






字节序:
IP地址和端口号再套接字地址结构体中总是以网络字节序的形式存储的
主机字节序:
主机内部内存存储数据的方式
a的主机字节序--->网络字节序--->b的主机字节序
网络字节序固定为大端
小端字节序:低位存在低字节
字节序转换函数:
htons(),htonl(),ntohs(),ntohl()
h:host
n:network
s:short,16位(如端口号)
l:long,32位(如IPv4地址)
注意:这四个函数的参数不是字符串,而我们从中断输入的是字符串,所以需要用atoi函数将字符串先转为int型变量,才可以用这四个函数。否则:errno=13(Permission to deny)
主机字节序:使用小端字节序
网络字节序:使用大端字节序
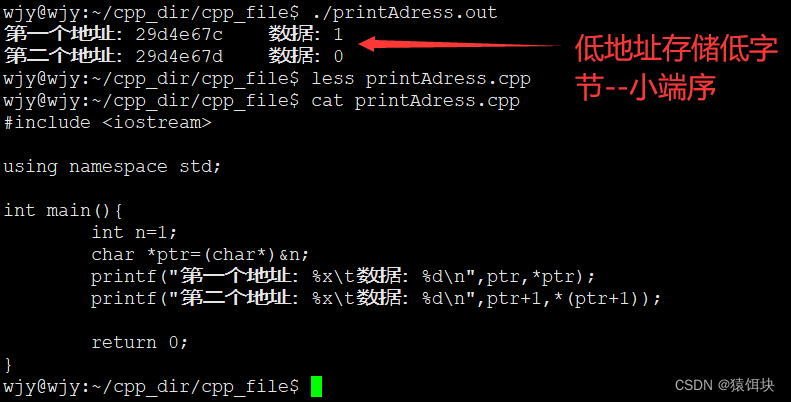
怎么判断主机是大端字节序还是小端字节序
从低地址获取一个整数的前一个字节数据(大端存储)或者后一个字节数据(小端)----数据从低地址向高地址存储
int main() {
int num =1;//高-00000000 00000000 00000000 00000001-低
char* p = (char*) & num;//把一个字节的地址赋给char指针,要么是00000000,要么是00000001
if (*p ==0)
cout << "大端存储" << endl;
else if(*p==1)
cout << "小端存储" << endl;
return 0;
}int main() {
int num =0x11223344;//11存储在一个字节,22存储在一个字节...
char* p = (char*) & num;//把一个字节的地址赋给char指针,要么是0x11,要么是0x44
for (int i = 0; i < 4; ++i)
printf("%x\n", *(p + i));//注意,四位二进制才表示一个十六进制数,而一个字节八位
if (*p ==0x11)
cout << "大端存储" << endl;
else if(*p==0x44)
cout << "小端存储" << endl;
return 0;
}
联合体判断大小端
#include <iostream>
using namespace std;
int main() {
union {
int a;
char b;
} endian;//联合体成员都具有相同一块地址
//数据是由低地址向高地址存储的,所以b在低地址处
endian.a = 1;//00000000 00000000 00000000 00000001
if (endian.b == 1) {//低地址处存储地位
printf("Little Endian\n");
}
else {//低地址处存储高位
printf("Big Endian\n");
}
return 0;
}net_pton:
#include <arpa/inet.h>
int inet_pton(int af, const char *src, void *dst);
IP地址在电脑中的保存形式通常是ASCLL码的形式,而套接字中保存IP地址的方式是二进制的数值形式,所以,在建立套接字保存IP地址时,需要将我们输入的字符串形式的IP地址转换为数值形式存放在套接字中
p---presentation(表达式格式) n---numeric(数值格式)
成功返回1,
inet_ntop:
#include <arpa/inet.h>
const char *inet_ntop(int af, const void *src,char *dst, socklen_t size);
前三个参数和inet_pton相同,最后一个参数是目标存储单元的大小,socklen_t类型。
成功返回存储单元的地址,失败返回NULL。
inet_ntoa
inet_ntoa()是将网络地址转换成“.”点隔的字符串格式。
获取对端的IP和端口
std::string client_ip_port = std::string(inet_ntoa(client.sin_addr)) + ":" + std::to_string(ntohs(client.sin_port));
std::string client_ip = std::string(inet_ntoa(client.sin_addr));套接字类型:
SOCK_STREAM,SOZK_DGRAM,...
listen:
服务端由listen函数告知内核进行一下工作:
监听套接字,listen的监听是全程监听,所以不会阻塞。
未完成连接的放入未完成连接队列,已完成的放入已连接队列
当队列满了之后将拒绝新的连接请求
accept():
从等待连接队列中复制等待连接的套接字,得到套接字副本,将套接字中属于对端的信息存入cliaddr,并绑定在套接字中,得到新的套接字,这个套接字有s端和c端,两端的控制信息,并和客户端套接字连接在一起。(完成连接)
那么新的套接字创建,原来等待连接的套接字会怎么样:
继续等待下一个套接字的到来,然后进行复制连接。
bind:
客户端为什么不用bind绑定端口和目的地址:
端口号
通配地址:
INADDR_ANY的值位0(0.0.0.0:表示不确定地址,所有地址,任意地址),IP地址设置位统配地址,则地址由内核选择
统配地址需要转换:htonl(INADDR_ANY);
127.0.0.1是回送地址,指明目的地址是本机地址
s端不仅需要用户设置自己的地址和端口号,然后绑定到套接字中,也需要接收c端的套接字和套接字中对端的信息,然后存放在本端建立的用来存储对端信息的套接字地址结构体中,然后绑定到套接字中,这样套接字中就有双份通信的信息。
c端不需要用户设置本端IP地址和端口号,只需要设置目的s端的,本端的在connect时内核自动选择并绑定。
bind:
c端不需要bind函数,s端才需要
全局套接字和局部套接字:
使用的权限如同全局变量和局部变量一样
connect:
非阻塞connect:
非阻塞TCP套接字调用connect会发生什么:
非阻塞TCP套接字调用connect会立即返回一个EINPROGRESS的错误,但是已经发起的TCP三路握手会继续进行。
所谓的非阻塞connect不是这个connect函数本身是非阻塞的,而是由于调用这个函数的套接字是非阻塞的。
非阻塞connect的返回值:
1,可能返回0:当客户端和服务端都在一台主机上时,函数成功饭返回0.
2,返回-1:
1):errno=EINPROGESS -------表明还在连接
2):errno!=EINPROGRESS ------表明连接不成功。
再使用getsockopt()函数检测套接字是否连接成功:
int error=0;
getsockopt(sockfd,SOL_SOCKET,SO_ERROR,&error,sizeof(error))
如果error成功获取,即error不为0,则表示套接字没有建立
IPv4的套接字地址结构体:

IPv6的套接字地址结构体:

通用套接字地址结构体:


服务端套接字建立过程:
int listenfd,connfd;
sockaddr_in servaddr;
socklen_t serlen=sizeof(servaddr);
listenfd=socket(AF_INET,SOCK_STREAM,0);
bzero(&servaddr,serlen);
servaddr.sin_family=AF_INET;
servaddr.sin_port=htons(atoi(argv[1]));
servaddr.sin_addr.s_addr=htonl(INADDR_ANY);
int retb=bind(listenfd,(SA*)&servaddr,serlen);
assert(retb!=-1);
sockaddr_in cliaddr;
socklen_t clilen=sizeof(cliaddr);
int connfd=accept(sockfd,(SA*)&cliaddr,&clilen);
assert(connfd!=-1);
定义监听描述符
定义保存服务端信息的套接字地址结构体
建立监听描述符
清空地址结构体
将服务端信息存入地址结构体
将监听描述符和地址结构体绑定
监听
连接套接字,保存客户端信息入套接字
注意:bind和accept的参数的强制类型转换
客户端套接字建立过程:
int sockfd;
sockaddr_in servaddr;
socklen_t serlen=sizeof(servaddr);
sockfd=socket(AF_INET,SOCK_STREAM,0);
bzero(&servaddr,serlen);
servaddr.sin_family=AF_INET;
servaddr.sin_port=htons(atoi(argv[2]));
inet_pton(AF_INET,argv[1],&servaddr.sin_addr);
int retc=connect(sockfd,(SA*)&servaddr,serlen);
assert(retc!=-1);
建立描述符
建立IPv4套接字地址结构体
创建套接字
清空套接字地址结构体
设置套接字地址结构体信息
发起连接
无论是C端还是S端,都要设置服务端的信息
C端设置是为了找到目标服务器
S端设置是为了将本端信息绑定入监听套接字,方便发送给客户端,完成连接
c端不需要用户设置本端IP地址和端口号,只需要设置目的s端的,本端的在connect时内核自动选择并绑定。
目标主机的IP地址存入可以用htonl(),也可以用inet_pton()
地址族和协议族:


通配地址
0.0.0.0
IP地址设置为通配地址(INADDR_ANY),则本地IP地址由内核任意选择
环回地址
127.0.0.1
指定目标主机的IP地址为本机IP的IP地址
三个预定义的文件指针(FILE*):
stdin----0,stdout----1,stderr----2。
注意和标准描述符的区分:
标准输出描述符:STDOUT_FILENO
标准输入描述符:STDIN_FILENO
标准错误描述符:STDERR_FILENO
关闭选项:
parr[j].events&=~POLLIN;
注意:取反,然后与运算才能关闭,或运算不能关闭
errno:
是一个整型变量,当系统调用或者库函数发生错误时,通过设置errno的值来告诉调用者发生了什么错误。
EINTR:当系统调用被中断时返回的值。
errno的值的意义:
#ifndef _ASM_GENERIC_ERRNO_BASE_H
#define _ASM_GENERIC_ERRNO_BASE_H
#define EPERM 1 /* Operation not permitted */
#define ENOENT 2 /* No such file or directory */
#define ESRCH 3 /* No such process */
#define EINTR 4 /* Interrupted system call */
#define EIO 5 /* I/O error */
#define ENXIO 6 /* No such device or address */
#define E2BIG 7 /* Argument list too long */
#define ENOEXEC 8 /* Exec format error */
#define EBADF 9 /* Bad file number */
#define ECHILD 10 /* No child processes */
#define EAGAIN 11 /* Try again */
#define ENOMEM 12 /* Out of memory */
#define EACCES 13 /* Permission denied */
#define EFAULT 14 /* Bad address */
#define ENOTBLK 15 /* Block device required */
#define EBUSY 16 /* Device or resource busy */
#define EEXIST 17 /* File exists */
#define EXDEV 18 /* Cross-device link */
#define ENODEV 19 /* No such device */
#define ENOTDIR 20 /* Not a directory */
#define EISDIR 21 /* Is a directory */
#define EINVAL 22 /* Invalid argument */
#define ENFILE 23 /* File table overflow */
#define EMFILE 24 /* Too many open files */
#define ENOTTY 25 /* Not a typewriter */
#define ETXTBSY 26 /* Text file busy */
#define EFBIG 27 /* File too large */
#define ENOSPC 28 /* No space left on device */
#define ESPIPE 29 /* Illegal seek */
#define EROFS 30 /* Read-only file system */
#define EMLINK 31 /* Too many links */
#define EPIPE 32 /* Broken pipe */
#define EDOM 33 /* Math argument out of domain of func */
#define ERANGE 34 /* Math result not representable */
#endif#ifndef _ASM_GENERIC_ERRNO_H
#define _ASM_GENERIC_ERRNO_H
#include <asm-generic/errno-base.h>
#define EDEADLK 35 /* Resource deadlock would occur */
#define ENAMETOOLONG 36 /* File name too long */
#define ENOLCK 37 /* No record locks available */
#define ENOSYS 38 /* Function not implemented */
#define ENOTEMPTY 39 /* Directory not empty */
#define ELOOP 40 /* Too many symbolic links encountered */
#define EWOULDBLOCK EAGAIN /* Operation would block */
#define ENOMSG 42 /* No message of desired type */
#define EIDRM 43 /* Identifier removed */
#define ECHRNG 44 /* Channel number out of range */
#define EL2NSYNC 45 /* Level 2 not synchronized */
#define EL3HLT 46 /* Level 3 halted */
#define EL3RST 47 /* Level 3 reset */
#define ELNRNG 48 /* Link number out of range */
#define EUNATCH 49 /* Protocol driver not attached */
#define ENOCSI 50 /* No CSI structure available */
#define EL2HLT 51 /* Level 2 halted */
#define EBADE 52 /* Invalid exchange */
#define EBADR 53 /* Invalid request descriptor */
#define EXFULL 54 /* Exchange full */
#define ENOANO 55 /* No anode */
#define EBADRQC 56 /* Invalid request code */
#define EBADSLT 57 /* Invalid slot */
#define EDEADLOCK EDEADLK
#define EBFONT 59 /* Bad font file format */
#define ENOSTR 60 /* Device not a stream */
#define ENODATA 61 /* No data available */
#define ETIME 62 /* Timer expired */
#define ENOSR 63 /* Out of streams resources */
#define ENONET 64 /* Machine is not on the network */
#define ENOPKG 65 /* Package not installed */
#define EREMOTE 66 /* Object is remote */
#define ENOLINK 67 /* Link has been severed */
#define EADV 68 /* Advertise error */
#define ESRMNT 69 /* Srmount error */
#define ECOMM 70 /* Communication error on send */
#define EPROTO 71 /* Protocol error */
#define EMULTIHOP 72 /* Multihop attempted */
#define EDOTDOT 73 /* RFS specific error */
#define EBADMSG 74 /* Not a data message */
#define EOVERFLOW 75 /* Value too large for defined data type */
#define ENOTUNIQ 76 /* Name not unique on network */
#define EBADFD 77 /* File descriptor in bad state */
#define EREMCHG 78 /* Remote address changed */
#define ELIBACC 79 /* Can not access a needed shared library */
#define ELIBBAD 80 /* Accessing a corrupted shared library */
#define ELIBSCN 81 /* .lib section in a.out corrupted */
#define ELIBMAX 82 /* Attempting to link in too many shared libraries */
#define ELIBEXEC 83 /* Cannot exec a shared library directly */
#define EILSEQ 84 /* Illegal byte sequence */
#define ERESTART 85 /* Interrupted system call should be restarted */
#define ESTRPIPE 86 /* Streams pipe error */
#define EUSERS 87 /* Too many users */
#define ENOTSOCK 88 /* Socket operation on non-socket */
#define EDESTADDRREQ 89 /* Destination address required */
#define EMSGSIZE 90 /* Message too long */
#define EPROTOTYPE 91 /* Protocol wrong type for socket */
#define ENOPROTOOPT 92 /* Protocol not available */
#define EPROTONOSUPPORT 93 /* Protocol not supported */
#define ESOCKTNOSUPPORT 94 /* Socket type not supported */
#define EOPNOTSUPP 95 /* Operation not supported on transport endpoint */
#define EPFNOSUPPORT 96 /* Protocol family not supported */
#define EAFNOSUPPORT 97 /* Address family not supported by protocol */
#define EADDRINUSE 98 /* Address already in use */
#define EADDRNOTAVAIL 99 /* Cannot assign requested address */
#define ENETDOWN 100 /* Network is down */
#define ENETUNREACH 101 /* Network is unreachable */
#define ENETRESET 102 /* Network dropped connection because of reset */
#define ECONNABORTED 103 /* Software caused connection abort */
#define ECONNRESET 104 /* Connection reset by peer */
#define ENOBUFS 105 /* No buffer space available */
#define EISCONN 106 /* Transport endpoint is already connected */
#define ENOTCONN 107 /* Transport endpoint is not connected */
#define ESHUTDOWN 108 /* Cannot send after transport endpoint shutdown */
#define ETOOMANYREFS 109 /* Too many references: cannot splice */
#define ETIMEDOUT 110 /* Connection timed out */
#define ECONNREFUSED 111 /* Connection refused */
#define EHOSTDOWN 112 /* Host is down */
#define EHOSTUNREACH 113 /* No route to host */
#define EALREADY 114 /* Operation already in progress */
#define EINPROGRESS 115 /* Operation now in progress */
#define ESTALE 116 /* Stale file handle */
#define EUCLEAN 117 /* Structure needs cleaning */
#define ENOTNAM 118 /* Not a XENIX named type file */
#define ENAVAIL 119 /* No XENIX semaphores available */
#define EISNAM 120 /* Is a named type file */
#define EREMOTEIO 121 /* Remote I/O error */
#define EDQUOT 122 /* Quota exceeded */
#define ENOMEDIUM 123 /* No medium found */
#define EMEDIUMTYPE 124 /* Wrong medium type */
#define ECANCELED 125 /* Operation Canceled */
#define ENOKEY 126 /* Required key not available */
#define EKEYEXPIRED 127 /* Key has expired */
#define EKEYREVOKED 128 /* Key has been revoked */
#define EKEYREJECTED 129 /* Key was rejected by service */
/* for robust mutexes */
#define EOWNERDEAD 130 /* Owner died */
#define ENOTRECOVERABLE 131 /* State not recoverable */
#define ERFKILL 132 /* Operation not possible due to RF-kill */
#define EHWPOISON 133 /* Memory page has hardware error */
#endifEAGAIN--EWOULDBLOCK
read数据或者write数据时,可以会返回以上两种错误
EAGAIN:开辟的缓冲区已经满了,暂时还不能写入数据
EWOULDBLOCK:是因为套接字设置为非阻塞的状态,当套接字的TCP模块的缓冲区中已经没有数据可读是,read函数返回-1,置errno为EWOULDBLOCK。
缓冲区已满,系统暂时无法向缓冲区填充数据导致
注意:这种清空并不是套接字异常,需要再次读取数据
I/O复用:
三个函数调用成功返回的都是准备就绪的描述符个数。
select:
int select(int maxi, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
maxi是最大描述符加 1
为什么每一次循环都需要重新加入描述符到集合中。因为select成功返回后,只有准备就绪的fd留在了集合内。
select的使用过程:
建立集合(fd_set)--->清空集合(FD_ZERO())---->加入套接字(FD_SET())--->select中使用---->一个一个套接字的去判断是否准备好(是否还在集合中)
为什么要把描述符放入不同集合当中:
把需要检测的描述符放入集合之中,通过select函数就可以把准备好的描述符留在集合中,把没有准备清除,因为被清除,所以需要再次检测时需要再把需要检测的描述符加如集合中。
集合之间可以相互赋值,即把集合中有的描述符赋值一份给另一个集合。
如何判断某个套接字是否准备好:
FD_ISSET();
如果要设置阻塞时间:
struct tiemval{
long tv_sev;
long tv_usev;
};
poll:
poll(struct pollfd* array,int narray,int timeout)
struct pollfd
{
int fd;
short events;
short revents
};
events:

POLLRDHUP: . 读取到对端关闭
(至此,就有两种检测对端关闭的方法:
1,read类函数返回0
2,fd的事件中发生POLLRDHUP事件
)
用&运算符来判断当前发生的事件是不是指定事件
timeout:
INFTIM(-1):阻塞
0:不阻塞
timeout>0:等待timeout秒
如何判断某个套接字是否准备好:
直接在poll后用&判断某个套接字当前发生的事件是不是指定事件。
poll的利用过程:
建立pollfd数组---》初始化数组元素中的数据---》监听
epoll:
epoll是Linux特有的I/O复用函数
1,epoll_create:
epoll在使用之前需要先创建内核事件表---epoll_create(int size);
size仅表示内核事件表的大小
size应该根据什么选值呢:
函数返回事件表描述符
当某一进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关。eventpoll结构体如下所示:
struct eventpoll{
....
/*红黑树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/ //存放需要监控的事件
struct rb_root rbr;
/*双链表中则存放着将要通过epoll_wait返回给用户的满足条件的事件*/ //存放准备就绪的事件
struct list_head rdlist;
....
};
每一个epoll对象都有一个独立的eventpoll结构体,
2,epoll_ctl:
事件表操作函数---
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
op:
EPOLL_CTL_ADD:往事件表中注册fd以及fd上的事件
EPOLL_CTL_MOD:修改Ffd上注册的事件
EPOLL_CTL_DEL:从事件表中删除fd以及fd上的事件
fd:就是要操作的描述符
event:为每一个fd单独创建的事件结构体,用来注册fd上要注册的事件
注意:
1,如果是修改和删除事件表中的数据,event(最后一个参数)就可以不用指定了,直接指定为0(NULL)
2,对于EPOLL_CTL_MOD,新建一个epoll_event对象,修改注册事件时,fd之前注册的所有事件将不存在了。
struct epoll_event{
_uint32_t events;
epoll_data_t data;
};
events可以指定的事件和poll一样,只是事件的前面多一个E,如EPOLLIN
但是epoll多两个事件:EPOLLET,EPOLLONESHOT。
注意:
1,服务端,listenfd的事件注册注册为可读事件,因为连接的过程就是读取数据写入套接字的过程。
2,注册事件时,一定要用’|‘运算保留之前你的事件。
epoll_data_t是一个联合体:
联合体特征:任意时刻只允许一个成员有值,不可 拥有引用成员
typedef union epoll_data
{
void* ptr;
int fd;
uint32_t u32;
uint64_t u64;
}epoll_data_t;
对于epoll事件表中断开连接的套接字如何处理:
利用epoll_ctl()函数的EPOLL_CTL_DEL选项将套接字从事件表中删除,再关闭套接字
3,epoll_wait:
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
参数:
events:struct epoll_event类型的数组,用来存放准备就绪的事件
timeout:和poll意义相同
maxevents:指定最多监听多少个事件,也可以就取events数组的大小
(有时epoll_wait附近加cout语句epoll_wait会立即返回,不阻塞)
epoll中fd的LT模式和ET模式:
LT模式(level trigger--电平(水平)触发):fd的默认工作方式。
即使用默认工作方式工作的fd,当这个fd上的事件准备好时,应用程序可以不用处理,可以等到下一次使用epoll_wait检测出来准备好时再处理,可以这样循环,知道事件被处理
ET模式(edge trigger--边沿触发):需要使用events结构体注册
:当fd使用ET模式时,对于fd上准备好的某一事件,应用程序必须立即处理,
一位此fd上的本事只会被通知应用程序一次,下一次epoll_wait检测将不会向应用程序通知这同一事件
那么什么是这同一事件呢:
比如fd上第一次有数据可读,但是没有被读取。那么epoll_wait再次检测到上一次已经通知了的事件没有被处理,epoll_wait将不会再通知这同一事件。
这就要求使用ET模式的fd使用循环读取完数据
那么当同一个fd上再有新的数据可读时,能否被通知呢,即属于新事件呢,还是同一事件呢:
属于新事件。
ET模式不可以用&运算检测出来:
eg:
if(arrEvent[i].events&EPOLLET)
func_ET(arrEvent[i],epollfd,arrEvent[i].data.fd,listenfd);
else
{
cout<<(arrEvent[i].events&EPOLLET)<<endl;//这个计算出来的结果为0
func_LT(arrEvent[i],epollfd,arrEvent[i].data.fd,listenfd);
}
select,poll,epoll对于准备就绪事件的处理区别:
select:只保留准备就绪事件的描述符在集合中
poll:所有准备好以及没有准备好的事件都会保留在数组中,当有事件准备好时,需要一个个检查每一个描述符所代表的事件是否准备好(检查事件是否发生)
epoll:有数组用来保存准备好的事件(将准备好的事件从内核事件表中复制到数组中)
select,poll,epoll的异同点:
相同点:1,返回值都是准备就绪的描述符个数
不同点:
1,套接字的保存:select保存在集合中,poll保存在pollfd数字中,epoll需要监听的保存在eventpoll事件表的红黑树结构中,有事件需要处理的套接字保存在epoll_event数组中。
2,select返回的集合中保存了准备好的套接字,epoll有数组保存准备好的套接字,但是poll没有用于保存准备好的套接字,需要检测所有套接字的事件。
2,再次调用函数时,select需要重置集合,poll和epoll不需要,poll需要一个一个的检测发生的事件是不是设置的事件,而epoll利用数组保存准备好的事件
3,能监听的最大描述符:
select:可以监听的最大描述符数量有限
64位机:2048
32位机:1024
poll:因为用来保存描述符和事件的数据结构是链表,所以可以监听的描述符没有限制
epoll:虽然有上限,但是很大,10万以上
4,工作模式:
select,poll只能工作在LT模式,epoll工作既可以工作在LT也可以工作在ET模式
5,在内核中对事件检测的方式不同:
select和poll启动的内核检测方式是采用轮询的方式:
即每一次调用函数启动的内核事件都是要循环检测每一个注册了描述符及事件的集合或者数组,将准备就绪的事件拷贝到应用程序。
有I/O事件发生时,我们并不知道是哪几个描述符(可能有一个,多个,甚至全部),我们只能无差别轮询所有描述符和事件,找出准备就绪的描述符和事件。所以select具有O(n)的无差别轮询复杂度,同时处理的事件越多,无差别轮询时间就越长。
epoll采用回调的方式:
即内核不会一个一个地去检测事件的发生,而是等待事件的发生,当有事件发生时,内核调用回调函数callback()把准备就绪的事件加入事件表中,之后就把将准备就绪事件的内容拷贝到用户空间
6,效率:
select和poll:
因为内核检测方式为轮询,所以fd越多,效率越低
epoll:
不是轮询的方式,不会随着FD数目的增加效率下降。Epoll的效率就会远远高于select和poll。
但是注意:当准备就绪的fd非常多时,回调函数callback()会被频繁调用,性能上也会有问题
其中epoll是Linux所特有,而select则应该是POSIX所规定,一般操作系统均有实现
7,消息传递方式
select:内核需要将消息传递到用户空间,都需要内核拷贝动作
poll:同上
epoll:epoll通过内核和用户空间共享一块内存来实现的。
三个函数对于监听的数量的区别:
int select(int maxi, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
poll(struct pollfd* array,int nfds,int timeout)
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
注意:maxi,nfds,maxevents都是最大描述符加1,不是有些书本上说的数组元素个数,或者需要监听的事件数量。
如何防止多个线程同时处理一个socket:
当我们用多线程处理数据时,一个数据还没有处理完成,另外的数据就已经到达,这时就会有多个
线程同时处理一个套接字上的数据。
解决办法:在套接字的epoll_event结构体对象中注册EPOLLONESHOT事件。
原理:
对于注册了EPOLLONESHOT事件的套接字,当这个套接字上指定的事件发生 时,操作系统只会让其被触发一次,之后就算这个套接字有事件可以被触发,操作系统都不再让其触发,这个套接字还在事件表中,只是不会再被使用。
那么怎么让这套接字可以不断被触发使用:
当这个套接字被使用之后,我们调用重置的子函数再一次利用epoll_ctl将其再放入事件表中就可以了,这样不断循环,就可以不断被使用了
注意:因为这个套接字还是在事件表中的,只是不再被使用。
所以epoll_ctl()中,我们不再使用EPOLL_CTL_ADD加入套接字,而是使用EPOLL_CTL_MOD修改这个套接字的注册事件。
在重置的子函数中,我们需要重新建立一个epoll_even对象,重新配置fd,event,再注册进入事件表。
注意:
1,ET模式只是让套接字上同一就绪事件只会被通知一次,而EPOLLONESHOT是让这个套接字只能被使用一次。
2,注册了EPOLLONESHOT的套接字,当数据读取完毕之后,read类函数返回-1,并置errno为EAGAIN,所以当检测到读取的函数返回-1,且errno==EAGAIN时,就利用进行重置
3,多线程处理套接字时要记得使用
shutdown():
close有两个限制:
1,把引用计数减一,当引用计数为0时才关闭连接。
2,close关闭终止连接的同时,终止数据的双向传输。
shutdown可以不管引用计数,直接终止套接字或者套接字的读功能或者写功能。
半关闭:
就是关闭套接字的写功能
常用函数:
字符串转int,float函数:
atoi(),atol(),atoll()
assert:
如果表达式为假,想stderr发出一条错误信息,然后调用abort来终止程序运行。
inet_pton:
#include <arpa/inet.h>
int inet_pton(int af, const char *src, void *dst);
IP地址在电脑中的保存形式通常是ASCLL码的形式,而套接字中保存IP地址的方式是二进制的数值形式,所以,在建立套接字保存IP地址时,需要将我们输入的字符串形式的IP地址转换为数值形式存放在套接字中
p---presentation(表达式格式) n---numeric(数值格式)
成功返回1,
inet_ntop:
#include <arpa/inet.h>
const char *inet_ntop(int af, const void *src,char *dst, socklen_t size);
前三个参数和inet_pton相同,最后一个参数是目标存储单元的大小,socklen_t类型。
成功返回存储单元的地址,失败返回NULL。
bzero(&servaddr,serlen);
servaddr.sin_family=AF_INET;
servaddr.sin_port=htons(atoi(argv[2]));
inet_pton(AF_INET,argv[1],&servaddr.sin_addr);
read,recv;write,send:
read和write是都可以使用,不是专用于套接字的
recv和send是专用于套接字数据读写的,增加了数据读写的控制。
read,recv返回0表示对端关闭。
recvfrom,sendto:
用于UDP数据的读写,后面两个参数置为NULL和0也可以用于TCP数据读写
前面的四个参数和recv,send的相同,后面的两个参数用来获取和指定对端的地址。
readv,writev:
什么情况下使用readv和writev:
当需要同时发送多块内存的数据时(HTTP应答)
ssize_t readv(int fd,const struct iovec* vector,int count);
ssize_t writev(int fd,const struct iovec* vector,int count);
struct iovec
{
void* iov_base;//多个内存块的起始地址
size_t iov_len;//内存块中要传输的数据字节大小
};
count:是需要发送数据的内存块数量
要建立本结构体的一个数组,因为一个内存块就是一个数组元素。
读取的函数如果是非阻塞的,如果没有数据可读,也会阻塞,直到有数据可读
那么有没有什么办法,让函数自动退出呢,就是设置非阻塞。
对于设置了非阻塞的函数,如果没有数据可读,函数就退出,返回一个错误
套接字的非阻塞读取和函数的非阻塞读取:
套接字非阻塞:
设置套接字为非阻塞,没有数据可读,函数立即返回-1,设置errno=EWOULDBLOCK
非阻塞套接字返回的错误:
Resource temporarily unavailable
资源暂时不可获得
函数的非阻塞:设置函数为非阻塞
recv(fd,buffer,size,MSG_DONTWAIT)
没有数据可读,函数立即返回,设置errno
linux-printf:
unix对于标准输出,并不是直接输出到终端,而是复制数据缓存到缓冲区,当遇到行刷新标志('\n')或者缓冲区已满的情况下,才会把缓冲区的数据输出到终端上,所以linux中printf输出的数据之后要加上'\n'.
fcntl:
对套接字描述符进行控制设置。
关闭非阻塞的操作:
flag&=~O_NONBLOCK;
是与运算
exec族:
所需头文件
#include <unistd.h>
函数原型
int execl(const char *pathname, const char *arg, ...)
int execv(const char *pathname, char *const argv[])
int execle(const char *pathname, const char *arg, ..., char *const envp[])
int execve(const char *pathname, char *const argv[], char *const envp[])
int execlp(const char *filename, const char *arg, ...)
int execvp(const char *filename, char *const argv[])
函数返回值
成功:函数不会返回
出错:返回-1,失败原因记录在error中
① 查找方式:上表其中前4个函数的查找方式都是完整的文件目录路径(pathname),而最后2个函数(也就是以p结尾的两个函数)可以只给出文件名,系统就会自动从环境变量“$PATH”所指出的路径中进行查找。
② 参数传递方式(以特殊字母来记忆):exec函数族的参数传递有两种方式,一种是逐个列举(l)的方式,而另一种则是将所有参数整体构造成指针数组(v)进行传递。
在这里参数传递方式是以函数名的第5位字母来区分的,字母为“l”(list)的表示逐个列举的方式,字母为“v”(vertor)的表示将所有参数整体构造成指针数组传递,然后将该数组的首地址当做参数传给它,数组中的最后一个指针要求是NULL。读者可以观察execl、execle、execlp的语法与execv、execve、execvp的区别。
参数就分三类:路径名还在文件名,参数,
③ 环境变量:exec函数族使用了系统默认的环境变量,也可以传入指定的环境变量。这里以“e”(environment)结尾的两个函数execle、execve就可以在envp[]中指定当前进程所使用的环境变量替换掉该进程继承的所有环境变量。
(3)PATH环境变量说明
PATH环境变量包含了一张目录表,系统通过PATH环境变量定义的路径搜索执行码,PATH环境变量定义时目录之间需用用“:”分隔,以“.”号表示结束。PATH环境变量定义在用户的.profile或.bash_profile中,下面是PATH环境变量定义的样例,此PATH变量指定在“/bin”、“/usr/bin”和当前目录三个目录进行搜索执行码。
PATH=/bin:/usr/bin:.
export $PATH
eg:
char *const ps_argv[] ={"ps", "-o", "pid,ppid,pgrp,session,tpgid,comm", NULL};
char *const ps_envp[] ={"PATH=/bin:/usr/bin", "TERM=console", NULL};//环境变量的指定方式
execl("/bin/ps", "ps", "-o", "pid,ppid,pgrp,session,tpgid,comm", NULL);
execv("/bin/ps", ps_argv);
execle("/bin/ps", "ps", "-o", "pid,ppid,pgrp,session,tpgid,comm", NULL, ps_envp);
execve("/bin/ps", ps_argv, ps_envp);
execlp("ps", "ps", "-o", "pid,ppid,pgrp,session,tpgid,comm", NULL);
execvp("ps", ps_argv);
更多内容请参考原文链接
CGI程序中运用到的:如何在一个进程中打开并执行另外一个一个文件
注意:exec族函数调用新程序的时候并不是创建新的进程,只是进行数据替换,用新程序替换调用的程序(替换的数据包括数据段,代码段,堆段和栈段),进程的ID没有变
获取本端和对端地址:
getsockname(fd,,):
用于获取fd对应的本端地址,获取的地址存于第二个参数中,fd地址长度存放于第三个参数中
getpeername:
获取对端地址,参数意义和getsockname相同。
带外数据(紧急数据):
什么时候需要带外数据:用于设置用于告知对方本端发生的重要事件。
UDP和TCP都没有真正的带外数据,但是TCP也可以设置需要紧急处理的数据,所以也称带外数据。
带外数据有哪些特殊之处:
1,优先级比普通数据高,所以总会被优先处理。
2,带外数据和普通数据会使套接字处于不同的状态:
带外数据:套接字处于异常状态。
普通数据:套接字处于可读状态。
(所以,可以利用I/O复用判别套接字,来处理带外数据和普通数据。)
带外数据怎么设置(发送):只需要将send设置为:MSG_OOB,不用管数据。
带外数据怎么接收:
TCP头部中有一个紧急指针的标志位,linux内核可以检测这个紧急标志位,并通知应用程序,
内核通知应用程序有带外数据到达的两种方式:I/O复用产生的异常事件,SIGURG信号。
最直接的读取方式:
sockatmark:
用于判断套接字中下一个读取的数据是不是带外数据,如果是,返回1,如果不是,返回0.
如果是带外数据,调用recv()的MSG_OOB选项来接收带外数据。
sendfile:
sendfile(int sockfd,int filefd,off_t* offset,size_t count)
直接从filefd指定的文件中offset指定的位置发送count字节的数据给sockfd指定的对端。
这是一个零拷贝函数,所有操作都在内核完成,不需要用户缓冲区和内核缓冲区之间拷贝数据。
splice:
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
也是零拷贝函数,用于两个描述符之间传递数据。
(从哪里来,要到哪里去)
off_in:数据发送端(接收本套接字的数据)
off_out:数据接收端(发送到本套接字)
len:写入数据的长度
flags:控制数据移动方式
注意:
1,fd_in是要读入数据的fd,fd_out是要写出数据的fd。
2,使用splice时,必须至少有一个是管道描述符。
3,如果fd_in和fd_out为管道描述符,对应的off_in,off_out必须为NULL。
4,splice可能返回0,表示管道没有数据移动。
flags:

成功返回移动的字节数据大小,没有数据移动返回0,失败返回-1
mmap,munmap:
mmap将一个文件或者其它对象的数据映射进指定的内存。(通俗一点就是从其他地方指定的位置拷贝数据到本进程指定长度的地址当中)
mmap操作提供了一种机制,让用户程序直接访问设备内存,这种机制,相比较在用户空间和内核空间互相拷贝数据,效率更高。在要求高性能的应用中比较常用。
munmap执行相反的操作,删除特定内存区的对象映射。
#include <sys/mman.h>
void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
int munmap(void *start, size_t length);
start:映射区内存的起始地址,设置为0时表示由系统决定映射区的起始地址。
length:映射区内存的长度。注意,这个不是映射的数据长度。
为什么length=1,也可以映射正文件的内容:
prot:内存区保护标志,不能与文件的打开模式冲突。是以下的某个值,可以通过or运算(“|”)合理地组合在一起
PROT_EXEC //内存区内容可以被执行
PROT_READ //内存区内容可以被读取
PROT_WRITE //内存区可以被写入
PROT_NONE //内存区不可访问
flags:设置内存区的属性。

fd:文件描述符,被映射的文件描述符。
offset:被映射对象内容起始点。
流程:从fd指定的文件的offset位置映射fd中的数据到start的内存中;
注意:mmap返回的地址类型是void*,需要强转。
对mmap返回的地址操作就会映射到内存,实现对内存的操作就是对文件的操作;
memcpy:
memory copy内存(数据)拷贝函数
void *memcpy(void *dest, const void *src, size_t n);
它的功能是从src的开始位置拷贝n个字节的数据到dest。如果dest存在数据,将会被覆盖。memcpy函数的返回值是dest的指针。memcpy函数定义在string.h头文件里。
void main()
{
char arr[10]="aaaaaaaa";
char* str="uiefcb";
memcpy(arr,str,6);
printf("%s\n",arr);
}
输出:uiefcbaa
文件操作类函数:
creat:
int creat(const char *pathname, mode_t mode);
创建文件。
open:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
这两个函数的区别:
第一个是用来打开已经存在的文件的,不需要权限设置。
第二个是用来可能需要创建一个文件是,给新创建的文件设置权限的。
O_RDONLY: 只读打开
O_WRONLY: 只写打开
O_RDWR: 读,写打开
这三个常量,必须制定一个且只能指定一个
O_CREAT: 若文件不存在,则创建它,需要使
用mode选项。来指明新文件的访问权限
O_APPEND: 追加写,如果文件已经有内容,这次打开文件所
写的数据附加到文件的末尾而不覆盖原来的内容
O_TRUNC 若文件存在并且以可写的方式打开时, 此旗标会令文件长度清为0, 而原来存于该文件的资料也会消失.
lseek:
重定位文件指针(光标)在文件中的位置,seek---寻找,定位。
off_t lseek(int fd, off_t offset, int whence);
offset:可正可负
光标的偏移位置是whence指定的位置加上offset的值。
SEEK_SET: 文件开头
SEEK_CUR: 当前位置
SEEK_END: 文件结尾
其中SEEK_SET,SEEK_CUR和SEEK_END和依次为0,1和2.
socket选项和控制函数:
getsockopt:
int getsockopt(int sockfd, int level, int optname, void *optval, socklen_t *optlen);
setsockopt:
int setsockopt(int sockfd, int level, int optname, const void *optval, socklen_t optlen);
参数:
level常用的是:SOL_SOCKET
SO-->socket,L-->level
optval是为选项设置的一个存有变量的值
optlen是以上变量的长度
int reuse=1;
setsockopt(connfd,SOL_SOCKET,SO_REUSEADDR,&reuse,sizeof(reuse));
如何设置TCP发送缓冲区和接收缓冲区的大小:
就是利用setsockopt函数设置:SO_SEDBUF选项和SO_RECVBUF选项。
SO_REUSEADDR:
允许重用本地地址
对于TCP,绝对不可能启动绑定相同IP地址和相同端口号的多个服务器,两个都不行,因为这是完全重复的。但是可以将一个端口号绑定到具有不同IP地址的多个不同套接字上,这就是设置该套接字的SO_REUSEADDR选项。
每一个TCP服务器套接字都应该设置这个选项。
设置这个选项的时候也可以设置允许重用本地地址的套接字的个数:
通过setsockopt第四个参数。
对于UDP可以启动和绑定多个具有相同IP地址和端口号的套接字。
因为UDP套接字和TCP套接字互不相关,所以可以在同一个或者不同程序中开启一个TCP套接字和多个UDP套接字。
在套接字的创建中,servaddr,cliaddr,clilen这些变量在成功创建套接字之后,套接字中就会存有通信双方的信息,所以,这些变量的值发生改变也不会对已经创建的套接字产生影响。所以在利用这些相同变量成功创建一个变量之后还可以用来创建别的变量。
setsockopt应该设置在什么位置:
socket()创建套接字之后---最好socket下面就用setsockopt
bind()绑定套接字之前
SO_LINGER选项
作用:close关闭套接字时,若有数据待发送,可选择延迟关闭
通常close关闭套接字:close只是通知内核需要关闭该套接字,之后close函数立即结束返回。
但是内核没有马上关闭套接字,而是先检查该套接字的发送缓冲区还有没有数据,如果有,则先将缓冲区的数据发送给对端,才关闭套接字连接。如果发送缓冲区没有数据,则立即关闭连接。
设置SO_LINGER选项可以设置指定套接字的关闭状态:
SO_LINGER选项用来设置套接字的对象是一个结构体:
struct linger
{
int l_onoff;//非0--开启该选项,0--关闭该选项,如同没设置
int l_linger;//如果l_onoff不为0,此成员表示close之后需要滞留的时间
};1,l_onoff为0:close使用默认行为关闭套接字
2,l_onoff不为0,l_linger=0:
表示滞留时间为0,即close立即关闭套接字,且不要再发送套接字连接中的数据,立即终止连接。
3,l_onof不为0,l_linger也不为0,套接字为阻塞,那么close之后将滞留指定的时间,如果套接字为非阻塞,close立即返回,
管道:
pipe:
创建半双工管道
pipe创建两个文件描述符存放于数组中
如果两个文件描述符没有设置为非阻塞,则,管道内明天数据,read阻塞,管道没有空间,write阻塞。
int fd[2];
pipe(fd);
fd[1]只能写入数据,管道数据入口。
fd[0]只能读出数据,管道数据出口。
如果需要实现双传输,就需要创建两个管道
socketpair
int socketpair(int domain, int type, int protocol, int sv[2]);
用来创建全双工管道,前三个参数和socket相同,只是需要注意:第一个参数一定要是UNIX本地域协议族——AF_UNIX / AF_LOCAL/PF_UNIX/PF_LOCAL,最后一个就是数组。
重定向:
使用来重定向的函数:
int dup(int oldfd);
int dup2(int oldfd, int newfd);
功能:用来创建一个描述符,该描述符与指定描述符指向相同的对象。
两个函数用来创建一个描述符,该描述符和指定的源描述符指向相同的文件,管道或者网络连接对象。返回的描述符总是取当前系统可用的最小整数值。
dup2和dup的区别就是可以用newfd参数指定新描述符的数值,如果newfd已经打开,则先将其关闭(dup2具有优先权)。如果newfd等于oldfd,则dup2返回newfd, 而不关闭它。dup2函数返回的新文件描述符同样与参数oldfd共享同一文件表项。
STUOUT_FILENO
STDIN_FILENO
STDERR_FILENO
重定向标准输出文件描述符(CGI服务器原理)

此时printf输出就不是到终端了,而是发送给客户端
fcntl()文件重定向:
利用F_DUPFD属性设置套接字:
实际上,调用dup(oldfd)等效于,fcntl(oldfd, F_DUPFD, 0)
而调用dup2(oldfd, newfd)等效于,close(oldfd);fcntl(oldfd, F_DUPFD, newfd);
如何重定向一个描述符:
如果这个描述符已经存在,先关闭描述符,再利用dup或者dup2返回。(先关闭,再返回)
标准输出描述符:STDOUT_FILENO
标准输入描述符:STDIN_FILENO
标准错误描述符:STDERR_FILENO
UDP:
udp套接字不是不连接而是无连接:
TCP是一开始就连接好,整个数据传输的过程连接都存在。
UDP是无连接,发送端指明接收到IP地址和端口号,只是为了指明数据接收端;
接收端暂时保存发送端信息,只是为了要发送数据。
既然UDP无连接,那么recvfrom读取到0表示什么:
UDP中是可以发送和接受长度为0的数据包的,这表示数据报只有UDP首部,没有数据。
服务端:
UDP程序的创建在bind和bind之前和TCP几乎一样,只是在bind之后没有listen和accept.
bind之后就可以写功能函数了。
客户端:
没有connect.
UDP因为没有连接,所以也无需关心对端的关闭套接字的问题
udp客户端套接字什么时候内核分配IP地址和端口号:
当首次调用sendto时。
udp客户端使用connect:
使用connect的udp套接字称为已连接udp套接字
没有使用connect的套接字称为未连接udp套接字
已连接UDP套接字可以向像TCP一样,一次连接,多次发送数据。
1,没有三路握手过程:
2,使用connect之后,服务端的IP地址和端口号就被绑定了,所以我们可以使用read,readv,recv,send,writev,write这些函数发送和读取数据,而使用sendto时无需指定目的地址,使用recvfrom时也无需获取对端的通信信息,因为,connect绑定之后,客户端就只能接收来自connect所绑定的服务端的数据报,其他服务端的都不能接收。(唯一性)
3,已连接套接字引发的异步错误可以返回给套接字所在的进程,而未连接的套接字引发的异步错误不会返回给套接字所在的进程。
异步错误:
某个函数执行过程中引发的错误,整这个错误不随函数返回,而是在函数返回之后才返回
4,当客户端和服务端都需要进行单一对象通信时,都可以使用connect。
5,TCP套接字只能使用一次connect,UDP套接字可以多次connect:
(1):指定新的IP地址和端口号。
(2):断开连接:将sin_family设置为:AF_UNNSPEC。
UDP怎么增加可靠性
TCP为什么可靠----网络工作原理
信号:
信号从哪里来:
由用户,系统,或者进程发送给进程的信息
来了由谁检测接收:
利用信号捕获函数捕获信号,并定义hanshu来处理信号
信号捕获函数:
signal(),sigaction
这两个函数的作用:捕获指定信号,利用函数处理
信号处理的编程过程:
利用信号捕获函数注册信号和信号处理函数--->捕获信号--->处理函数进行处理
进程之间传递信号的函数(kill):
int kill(pid_t pid,int sig);
函数将sig信号传递给ID为pid的进程
sig为0表示不发生信号


信号的类型以及作用:


几个多见,多用的信号:
SIGHUP:
控制终端停止(挂起)
SIGPIPE:
当向一个读端关闭的管道和套接字中写入数据时,系统将会向进程发送SIGPIPE信号
此信号必须捕获并处理,至少忽略,否则进程将终止(管道或者套接字已经关闭)
SIGURG:
当有带外数据(紧急数据)到达时,内核(系统)通知应用程序的方式就是向应用程序发送SIGURG信号
SIGCHILD:
子进程退出或者暂停,操作系统发给父进程的信号
SIGINT:
用户键盘输入ctrl+C中断进程时,系统发送给进程的信号
SIGTERM和SIGTERM:
都是发给指定进程以终止此进程的信号,但是不同的是:
前者可以被阻塞、处理和忽略
但是后者不可以。KILL命令的默认不带参数发送的信号就是SIGTERM.让程序有好的退出。因为它可以被阻塞,所以有的进程不能被结束时,用kill发送后者信号,即可。
SUGPIPE:
当进程向某个已接收了RST(reset---复位)的套接字发送数据时,内核将向该进程发送SIGPIPE信号,该信号的默认行为是终止进程,所以进程需要 捕获此信号进行选择处理
信号处理函数:
两个宏定义用来处理函数:
SIG_IGN-----忽略信号
SIG_DFL-----使用信号的默认m
signal:
sighandler_t signal(int signum, sighandler_t handler);
signum是需要捕获的信号,handler是信号处理函数
第一次调用成功返回默认处理函数SIGDEF的函数指针,之后的返回上一次调用的函数的函数指针
出错返回SIG_ERR,置errno.
signal的本质也是内部调用sigaction:

sigaction:
int sigaction(int sig, const struct sigaction *act, struct sigaction *oldact);
act指针中需要设置信号处理函数,当调用sigaction()时,sig是需要监测的信号,oldact一般设置为NULL就可以
(函数中包含结构体,结构体中包含函数。其实signal简单直接,一个信号,一个函数就可以)
struct sigaction {
void (*sa_handler)(int);//指定信号处理函数,关于这个参数不要传参,直接赋值函数名
void (*sa_sigaction)(int, siginfo_t *, void *);//
sigset_t sa_mask;
int sa_flags;//设定收到信号的处理行为
void (*sa_restorer)(void);//已过时,不使用
};
sa_flag:

使用sigaction函数需要进行的处理是:
建立sigaction结构体,并初始化结构体:
三个主要步骤:
1,指明信号处理函数
2,重启系统调用
3,加入所有信号
信号集:
linux用sigset_t来表示一组信号,sigset_t其实是一个结构体,其成员只有一个长整型数组
对信号的处理函数:
sigfillset():初始化信号集,使之包含所有信号。
signal和sigaction的对比:
| 优点 | |
| signal | 利用简单,内部调用sigaction |
| sigaction | 信号处理函数更健壮的接口 |
定时器容器
两种高效的管理定时器容器:
时间轮和时间堆
什么是定时:
就是在一段指定时间之后触发某段代码多机制
linux提供的三种定时器方法:
1、
拍照
SO_RCVTIMEO
设置套接字接收数据超时时间
SO_SNDTIME
设置套接字发送数据超时时间
套接字选项的设置都是用setsockopt函数,这两个函数也一样,在需要给套接字设置定时的时候,在使用套接字前,利用setsockopt函数设置套接字的定时时间即可。
流量控制:
控制数据流传送速度的方式。
为了解决:接收方从接收缓冲区取数据的速度慢于发送方发送数据的速度
流量控制的方式:
速度流量控制:
给发送方指定一个发送数据速度的速率
窗口流量控制:
窗口:就是可接收数据的大小
接收方利用窗口告知发送方自己可以提供多大的缓冲区
通告窗口和拥塞窗口
本端的窗口
什么时候使用UDP,而不用TCP:
1,因为UDP支持多播和广播,所以,使用多播和广播时就必须使用UDP。
2,UDP适用于传送少量数据,当需要传送海量数据时,应该用TCP。
怎么提高UDP的可靠性:
1,设置超时和重传:用于处理丢失的数据报。
2,设置序列号:供客户检验一个应答是否匹配相应的请求。
非阻塞I/O:
非阻塞connect的连接过程:
对于主机和目的主机是同一台主机的,connect可能会立即连接成功并返回0.
但是,大多实际应用中,当套接字调用非阻塞的connect的时候,connect会返回EINPROGRESS的错误,但是三路握手继续进行。
非阻塞connect的返回值:
1,0:表示connect立即连接成功,表明源主机和目的主机都是一个主机。
2,-1:立即错误返回。
进程:
正在运行的程序。
进程的创建:
pid_t fork();//这是Linux下创建进程的唯一方式
当创建进程时,都会在内核表项中为每一个进程创建一个进程表项
子进程需要复制两样东西:
1,父进程的代码------完全复制
2,数据------------------写时复制,即进程执行写操作时才会复制数据。
进程创建的实质:
数据是否共享
哪些数据共享
子进程和父进程有哪些地方相同
子进程和父进程有哪些差别
信号处理:
对终止子进程保留的信息进行释放
什么是僵尸进程:
当子进程比父进程先结束,但是父进程并没有回收子进程,并释放子进程占用的资源,此时子进程的状态就称为僵尸进程。(就是那些已经终止,但是还没被回收的进程)
(已经终止,但是依然存在)
设置僵尸进程的作用:
保留子进程的部分进程信息,以便父进程在以后某个时刻获取。
僵尸进程的危害:
如果父进程不调用wait或者waitpid来释放终止子进程的信息,那么子进程保留下来的资源就不会被释放,占用内存空间,子进程的进程号会被这个变为僵尸进程的进程占用,如果僵尸进程太多,就会导致新进程因为不能获得进程号而不能产生,而且僵尸进程占用内存空间,可能会导致耗尽进程资源。
wait和waitpid:
函数的作用:
在父进程中调用
wait:等待所有终止的子进程。不能控制阻塞状态。当没有进程终止时,调用者将阻塞。
wait因为没有办法防止其阻塞,所以不能循环调用,否则,调用者将在wait处永远循环,永远阻塞。
pid_t wait(int *status)
pid_t waitpid(pid_t pid, int *status, int options);
参数:
两个函数的status都是用来保存子进程终止状态的整型指针
pid是指定需要等待的子进程的id号,pid为-1表示等待任意子进程终止
options是函数选项,最常用的是WNOHANG,告诉内核指定进程没有终止,或者没有进程终止时不要阻塞,立即返回,这就不会导致进程阻塞
waitpid的一般运用形式:
while(pid=waitpid(-1,&state,WNOHANG)>0)
{
//Getting in is successful,continue
cout<<"pid="<<pid<<" process terminate."<<endl;
continue;//获取终止的子进程,则继续等待,否则退出
}
进程间通信方式:
1,最简单:管道
//管道只能用于有关联的进程(父子进程,兄弟进程)之间的通信
//下面三种方式可以在多个无关进程之间通信
2,消息队列
什么是消息队列:
消息---就是数据
队列---是一种先进先出的数据结构
先进先出(队列):

先进后出(栈):
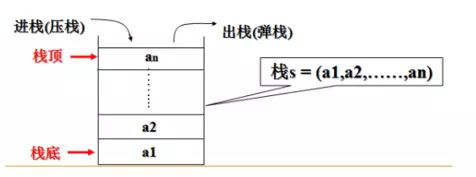
所以消息队列:就是存储消息(数据)的队列
生产者---将数据放入队列中
消费者---从队列中取走数据
作用:
作为中间件(不直接传递数据,而是间接的传递数据)
1、解耦
假设有A、B两个业务接口,A调用B,但是某天B业务接口用不了了,A需要调用其他业务的接口,那么这时A的代码需要做修改,又又过了几天,B接口又可以用了,A又需要调用B的接口或是其他接口都需要A去调用,这时A业务的代码又改改改,A直接爆炸说不干了。。
这时候消息队列就派上用场了,在A业务和其他业务之间引入消息队列,A的调用可以写到消息队列中去,然后其他业务作为消费者去消费消息队列中的消息就可以了。A终于再也不用去改代码了。这就是解耦的好处。

2,削锋
什么削锋,一点也不好理解
比如,系统每秒只可以处理一万个数据,但是突然某个时刻数据超过一万个,这就需要利用消息队列将多的数据存储在队列里,等待处理。
创建或者获取一个消息队列--msgget:
int msgget(key_t key, int msgflg);
参数:
key:需要创建或者获取到消息队列的标识
msgflg:有两个选项
IPC_CREAT :如果消息队列对象不存在,则创建之,否则则进行打开操作;
IPC_EXCL:和IPC_CREAT 一起使用(用”|”连接),如果消息对象不存在则创建之,否 则产生一个错误并返回。
成功返回一个消息列队的标识符,失败返回-1,值errno.
将消息(数据)存入消息列队--msgsnd:
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg);
参数:
msqid:msgget返回的消息列队标识符
msgp:指向需要发送的消息数据的地址
消息必须被定义为如下类型:
struct msgbuf {
long mtype; /* message type, must be > 0 */
char mtext[512]; /* message data */
};
msgsz:消息数据的长度
msgflg:

msgflg 为0表示阻塞方式,设置IPC_NOWAIT 表示非阻塞方式
函数成功返回0,失败返回-1,置errno.
从消息队列获取数据--msgrcv:
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp,int msgflg);
其他参数和msgsnd相同。
msgtyp:
0:接收第一个消息
>0:接收类型等于msgtyp的第一个消息
<0:接收类型等于或者小于msgtyp绝对值的第一个消息
函数成功返回0,失败返回-1,置errno.
消息队列的控制函数--msgctl:
int msgctl(int msqid, int cmd, struct msqid_ds *buf);
参数:
cmd:


buf:
struct msqid_ds {
struct ipc_perm msg_perm; /* Ownership and permissions */
time_t msg_stime; /* Time of last msgsnd(2) */
time_t msg_rtime; /* Time of last msgrcv(2) */
time_t msg_ctime; /* Time of last change */
unsigned long __msg_cbytes; /* Current number of bytes in
queue (nonstandard) */
msgqnum_t msg_qnum; /* Current number of messages
in queue */
msglen_t msg_qbytes; /* Maximum number of bytes
allowed in queue */
pid_t msg_lspid; /* PID of last msgsnd(2) */
pid_t msg_lrpid; /* PID of last msgrcv(2) */
};
3,共享内存
1)创建和使用共享内存的第一种方法
共享内存的创建/获取--shmget:
int shmget(key_t key, size_t size, int shmflg);
参数:
key用来标识共享内存段的
size指定共享内存段的大小,单位为字节
如果是创建新的共享内存,size必须不为0,如果是获取已经存在的共享内存,size为0.
shmflg是用来对共享内存做一些额外操作的

共享内存和进程的关联--shmat:
虽然是共享内存,但是不是每一个进程都可以随便访问。
每一个进程需要访问共享内存都需要将共享内存和本进程的进程地址建立关联
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数:
shmid是shmget返回的共享内存的标识符
shmaddr指定共享内存关联到进程的哪一块地址空间
shmflg指定进程和共享内存的一些关系:


进程释放取消和共享内存的关联--shmdt:
当进程使用完共享内存,需要取消和共享内存的关联
int shmdt(const void *shmaddr);
参数就是上一个函数指定的进程的地址
对共享内存的一些操作--shmctl:
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数:
cmd:指定要执行的命令

buf:
struct shmid_ds {
struct ipc_perm shm_perm; /* Ownership and permissions */
size_t shm_segsz; /* Size of segment (bytes) */
time_t shm_atime; /* Last attach time */
time_t shm_dtime; /* Last detach time */
time_t shm_ctime; /* Last change time */
pid_t shm_cpid; /* PID of creator */
pid_t shm_lpid; /* PID of last shmat(2)/shmdt(2) */
shmatt_t shm_nattch; /* No. of current attaches */
...
};
2)创建和使用共享内存的第二种方法:
创建共享内存--shm_open:
int shm_open(const char *name, int oflag, mode_t mode);
功能:创建或者打开共享内存文件(注意:不是共享内存)。
参数:
name 需要创建或者打开的共享内存文件名
oflag

mode和open函数的最后一个参数一样,标识要创建的文件的访问权限

返回值,函数打开或者创建成功返回一个文件描述符,失败返回-1,置errno.
进程和共享内存文件建立关联--mmap:
如同第一种方式一样,建立的共享内存需要和进程建立关联,进程才可以访问
void *mmap(void *addr, size_t length, int prot, int flags,int fd, off_t offset);
这里用mmap函数来将共享内存文件和进程关联,关于mmap请翻本博文之前的内容
取消进程和共享内存文件的关联--munmap:
int munmap(void *start, size_t length);
销毁共享内存--shm_unlink:
int shm_unlink(const char *name);
和open函数关闭一个文件描述符一样,共享内存文件也需要销毁,即释放共享内存文件所占是资源。但是不同的是,shm_unlink不是用描述符销毁,而是直接用文件名。
使用了POSIX共享内存函数,编译时需要指定链接选项:-lrt
Link with -lrt.
进程同步方式:
1,信号量(IPC)
(注意:linux下有两种信号量,下面讲的是IPC--进程间通信使用的信号量,另外一种信号量是POSIX信号量,这两种信号量不能保证互换)在此为了自己学习好记,命名这种信号量为---进程信号量
什么是信号量:
信号量是一个特殊的变量,程序对其访问都是原子操作,且只允许对它进行等待(即P(信号变量))和发送(即V(信号变量))信息操作。最简单的信号量是只能取0和1的变量,这也是信号量最常见的一种形式,叫做二进制信号量。而可以取多个正整数的信号量被称为通用信号量。这里主要讨论二进制信号量。
什么是临界区:
进程和其他进程产生竞态条件的代码段
所谓的进程同步就是保证任意时刻只有一个进程在运行临界区代码
用来干什么:
用来同步进程对资源的唯一访问
怎么用(信号量同步原理):

(进程所谓的能否执行关键代码段,就是获取的信号量的值是否不为0,如果不为0,就继续执行代码,如果获取的信号量的值为0,那进程就阻塞,一直到其他进程让信号量的值变为非0。)
一个进程对信号量有两种操作:p(加1,或者等待),v(减1)
P:进程获取信号量,即进入P操作,通过函数semop()要求对信号量减1,先检测信号量的值是否为0,不为0,就减1,如果信号量的值为0,进程就阻塞到其他进程释放信号量使信号量的值变为大于0.,然后此进程对信号量减1,之后进程继续执行代码。当关键代码段执行完了之后,再次调用semop()函数对信号量进行V操作,即让信号量的值加1,释放信号量。
信号量的三个函数:
semget:
int semget(key_t key, int nsems, int semflg);
用于创建一个新的信号量集,或者获取一个新的信号量集
nsems为0,表示要获取已经存在信号量集
nsems不为0,表示要创建nsems个信号量
参数:
key:是唯一表示一个信号量集的整数,俗称键值,为什么要唯一标识一个信号量集,一位,不同进程之间需要使用这个唯一的键值来创建或者获取信号量,才能实现进程之间的同步。
一个特殊键值---IPC_PRIVATE(private),其值为0,可以直接用0代替,使用这个键值无论信号量是否存在,semget都会创建一个新的信号量,这个信号量并不同其名字是私有的,其他进程也可以使用
semflg:指定信号量的权限,设定依据如下表:
这个参数可以和IPC_CREAT和IPC_EXCL进行按位或运算,创建一个新的,唯一的信号量集,如果信号量已经存在,返回错误。
函数成功返回信号量集标识符---一个整数
失败返回-1,置errno.
之后的信号处理函数需要使用这个标识符
semop:
int semop(int semid, struct sembuf *sops, size_t nsops);
参数:
semid是semget函数返回的信号集标识符
sops是sembuf类型的结构体对象或者数组
nsops是第二个参数数组的元素个数,如果只是一个对象,那nsop=1.
sembuf结构体:
struct sembuf{
unsigned short sem_num; /* semaphore number *///信号量的编号,0表示第一个信号量
short sem_op; /* semaphore operation *///指定操作类型,等待,加1,或者减1,就是0/-1/1
short sem_flg; /* operation flags */
};
sem_op:
大于0:将操作的信号量的值加1
(内核中有一个信号量的变量---unsigned short semval,表示信号量的值)
等于0:表示进程需要等待此信号量值变为0,如果信号量值为0,函数立即返回,否则返回错误或者阻塞到信号量的值为0
小于0:表示进程需要获取此信号量,对信号量进行减操作。
sem_flg有两个选项:IPC_NOWAIT,SEM_UNDO
IPC_NOWAIT:无论信号量操作是否成功,semop立即返回
SEM_UNDO:当进程退出时,取消正在进行的semop操作
semop函数的作用:
用来执行pv操作,即对信号量进行等待,减1,或者加1
semop()怎么使用:
第一个参数为信号量集标识符
配置sembuf对象的三个成员
给出nsops
然后调用semop就可以。
semctl:
int semctl(int semid, int semnum, int cmd, ...);
参数:
semid信号机标识符
semnum:信号量在信号集中的编号
cmd:操作的命令
命令选项 :
注意:使用semctl对信号量的值进程设定时,不要直接给一个值,而是要建立semun共用体对象,给对象中的成员赋值,利用这个对象给信号量赋值。
union semun {
int val; /* Value for SETVAL */
struct semid_ds *buf; /* Buffer for IPC_STAT, IPC_SET */
unsigned short *array; /* Array for GETALL, SETALL */
struct seminfo *__buf; /* Buffer for IPC_INFO
(Linux-specific) */
};
注意,这个共用体如果没有,需要自己定义。
信号量的使用过程:
1,semget:创建信号量
2,semctl:初始化信号量,即设置信号量的初值
3,进程通过semop()函数来获取信号量,对信号量进行PV操作。
信号量最后总结就是进程通过函数对信号量进行锁定和释放的过程
注意:信号量是用来进程间同步的,所以信号量必须在父进程没有创建之前创建信号量,如果在每一个进程都创建信号量,那就不能同步了
2,互斥锁和条件变量可以用来进程通信吗
首先,互斥锁和条件变量,都是变量,只要是在线程或者进程之间是共享的,就可以用来同步线程或者进程。
线程的创建和管理
线程
内核线程:
运行在内核空间,由内核调度
用户线程:
运行在用户空间,由线程库调度,(不是用户调度)
线程和进程的并发,实质都是快速切换。
创建线程:
int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine) (void *), void *arg);
参数:
thread:新线程的标识符,之后的函数可以通过这个标识符引用这个新线程
attr:用于设置新线程的属性,为NULL时使用线程的默认属性。
第三个参数:为线程使用的函数,即线程的起始地址
由参数可知:线程使用的函数应该定义为:返回类型为void*,参数为void *,且只有一个参数。
第四个参数:函数的参数
需要传多个参数怎么办----将参数放在结构体中,传递结构体。
线程退出:
pthread_exit(void* ret)
安全,干净的退出。
ret参数用来向线程的回收者传递本线程退出的信息
注意:线程的退出并不是像子函数一样回到线程开始的起点
exit是进程终止函数,调用将使所有线程终止
本线程暂停,回收其他线程:
int pthread_join(pthread_t thread, void **retval);
参数:
thread:要等待的线程的标识符,
retval:用于接收目标线程退出的信息
函数成功返回0,失败返回以下错误码:

int pthread_detach(thread_t id)
当一个线程终止时,如果不用pthread_detach设置为脱离的,则其线程ID和退出信息一直保存到其他线程调用pthread_join()获取它,或者进程终止。
pthread_detach就是让线程终止时,释放所有资源。
别等了,放心去吧
成功返回0
取消指定的线程:
int pthread_cancel(pthread_t thread);
让线程异常终止
pthread_self():
获取线程自己的ID号
线程的同步:
就是要求线程可以按排队获取资源或者执行
线程同步的方法:
pthread_join可以等待一个线程执行完,再执行下一个线程,都是这样效率太低
1,信号量(POSIX)
(注意:linux下有两种信号量,下面讲的是IPC--进程间通信使用的信号量,另外一种信号量是POSIX信号量,这两种信号量不能保证互换)线程信号量
信号量的函数和使用过程
1)定义一个信号量(变量):sem_t sem;
2)初始化该信号量:
int sem_init(sem_t *sem, int pshared, unsigned int value);
参数:
pshared:这个参数很重要,因为这个参数的值决定这个信号量是单一进程使用的信号量,即线程之间使用的信号量,还是可以在不同进程之间使用。
为0:单一进程,不同线程之间使用
不为0:进程之间使用
所以线程使用之间设置为0
value:设置信号量的初始值
注意:信号量是通过这个初始化函数赋值,而不是通过用户直接赋值给信号量
3)启动信号量
int sem_post(sem_t *sem);
以原子操作的方式将信号量的值加1
如果是连续性的将信号量的值加1,那么信号量的值将连续的往上加1.。
4)获取信号量(实质是将信号量的值减1)
int sem_wait(sem_t *sem);//阻塞获取
int sem_trywait(sem_t *sem);//非阻塞,函数立即返回-1,errno=EAGAIN
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);//设定获取时限
5)销毁信号量
int sem_destroy(sem_t *sem);
上面信号量的函数,处了初始化,使用到信号量的地方都是使用信号量的地址
信号量的函数成功都返回0
2,互斥锁(互斥量)
建立一个互斥锁对象--pthread_mutex_t:
静态初始化互斥量--PTHREAD_MUTEX_INITIALIZER
动态初始化互斥量--pthread_mutex_init:
int pthread_mutex_init(pthread_mutex_t *mutex,const pthread_mutexattr_t *attr);
第二个是需要初始化的互斥锁的属性,一般为NULL,表示使用默认属性
上锁--pthread_mutex_lock:
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_trylock(pthread_mutex_t *mutex);
//pthread_mutex_lock的非阻塞版本
// 调用该函数时,若互斥锁未加锁,则上锁,返回 0;
// 若互斥锁已加锁,则函数直接返回失败,即 EBUSY。
加锁时限函数--pthread_mutex_timedlock:
int pthread_mutex_timedlock(pthread_mutex_t mutex, const struct timespec *tsptr);
和pthread_mutex_lock功能相同,只是限定等待对互斥锁加锁的时限,如果指定时间内成功加锁,返回0,如果超过指定时间没有能加锁,就返回错误编码
struct timespec {
time_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
};
关于时间获取以及设置
释放互斥锁--pthread_mutex_unlock:
int pthread_mutex_unlock(pthread_mutex_t *mutex);
销毁互斥锁--pthread_mutex_destroy:
int pthread_mutex_destroy(pthread_mutex_t *mutex);
互斥锁的使用,所用参数都是指针
死锁:
原因:
面试:
线程和进程在利用互斥锁的时候陷入的一种僵局状态。
1,同一个线程对同一个互斥量连续加锁,进入自锁状态。
2,线程僵持状态
比如:两个线程,线程A锁住互斥锁1,等待互斥锁2,线程B锁住互斥锁2,等待互斥锁1.
死锁危害:
1,线程无法进行下去
2,线程占据的资源无法释放
避免死锁的方法:
1,加锁顺序:保证每一个线程加锁顺序一样
2,加锁时限:
利用pthread_mutex_timedlock函数进行加锁时限设置
3,利用pthread_mutex_trylock(pthread_t* m_mutex)对互斥锁进行加锁,如果互斥锁没有被锁,这个函数就会对互斥锁上锁,如果已经被锁住,则函数也不会阻塞,而是失败返回。
3,条件变量
说说什么是条件变量:
条件变量和互斥锁都是变量
条件变量的类型:pthread_cond_t
条件变量的静态初始化:
PTHREAD_COND_INITIALIZER
条件变量的动态初始化:
pthread_cond_init(pthread_cond_t* cond,pthread_condattr*cond_attr)
同互斥锁,第二个参数为条件变量的属性,使用NULL,表示使用默认属性
互斥锁需要上锁,那么条件变量要怎么办呢:
互斥锁是用来实现线程同步的,而条件变量是线程等待资源条件满足被唤醒的一种方式
条件变量只需要等待某一个资源条件满足,然后利用此条件变量唤醒等待此条件变量的线程
等待条件变量:
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex)
这个是无条件等待条件变量
条件变量是需要互斥量来保护的,线程在使用和改变条件变量之前必须先锁住互斥锁
为什么:
如果不使用互斥锁,那么可能会产生多个线程同时修改一个条件变量的情况
int pthread_cond_timedwait(pthread_cond_t *cond, pthread_mutex_t *mutex, const struct timespec *abstime)
这个是计时等待
如果超时条件还没有满足,此函数将从新获取条件变量,返回ETIMEOUT。
wait函数的过程:
wait函数通知内核将线程放入等待条件变量的等待列队,然后释放此互斥量,当这个线程被唤醒时,wait再将互斥量上锁
wait函数是先释放锁,被唤醒再加锁,所以被释放之前得先对互斥锁上锁,当wait返回并执行完成之后也要解锁。
所以:
有互斥锁不一定有条件变量
有条件变量一定有互斥锁
条件变量的使用过程:
先上锁---->再wait----->再解锁
唤醒等待条件变量的线程:
int pthread_cond_signal(pthread_cond_t* cond)
唤醒等待此条件变量的一个线程
int pthread_cond_broadcast(pthread_cond_t* cond)
唤醒等待此条件变量的所有线程
那么什么时候唤醒线程呢:
这就取决于程序设计者自己编写的程序了,只要当程序的某一个资源满足时,利用条件变量
和这个这两个函数中的一个唤醒线程即可。
销毁一个条件变量:
pthread_cond_destroy(pthread_cond_t* cond)
试图销毁一个正在等待的条件变量将失败,并返回EBUSY。
信号量和条件变量的区别
1,信号量通过改变值的形式让线程继续执行,而条件变量通过接口函数唤醒线程。
2,
信号量不需要互斥锁的原因:
因为信号量的值是非负数的值,只要信号量的值不为0,那么就可以唤醒多个那么每个线程利用一次信号量就将信号量值减一,直到信号量的值为0,线程阻塞。
条件变量需要互斥锁的原因:
条件变量没有这种控制机制,条件变量要么唤醒一个线程,要么唤醒所有线程,所以需要互斥锁来控制单一线程的唤醒。
条件变量的互斥锁的两次上锁和解锁过程
先上锁再解锁,再等待条件变量唤醒,唤醒之后再上锁,完成功能之后再解锁
4,读写锁
5,自旋锁
进程池和线程池
动态创建进程和线程
在程序运行的过程中,什么时候需要,什么时候才建立
动态创建子进程的缺点
1、创建耗时,客户响应慢
2,动态创建的进程或者线程通常只为一个客户连接使用,如果客户连接多,会导致系统上创建的进程或者线程很多,进程或者线程之间的切换也会消耗很多CPU时间。
进程池的创建
进程池的特点
进程池中所有子进程都运行相同的代码,具有相同的属性
子进程的创建
1,将子进程所拥有的数据和信息利用类包装起来
子进程的类所具有的信息:
1),用于保存本进程ID号的pid_t的变量
2),子进程和父进程如何通信----管道
每一个子进程都要有属于自己的和父进程的通信管道
2,利用new便可以创建子进程类的数组
注意:New出来的只是一个类数组,不是进程池
3,利用fork循环创建子进程,并保存ID号
4,利用循环和创建管道的函数创建每一个子进程的管道
5,利用子进程
不要说成启动子进程,因为进程一旦创建,它就是一直在运行的。
父进程只需要通过管道给指定的子进程发送消息即可
6,子进程和父进程代码模块
子进程和父进程具有相同的代码,所以在父进程中就要写好子进程和父进程的的代码块,然后通过某个变量在子进程中和父进程中的值不同判断当前所在是子进程还是父进程,然后执行属于自己的代码块。
父进程给子进程分配任务:
(1,寻找空闲的子进程来执行任务
//所以要有一个共享的变量来标志子进程的工作状态:忙碌/空闲)
上面的这句话是有问题的,因为无论是进程还是线程,只要被创建,都是处于运行的状态,即忙碌的状态,直到停止运行,
2,当所有子进程都忙碌时(只要是还在运行的进程,就都是忙碌的)
只能循坏给还在运行的子进程分配任务,除非,必须指定这个任务要分配给哪一个子进程
进程池中的信号处理:
信号的处理对象可能是父进程,也可能是所有进程,或许可能是子进程,所以不是所有信号都需要发送给子进程处理。根据不同的信号要求,决定是传给子进程处理,还是不传。
管道只要在子进程和父进程代码相同的模块创建,虽然子进程和父进程中都有一份管道的数据,但是管道的描述符是相同的,都是同一个管道的描述符,那么就可以利用描述符在不同进程之间通过管道传输数据。
父进程没有必要利用管道给子进程发送信号,而是利用信号发送函数直接发送信号,在子进程中再通过信号检测函数就可以接收到信号
信号本身是一个int类型,但是数据的发送传输都是以字符的形式传输,所以如果需要传输信号,就需要将信号转为字符,再传输。因为char和int可以相互转换(利用ASCLL码),所以在接收端再转会int类型即可,或者不用转,因为接收到的一个字节就是一个字符信号,直接利用接收到的字符和信号进行比较。
void sig_handler(int sig)
{
int msg=sig;
send(sig_pipefd[1],(char*)&msg,1,0);
}
先将msg的地址转为char类型,再发送这个地址中的数据。
套接字的连接和套接字的数据的读取:
父进程监听到有连接,通过管道给子进程发送某个数据或者信号(这个数据或者信号用来提醒子进程进行连接),子进程接收到这个数据就进行连接,并把这个连接好的套接字在本进程注册,这个套接字的数据读取和操作也在本进程。
对于进程中关闭了连接的套接字的处理:
1,首先要清除利用套接字来处理数据的进程有没有和套接字绑定在一起(也就是关闭套接字,进程依然可以再次使用),如果没有绑定,就清除套接字的数据,然后关闭套接字即可。
对已经终止的子进程的处理:
在父进程中需要对一些和此子进程有关的数据进行清理或者关闭或者重置:
1,管道
2,将该子进程的数据(变量,函数等)还原到未使用的状态
方法:
1):如果子进程中的数据很多,而且子进程的数据是被分装在类中的,直接建立一个初始状态的类对象,用来对终止的子进程的数据赋值,就还原了
2):如果子进程的数据不是很多,可以用代码一个一个地还原
父进程终止退出:
一个很方便的方式,当所有子进程都没有事做,而父进程需要退出的方式:
定义一个变量,赋值为true,当检测所有子进程终止时,赋值为false.
子进程也不要一个一个检测结束没有,而是应该检测,只要有一个没有结束,就让父进程继续运行
有什么办法可以确保一个客户连接在整个生命周期内仅被一个线程或者进程处理:
EPOLLONESHHOT
统一事件源
所谓统一就是将接收到的信号通过设置的管道发送给I/O复用函数,通过I/O复用函数检测出来进行处理,因为利用将接收的信号和其他需要接收的数据一起都是通过I/O复用函数一起统一检测和处理的,所以称为统一事件源
统一事件源处理过程:
1,建立管道---》2,注册需要检测的信号---》3,检测到信号,通过信号处理函数发送给I/O复用函数检测和处理
进程池的销毁
同一个变量在子进程和父进程中具有的值互不相关
同一个变量在不同进程中的值的改变也互不相关
线程池的创建和利用过程(线程池的封装):
(半同步/半反应堆模式:)
准备工作:
创建一个线程标识符数组:
创建一个pthread_t*的数组,即线程标识符的数组
同步线程获取数据的来源:
这里用list容器创建队列为列,list容器中保存的元素是封装好的 工作对象
创建线程
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine) (void *), void *arg);
Compile and link with -pthread.
注意:在C++中使用pthread_create时第三个参数必须是一个静态函数,否则报错:
invalid use of non-static member function
构造函数中实现循环创建线程,pthread_create()获取线程标识符保存于数组中
为什么要在构造函数中创建线程池;
因为需要创建好,直接利用的,所以需要以来就要创建好。
其实,线程池的创建很简单,就是new一个pthread_t的数组,再循环pthread_create()就完了。
比较复杂的是后面对线程池功能的设计。
在创建的过程中,需要进行检测,如果创建出问题,需要销毁创建的数据,退出:
if(pthread_create(m_thread+i,NULL,worker,this)!=0)
{
cout<<"Create thread "<<i<<"error"<<endl;
delete [] m_thread;
throw std::exception();
}
if(pthread_detach(m_thread+i))
{
delete [] m_thread;
throw std::exception();
}
创建函数用来向工作队列添加元素(使用这线程池的对象):
向工作队列中添加元素,并让(让信号量的值加1)线程来获取元素。
线程函数
线程函数可以通过一些同步机制来相继获得队列(list为列)数据,然后开始执行封装好的对象的入口函数,去执行对象的功能。
这里以信号量为列。
当每次向队列中增加一个元素,就让信号量的值加一。
之后通过循环检测信号量的值来检测队列中是否有需要处理的任务,如果有就从队列中取出这个对象(元素),执行这个对象的入口函数去执行其他功能。(从队列中取出一个元素,就删除一个元素)
三大类并发模型
并发模型可分为多进程模型、多线程模型和事件驱动模型三大类:
多进程模型
每接受一个连接就fork一个子进程,在该子进程中处理该连接的请求
特点是多进程占用系统资源多,进程切换的系统开销大,Linux下最大进程数有限制,不利于处理大并发
多线程模型
每接受一个连接就create一个子线程,利用子线程处理这个连接的请求
Linux下有最大线程数限制(进程虚拟地址空间有限),进程频繁创建和销毁造成系统开销,同样不利于处理大并发
事件驱动模型
Linux下基于select、poll或epoll实现
程序的基本结构是一个事件循环结合非阻塞IO,以事件驱动和事件回调的方式实现业务逻辑,目前在高性能的网络程序中,使用得最广泛的就是这种并发模型
结合线程池,避免线程频繁创建和销毁的开销,能很好地处理高并发
两种事件处理模式:
Reactor:
主线程只负责监听,由子线程进行数据读取,发送等数据处理。
Proactor:
数据的读和写在主线程中完成,主线程读取完数据唤醒子线程对读取的客户数据进行处理
作用:刚开始学习的时候可能意识不到这两种事件处理模式的重要性,想想一下当你编写一个服务器程序时,读取客户数据之后的代码应该怎么写,这个时候就要选择这两种模式中的一种继续写下面的代码。
两种高效的并发模式:
1,半同步/半异步模式:
这里同步和异步和I/O的同步和异步不同。
同步:程序完全按照代码的顺序,顺序的执行
异步:在进程执行的过程中,进程会被中断去处理其他事件,处理完成再返回原处继续执行。

按同步方式运行的叫同步线程
按异步方式运行的叫异步进程
异步线程用于处理I/O事件(数据的读和写),同步线程用于处理异步线程处理得到的客户请求数据
半同步/半反应堆模式(一对一模式):
采用reactor事件处理模式
主线负责监听,连接套接字,并往自己的epoll内核事件表中注册该socket
当有已连接的socket上有数据需要读取或者需要发送数据时,将该socket加入请求队列中
所有的工作线程 ,工作线程通过竞争()的方式随机获取这个套接字。
子线程没有自己的套接字,需要抢----与半同步半异步的区别
(工作线程没有I/O复用,一次只能接收和处理一个socket)

这种模式有一个大缺点:(工作线程不够用)
每一个线程同一时间只能处理一个客户请求,如果客户端较多,而工作线程较少,那么请求队列中将堆积很多的客户请求,客户端的响应速度将变慢。但是如果增加工作线程,将不仅耗费更多的系统资源,大量的工作线程之间的切换也将花费大量CPU时间。
半同步/半异步模式(一对多模式):
这种模式可以解决半同步/半异步模式‘工作线程不够用’的缺点
主线程只需要监听套接字(使用I/O复用)
当有套接字请求连接到来时,主线程通过管道的方式选定某一个工作进行套接字连接,这个工作线程中也利用I/O复用(如epoll)将自己连接好的套接字注册在自己的epoll事件表中,以后这个已连接的所有数据的处理都由这个工作线程来完成。这样,一个工作线程就可以处理多个客户请求。
(工作线程有I/O复用,一个工作线程可以处理多个客户请求)
子线程利用epoll注册套接字:这个套接字以后就是我的了,他的事情由我来负责。

2,领导 者追随者模式:
领导者/追随者模式是多个工作线程轮流获得事件源集合,轮流监听、分发并处理事件的一种模式。在任意时间点,程序都仅有一个领导者线程,它负责监听V0事件。而其他线程则都是追随者,它们休眠在线程泄中等待成为新的领导者。当前的领导者如果检测到10事件,首先要从线程池中推选出新的领导者线程,然后处理10事件。此时,新的领导者等待新的10事件,而原来的领导者则处理10事件,二者实现了并发。
由于领导者线程自己监听10事件并处理客户请求,个因而领导者/追随者模式不需要在线程之间传递任何额外的数据,迪无须像半同步/半反应堆模式那样在线程之间同步对请求队列的访问。但领导者/追随者的一个明显缺点是仅支持一个事件源集合,因此也无法像图8-11所示的那样,让每个工作线程独立地管理多个客户连接。
一些常规标识:
IPC:
Inter-Process Communication
进程间通信
POSIX:
POSIX表示可移植操作系统接口(函数)(Portable Operating System Interface of UNIX,缩写为 POSIX )
就是一种标准,为了编写的代码可以的不同操作系统上编译和运训
当写一个比较大的项目时,一定要制作清晰的架构出来。















 1089
1089











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









