,向量的每一个元素对应一个动作的得分。例如,超级玛丽游戏中动作有left,right,up三个动作,因此输出向量是三维的:[2000,1000, 3000]。通过这个向量,就能指导Agent应该做的动作。Agent此时应该做up动作,因为该动作分数最高,代表做该动作能获得的回报的期望最大。
(二)如何使用DQN指导Agent打游戏:

- 以
- Agent执行
;
- 同时环境还会告诉Agent得到的即时奖励
,
- 重复此过程,直至游戏结束。
如何训练DQN?最常用的是TD算法。
四、时序差分:Temporal Difference(TD) Learning
先看一个例子:开车从纽约(NYC)到亚特兰大(Atlanta)需要多长时间?用模型进行预测,例如
,分钟。如何更新这个模型?

方法一:
- 模型做一个预测,这个预测一开始可以是随机的:
,即
- 从NYC开车到Atlanta,结束一次完整行程后得到真实时间
,如,
- 计算预测值和真实值的损失函数Loss:
(类似均方损失函数),训练模型的目的就是使估计值逐渐逼近真实值,即误差尽可能小。
- 计算梯度:
(链式法则,L是q的函数,q是w的函数)
- 梯度下降法更新参数w:
(
为学习率,值在(0,1)之间)
方法一特点:通过梯度下降更新参数w,使模型估计值越来越逼近真实值。但该方法必须等一整次旅途结束后,才能对模型进行一次更新(这是蒙特卡洛方法的典型特征)。能否在完成一整次旅途之前就对模型更新,即走一步更新一次?
方法二(TD算法):

- 模型做一个预测,这个预测一开始可以是随机的:
(同方法一)
- 从NYC开车到途中某处(华盛顿:DC),观测到实际使用了300分钟;此时模型又做一个预测:预测从DC到Atlanta需要600分钟。
- 更新预测值:300 + 600 = 900 分钟,这个新的估计成为TD target,记为
这个值比一开始的纯估计
要更可靠,因为里面包含了300的真实值。越接近Atlanta,TD target就越准确。
- 计算最初预测值和TD target的损失函数Loss:
称为TD error。模型训练的目的就是使TD error接近0.
- 计算梯度:
(链式法则,L是q的函数,q是w的函数)(同方法一)
- 梯度下降法更新参数w:
TD算法特点:不必等一次完整旅途结束就可以更新模型参数,走一步就能更新一次。用TD算法来训练打游戏的DQN非常合适:不需要打完游戏就能更新DQN参数。
五、用TD算法训练DQN
(一)将TD算法用在DQN中:

在估计旅途耗时的例子中,NYC到ATL的总估计时间 约等于 NYC到DC的真实时间 加上 DC到ATL的估计时间。类比到深度强化学习中,表示:DQN在t时刻做的估计值(期望)约等于 在t时刻观测到的真实奖励 加上 DQN在t+1时刻做的估计值(期望)。
下面解释公式的来源:
回顾的定义:
是回报 (Return),表示t时刻开始未来执行一组动作后能够获得的奖励之和:
从第二项起,拿出公有的,将公式变为:
根据回报的定义,上式括号里的项共同表示了回报,则公式变为:
相邻两个时刻的折扣回报之间的关系:
DQN在t时刻的输出是,这是对回报
的期望的近似:
DQN在t+1时刻的输出是,这是对回报
的期望的近似 :
因此,.
约等号左边是DQN的预测,右边是TD target.
(二)用TD算法训练DQN的模型参数
TD算法的一次循环由如下步骤组成,每次循环更新一次模型参数w:
- 在
时刻,观测到当前的状态
,
是当前的模型参数;
- 在
时刻,模型观测到了真实奖励
. 动作
- 计算TD target:
,因为
.
- 计算最初预测值
和TD target的损失函数Loss:
- 计算梯度:
. 记
,这个梯度可以用Pytorch自动求。
- 梯度下降法更新参数w:
.















 8167
8167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









