







学习总结:
这一课在B站上学习了梯度下降,对于其中认识总结如下:
在初入深度学习坑时,我们经常会听到一个词语叫 ”梯度下降算法“,老实说,在没有学习这一章节我也对此毫无头绪,在学习玩之后,对此有了以下总结:
对于一个问题而言,我们总可以提出三个问题:是什么?为什么?以及怎么样?对于梯度下降也是同样,以下总结从三个方面来解释:
梯度下降是什么?
简单来说就是一种寻找目标函数最小化的方法,它利用梯度信息,通过不断迭代调整参数来寻找合适的目标值。 用自己的话来说,其实就是对于一个函数而言,比如一个凸函数(机器学习中的凸函数与高数定义略微有区别),需要求得它的最小值,那么我们可以用梯度下降方法来找得,在使用这种算法的时候,每一次迭代会对里面的参数进行更新(比如权重值w)
为什么需要梯度下降?
在上一篇博客中我们知道,对于一个假设出来的线性模型 y=wx(b参数暂时省略),我们可以用穷举法对于w进行穷举,最终找到使得损失函数最小的w,但我们知道,机器学习存在维度诅咒,因此在高纬度的时候模型训练相当困难,在参数过多,那么这时候再采用穷举法便无法解决问题,
我们或许能想到能否使用分治法来找寻对应的参数,算法告诉我们使用分治法在找寻值的确非常优异,但是这种方法往往会带来一个陷入”局部“的问题,在损失函数不是光滑的凸函数或者有多个最小值,这种方法往往只会得到局部最优解,而这种时候梯度下降算法便能使得问题更好的解决
如何实现梯度下降?
梯度下降算法体现了算法核心思想中的贪心策略,对于一个cost(w)损失函数,假定这个损失函数是简单的凸函数,我们给定一个w初值,也就是给定一个点,对于这个点,我们利用函数对于点的导数,判断其中的梯度下降方向并且给定一个步长(学习率),最后使得这个点往梯度下降的方向不断前行来找到最低点,在前行的同时更新w值

推导如下:


表面一看,这种方法貌似挺完美,但其实梯度下降算法也存在其中的问题,同样对于复杂的函数,同样也会陷入局部最优解的问题,但为什么我们会在深度学习中大量使用呢?其实对于深度学习,目标函数往往不会存在太多的局部最优点,而是存在一种 "鞍点",在这种点时,求得的导数等于0,根据公式,如果函数陷入该点,导数为0,w便无法继续迭代更新
对于这个问题我们便引入了 "随机梯度下降方法"进行解决,我们的cost函数是作为所有样本的损失函数,但随机梯度下降法是利用单个样本的损失对w进行迭代更新,单个样本存在 "噪声",因此这些噪声可以使得在陷入鞍点时候,也能向前推进(这些噪声算的对应点的导数值不会总是也为0)

附代码:
梯度下降
import matplotlib.pyplot as plt
x_data = [1.0,2.0,3.0]
y_data = [2.0,4.0,6.0]
w = 1.0
epoch_list =[]
loss_list =[]
def forward(x):
return x*w
def loss(xs,ys):
loss = 0
for x,y in zip(xs,ys):
y_pred = forward(x)
loss = loss +(y_pred-y)*(y_pred-y)
return loss/len(xs)
def gradient(xs,ys):
grad = 0
for x,y in zip(xs,ys):
grad = grad+2*x*(x*w -y)
return grad /len(xs)
print('Predict (before training)', 4, forward(4))
for epoch in range(200):
loss_val =loss(x_data,y_data)
grad_val = gradient(x_data,y_data)
w = w-0.01*grad_val
epoch_list.append(epoch)
loss_list.append(loss_val)
print('Epoch:',epoch,'w=%.2f'%w,"loss=%.2f"%loss_val)
print('Predict (before training)', 4, forward(4))
plt.plot(epoch_list,loss_list)
plt.xlabel("loss")
plt.ylabel("epoch")
plt.show()结果展


随机梯度下降
import random
import matplotlib.pyplot as plt
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
w=1.0
def forward(x):
return w*x
def loss(xs,ys):
y_pred = forward(xs)
return (y_pred-ys)**2
def gradient(x,y):
return 2*x*(x*w-y)
epoch_list=[]
loss_list=[]
print('predict (before training)', 4, forward(4))
num= len(x_data)
for epoch in range(100):
sc_index = random.randint(0,len(x_data)-1)
x,y = x_data[sc_index],y_data[sc_index]
grad = gradient(x,y)
w= w-0.01*grad
los = loss(x,y)
#print(x,y,"\tgrad:%2f"%grad)
print(f'progress:{epoch} grad={grad:.2f} w={w:.2f} loss={los:.2f}')
epoch_list.append(epoch)
loss_list.append(los)
print('predict (before training)', 4, forward(4))
plt.plot(epoch_list,loss_list)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()结果展示:

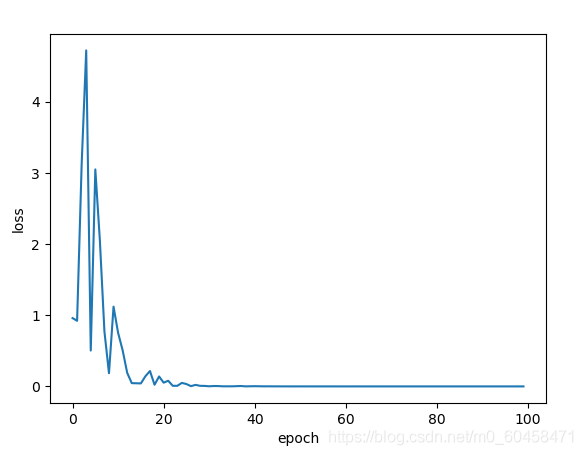
梯度下降算法运算可以并行计算(所有样本训练完一次进行一次更新),但性能不好,而随机梯度则不能并行(每一个样本w参数更新影响下一个样本训练),但性能好,两者结合提出一种折中取样mini-batch(由几个单独样本构成一个小整体用于求梯度然后对参数进行更新)
batch原指所有样本(一个批次),但由于深度学习中大量使用随机梯度下降算法,而随机梯度(SGD)采用的是mini-batch,因此省略mini,因此我们现在提到的batch实际上是mini-batch
本人小白一枚,刚入深度学习坑,纯粹自我总结,有问题请大佬指出!不胜感激














 3067
3067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









