







Abstract
由于大规模模型的端到端训练,视觉与语言预训练的成本变得越来越高昂。本文提出了BLIP-2,一种通用且高效的预训练策略,它通过冻结预训练图像编码器和冻结的大型语言模型去启动vision-language pre-training。BLIP-2通过一个轻量级 Querying Transformer 来桥接模态差距,该 Transformer 在两个阶段进行预训练。
第一阶段从冻结的图像编码器中启动视觉语言表征学习。第二阶段从冻结的语言模型中启动视觉到语言的生成式学习。尽管BLIP-2的可训练参数比现有方法少得多,但它仍在各种视觉语言任务上取得了sota的性能。例如,BLIP2在零样本VQAv2上的表现比Flamingo80B高出8.7%,同时可训练参数减少了54倍。本文还展示了模型涌现的零样本图像到文本生成能力,能够遵循自然语言指令。
Introduction
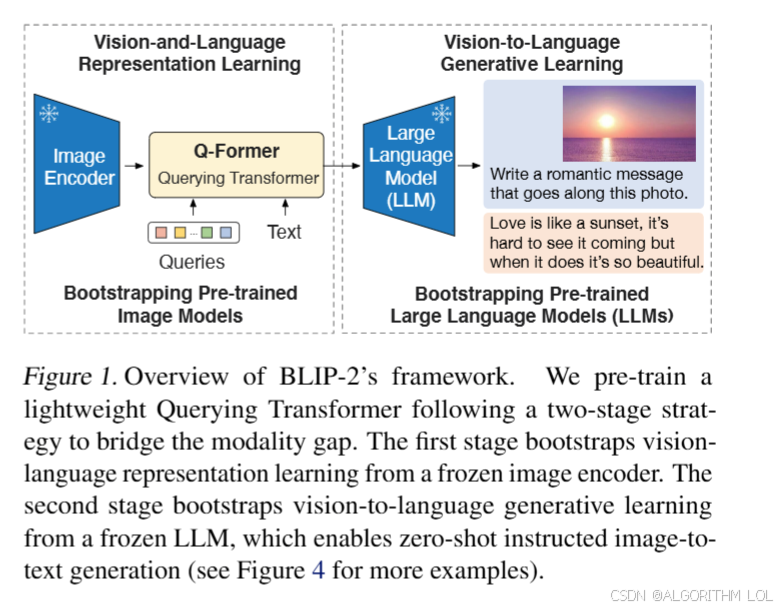
提出了一种通用的、计算效率高的VLP(视觉语言联合预测)方法,通过从现成的预训练视觉模型和语言模型中进行引导学习。
为了降低计算成本和抵消灾难性遗忘的问题,单模态预训练模型在预训练期间保持冻结状态。为了利用预训练的单模态模型进行VLP,关键是要促进跨模态对齐。然而,由于LLMs在其单模态预训练期间没有看到图像,冻结它们使得视觉语言的对齐变得具有挑战性。
为了在冻结的单模态模型上实现有效的视觉语言对齐,作者提出了一个Querying Transformer(Q-Former),该Transformer采用了一种新的两阶段预训练策略。如图 1 所示,Q-Former是一个轻量级Transformer,它使用一组可学习的Query向量从冻结的图像编码器中提取视觉特征。它在冻结的图像编码器和冻结的LLM之间充当信息bottleneck,为LLM提供最有用的视觉特征以输出所需的文本。
在第一阶段预训练中,作者执行视觉语言表征学习,强制Q-Former学习与文本最相关的视觉表征。在第二阶段预训练中,作者通过将Q-Former的输出连接到一个冻结的LLM,进行视觉到语言的生成学习,并训练Q-Former,使其输出的视觉表征可以被LLM解释。
Method
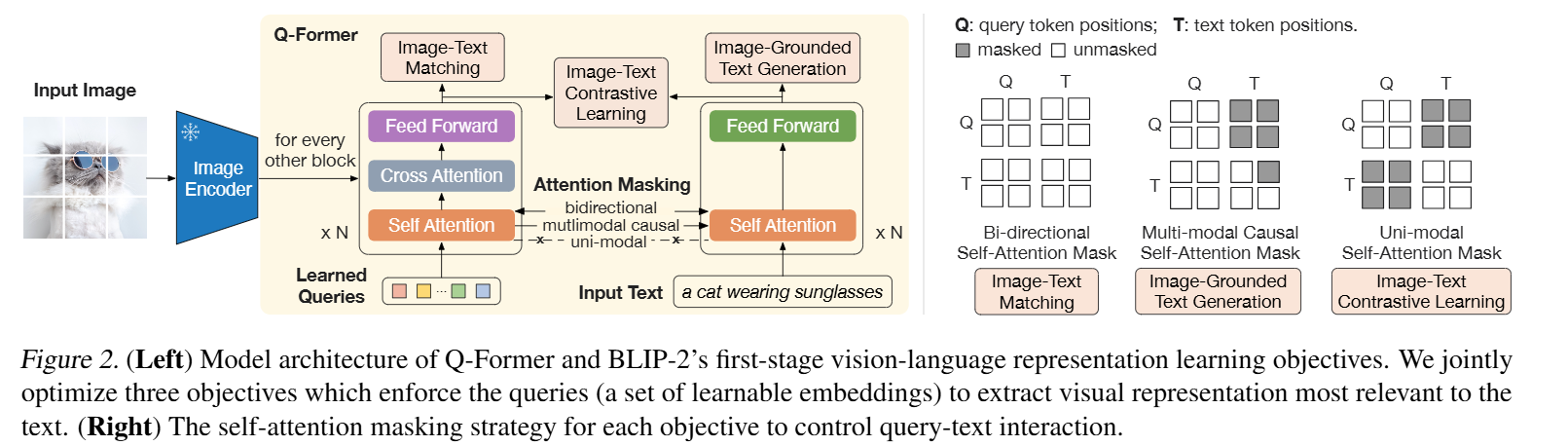
3.1. 模型架构
- Q-Former: BLIP-2的核心组件,一个轻量级的Transformer,包含两个子模块:
- 图像Transformer: 与冻结的图像编码器交互,提取视觉特征。
- 文本Transformer: 兼具文本编码器和文本解码器的功能。
我们创建了一组可学习的Query嵌入作为图像Transformer的输入。Query通过自注意力层相互作用,并通过交叉注意力层(每隔一个Transformer块插入一次)与冻结的图像特征相互作用。Query还可以通过相同的自注意力层与文本相互作用。根据预训练任务的不同,我们应用不同的自注意力掩码来控制Query与文本的交互。我们使用BERT base(Devlin等人,2019年)的预训练权重初始化Q-Former,交叉注意力层则是随机初始化的。
Q-Former总共包含1.88亿个参数,使用32个Query,每个Query的维度为768(与Q-Former的隐藏维度相同)。我们用Z来表示输出Query表示。Z的大小(32×768)比冻结图像特征的大小小得多(例如,对于ViT-L/14,大小为257×1024)。这种 bottleneck 架构预训练目标一起工作,迫使Query提取与文本最相关的视觉信息。
3.2. 从冻结的图像编码器中引导视觉语言表征学习
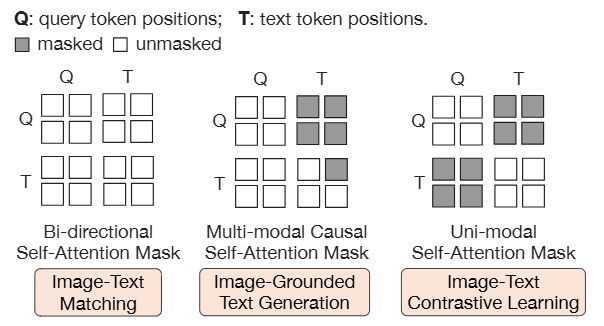
- 三个预训练目标 共同优化,但采用不同的注意力掩码策略来控制Query和文本之间的交互。
- 图像-文本对比学习 (ITC): 对齐图像表征和文本表征,最大化相互信息。
- 基于图像的文本生成 (ITG): 训练Q-Former根据输入图像生成文本。
- 图像-文本匹配 (ITM): 学习图像和文本表征之间的细粒度对齐。
3.3. 从冻结的LLM中引导视觉到语言的生成式学习
- 视觉提示: 将Q-Former的输出投影到LLM的文本嵌入维度,作为软视觉提示。
- 信息bottleneck: Q-Former提取与语言相关的视觉信息,减轻LLM的负担。
- 生成式预训练: 使用语言模型损失或前缀语言模型损失,训练LLM根据视觉提示生成文本。
3.4. 模型预训练
-
1. 预训练数据:
BLIP-2使用与BLIP相同的数据集进行预训练,该数据集包含来自COCO、Visual Genome等数据集的129M图像和文本对。为了扩充数据集,还使用了CapFilt方法为网络图像生成合成标题。
2. 冻结的模型:
- 图像编码器: 使用CLIP的ViT-L/14或EVA-CLIP的ViT-G/14作为冻结的图像编码器,并使用倒数第二层的输出特征。
- 语言模型: 使用OPT模型家族(解码器型)或FlanT5模型家族(编码器-解码器型)作为冻结的语言模型。
3. 预训练目标:
BLIP-2的预训练分为两个阶段,每个阶段都包含特定的预训练目标:
-
第一阶段(表征学习)
- 图像-文本对比学习 (ITC): 对齐图像表征和文本表征,最大化相互信息。
- 基于图像的文本生成 (ITG): 训练Q-Former根据输入图像生成文本。
- 图像-文本匹配 (ITM): 学习图像和文本表征之间的细粒度对齐。
-
第二阶段(生成式学习)
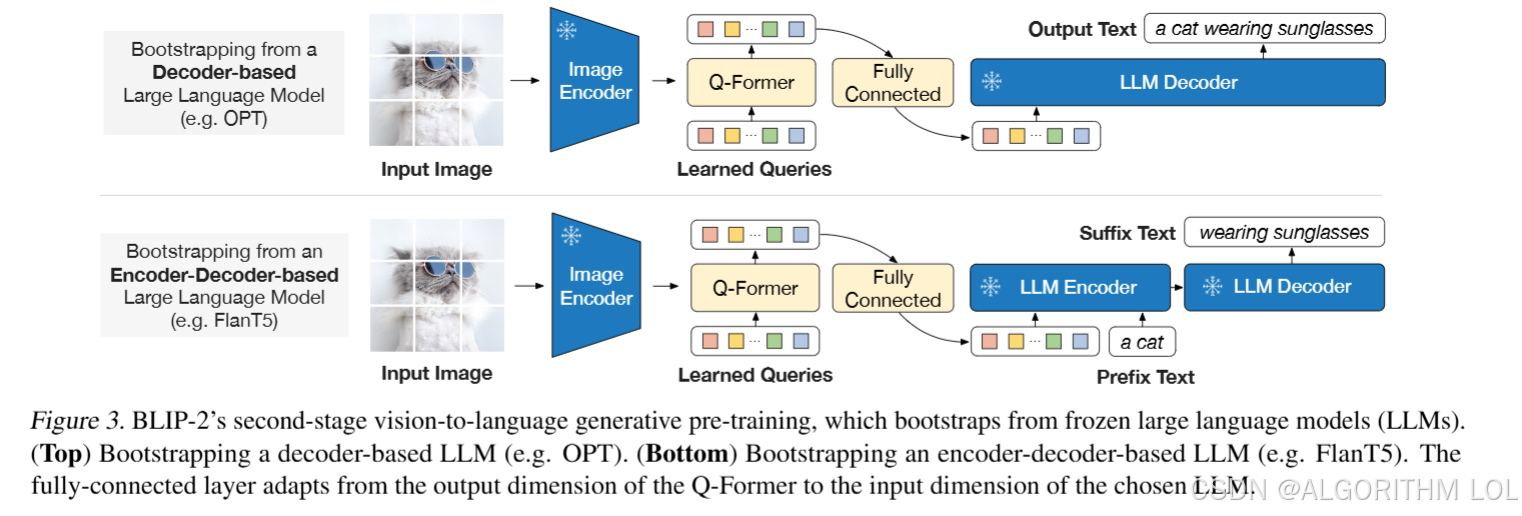
- 语言模型损失 (LM): 训练LLM根据Q-Former的输出生成文本。
- 前缀语言模型损失 (PLM): 将文本分为前缀和后缀,前缀与视觉表示连接后输入LLM的编码器,后缀作为解码器的生成目标。
4. 训练细节:
- 预训练步骤: 第一阶段预训练250k步,第二阶段预训练80k步。
- 批量大小: 根据使用的模型和阶段,设置不同的批量大小。
- 优化器: 使用AdamW优化器,并进行参数调整和正则化。
- 学习率: 使用余弦退火策略,并设置峰值学习率和线性预热步骤。
- 数据增强: 使用随机缩放裁剪和水平翻转等方法对图像进行增强。
Experiment
1. 零样本指令图像到文本生成:
- 实验方法: 将文本提示附加到视觉提示后,作为输入输入到LLM中。
- 实验结果: BLIP-2展示了广泛的零样本图像到文本生成能力,包括视觉知识推理、视觉常识推理、视觉对话等。
2. 零样本视觉问答 (VQA):
- 实验方法: 使用不同的提示格式,并使用beam search和长度惩罚进行文本生成。
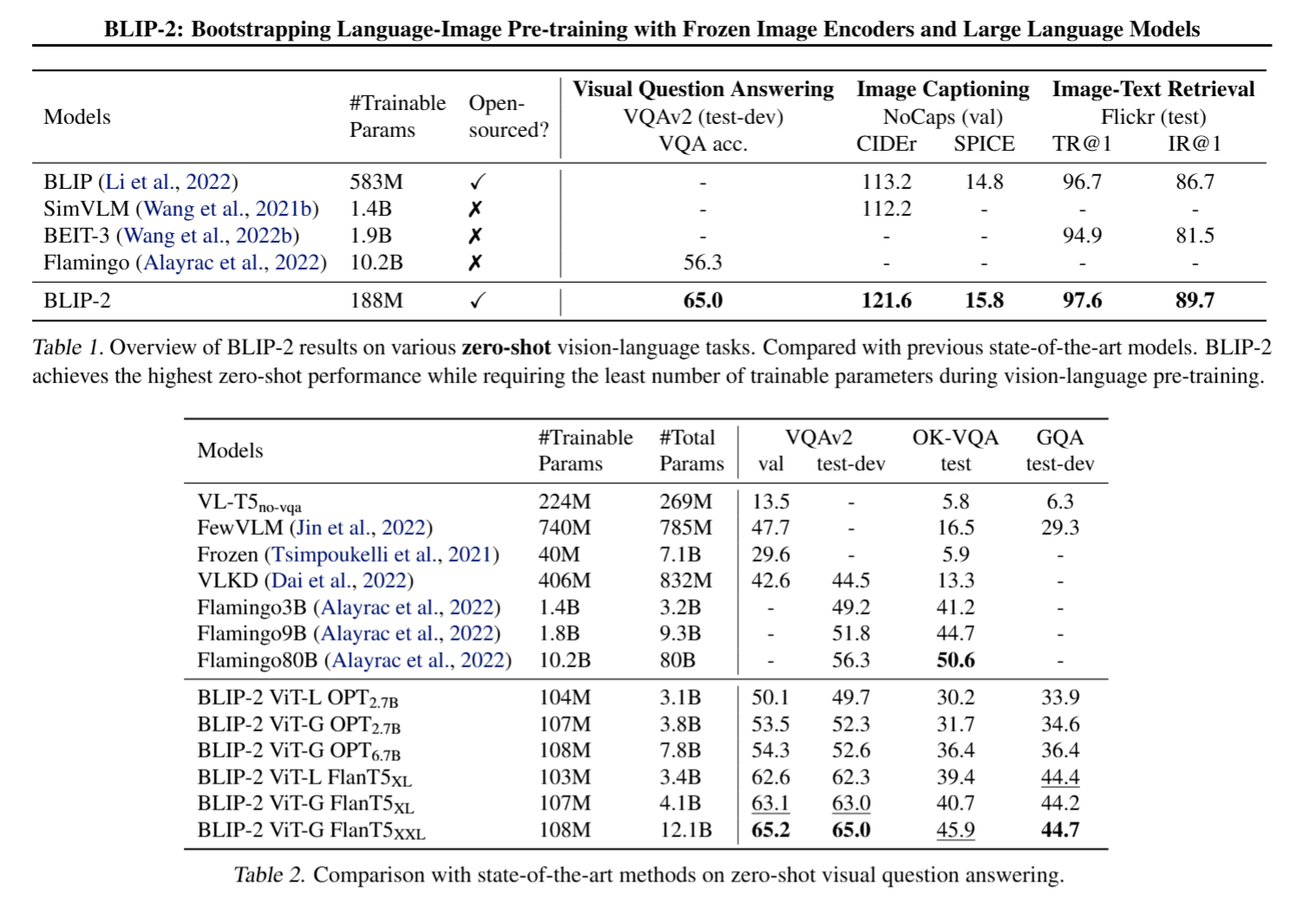
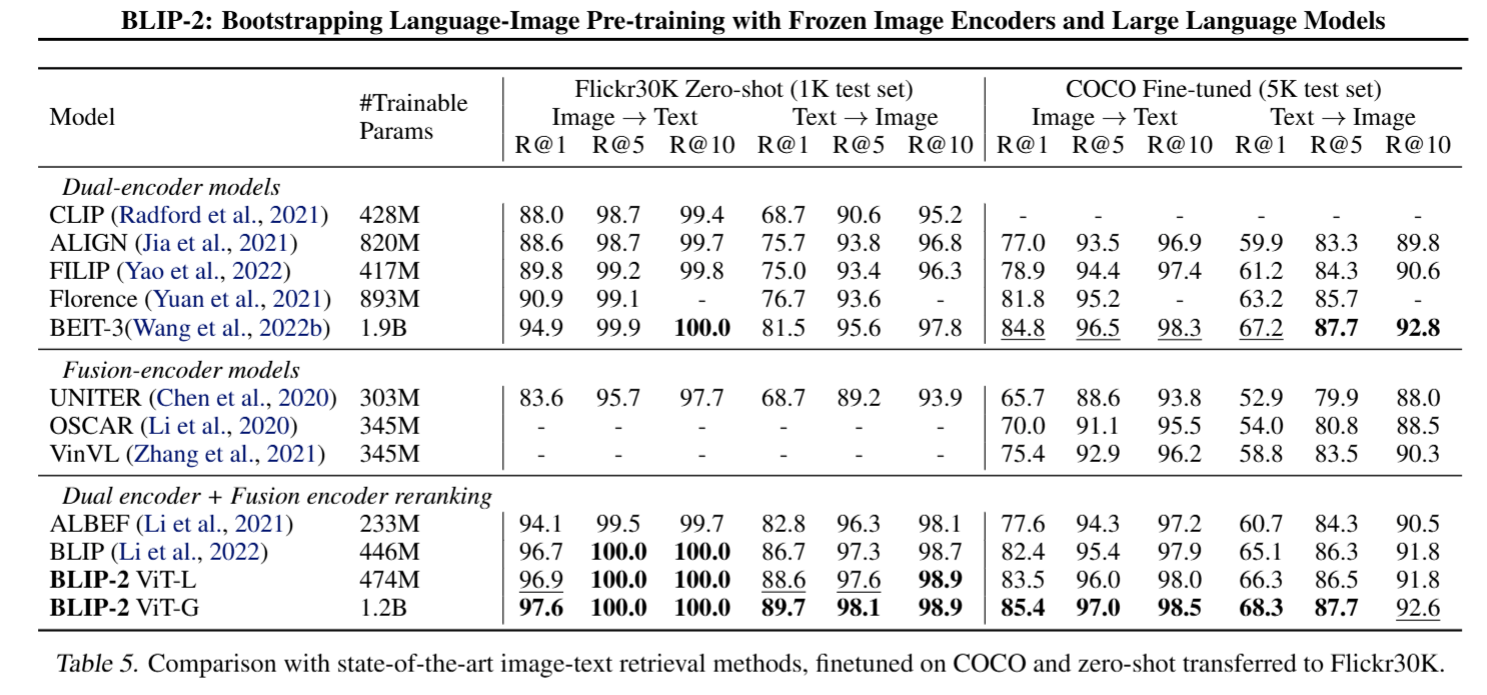
- 实验结果: BLIP-2在VQAv2和GQA数据集上取得了最先进的性能,并显著优于Flamingo80B。
3. 图像标注:
- 实验方法: 使用“一张照片的”作为初始输入,并使用语言模型损失进行微调。
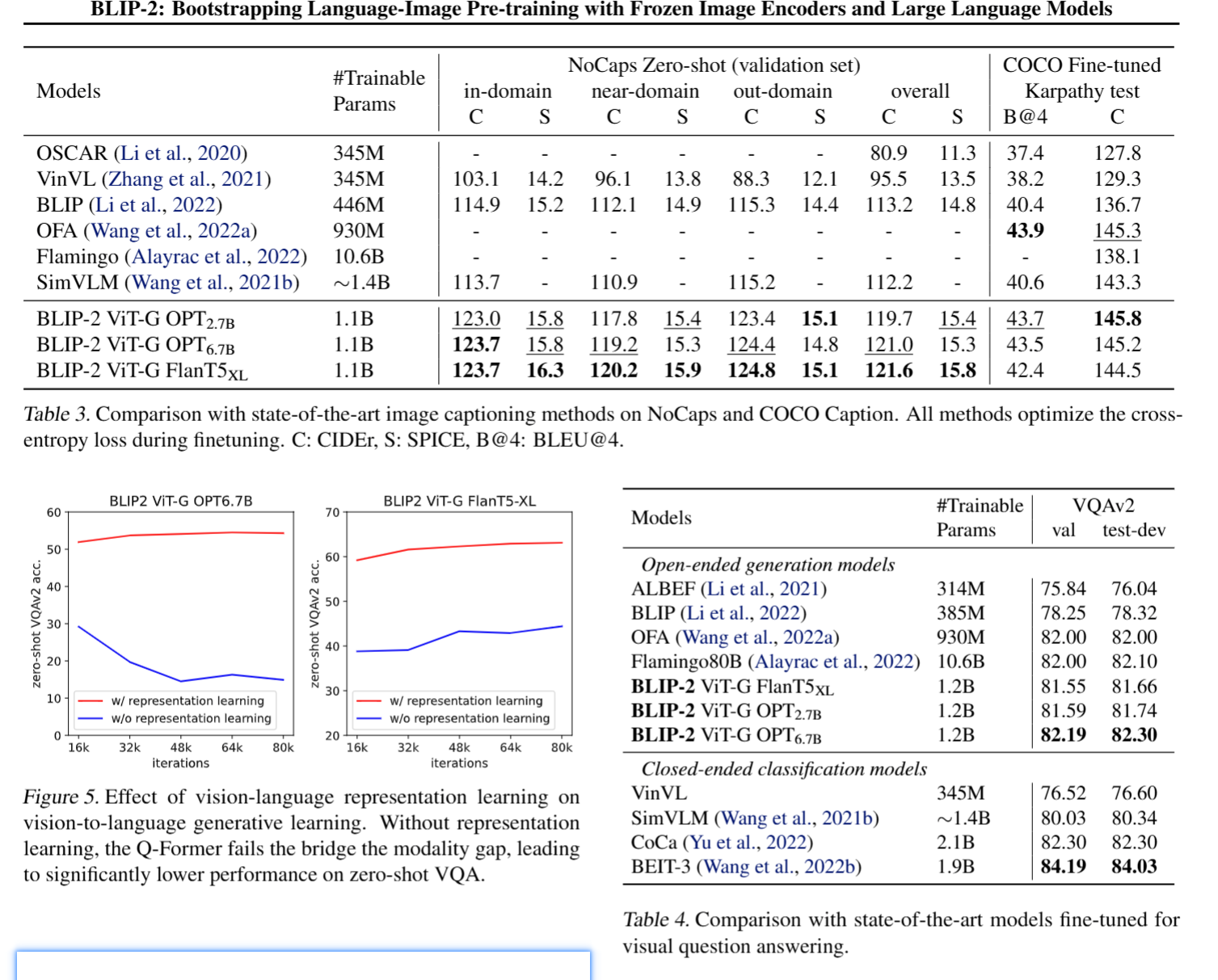
- 实验结果: BLIP-2在COCO和NoCaps数据集上取得了最先进的性能,证明了模型对域外图像的泛化能力。
4. 视觉问答 (VQA):
- 实验方法: 将问题作为输入,并使用开放式的答案生成损失进行微调。
- 实验结果: BLIP-2在VQAv2数据集上取得了最先进的性能,并优于大多数开放式的生成模型。
5. 图像-文本检索:
- 实验方法: 直接微调第一阶段预训练的模型,使用ITC、ITM和ITG损失进行微调。
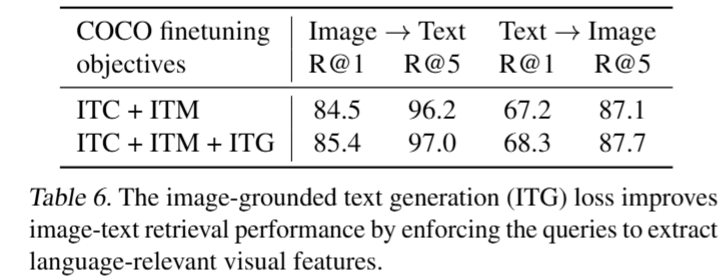
- 实验结果: BLIP-2在COCO和Flickr30K数据集上取得了最先进的性能,并显著优于现有方法。
6. 消融实验:
- 实验方法: 探究不同预训练目标对模型性能的影响。
- 实验结果: ITC、ITM和ITG损失都对模型性能有贡献,其中ITG损失对图像-文本检索也有益。
Limitation
1. 缺乏上下文学习能力:
- 问题: LLMs通常可以基于少量样例进行上下文学习,但BLIP-2在提供少量VQA样例的情况下,VQA性能没有显著提升。
- 原因: 预训练数据集中每个样本只包含一个图像-文本对,LLMs无法学习到多个图像-文本对之间的关联。
- 改进方向: 构建包含多个图像-文本对的预训练数据集,让LLMs学习到上下文信息。
2. 图像到文本生成的局限性:
- 问题: BLIP-2的图像到文本生成结果可能由于多种原因而不够理想,例如LLMs的知识不准确、激活了错误的推理路径或缺乏对新图像内容的最新信息。
- 改进方向: 使用指令来引导模型的生成,或使用过滤后的数据集进行训练,以避免生成有害内容。
3. 继承LLMs的风险:
- 问题: BLIP-2继承了LLMs的一些风险,例如输出不当言论、传播社会偏见或泄露隐私信息。
- 改进方向: 使用指令来引导模型的生成,或使用过滤后的数据集进行训练,以避免生成有害内容。


















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









